Adatparticionálási stratégiák
Ez a cikk a különböző Azure-adattárakban lévő adatok particionálására vonatkozó stratégiákat ismerteti. Az adatok particionálásával és az ajánlott eljárásokkal kapcsolatos általános útmutatásért lásd adatparticionálási.
Az Azure SQL Database particionálása
Egyetlen SQL-adatbázis legfeljebb az általa tartalmazhatott adatok mennyiségére korlátozható. Az átviteli sebességet az architekturális tényezők és az egyidejű kapcsolatok száma korlátozza.
rugalmas készletek támogatják az SQL-adatbázisok horizontális skálázását. Rugalmas készletek használatával particionálhatja az adatokat több SQL-adatbázisra kiterjedő szegmensekre. Szegmenseket is hozzáadhat vagy eltávolíthat, mivel a kezelni kívánt adatmennyiség növekszik és csökken. A rugalmas készletek a terhelés adatbázisok közötti elosztásával is csökkenthetik a versengést.
Minden szegmens SQL-adatbázisként van implementálva. A szegmensek több adatkészletet is tartalmazhatnak (shardlet). Minden adatbázis olyan metaadatokat tart fenn, amelyek a benne található szegmenseket ismertetik. A szegmensek lehetnek egyetlen adatelem vagy egy olyan elemcsoport, amely ugyanazt a szegmenskulcsot használja. Egy több-bérlős alkalmazásban például a szegmenskulcs lehet a bérlőazonosító, és a bérlő összes adata ugyanabban a szegmensben tárolható.
Az ügyfélalkalmazások felelősek az adatkészletek shardlet kulccsal való társításáért. Egy külön SQL Database globális szegmenstérkép-kezelőként működik. Ez az adatbázis tartalmazza a rendszer összes shardját és shardletjét. Az alkalmazás csatlakozik a szegmenstérkép-kezelő adatbázisához a szegmenstérkép másolatának lekéréséhez. Helyileg gyorsítótárazza a szegmenstérképet, és a térkép használatával irányítja az adatkéréseket a megfelelő szegmensbe. Ez a funkció a Java és a .NET számára elérhető Elastic Database-ügyfélkódtártartalmazott API-k sorozata mögött rejtve van.
További információ a rugalmas készletekről: Horizontális felskálázás az Azure SQL Database.
A késés csökkentése és a rendelkezésre állás javítása érdekében replikálhatja a globális szegmenstérkép-kezelő adatbázist. A Prémium tarifacsomagokkal konfigurálhatja az aktív georeplikálást az adatok különböző régiókban lévő adatbázisokba való folyamatos másolásához.
Másik lehetőségként az Azure SQL Data Sync vagy Azure Data Factory használatával replikálhatja a szegmenstérkép-kezelő adatbázisát régiók között. Ez a replikációs forma rendszeres időközönként fut, és akkor megfelelőbb, ha a szegmenstérkép ritkán változik, és nem igényel prémium szintű szintet.
Az Elastic Database két sémát biztosít az adatok szegmensekhez való leképezéséhez és szegmensekben való tárolásához:
A lista szegmenstérképe egyetlen kulcsot társít egy szegmenshez. Egy több-bérlős rendszerben például az egyes bérlők adatai társíthatók egy egyedi kulccsal, és a saját szegmensében tárolhatók. Az elkülönítés garantálása érdekében minden szegmens a saját szegmensében tartható.

A diagram Visio-fájljának letöltése.
Egy tartomány szegmenstérképe egy egybefüggő kulcsértékeket társít egy szegmenshez. Csoportosíthatja például a bérlők egy csoportjának adatait (mindegyik saját kulccsal) ugyanabban a szegmensben. Ez a séma olcsóbb, mint az első, mivel a bérlők megosztják az adattárolást, de kevésbé elszigeteltek.

A diagram Visio-fájljának letöltése
Egyetlen töredék több töredékrész adatait is tartalmazhatja. A listaszilánkok használatával például különböző, nem egybefüggő bérlők adatait tárolhatja ugyanabban a szegmensben. A tartományshardleteket és a listaszilánkokat ugyanabban a szegmensben is keverheti, bár ezek kezelése különböző térképeken keresztül történik. Az alábbi ábrán ez a megközelítés látható:

A diagram Visio-fájljának letöltése.
A rugalmas készletek lehetővé teszik a szegmensek hozzáadását és eltávolítását az adatmennyiség zsugorodása és növekedése során. Az ügyfélalkalmazások dinamikusan hozhatnak létre és törölhetnek szegmenseket, és transzparens módon frissíthetik a szegmenstérkép-kezelőt. A szegmensek eltávolítása azonban olyan romboló művelet, amely az adott szegmensben lévő összes adat törlését is igényli.
Ha egy alkalmazásnak fel kell osztania egy szegmenst két különálló szegmensre, vagy egyesítenie kell a szegmenseket, használja a felosztott egyesítési eszközt. Ez az eszköz Azure-webszolgáltatásként fut, és biztonságosan migrálja az adatokat a szegmensek között.
A particionálási séma jelentősen befolyásolhatja a rendszer teljesítményét. Emellett befolyásolhatja a szegmensek hozzáadásának vagy eltávolításának sebességét, vagy azt, hogy az adatokat a szegmensek között újra kell particionálásra végezni. Vegye figyelembe a következő szempontokat:
Csoportosítsa az ugyanabban a szegmensben együtt használt adatokat, és kerülje a több szegmensből származó adatokat elérő műveleteket. A szegmensek önálló SQL-adatbázisok, és az adatbázisközi illesztéseket az ügyféloldalon kell végrehajtani.
Bár az SQL Database nem támogatja az adatbázisközi illesztéseket, az Elastic Database-eszközökkel több szegmenses lekérdezéseket hajthat végre. A több szegmensből álló lekérdezések egyedi lekérdezéseket küldenek az egyes adatbázisoknak, és egyesítik az eredményeket.
Ne tervezzen olyan rendszert, amely függőségekkel rendelkezik a szegmensek között. Az adatbázis hivatkozási integritási korlátozásai, eseményindítói és tárolt eljárásai nem hivatkozhatnak egy másik objektumra.
Ha olyan referenciaadatokkal rendelkezik, amelyeket a lekérdezések gyakran használnak, fontolja meg az adatok szegmensek közötti replikálását. Ez a megközelítés szükségtelenné teheti az adatok adatbázisok közötti összekapcsolására. Ideális esetben az ilyen adatoknak statikusnak vagy lassan mozgónak kell lenniük, hogy minimalizálják a replikációs munkát, és csökkentsék annak esélyét, hogy elavulttá váljanak.
