Társított szolgáltatások az Azure Data Factoryben és az Azure Synapse Analyticsben
A következőkre vonatkozik:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Fontos
Az Azure Machine Learning Studio (klasszikus) támogatása 2024. augusztus 31-én megszűnik. Javasoljuk, hogy erre a dátumra váltson az Azure Machine Learningre .
2021. december 1-től nem hozhat létre új Machine Learning Studio-erőforrásokat (klasszikus) (munkaterület- és webszolgáltatás-csomagot). 2024. augusztus 31-ig továbbra is használhatja a Machine Learning Studio (klasszikus) kísérleteket és webszolgáltatásokat. További információk:
- Migrálás az Azure Machine Learningbe a Machine Learning Studióból (klasszikus)
- Mi az Azure Machine Learning?
A Machine Learning Studio (klasszikus) dokumentációja kivezetés alatt áll, és előfordulhat, hogy a jövőben nem frissül.
Ez a cikk segítséget nyújt az Azure Data Factory és az Azure Synapse Analytics folyamatainak és tevékenységeinek megismerésében, valamint az adatáthelyezési és adatfeldolgozási forgatókönyvek végpontok közötti adatvezérelt munkafolyamatainak létrehozásában.
Áttekintés
A Data Factory vagy a Synapse-munkaterület egy vagy több folyamatból áll. A folyamatok olyan tevékenységek logikus csoportosításai, amelyek együttesen vesznek részt egy feladat végrehajtásában. Például a folyamat tartalmazhat egy olyan tevékenységkészletet, amely naplóadatokat tölt be és töröl, majd egy leképezési adatfolyamot futtat a naplóadatok elemzéséhez. A folyamatok lehetővé teszik, hogy a tevékenységeket egy készletben kezelje, ne pedig külön-külön. Magát a folyamatot helyezheti üzembe és ütemezheti az önálló tevékenységek helyett.
A folyamat tevékenységei meghatározzák az adatokon végrehajtandó műveleteket. A másolási tevékenység használatával például egy SQL Serverből egy Azure Blob Storage-tárolóba másolhatja az adatokat. Ezután adatfolyam-tevékenység vagy Databricks Notebook-tevékenység használatával feldolgozhatja és átalakíthatja az adatokat a blobtárolóból egy Azure Synapse Analytics-készletbe, amelyre üzletiintelligencia-jelentési megoldások épülnek.
Az Azure Data Factory és az Azure Synapse Analytics három tevékenységcsoportot tartalmaz: adatáthelyezési tevékenységeket, adatátalakítási tevékenységeket és vezérlési tevékenységeket. Minden tevékenység nulla vagy több bemeneti adatkészletet képes fogadni, és egy vagy több kimeneti adatkészletet képes előállítani. Az alábbi ábra a folyamat, a tevékenység és az adatkészlet közötti kapcsolatot mutatja be:

A bemeneti adatkészlet a folyamat egy tevékenységének bemenetét, a kimeneti adatkészlet pedig a tevékenység kimenetét jelöli. Az adatkészletek adatokat határoznak meg a különböző adattárakban, például táblákban, fájlokban, mappákban és dokumentumokban. Az adatkészlet létrehozását követően használhatja azt egy folyamat tevékenységei esetében. Az adatkészletek lehetnek például egy másolási tevékenység vagy egy HDInsightHive-tevékenység be- vagy kimeneti adatkészletei. Az adatkészletekről további információkat Az Azure Data Factory adatkészletei cikkben talál.
Feljegyzés
A folyamatonként legfeljebb 80 tevékenység alapértelmezett helyreállítható korlátja van, amely magában foglalja a tárolók belső tevékenységeit is.
Adattovábbítási tevékenységek
A Data Factory másolási tevékenysége adatokat másol egy forrásadattárból egy fogadó adattárba. A Data Factory a jelen szakaszban található táblában felsorolt adattárakat támogatja. Az adatok bármilyen forrásból bármilyen fogadóba másolhatók.
További információkat a Másolási tevékenység áttekintése cikkben talál.
