A szervezetek gyakori problémája, hogy hogyan gyűjthetnek adatokat több forrásból, több formátumban. Ezután át kell helyeznie egy vagy több adattárba. Előfordulhat, hogy a cél nem ugyanaz az adattártípus, mint a forrás. A formátum gyakran eltérő, vagy az adatokat formázni vagy megtisztítani kell, mielőtt betöltené őket a végső célhelyre.
Az évek során különböző eszközöket, szolgáltatásokat és folyamatokat fejlesztettek ki, amelyek segítenek a kihívások megoldásában. A használt folyamattól függetlenül gyakori szükség van a munka koordinálására és bizonyos szintű adatátalakítás alkalmazására az adatfolyamon belül. Az alábbi szakaszok kiemelik a feladatok végrehajtásához használt gyakori módszereket.
Kinyerési, átalakítási és betöltési (ETL) folyamat
A kinyerés, átalakítás és betöltés (ETL) egy olyan adatfolyam, amely különböző forrásokból gyűjt adatokat. Ezután üzleti szabályok szerint alakítja át az adatokat, és betölti az adatokat egy céladattárba. Az ETL-ben az átalakítási munka egy speciális motorban történik, és gyakran átmeneti táblák használatával ideiglenesen tárolja az adatokat az átalakítás során, és végül betöltődik a célhelyre.
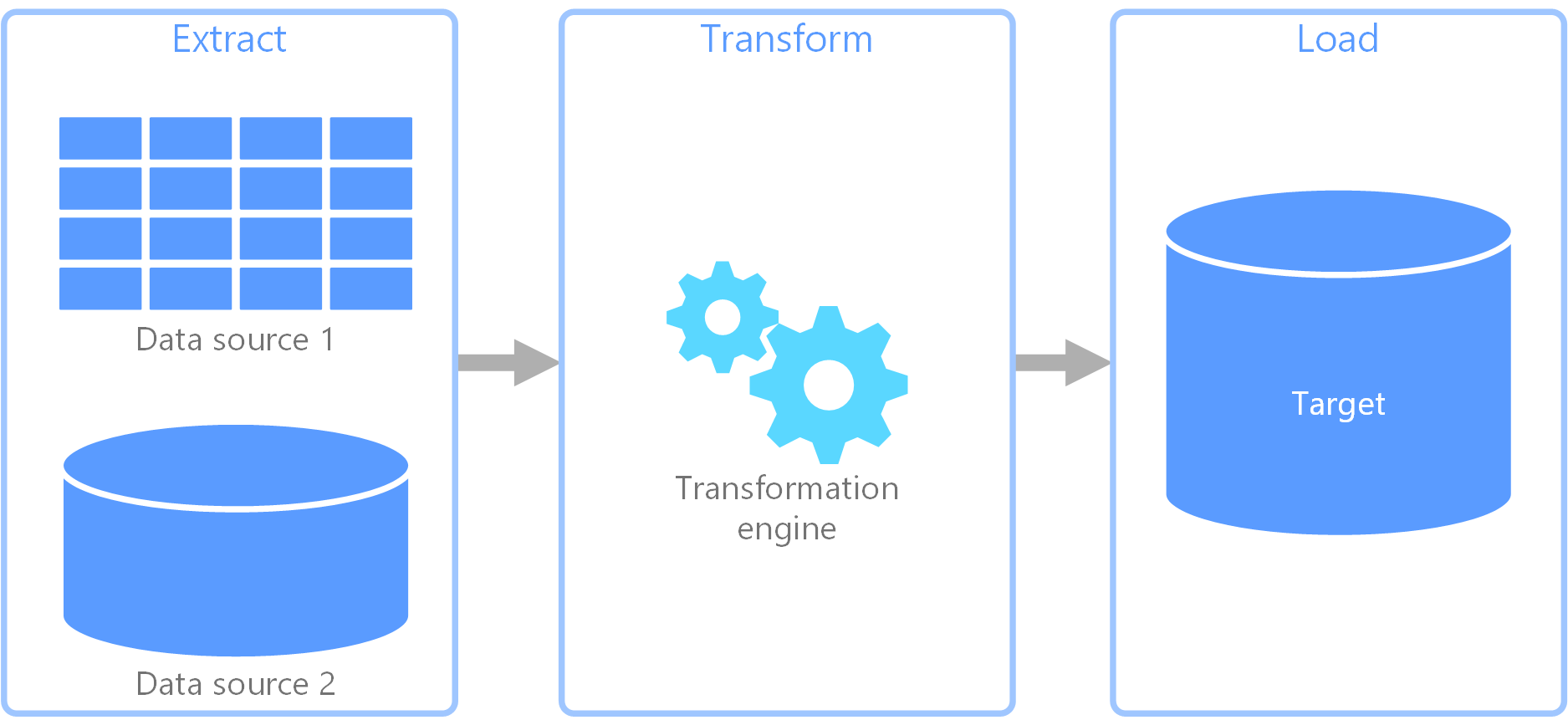
Az adatátalakítás általában különböző műveleteket foglal magában, például szűrést, rendezést, összesítést, adatok összekapcsolását, adattisztítást, deduplikációt és adat-érvényesítést.