Az ugyanahhoz a szegmenstérképhez tartozó szegmensleképezőknek ugyanazzal a sémával kell rendelkezniük. Ezt a szabályt az SQL Database nem kényszeríti ki, de az adatkezelés és a lekérdezés nagyon bonyolulttá válik, ha minden szegmens más sémával rendelkezik. Ehelyett hozzon létre különálló szegmenstérképeket az egyes sémákhoz. Ne feledje, hogy a különböző szegmensekhez tartozó adatok ugyanabban a szegmensben tárolhatók.
A tranzakciós műveletek csak a szegmenseken belüli adatok esetében támogatottak, szegmenseken belül nem. A tranzakciók mindaddig kiterjedhetnek a szegmensekre, amíg ugyanahhoz a szegmenshez tartoznak. Ezért ha az üzleti logikának tranzakciókat kell végrehajtania, akkor vagy ugyanabban a szegmensben tárolja az adatokat, vagy végleges konzisztenciát valósít meg.
Helyezze a szegmenseket azokhoz a felhasználókhoz, akik hozzáférnek az ezekben a szegmensekben lévő adatokhoz. Ez a stratégia segít csökkenteni a késést.
Kerülje a rendkívül aktív és viszonylag inaktív szegmensek keverékét. Próbálja egyenletesen elosztani a terhelést a szegmensek között. Ehhez szükség lehet a szilánkkulcsok kivonatolására. Ha a szegmenseket georendezi, győződjön meg arról, hogy a kivonatolt kulcsok az adatokhoz hozzáférő felhasználók közelében tárolt szegmensekben tárolt szegmensekre vannak leképezve.
Az Azure Table Storage particionálása
Az Azure Table Storage egy kulcs-érték tároló, amelyet particionálásra terveztek. Minden entitást egy partíció tárol, a partíciókat pedig belsőleg az Azure Table Storage felügyeli. A táblában tárolt minden entitásnak rendelkeznie kell egy kétrészes kulccsal, amely a következőket tartalmazza:
A partíciókulcs. Ez egy sztringérték, amely meghatározza azt a partíciót, amelyben az Azure Table Storage elhelyezi az entitást. Az azonos partíciókulcsú entitások ugyanabban a partícióban vannak tárolva.
A sorkulcs. Ez egy sztringérték, amely azonosítja a partíción belüli entitást. A partíción belüli összes entitás lexikálisan, növekvő sorrendben van rendezve ezzel a kulccsal. A partíciókulcs/sorkulcs kombinációnak egyedinek kell lennie az egyes entitásokhoz, és nem haladhatja meg az 1 KB-ot.
Ha egy korábban nem használt partíciókulcsot tartalmazó táblához ad hozzá egy entitást, az Azure Table Storage létrehoz egy új partíciót ehhez az entitáshoz. Az azonos partíciókulcsú egyéb entitások ugyanabban a partícióban lesznek tárolva.
Ez a mechanizmus hatékonyan implementál egy automatikus vertikális felskálázási stratégiát. A rendszer minden partíciót ugyanazon a kiszolgálón tárol egy Azure-adatközpontban, így biztosítva, hogy az egyetlen partícióról adatokat lekérő lekérdezések gyorsan fussanak.
A Microsoft közzétette skálázhatósági célokat az Azure Storage-hoz. Ha a rendszer valószínűleg túllépi ezeket a korlátokat, fontolja meg az entitások több táblára való felosztását. Függőleges particionálással ossza fel a mezőket azokra a csoportokra, amelyekhez a legnagyobb valószínűséggel együtt férnek hozzá.
Az alábbi ábra egy példatárfiók logikai szerkezetét mutatja be. A tárfiók három táblát tartalmaz: Ügyféladatok, Termékadatok és Rendelési adatok.
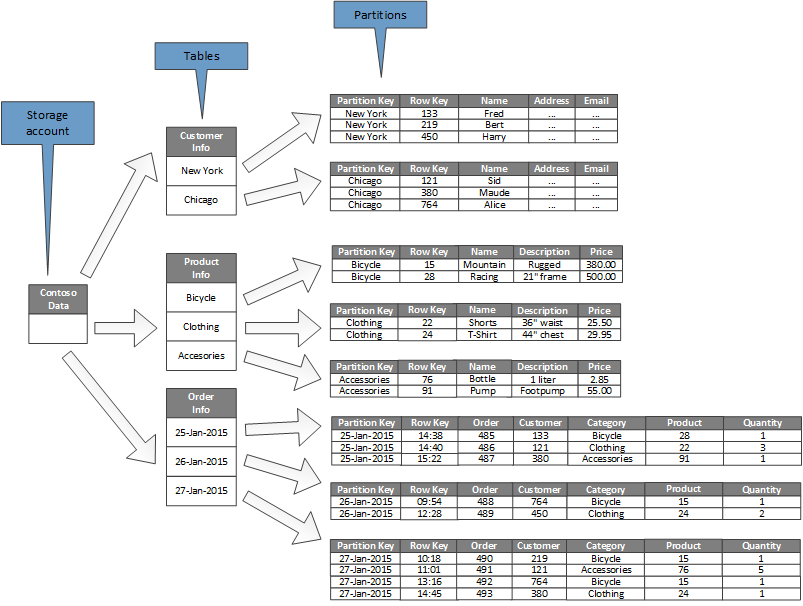
Minden tábla több partícióval rendelkezik.
- Az Ügyféladatok táblában az adatok particionálása annak a városnak megfelelően történik, ahol az ügyfél található. A sorkulcs tartalmazza az ügyfélazonosítót.
- A Termékinformáció táblában a termékek termékkategória szerint vannak particionálva, a sorkulcs pedig a termékszámot tartalmazza.
- A Rendelés adatai táblában a rendelések a rendelés dátuma szerint vannak particionálva, a sorkulcs pedig a rendelés beérkezésének időpontját határozza meg. Minden adatot az egyes partíciók sorkulcsa rendez.
Az entitások Azure Table Storage-hoz való tervezésekor vegye figyelembe a következő szempontokat:
Válassza ki a partíciókulcsot és a sorkulcsot az adatok elérésének módjával. Válasszon egy partíciókulcs/sorkulcs kombinációt, amely támogatja a lekérdezések többségét. A leghatékonyabb lekérdezések a partíciókulcs és a sorkulcs megadásával kérik le az adatokat. A partíciókulcsot és sorkulcsok tartományát meghatározó lekérdezések egyetlen partíció beolvasásával végezhetők el. Ez viszonylag gyors, mert az adatok sorkulcs-sorrendben lesznek tárolva. Ha a lekérdezések nem határozzák meg a vizsgálandó partíciót, minden partíciót be kell vizsgálni.
Ha egy entitás rendelkezik egy természetes kulccsal, használja partíciókulcsként, és adjon meg egy üres sztringet sorkulcsként. Ha egy entitás két tulajdonságból álló összetett kulccsal rendelkezik, válassza a leglassabb változó tulajdonságot partíciókulcsként, a másikat pedig sorkulcsként. Ha egy entitás két kulcstulajdonságnál több tulajdonsággal rendelkezik, a tulajdonságok összefűzével adja meg a partíció- és sorkulcsokat.