Az adattárra kattintva megtudhatja, hogy az adott tárolóba, illetve tárolóból hogyan másolhat adatokat.
Feljegyzés
Az előzetes verzió jelzéssel ellátott összekötőket kipróbálhatja, és visszajelzést küldhet róluk. Ha függőséget szeretne felvenni a megoldásában található előzetes verziójú összekötőkre, lépjen kapcsolatba az Azure-támogatással.
Adatátalakítási tevékenységek
Az Azure Data Factory és az Azure Synapse Analytics az alábbi átalakítási tevékenységeket támogatja, amelyek egyenként vagy más tevékenységgel összeláncolt módon vehetők fel.
További információkért tekintse meg az adatátalakítási tevékenységekről szóló cikket.
| Adatátalakítási tevékenység | Számítási környezet |
|---|---|
| Adatfolyam | Az Azure Data Factory által felügyelt Apache Spark-fürtök |
| Azure-függvény | Azure Functions |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Hadoop Streaming | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| ML Studio (klasszikus) tevékenységek: Batch-végrehajtás és erőforrás frissítése | Azure VM |
| Tárolt eljárás | Azure SQL, Azure Synapse Analytics vagy SQL Server |
| U-SQL | Azure Data Lake Analytics |
| Egyéni tevékenység | Azure Batch |
| Databricks-jegyzetfüzet | Azure Databricks |
| Databricks Jar-tevékenység | Azure Databricks |
| Databricks Python-tevékenység | Azure Databricks |
| Synapse Notebook-tevékenység | Azure Synapse Analytics |
Vezérlésfolyam-tevékenységek
A támogatott átvitelvezérlési tevékenységek a következők:
| Vezérlési tevékenység | Leírás |
|---|---|
| Változó hozzáfűzése | Adjon hozzá egy értéket egy meglévő tömbváltozóhoz. |
| Folyamat végrehajtása | A Folyamat végrehajtása tevékenység lehetővé teszi, hogy egy Data Factory- vagy Synapse-folyamat meghívjon egy másik folyamatot. |
| Szűrő | Szűrőkifejezés alkalmazása bemeneti tömbre |
| Minden egyes | A ForEach tevékenység ismétlődő átvitelvezérlést határoz meg a folyamatban. Ez a tevékenység egy gyűjtemény megismétlésére, valamint egy megadott ciklustevékenység végrehajtására szolgál. E tevékenység ciklusos megvalósítása hasonló a Foreach ciklusos szerkezetéhez a programozási nyelvek esetében. |
| Metaadatok lekérése | A GetMetadata-tevékenység a Data Factoryben vagy a Synapse-folyamatban lévő adatok metaadatainak lekérésére használható. |
| If Condition tevékenység | Az If Condition tevékenység igaz vagy hamis értéket visszaadó feltételek alapján történő elágaztatásra használható. Az If Condition tevékenység ugyanazokat a funkciókat biztosítja, mint a programnyelvek if utasítása. Kiértékeli a tevékenységek egy készletét, amikor a feltétel kiértékeli azt true , és egy másik tevékenységkészletet, amikor a feltétel kiértékelése a következőre történik: false. |
| Keresési tevékenység | A Keresési tevékenység segítségével bármely külső forrásból kiolvashat vagy megkereshet egy rekordot, táblanevet vagy értéket. Erre a kimenetre a későbbi tevékenységek is hivatkozhatnak. |
| Változó beállítása | Meglévő változó értékének beállítása. |
| Until tevékenység | A Do-Until ciklus megvalósítása hasonló a programozási nyelvek Do-Until ciklusos szerkezetéhez. Egy tevékenységkészletet futtat le ciklusosan addig, amíg a tevékenységhez rendelt feltétel igaz értéket nem ad vissza. Megadhat időtúllépési értéket a tevékenység befejezéséig. |
| Érvényesítési tevékenység | Győződjön meg arról, hogy egy folyamat csak akkor folytatja a végrehajtást, ha létezik referenciaadatkészlet, megfelel egy megadott feltételnek, vagy időtúllépés történt. |
| Wait tevékenység | Ha várakozási tevékenységet használ egy folyamatban, a folyamat a megadott időre vár, mielőtt folytatná a további tevékenységek végrehajtását. |
| Webes tevékenység | A webes tevékenységgel egyéni REST-végpontot hívhat meg egy folyamatból. Az adatkészleteket és a társított szolgáltatásokat továbbíthatja a tevékenység számára felhasználásra vagy elérés céljára. |
| Webhook tevékenység | A webhook-tevékenység használatával hívjon meg egy végpontot, és adjon át egy visszahívási URL-címet. A folyamatfuttatás megvárja a visszahívás meghívását, mielőtt továbblép a következő tevékenységre. |
Folyamat létrehozása felhasználói felülettel
Új folyamat létrehozásához lépjen a Data Factory Studióban a Szerző lapra (amelyet a ceruza ikon jelöl), majd kattintson a pluszjelre, és válassza a Folyamat lehetőséget a menüből, majd ismét a Folyamat parancsot az almenüből.