A három ETL-fázis gyakran párhuzamosan fut, hogy időt takarítson meg. Az adatok kinyerése közben például egy átalakítási folyamat dolgozhat a már fogadott adatokon, és előkészítheti őket a betöltésre, és a betöltési folyamat elkezdheti az előkészített adatokon végzett munkát ahelyett, hogy a teljes kinyerési folyamat befejezésére várna.
Kapcsolódó Azure-szolgáltatás:
Other tools:
Kinyerés, betöltés és átalakítás (ETL)
A kinyerés, a betöltés és az átalakítás (ELT) csak abban különbözik az ETL-től, ahol az átalakítás végbemegy. Az ELT-folyamatban az átalakítás a céladattárban történik. Külön átalakítási motor használata helyett a céladattár feldolgozási képességeit használják az adatok átalakítására. Ez leegyszerűsíti az architektúrát azáltal, hogy eltávolítja az átalakítási motort a folyamatból. Ennek a megközelítésnek egy másik előnye, hogy a céladattár skálázása az ELT-folyamat teljesítményét is skálázza. Az ELT azonban csak akkor működik jól, ha a célrendszer elég hatékony az adatok hatékony átalakításához.
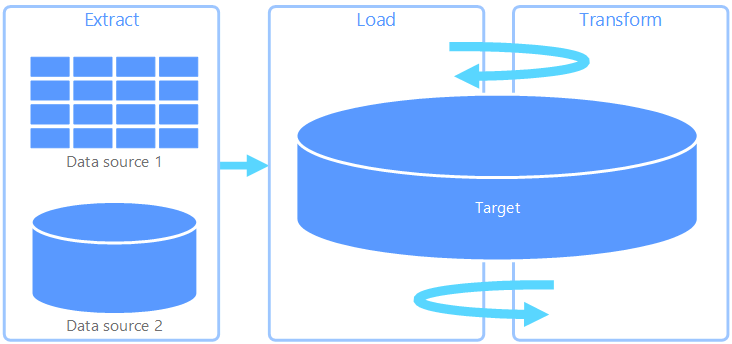
Az ELT tipikus használati esetei a big data-tartományba tartoznak. Első lépésként például az összes forrásadatot egy skálázható tárolóban lévő, egybesimított fájlokba nyeri ki, például Hadoop elosztott fájlrendszert, Azure-blobtárolót vagy 2. generációs Azure Data Lake-t (vagy kombinációt). A forrásadatok lekérdezéséhez olyan technológiák használhatók, mint a Spark, a Hive vagy a Polybase. Az ELT lényege, hogy az átalakítás végrehajtásához használt adattár ugyanaz az adattár, ahol az adatok végső felhasználása történik. Ez az adattár közvetlenül a méretezhető tárolóból olvassa be az adatokat ahelyett, hogy saját védett tárolójába töltenél be. Ez a módszer kihagyja az ETL-ben található adatmásolási lépést, amely gyakran időigényes művelet lehet nagy adathalmazok esetében.
A gyakorlatban a céladattár egy Hadoop-fürtöt (Hive vagy Spark használatával) vagy dedikált SQL-készleteket használó adattárház az Azure Synapse Analyticsben. Általánosságban elmondható, hogy a séma felül van kapcsolva az egybesimított fájladatokon lekérdezéskor, és táblaként van tárolva, így az adatok lekérdezhetők, mint az adattár többi táblája. Ezeket azért nevezzük külső tábláknak, mert az adatok nem az adattár által felügyelt tárolóban találhatók, hanem néhány külső skálázható tárolóban, például az Azure Data Lake Store-ban vagy az Azure Blob Storage-ban.