Ha rendszeresen olyan lekérdezéseket hajt végre, amelyek a partíció- és sorkulcsokon kívül más mezők használatával keresnek adatokat, fontolja meg a Indextábla mintaimplementálását, vagy fontolja meg az indexelést támogató másik adattár használatát, például az Azure Cosmos DB-t.
Ha a partíciókulcsokat monoton szekvencia (például "0001", "0002", "0003") használatával hozza létre, és mindegyik partíció csak korlátozott mennyiségű adatot tartalmaz, az Azure Table Storage fizikailag csoportosíthatja ezeket a partíciókat ugyanazon a kiszolgálón. Az Azure Storage feltételezi, hogy az alkalmazás valószínűleg több partíción (tartomány-lekérdezésen) végez lekérdezéseket, és erre az esetre van optimalizálva. Ez a megközelítés azonban hotspotokhoz vezethet, mivel az új entitások összes beszúrása valószínűleg az egybefüggő tartomány egyik végén koncentrálódik. A méretezhetőséget is csökkentheti. A terhelés egyenletesebb elosztásához fontolja meg a partíciókulcs kivonatolását.
Az Azure Table Storage támogatja az ugyanazon partícióhoz tartozó entitások tranzakciós műveleteit. Az alkalmazások atomi egységként több beszúrási, frissítési, törlési, csere- vagy egyesítési műveletet hajthatnak végre, feltéve, hogy a tranzakció nem tartalmaz több mint 100 entitást, és a kérelem hasznos adatai nem haladják meg a 4 MB-ot. A több partícióra kiterjedő műveletek nem tranzakciósak, és előfordulhat, hogy a végleges konzisztenciát kell implementálnia. További információ a táblatárolásról és a tranzakciókról: Entitáscsoport tranzakcióinak végrehajtása.
Vegye figyelembe a partíciókulcs részletességét:
Ha minden entitáshoz ugyanazt a partíciókulcsot használja, az egyetlen kiszolgálón tárolt partíciót eredményez. Ez megakadályozza, hogy a partíció horizontálisan felskálázható legyen, és egyetlen kiszolgálóra összpontosítsa a terhelést. Ennek eredményeképpen ez a megközelítés csak kis számú entitás tárolására alkalmas. Ugyanakkor biztosítja, hogy minden entitás részt vehessen az entitáscsoport tranzakcióiban.
Ha minden entitáshoz egyedi partíciókulcsot használ, a táblatároló szolgáltatás minden entitáshoz külön partíciót hoz létre, ami nagy számú kis partíciót eredményez. Ez a megközelítés méretezhetőbb, mint egyetlen partíciókulcs használata, de az entitáscsoport tranzakciói nem lehetségesek. Emellett egynél több entitást lekérő lekérdezések több kiszolgálóról is beolvashatják az adatokat. Ha azonban az alkalmazás tartománylekérdezéseket hajt végre, akkor a partíciókulcsok monoton szekvenciáját használva optimalizálhatja ezeket a lekérdezéseket.
A partíciókulcsnak az entitások egy részhalmazán való megosztása lehetővé teszi a kapcsolódó entitások csoportosítását ugyanabban a partícióban. A kapcsolódó entitásokat tartalmazó műveletek entitáscsoport-tranzakciók használatával végezhetők el, és a kapcsolódó entitásokat lekérdező lekérdezések egyetlen kiszolgálóhoz való hozzáféréssel is kielégíthetők.
További információ: Azure Storage táblatervezési útmutatója és Skálázható particionálási stratégia.
Az Azure Blob Storage particionálása
Az Azure Blob Storage lehetővé teszi nagy bináris objektumok tárolását. Használjon blokkblobokat olyan helyzetekben, amikor nagy mennyiségű adatot kell gyorsan feltöltenie vagy letöltenie. Használjon lapblobokat olyan alkalmazásokhoz, amelyek az adatok egyes részeihez való soros hozzáférés helyett véletlenszerű hozzáférést igényelnek.
Minden blob (blokk vagy oldal) egy Azure Storage-fiók tárolójában található. Tárolók használatával csoportosíthatja az azonos biztonsági követelményekkel rendelkező kapcsolódó blobokat. Ez a csoportosítás nem fizikai, hanem logikai. Egy tárolón belül minden blobnak egyedi neve van.
A blob partíciókulcsa a fiók neve + tároló neve + blob neve. A partíciókulcs az adatok tartományokra való particionálására szolgál, és ezek a tartományok terheléselosztása a rendszeren belül történik. A blobok több kiszolgálón is eloszthatók a hozzáférés skálázása érdekében, de egyetlen blobot csak egyetlen kiszolgáló tud kiszolgálni.
Ha az elnevezési séma időbélyegeket vagy numerikus azonosítókat használ, az túlzott forgalomhoz vezethet egy partícióra, ami korlátozza a rendszer hatékony terheléselosztását. Ha például olyan napi műveleteket végez, amelyek egy blobobjektumot használnak időbélyeggel, például yyyyy-mm-dd, a művelet összes forgalma egyetlen partíciókiszolgálóra kerül. Ehelyett fontolja meg a név előtagjának háromjegyű kivonattal való előtagolását. További információ: partícióelnevezési konvenció.
Az egyetlen blokk vagy lap írása atomi művelet, de a blokkokat, oldalakat vagy blobokat felölelő műveletek nem. Ha konzisztenciát szeretne biztosítani a blokkok, lapok és blobok írási műveleteinek végrehajtásakor, blobbérlet használatával vegye ki az írási zárolást.
Azure Storage-üzenetsorok particionálása
Az Azure Storage-üzenetsorok lehetővé teszik a folyamatok közötti aszinkron üzenetküldés implementálását. Az Azure Storage-fiókok tetszőleges számú üzenetsort tartalmazhatnak, és minden üzenetsor tetszőleges számú üzenetet tartalmazhat. Az egyetlen korlátozás a tárfiókban elérhető terület. Az egyes üzenetek maximális mérete 64 KB. Ha ennél nagyobb üzenetekre van szüksége, fontolja meg inkább az Azure Service Bus-üzenetsorok használatát.
Minden tárolási üzenetsor egyedi névvel rendelkezik az azt tartalmazó tárfiókon belül. Az Azure a név alapján állítja be az üzenetsorokat. Az üzenetsor összes üzenete ugyanabban a partícióban van tárolva, amelyet egyetlen kiszolgáló vezérel. A különböző üzenetsorokat különböző kiszolgálók kezelhetik a terheléselosztás érdekében. Az üzenetsorok kiszolgálókra való lefoglalása az alkalmazások és a felhasználók számára átlátható.
Nagy méretű alkalmazásokban ne használja ugyanazt a tárolási üzenetsort az alkalmazás minden példányához, mert ez a megközelítés azt eredményezheti, hogy az üzenetsort üzemeltető kiszolgáló gyakori hellyel rendelkezik. Ehelyett használjon különböző üzenetsorokat az alkalmazás különböző funkcionális területeihez. Az Azure Storage-üzenetsorok nem támogatják a tranzakciókat, ezért az üzenetek különböző üzenetsorokra való irányítása kevés hatással lehet az üzenetkonzisztenciára.
Egy Azure Storage-üzenetsor másodpercenként legfeljebb 2000 üzenetet képes kezelni. Ha ennél nagyobb sebességgel kell feldolgoznia az üzeneteket, érdemes lehet több üzenetsort létrehoznia. Egy globális alkalmazásban például hozzon létre külön tárolási üzenetsorokat külön tárfiókokban az egyes régiókban futó alkalmazáspéldányok kezeléséhez.
Az Azure Service Bus particionálása
Az Azure Service Bus üzenetközvetítővel kezeli a Service Bus-üzenetsorba vagy -témakörbe küldött üzeneteket. Alapértelmezés szerint az üzenetsorba vagy témakörbe küldött összes üzenetet ugyanaz az üzenetközvetítő folyamat kezeli. Ez az architektúra korlátozhatja az üzenetsor teljes átviteli sebességét. Létrehozhat azonban egy üzenetsort vagy témakört is. Ezt úgy teheti meg, hogy az üzenetsor vagy a témakör leírásának EnablePartitioning tulajdonságát igaz értékre állítja.
A particionált üzenetsorok vagy témakörök több töredékre vannak osztva, amelyek mindegyikét külön üzenettár és üzenetközvetítő készíti el. A Service Bus felelősséget vállal a töredékek létrehozásáért és kezeléséért. Amikor egy alkalmazás közzétesz egy üzenetet egy particionált üzenetsorba vagy témakörbe, a Service Bus hozzárendeli az üzenetet az üzenetsor vagy témakör egy töredékéhez. Amikor egy alkalmazás üzenetet kap egy üzenetsorból vagy előfizetésből, a Service Bus ellenőrzi az egyes töredékeket a következő elérhető üzenethez, majd átadja azt az alkalmazásnak feldolgozás céljából.
Ez a struktúra segít elosztani a terhelést az üzenetközvetítők és üzenettárolók között, fokozza a méretezhetőséget és javítja a rendelkezésre állást. Ha egy töredék üzenetközvetítője vagy üzenettárolója átmenetileg nem érhető el, a Service Bus lekérheti az üzeneteket a fennmaradó rendelkezésre álló töredékek egyikéből.
A Service Bus az alábbiak szerint rendel hozzá egy üzenetet egy töredékhez:
Ha az üzenet egy munkamenethez tartozik, a rendszer az SessionId tulajdonsággal azonos értékű üzeneteket ugyanarra a töredékre küldi.
Ha az üzenet nem munkamenethez tartozik, de a feladó megadott egy értéket a PartitionKey tulajdonsághoz, akkor a rendszer az azonos PartitionKey értékkel rendelkező összes üzenetet ugyanarra a töredékre küldi.
Megjegyzés
Ha a SessionId és PartitionKey tulajdonságok is meg vannak adva, akkor azokat ugyanarra az értékre kell állítani, vagy az üzenet el lesz utasítva.
Ha az üzenet SessionId és PartitionKey tulajdonságai nincsenek megadva, de a duplikált észlelés engedélyezve van, a rendszer a MessageId tulajdonságot fogja használni. Az azonos MessageId rendelkező összes üzenet ugyanahhoz a töredékhez lesz irányítva.
Ha az üzenetek nem tartalmaznak SessionId, PartitionKey, vagy MessageId tulajdonságot, akkor a Service Bus egymás után rendeli hozzá az üzeneteket a töredékekhez. Ha egy töredék nem érhető el, a Service Bus a következőre lép. Ez azt jelenti, hogy az üzenetküldési infrastruktúra átmeneti hibája nem okozza az üzenetküldési művelet meghiúsulását.
A Service Bus-üzenetsor vagy -témakör particionálásának eldöntésekor vegye figyelembe a következő szempontokat:
A Service Bus-üzenetsorok és témakörök a Service Bus-névtér hatókörén belül jönnek létre. A Service Bus jelenleg névtérenként legfeljebb 100 particionált üzenetsort vagy témakört tesz lehetővé.
Minden Service Bus-névtér kvótákat ír elő az elérhető erőforrásokra, például a témakörenkénti előfizetések számát, az egyidejű küldési és fogadási kérelmek másodpercenkénti számát, valamint az egyidejű kapcsolatok maximális számát. Ezeket a kvótákat Service Bus-kvótákdokumentálják. Ha várhatóan túllépi ezeket az értékeket, hozzon létre további névtereket saját üzenetsorokkal és témakörökkel, és terjessze el a munkát ezeken a névtereken. Egy globális alkalmazásban például hozzon létre külön névtereket az egyes régiókban, és konfigurálja az alkalmazáspéldányokat a legközelebbi névtér üzenetsorainak és témaköreinek használatára.
A tranzakciók keretében küldött üzenetekben meg kell adni egy partíciókulcsot. Ez lehet SessionId, PartitionKeyvagy MessageId tulajdonság. Az ugyanazon tranzakció részeként küldött összes üzenetnek ugyanazt a partíciókulcsot kell megadnia, mert azokat ugyanazon üzenetközvetítői folyamatnak kell kezelnie. Ugyanabban a tranzakcióban nem küldhet üzeneteket különböző üzenetsorokra vagy témakörökre.
A particionált üzenetsorok és témakörök nem konfigurálhatók úgy, hogy az inaktívvá válásukkor automatikusan törlődjenek.
A particionált üzenetsorok és témakörök jelenleg nem használhatók az Advanced Message Queuing Protocol (AMQP) használatával, ha platformfüggetlen vagy hibrid megoldásokat készít.
Az Azure Cosmos DB particionálása
Azure Cosmos DB for NoSQL egy NoSQL-adatbázis JSON-dokumentumok tárolására. Az Azure Cosmos DB-adatbázisban lévő dokumentumok egy objektum vagy más adat JSON-szerializált ábrázolása. Nincs rögzített séma kényszerítve, kivéve, hogy minden dokumentumnak egyedi azonosítót kell tartalmaznia.
A dokumentumok gyűjteményekbe vannak rendezve. A kapcsolódó dokumentumokat csoportosíthatja egy gyűjteményben. Például egy olyan rendszerben, amely blog-közzétételeket tart fenn, az egyes blogbejegyzések tartalmát dokumentumként tárolhatja egy gyűjteményben. Az egyes tárgytípusokhoz gyűjteményeket is létrehozhat. Másik lehetőségként egy több-bérlős alkalmazásban, például egy olyan rendszerben, amelyben a különböző szerzők vezérlik és kezelik saját blogbejegyzéseiket, a blogokat szerzők szerint particionálhatja, és külön gyűjteményeket hozhat létre minden szerző számára. A gyűjtemények számára lefoglalt tárterület rugalmas, és szükség szerint zsugorodhat vagy növekedhet.
Az Azure Cosmos DB támogatja az adatok alkalmazás által definiált partíciókulcson alapuló automatikus particionálását. A logikai partíció olyan partíció, amely egyetlen partíciókulcs-érték összes adatát tárolja. Minden olyan dokumentum, amely ugyanazt az értéket használja a partíciókulcshoz, ugyanabban a logikai partícióban lesz elhelyezve. Az Azure Cosmos DB a partíciókulcs kivonata alapján osztja el az értékeket. A logikai partíciók maximális mérete 20 GB. Ezért a partíciókulcs kiválasztása fontos döntés a tervezéskor. Válasszon olyan tulajdonságot, amely számos értéket és hozzáférési mintát tartalmaz. További információ: Partíció és méretezés az Azure Cosmos DB.
Megjegyzés
Minden Azure Cosmos DB-adatbázis rendelkezik egy teljesítményszinttel, amely meghatározza a kapott erőforrások mennyiségét. A teljesítményszint kérelemegységhez (RU) sebességkorláthoz van társítva. A RU-sebességkorlát az adott gyűjtemény által kizárólagos használatra fenntartott és elérhető erőforrások mennyiségét határozza meg. A gyűjtemény költsége az adott gyűjteményhez kiválasztott teljesítményszinttől függ. Minél magasabb a teljesítményszint (és a RU-sebességkorlát), annál magasabb a díj. A gyűjtemények teljesítményszintjének módosításához használja az Azure Portalt. További információ: Kérelemegységek az Azure Cosmos DB.
Ha az Azure Cosmos DB által biztosított particionálási mechanizmus nem elegendő, előfordulhat, hogy az adatokat az alkalmazás szintjén kell szétszednie. A dokumentumgyűjtemények természetes mechanizmust biztosítanak az adatok egyetlen adatbázison belüli particionálásához. A horizontális skálázás megvalósításának legegyszerűbb módja, ha minden szegmenshez létrehoz egy gyűjteményt. A tárolók logikai erőforrások, és egy vagy több kiszolgálóra is kiterjedhetnek. A rögzített méretű tárolók maximális korlátja 20 GB és 10 000 RU/s átviteli sebesség. A korlátlan tárolóknak nincs maximális tárterületméretük, de meg kell adniuk egy partíciókulcsot. Az alkalmazás horizontális felosztásával az ügyfélalkalmazásnak a megfelelő szegmensre kell irányítania a kéréseket, általában a szegmenskulcsot meghatározó adatok bizonyos attribútumai alapján saját leképezési mechanizmus implementálásával.
Minden adatbázis egy Azure Cosmos DB-adatbázisfiók kontextusában jön létre. Egyetlen fiók több adatbázist is tartalmazhat, és meghatározza, hogy mely régiókban jönnek létre az adatbázisok. Minden fiók saját hozzáférés-vezérlést is kényszerít. Az Azure Cosmos DB-fiókokkal földrajzilag megkeresheti azokat a szegmenseket (adatbázisokon belüli gyűjteményeket), amelyek a hozzáférésükhöz szükséges felhasználókhoz közel vannak, és korlátozásokat kényszeríthet ki, hogy csak ezek a felhasználók csatlakozzanak hozzájuk.
Az adatok a NoSQL-hez készült Azure Cosmos DB-vel való particionálásának eldöntésekor vegye figyelembe a következő szempontokat:
Az Azure Cosmos DB-adatbázisokhoz elérhető erőforrásokra a fiókkvótakorlátozásai vonatkoznak. Minden adatbázis több gyűjteményt tartalmazhat, és minden gyűjtemény egy teljesítményszinttel van társítva, amely az adott gyűjtemény ru-sebességkorlátját (fenntartott átviteli sebességét) szabályozza. További információ: Azure-előfizetések és -szolgáltatások korlátai, kvótái és megkötései.
Minden dokumentumnak rendelkeznie kell egy attribútummal, amely a dokumentum egyedi azonosítására használható abban a gyűjteményben, amelyben aztalálható. Ez az attribútum eltér a szegmenskulcstól, amely meghatározza, hogy melyik gyűjtemény tartalmazza a dokumentumot. A gyűjtemények nagy számú dokumentumot tartalmazhatnak. Elméletileg csak a dokumentumazonosító maximális hossza korlátozza. A dokumentumazonosító legfeljebb 255 karakter hosszúságú lehet.
A dokumentumon végzett összes művelet egy tranzakció kontextusában történik. A tranzakciók hatóköre arra a gyűjteményre terjed ki, amelyben a dokumentum található. Ha egy művelet meghiúsul, az elvégzett munka vissza lesz állítva. Bár egy dokumentumot műveletnek vetnek alá, a végrehajtott módosítások pillanatképszintű elkülönítés alá esnek. Ez a mechanizmus garantálja, hogy ha például egy új dokumentum létrehozására irányuló kérés meghiúsul, egy másik felhasználó, aki egyszerre kérdezi le az adatbázist, nem fog látni egy részleges dokumentumot, amely ezután el lesz távolítva.
Adatbázis-lekérdezések hatóköre a gyűjtemény szintjén is. Egyetlen lekérdezés csak egy gyűjteményből tud adatokat lekérni. Ha több gyűjteményből kell adatokat lekérnie, egyenként kell lekérdeznie az egyes gyűjteményeket, és egyesítenie kell az eredményeket az alkalmazáskódban.
Az Azure Cosmos DB támogatja a programozható elemeket, amelyek a dokumentumok mellett a gyűjteményben is tárolhatók. Ezek közé tartoznak a tárolt eljárások, a felhasználó által definiált függvények és a (JavaScriptben írt) triggerek. Ezek az elemek bármely dokumentumhoz hozzáférhetnek ugyanabban a gyűjteményben. Ezenkívül ezek az elemek a környezeti tranzakció hatókörén belül futnak (olyan eseményindító esetén, amely egy dokumentumon végrehajtott létrehozási, törlési vagy csereművelet eredményeként aktiválódik), vagy egy új tranzakció elindításával (egy olyan tárolt eljárás esetén, amely explicit ügyfélkérés eredményeként fut). Ha egy programozható elem kódja kivételt jelez, a tranzakció vissza lesz állítva. Tárolt eljárásokat és eseményindítókat használhat a dokumentumok integritásának és konzisztenciájának fenntartásához, de ezeknek a dokumentumoknak ugyanabban a gyűjteményben kell lenniük.
Az adatbázisokban tárolni kívánt gyűjtemények valószínűleg nem lépik túl a gyűjtemények teljesítményszintjei által meghatározott átviteli sebességkorlátokat. További információ: Kérelemegységek az Azure Cosmos DB. Ha várhatóan eléri ezeket a korlátokat, fontolja meg a gyűjtemények különböző fiókokban lévő adatbázisok közötti felosztását, hogy csökkentse a gyűjteményenkénti terhelést.
Az Azure AI Search particionálása
Az adatok keresésének képessége gyakran a navigáció és a feltárás elsődleges módszere, amelyet számos webalkalmazás biztosít. Segít a felhasználóknak gyorsan megtalálni az erőforrásokat (például egy e-kereskedelmi alkalmazás termékeit) a keresési feltételek kombinációi alapján. Az AI Search szolgáltatás teljes szöveges keresési képességeket biztosít a webes tartalmakon keresztül, és olyan funkciókat tartalmaz, mint a típus-előre, a javasolt lekérdezések a közel egyezések alapján, valamint a részletes navigáció. További információ: Mi az AI-keresés?.
Az AI Search JSON-dokumentumként tárolja a kereshető tartalmakat egy adatbázisban. Olyan indexeket definiálhat, amelyek meghatározzák a dokumentumok kereshető mezőit, és ezeket a definíciókat megadják az AI Search számára. Amikor egy felhasználó keresési kérelmet küld, az AI Search a megfelelő indexekkel keresi meg az egyező elemeket.
A versengés csökkentése érdekében az AI Search által használt tároló 1, 2, 3, 4, 6 vagy 12 partícióra osztható, és minden partíció legfeljebb hatszor replikálható. A partíciók számának és a replikák számának szorzatát keresőegységnek (SU) nevezzük. Az AI Search egyetlen példánya legfeljebb 36 termékváltozatot tartalmazhat (egy 12 partícióval rendelkező adatbázis legfeljebb 3 replikát támogat).
A szolgáltatáshoz hozzárendelt összes su-ra kiszámlázzuk a számlát. A kereshető tartalom mennyiségének növekedésével vagy a keresési kérelmek számának növekedésével az AI Search egy meglévő példányához is hozzáadhat termékváltozatokat a további terhelés kezeléséhez. Maga az AI Search egyenletesen osztja el a dokumentumokat a partíciók között. A manuális particionálási stratégiák jelenleg nem támogatottak.
Minden partíció legfeljebb 15 millió dokumentumot tartalmazhat, vagy 300 GB tárterületet foglalhat el (amelyik kisebb). Legfeljebb 50 indexet hozhat létre. A szolgáltatás teljesítménye változó, és a dokumentumok összetettségétől, az elérhető indexektől és a hálózati késés hatásaitól függ. Átlagosan egyetlen replikának (1 SU) másodpercenként 15 lekérdezést (QPS) kell kezelnie, bár javasoljuk, hogy a saját adataival végezzen teljesítménymérést az átviteli sebesség pontosabb méréséhez. További információ: Szolgáltatáskorlátok az AI Search.
Megjegyzés
A kereshető dokumentumokban korlátozott adattípusokat tárolhat, beleértve a sztringeket, a logikai értékeket, a numerikus adatokat, a datetime-adatokat és néhány földrajzi adatot. További információt a Microsoft webhelyén támogatott adattípusok (AI Search) oldalon talál.
Korlátozottan szabályozhatja, hogy az AI Search hogyan particionálja az adatokat a szolgáltatás egyes példányaihoz. Globális környezetben azonban az alábbi stratégiák egyikével javíthatja a teljesítményt, és csökkentheti a késést és a versengést:
Hozzon létre egy AI Search-példányt minden földrajzi régióban, és győződjön meg arról, hogy az ügyfélalkalmazások a legközelebbi elérhető példányra irányulnak. Ez a stratégia megköveteli, hogy a kereshető tartalom minden frissítése időben replikálva legyen a szolgáltatás minden példányán.
Az AI Search két rétegének létrehozása:
- Minden régióban egy helyi szolgáltatás, amely az adott régió felhasználói által leggyakrabban elért adatokat tartalmazza. A felhasználók ide irányíthatják a kéréseket a gyors, de korlátozott eredmények érdekében.
- Egy globális szolgáltatás, amely az összes adatot magában foglalja. A felhasználók itt a lassabb, de teljesebb eredményekre vonatkozó kéréseket irányíthatják.
Ez a megközelítés akkor a legmegfelelőbb, ha a keresett adatok jelentős regionális eltérést mutatnak.
Az Azure Cache for Redis particionálása
Az Azure Cache for Redis egy megosztott gyorsítótárazási szolgáltatást biztosít a felhőben, amely a Redis kulcs-érték adattárán alapul. Ahogy a neve is mutatja, az Azure Cache for Redis gyorsítótárazási megoldásként szolgál. Csak átmeneti adatok tárolására használható, állandó adattárként nem. Az Azure Cache for Redist használó alkalmazásoknak továbbra is működnie kell, ha a gyorsítótár nem érhető el. Az Azure Cache for Redis támogatja az elsődleges/másodlagos replikációt a magas rendelkezésre állás biztosításához, de jelenleg a gyorsítótár maximális méretét 53 GB-ra korlátozza. Ha ennél több helyre van szüksége, további gyorsítótárakat kell létrehoznia. További információ: Azure Cache for Redis.
A Redis-adattár particionálásához fel kell osztani az adatokat a Redis szolgáltatás példányai között. Minden példány egyetlen partíciót alkot. Az Azure Cache for Redis egy homlokzat mögött absztrakciót végez a Redis-szolgáltatásokon, és nem teszi közvetlenül elérhetővé őket. A particionálás implementálásának legegyszerűbb módja több Azure Cache for Redis-példány létrehozása és az adatok szétosztása.
Minden adatelemet hozzárendelhet egy azonosítóhoz (partíciókulcshoz), amely meghatározza, hogy melyik gyorsítótár tárolja az adatelemet. Az ügyfélalkalmazás logikája ezt az azonosítót használhatja a kérések megfelelő partícióra való átirányításához. Ez a séma nagyon egyszerű, de ha a particionálási séma megváltozik (például ha további Azure Cache for Redis-példányok jönnek létre), előfordulhat, hogy újra kell konfigurálni az ügyfélalkalmazásokat.
A natív Redis (nem az Azure Cache for Redis) támogatja a kiszolgálóoldali particionálást a Redis-fürtözés alapján. Ebben a megközelítésben egy kivonatolási mechanizmus használatával egyenletesen oszthatja el az adatokat a kiszolgálók között. Minden Redis-kiszolgáló olyan metaadatokat tárol, amelyek a partíció által tárolt kivonatkulcsok tartományát ismertetik, valamint információkat tartalmaznak arról, hogy mely kivonatkulcsok találhatók a más kiszolgálók partícióin.
Az ügyfélalkalmazások egyszerűen kéréseket küldenek a részt vevő Redis-kiszolgálókra (valószínűleg a legközelebbire). A Redis-kiszolgáló megvizsgálja az ügyfélkérést. Ha helyileg megoldható, végrehajtja a kért műveletet. Ellenkező esetben továbbítja a kérést a megfelelő kiszolgálónak.
Ez a modell Redis-fürtözés használatával valósul meg, és részletesebben a Redis webhelyén található Redis-fürt oktatóanyagában. A Redis-fürtözés transzparens az ügyfélalkalmazások számára. További Redis-kiszolgálók is hozzáadhatók a fürthöz (és az adatok újraparticionálásra is használhatók) anélkül, hogy újrakonfigurálnia kellene az ügyfeleket.
Fontos
Az Azure Cache for Redis jelenleg csak prémium szinten támogatja a Redis-fürtözést.
A lap particionálás: az adatok több Redis-példány közötti felosztása, a Redis webhelyén további információt nyújt a particionálás Redis használatával történő implementálásáról. A szakasz többi része feltételezi, hogy ügyféloldali vagy proxyalapú particionálást valósít meg.
Vegye figyelembe a következő szempontokat, amikor eldönti, hogyan particionálhatja az adatokat az Azure Cache for Redis használatával:
Az Azure Cache for Redis nem állandó adattárként szolgál, ezért bármilyen particionálási sémát is implementál, az alkalmazás kódjának képesnek kell lennie adatokat lekérni olyan helyről, amely nem a gyorsítótár.
A gyakran használt adatokat ugyanabban a partícióban kell tárolni. A Redis egy hatékony kulcs-érték tároló, amely számos, nagymértékben optimalizált mechanizmust biztosít az adatok strukturálására. Ezek a mechanizmusok a következők lehetnek:
- Egyszerű sztringek (legfeljebb 512 MB hosszúságú bináris adatok)
- Összesítő típusok, például listák (amelyek üzenetsorként és veremként is működhetnek)
- Készletek (rendezett és rendezetlen)
- Kivonatok (amelyek csoportosíthatják a kapcsolódó mezőket, például az objektumok mezőit képviselő elemeket)
Az összesítési típusok lehetővé teszik, hogy számos kapcsolódó értéket társíthasson ugyanahhoz a kulccsal. A Redis-kulcsok a benne található adatelemek helyett egy listát, halmazt vagy kivonatot azonosítanak. Ezek a típusok mind elérhetők az Azure Cache for Redis szolgáltatásban, és a Redis webhelyén található Adattípusok oldal ismerteti őket. Egy olyan e-kereskedelmi rendszer részeként, amely nyomon követi az ügyfelek által leadott rendeléseket, az egyes ügyfelek adatait egy Redis-kivonatban tárolhatja, amely az ügyfélazonosító használatával van kulcsra vezérelten. Minden kivonat rendelkezhet az ügyfél rendelésazonosítóinak gyűjteményével. Egy külön Redis-készlet képes a rendelések tárolására, amely ismét kivonatként van strukturálva, és a rendelésazonosító használatával kulcsra van állítva. A 8. ábrán ez a struktúra látható. Vegye figyelembe, hogy a Redis nem implementálja a hivatkozási integritás semmilyen formáját, ezért a fejlesztő felelőssége, hogy fenntartsa az ügyfelek és a megrendelések közötti kapcsolatokat.
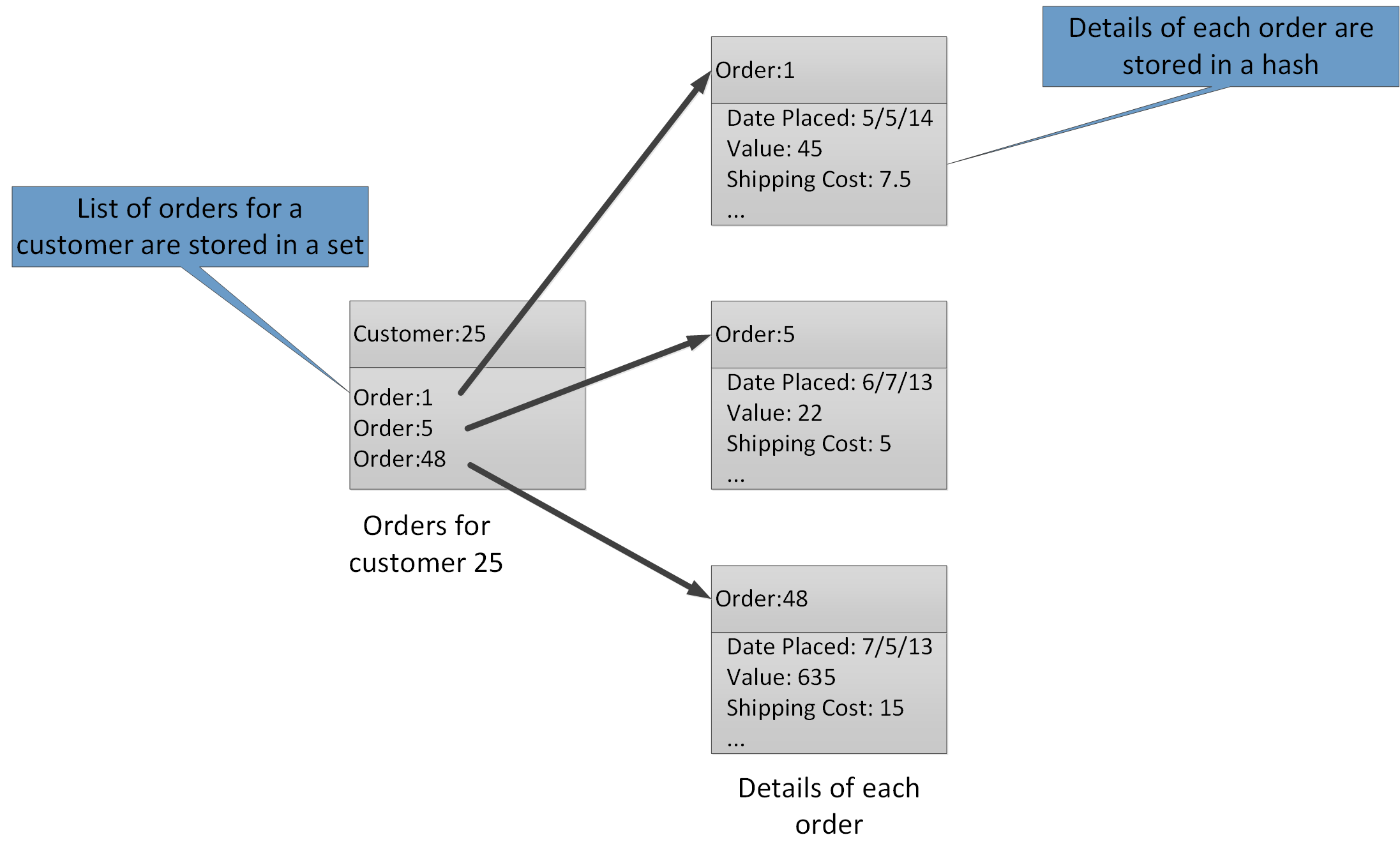
8. ábra. Javasolt struktúra a Redis Storage-ban az ügyfélrendelések és azok részleteinek rögzítéséhez.
Megjegyzés
A Redisben minden kulcs bináris adatérték (például Redis-sztringek), és legfeljebb 512 MB adatot tartalmazhat. Elméletileg a kulcsok szinte bármilyen információt tartalmazhatnak. Javasoljuk azonban, hogy konzisztens elnevezési konvenciót vezessen be az adattípust leíró és az entitást azonosító kulcsok esetében, de nem túl hosszú. Gyakori módszer a "entity_type:ID" űrlap kulcsainak használata. Használhatja például az "ügyfél:99" azonosítót egy 99-es azonosítójú ügyfél kulcsának jelzésére.
A függőleges particionálást úgy valósíthatja meg, hogy a kapcsolódó információkat különböző összesítésekben tárolja ugyanabban az adatbázisban. Egy e-kereskedelmi alkalmazásban például egy Redis-kivonatban tárolhatja a termékek általánosan elérhető adatait, a ritkábban használt részletes információkat pedig egy másikban. Mindkét kivonat ugyanazt a termékazonosítót használhatja a kulcs részeként. Használhatja például a "product: nn" (ahol nn a termékazonosító) a termékinformációkhoz, a részletes adatokhoz pedig a "product_details: nn" értéket. Ez a stratégia segíthet csökkenteni a legtöbb lekérdezés által valószínűleg lekért adatok mennyiségét.
Újraparticionálást végezhet a Redis-adattárakban, de ne feledje, hogy ez egy összetett és időigényes feladat. A Redis-fürtözés automatikusan újraparticionálódhat az adatok között, de ez a képesség nem érhető el az Azure Cache for Redisben. Ezért a particionálási séma tervezésekor próbáljon meg elegendő szabad helyet hagyni az egyes partíciókban, hogy az idővel várható adatnövekedést lehetővé tegye. Ne feledje azonban, hogy az Azure Cache for Redis célja az adatok ideiglenes gyorsítótárazása, és hogy a gyorsítótárban tárolt adatok élettartama korlátozott lehet élettartamként meghatározva élettartamként (TTL). Viszonylag változékony adatok esetén a TTL rövid lehet, a statikus adatok esetében azonban a TTL sokkal hosszabb lehet. Ne tároljon nagy mennyiségű hosszú élettartamú adatot a gyorsítótárban, ha az adatok mennyisége valószínűleg kitölti a gyorsítótárat. Megadhat egy kiürítési szabályzatot, amely miatt az Azure Cache for Redis eltávolítja az adatokat, ha a tárhely prémium szinten van.
Megjegyzés
Az Azure Cache for Redis használatakor a gyorsítótár maximális méretét (250 MB-tól 53 GB-ig) a megfelelő tarifacsomag kiválasztásával adhatja meg. Az Azure Cache for Redis létrehozása után azonban nem növelheti (vagy csökkentheti) a méretét.
A Redis-kötegek és -tranzakciók nem terjedhetnek ki több kapcsolatra, ezért a köteg vagy tranzakció által érintett összes adatot ugyanabban az adatbázisban (szegmensben) kell tartani.
Megjegyzés
A Redis-tranzakciók műveleteinek sorozata nem feltétlenül atomi. A tranzakciót alkotó parancsokat a rendszer a futtatás előtt ellenőrzi és várólistára állítja. Ha ebben a fázisban hiba történik, a rendszer a teljes üzenetsort elveti. A tranzakció sikeres elküldése után azonban az üzenetsorba helyezett parancsok egymás után futnak. Ha valamelyik parancs meghiúsul, csak az a parancs fog futni. A rendszer végrehajtja az üzenetsor összes korábbi és további parancsát. További információ: Tranzakciók lap a Redis webhelyén.
A Redis korlátozott számú atomműveletet támogat. Az ilyen típusú műveletek egyetlen, több kulcsot és értéket támogató művelete az MGET és az MSET művelet. Az MGET-műveletek egy adott kulcslistához tartozó értékgyűjteményt ad vissza, az MSET-műveletek pedig egy adott kulcslista értékeinek gyűjteményét tárolják. Ha ezeket a műveleteket kell használnia, az MSET- és MGET-parancsok által hivatkozott kulcs-érték párokat ugyanabban az adatbázisban kell tárolni.
Az Azure Service Fabric particionálása
Az Azure Service Fabric egy mikroszolgáltatási platform, amely futtatókörnyezetet biztosít a felhőben elosztott alkalmazások számára. A Service Fabric támogatja a .NET-vendég végrehajtható fájlokat, állapotalapú és állapot nélküli szolgáltatásokat és tárolókat. Az állapotalapú szolgáltatások megbízható gyűjteményt biztosítanak, az adatok a Service Fabric-fürtön belüli kulcs-érték gyűjteményben való állandó tárolásához. A kulcsok megbízható gyűjteményben való particionálásának stratégiáiról az Azure Service Fabric megbízható gyűjteményekre vonatkozó irányelvek és javaslatokcímű témakörben talál további információt.
Következő lépések
Azure Service Fabric áttekintése az Azure Service Fabric bemutatása.
Partition Service Fabric megbízható szolgáltatások további információt nyújtanak az Azure Service Fabric megbízható szolgáltatásairól.
Az Azure Event Hubs particionálása
Azure Event Hubs nagy léptékű adatstreamelésre lett tervezve, a particionálás pedig a szolgáltatásba van beépítve a horizontális skálázás engedélyezéséhez. Minden fogyasztó csak az üzenetstream egy adott partícióját olvassa be.
Az esemény-közzétevő csak a partíciókulcsot ismeri, azt a partíciót nem, amelyre az esemény közzé lesz téve. A kulcs és a partíció szétválasztása révén a küldőnek nem szükséges behatóan ismernie az alárendelt feldolgozási folyamatokat. (Az eseményeket közvetlenül is elküldheti egy adott partícióra, de általában ez nem ajánlott.)
A partíciók számának kiválasztásakor fontolja meg a hosszú távú skálázást. Az eseményközpont létrehozása után nem módosíthatja a partíciók számát.
Következő lépések
További információ a partíciók Event Hubsban való használatáról: Mi az Event Hubs?.
A rendelkezésre állás és a konzisztencia közötti kompromisszumokkal kapcsolatos megfontolásokért lásd Event Hubs-rendelkezésre állását és konzisztenciáját.