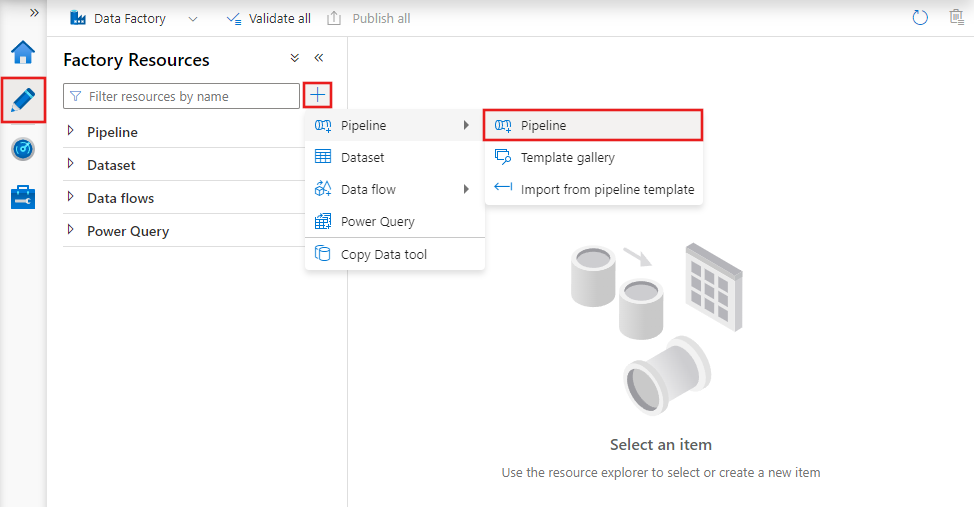
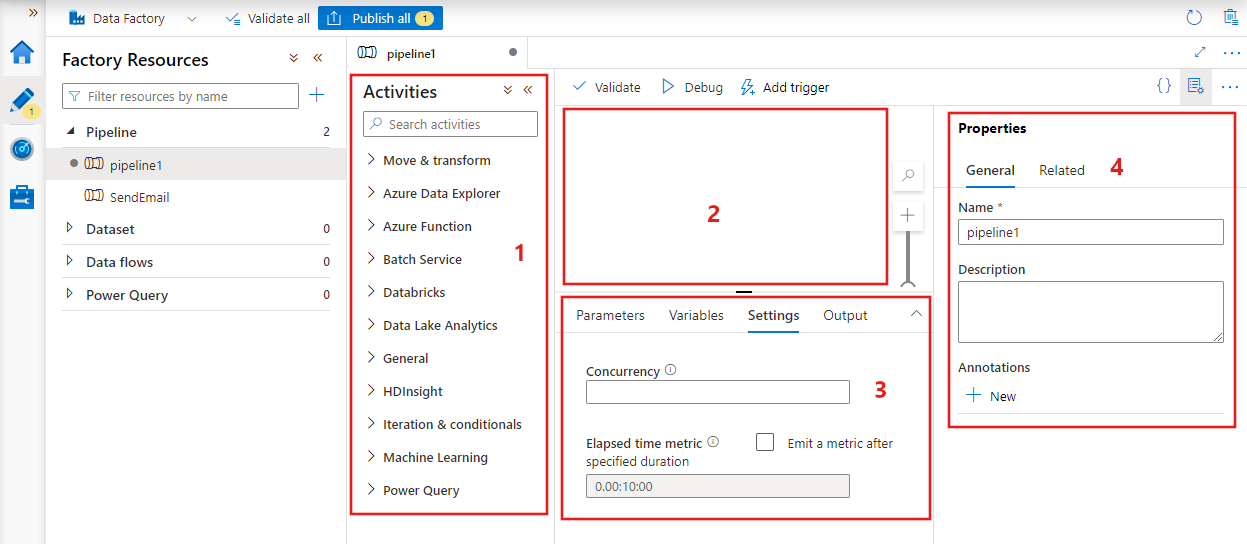
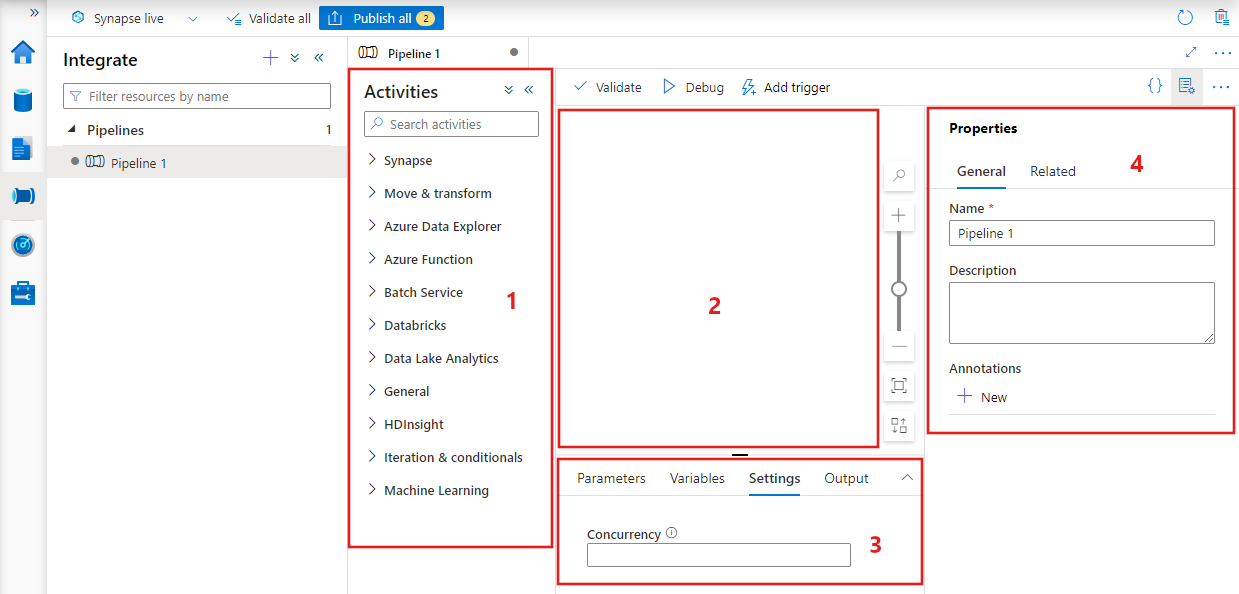
A Data Factory megjeleníti a folyamatszerkesztőt, ahol megtalálja a következőt:
- A folyamaton belül használható összes tevékenység.
- A folyamatszerkesztő vászna, ahol a tevékenységek megjelennek a folyamathoz való hozzáadáskor.
- A folyamatkonfigurációk panel, beleértve a paramétereket, a változókat, az általános beállításokat és a kimenetet.
- A folyamat tulajdonságai panel, ahol konfigurálható a folyamat neve, opcionális leírása és széljegyzetei. Ez a panel az adat-előállító folyamatához kapcsolódó elemeket is megjeleníti.
JSON csővezeték
Egy folyamat JSON-formátumban való meghatározása a következő módon történik:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Címke | Leírás | Típus | Szükséges |
|---|---|---|---|
| név | A folyamat neve. Adjon meg egy, a folyamat által végrehajtandó műveletet jelölő nevet.
|
Sztring | Igen |
| leírás | Adjon meg egy, az adott folyamat alkalmazását leíró szöveget. | Sztring | Nem |
| tevékenységek | A tevékenységek szakaszon belül egy vagy több tevékenység is meghatározható. A tevékenységek JSON-elemeiről részletes információkat a Tevékenység JSON-fájlja szakaszban talál. | Tömb | Igen |
| parameters | Az adott folyamat paraméterek szakaszában egy vagy több paraméter adható meg, így a folyamat rugalmasan újrafelhasználható. | Lista | Nem |
| Konkurencia | A folyamat egyidejű futtatásának maximális száma. Alapértelmezés szerint nincs maximális érték. Ha eléri az egyidejűségi korlátot, további folyamatfuttatások lesznek várólistán, amíg a korábbiak be nem fejeződnek | Szám | Nem |
| Széljegyzetek | A folyamathoz társított címkék listája | Tömb | Nem |
Tevékenység JSON-fájlja
A tevékenységek szakaszon belül egy vagy több tevékenység is meghatározható. A következő két fő tevékenységtípust különböztetjük meg: végrehajtási és vezérlési tevékenységek.
Végrehajtási tevékenységek
A végrehajtási tevékenységek közé az adatáthelyezési és az adatátalakítási tevékenységek tartoznak. Ezek a következő felső szintű struktúrával rendelkeznek:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
Az alábbi táblában a tevékenység JSON-definíciójában lévő tulajdonságok szerepelnek:
| Címke | Leírás | Szükséges |
|---|---|---|
| név | A tevékenység neve. Adjon meg egy, a tevékenység által végrehajtandó műveletet jelölő nevet.
|
Igen |
| leírás | Az adott tevékenységet vagy annak alkalmazását leíró szöveg | Igen |
| típus | A tevékenység típusa. A különböző tevékenységtípusokkal kapcsolatban lásd az adattovábbítási tevékenységeket, az adat-átalakítási tevékenységeket és a vezérlési tevékenységeket. | Igen |
| linkedServiceName | A tevékenység által használt társított szolgáltatás neve. Előfordulhat, hogy egy tevékenységhez meg kell adnia azt a társított szolgáltatást, amely a szükséges számítási környezethez kapcsolódik. |
Igen a HDInsight-tevékenységhez, az ML Studio (klasszikus) Kötegelt pontozási tevékenységhez és a Tárolt eljárás tevékenységhez. Minden egyéb esetében: nem |
| typeProperties | A typeProperties szakasz tulajdonságai az egyes tevékenységtípusoktól függenek. Az adott tevékenység típustulajdonságainak megtekintéséhez kattintson az előző szakaszban szereplő tevékenységhivatkozásokra. | Nem |
| szabályzat | Olyan szabályzatok, amelyek az adott tevékenység futásidejű viselkedését befolyásolják. Ez a tulajdonság időtúllépést és újrapróbálkozásos viselkedést tartalmaz. Ha nincs megadva, az alapértelmezett értékeket használja a rendszer. További információkat a Tevékenységszabályzat szakaszban talál. | Nem |
| dependsOn | Ez a tulajdonság a tevékenységfüggőségek, valamint az egymást követő tevékenységek függőségeinek meghatározására szolgál. További információért lásd: Tevékenységfüggőség | Nem |
Tevékenység-házirend
A szabályzatok hatással vannak egy tevékenység futásidejű viselkedésére, és konfigurációs beállításokat adnak meg. A tevékenységszabályzatok kizárólag végrehajtási tevékenységek esetében állnak rendelkezésre.
Tevékenységszabályzat JSON-definíciója
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| JSON-név | Leírás | Megengedett értékek | Kötelező |
|---|---|---|---|
| timeout | Megadja a futtatni kívánt tevékenység időtúllépését. | Időtartomány | Szám Az alapértelmezett időtúllépés 12 óra, minimum 10 perc. |
| retry | Újrapróbálkozási kísérletek maximális száma | Egész | Szám Az alapértelmezett érték: 0 |
| retryIntervalInSeconds | Az újrapróbálkozási kísérletek közötti késleltetés, másodpercben | Egész | Szám Az alapértelmezett érték 30 másodperc |
| secureOutput | Ha igaz értékre van állítva, a tevékenység kimenete biztonságosnak minősül, és nincs naplózva monitorozásra. | Logikai | Szám Az alapértelmezett érték a false (hamis). |
Vezérlési tevékenység
A vezérlési tevékenységek az alábbi felső szintű struktúrával rendelkeznek:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Címke | Leírás | Szükséges |
|---|---|---|
| név | A tevékenység neve. Adjon meg egy, a tevékenység által végrehajtandó műveletet jelölő nevet.
|
Igen |
| leírás | Az adott tevékenységet vagy annak alkalmazását leíró szöveg | Igen |
| típus | A tevékenység típusa. A különböző tevékenységtípusokkal kapcsolatban lásd az adattovábbítási tevékenységeket, az adat-átalakítási tevékenységeket és a vezérlési tevékenységeket. | Igen |
| typeProperties | A typeProperties szakasz tulajdonságai az egyes tevékenységtípusoktól függenek. Az adott tevékenység típustulajdonságainak megtekintéséhez kattintson az előző szakaszban szereplő tevékenységhivatkozásokra. | Nem |
| dependsOn | Ez a tulajdonság a tevékenységfüggőség, valamint az egymást követő tevékenységek függőségeinek meghatározására szolgál. További információért lásd: tevékenységfüggőség. | Nem |
Tevékenységfüggőség
A tevékenységfüggőség határozza meg, hogy a későbbi tevékenységek hogyan függenek a korábbi tevékenységektől, és meghatározza a következő tevékenység végrehajtásának feltételét. Egy adott tevékenység egy vagy több korábbi, eltérő függőségi feltétellel rendelkező tevékenységtől is függhet.
A különböző függőségi feltételek a következők: Sikeres, Sikertelen, Kihagyva, Befejezve.
Ha például egy folyamat rendelkezik A tevékenységgel –> B tevékenységgel, a különböző forgatókönyvek a következők lehetnek:
- A B tevékenység sikeres függőségi feltétellel rendelkezik az A tevékenység esetében: a B tevékenység csak akkor fut le, ha az A tevékenység végállapota sikeres
- A B tevékenység sikertelen függőségi feltétellel rendelkezik az A tevékenység esetében: a B tevékenység csak akkor fut le, ha az A tevékenység végállapota sikertelen
- A B tevékenység befejezve függőségi feltétellel rendelkezik az A tevékenység esetében: a B tevékenység akkor fut le, ha az A tevékenység végállapota sikeres vagy sikertelen
- A B tevékenységnek függőségi feltétele van az A tevékenységhez kihagyva: A B tevékenység akkor fut, ha az A tevékenység végleges állapota kihagyva. A kihagyás az X tevékenység – Y tevékenység –>> Z tevékenység forgatókönyvében történik, ahol minden tevékenység csak akkor fut, ha az előző tevékenység sikeres. Ha az X tevékenység sikertelen, akkor az Y tevékenység "Kihagyva" állapotú, mert soha nem hajtja végre. Hasonlóképpen a Z tevékenység "Kihagyva" állapotú is.
Példa: a 2. tevékenység az 1. tevékenység sikerességétől függ
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Minta másolási folyamat
Az alábbi mintafolyamat tevékenységek szakaszában egyetlen Másolás típusú tevékenység található. Ebben a mintában a másolási tevékenység adatokat másol egy Azure Blob Storage-ból egy Azure SQL Database-adatbázisba.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Vegye figyelembe az alábbiakat:
- A tevékenységek szakaszban csak egyetlen tevékenység van, amelynek a típusaCopy értékre van beállítva.
- A tevékenység bemenetének beállítása InputDataset, a kimeneté pedig OutputDataset. Az adatkészletek JSON-fáljban történő meghatározását lásd az Adatkészletek cikket.
- A typeProperties szakaszban forrástípusként a BlobSource, fogadótípusként pedig az SqlSink érték van megadva. Az adattovábbítási tevékenységek szakaszban kattintson a forrásként vagy fogadóként használni kívánt adattárra, hogy további információkhoz jusson az adott adattár esetén a kifelé vagy befelé irányuló adatáthelyezési lehetőségekről.
A folyamat létrehozásának teljes útmutatóját a Data Factory létrehozása című rövid útmutatóban találja.
Minta átalakítási folyamat
Az alábbi mintafolyamat tevékenységek szakaszában egyetlen HDInsightHive típusú tevékenység található. Ebben a mintában a HDInsight Hive-tevékenység egy Azure blobtárolóból származó adatokat alakít át egy Hive-szkriptfájl Azure HDInsight Hadoop-fürtön történő futtatásával.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Vegye figyelembe az alábbiakat:
- A tevékenységek szakaszban csak egyetlen tevékenység van, amelynek a típusaHDInsightHive értékre van beállítva.
- A Hive-szkriptfájl ( partitionweblogs.hql) az Azure Storage-fiókban (az AzureStorageLinkedService nevű scriptLinkedService által meghatározott) és a tároló
adfgetstartedszkriptmappájában van tárolva. - A
definesszakasz meghatározza a futásidő beállításait, amelyek Hive konfigurációs értékekként (például ${hiveconf:inputtable},${hiveconf:partitionedtable}) lesznek átadva a Hive-parancsfájlnak.
A typeProperties szakasz eltérő az egyes átalakítási tevékenységek esetében. Ahhoz, hogy megismerkedhessen az egyes átalakítási tevékenységek által támogatott típustulajdonságokkal, kattintson az adott átalakítási tevékenységre az Adatátalakítási tevékenységek szakaszban.
E folyamat létrehozásának teljes leírását lásd: Oktatóanyag: adatátalakítás a Spark használatával.
Több tevékenység egy adott folyamatban
Az előző két mintában a folyamatok csak egyetlen tevékenységet tartalmaztak. Egy folyamathoz azonban több tevékenység is tartozhat. Ha több tevékenységgel rendelkezik egy folyamatban, és az azt követő tevékenységek nem függnek a korábbi tevékenységektől, a tevékenységek párhuzamosan is futhatnak.
A tevékenységfüggőség segítségével összefűzhet két tevékenységet. Ez a fajta függőség azt határozza meg, hogy az egymást követő tevékenységek milyen függőségi viszonyban vannak a megelőző tevékenységekkel, meghatározva azt a feltételt, amelytől a következő feladat végrehajtása függ. Egy adott tevékenység egy vagy több korábbi, eltérő függőségi feltétellel rendelkező tevékenységtől is függhet.
Folyamatok ütemezése
A folyamatok ütemezése eseményindítókkal történik. Különböző típusú eseményindítók léteznek (Scheduler-eseményindító, amely lehetővé teszi a folyamatok aktiválását falióra ütemezésben, valamint a manuális eseményindító, amely igény szerint aktiválja a folyamatokat). Az eseményindítókról további információkat a Folyamat futtatása és eseményindítók cikkben talál.
Ahhoz, hogy az eseményindító kiváltsa egy folyamat indítását, az eseményindító meghatározásába bele kell foglalni az adott folyamat referenciáját. A folyamatok és az eseményindítók n-m kapcsolattal rendelkeznek. Egyetlen folyamatot több eseményindító is indíthat, és ugyanaz az eseményindító indíthat több folyamatot is. Ha az eseményindító meghatározása megtörtént, el kell indítania azt, hogy az képes legyen az adott folyamat indítására. Az eseményindítókról további információkat a Folyamat futtatása és eseményindítók cikkben talál.
Tegyük fel például, hogy van egy Scheduler-eseményindítója, az "A trigger", amelyet szeretnék elindítani a "MyCopyPipeline" folyamatról. Az eseményindítót az alábbi példában látható módon definiálja:
Az A eseményindító meghatározása
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}