Az adattár csak az adatok sémáját kezeli, és a sémát olvasásra alkalmazza. Egy Hive-t használó Hadoop-fürt például egy Hive-táblát ír le, ahol az adatforrás gyakorlatilag egy HDFS-fájlkészlet elérési útja. Az Azure Synapse-ban a PolyBase ugyanezt az eredményt érheti el – egy táblát hoz létre az adatbázison kívül tárolt adatokhoz. A forrásadatok betöltése után a külső táblákban található adatok az adattár képességeivel feldolgozhatók. Big Data-forgatókönyvekben ez azt jelenti, hogy az adattárnak képesnek kell lennie nagy mértékben párhuzamos feldolgozásra (MPP), amely kisebb adattömbökre bontja az adatokat, és párhuzamosan osztja el az adattömbök feldolgozását több csomópont között.
Az ELT-folyamat utolsó fázisa általában a forrásadatok végleges formátummá alakítása, amely hatékonyabb a támogatandó lekérdezések típusainál. Előfordulhat például, hogy az adatok particionálásra kerülnek. Emellett az ELT olyan optimalizált tárolási formátumokat is használhat, mint a Parquet, amely oszlopos módon tárolja a sororientált adatokat, és optimalizált indexelést biztosít.
Kapcsolódó Azure-szolgáltatás:
- Dedikált SQL-készletek az Azure Synapse Analyticsben
- Kiszolgáló nélküli SQL-készletek az Azure Synapse Analyticsben
- HDInsight és Hive
- Azure Data Factory
- Datamarts a Power BI-ban
Other tools:
Adatfolyam és vezérlési folyamat
Az adatfolyamok kontextusában a vezérlési folyamat biztosítja a feladatok egy csoportjának rendezett feldolgozását. A feladatok megfelelő feldolgozási sorrendjének kényszerítéséhez a rendszer elsőbbséget élvező korlátozásokat használ. Ezeket a kényszereket egy munkafolyamat-diagram összekötőinek tekintheti, ahogyan az az alábbi képen látható. Minden tevékenységnek van egy eredménye, például a siker, a hiba vagy a befejezés. Az ezt követő tevékenységek csak akkor kezdeményezik a feldolgozást, ha az elődje a fenti eredmények valamelyikével befejeződött.
A vezérlőfolyamatok feladatként hajtják végre az adatfolyamokat. Egy adatfolyam-feladatban az adatok kinyerhetők egy forrásból, átalakíthatók vagy betölthetők egy adattárba. Egy adatfolyam-tevékenység kimenete lehet a következő adatfolyam-tevékenység bemenete, és az adatfolyamok párhuzamosan is futtathatók. A vezérlőfolyamatokkal ellentétben nem adhat meg korlátozásokat az adatfolyam tevékenységei között. Hozzáadhat azonban egy adatmegjelenítőt az egyes tevékenységek által feldolgozott adatok megfigyeléséhez.
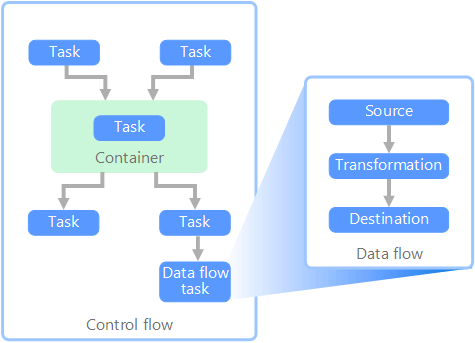
A fenti ábrán több tevékenység is szerepel a vezérlőfolyamatban, amelyek közül az egyik egy adatfolyam-feladat. Az egyik feladat egy tárolóba van ágyazva. A tárolók a feladatok struktúrájának biztosítására használhatók, és munkaegységet biztosítanak. Ilyen például a gyűjtemény ismétlődő elemeinek, például a mappában lévő fájloknak vagy az adatbázis-utasításoknak az ismétlése.
Kapcsolódó Azure-szolgáltatás:
Other tools:
Technológiai lehetőségek
- Online tranzakciófeldolgozási (OLTP-) adattárak
- Online elemzési feldolgozási (OLAP-) adattárak
- Adattárházak
- Folyamat vezénylése
Közreműködők
Ezt a cikket a Microsoft tartja karban. Eredetileg a következő közreműködők írták.
Fő szerző:
- Raunak Jhawar | Vezető felhőmérnök
- Zoiner Tejada | vezérigazgató és tervező
További lépések
- Adatok integrálása az Azure Data Factory vagy az Azure Synapse Pipeline használatával
- Az Azure Synapse Analytics bemutatása
- Adatáthelyezés és -átalakítás vezénylése az Azure Data Factoryben vagy az Azure Synapse Pipeline-ban
Kapcsolódó erőforrások
Az alábbi referenciaarchitektúrák a végpontok közötti ELT-folyamatokat mutatják be az Azure-ban: