Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A data lake egy tárház, amely nagy mennyiségű adatot tárol natív, nyers formátumban. A Data Lake-tárolók úgy vannak optimalizálva, hogy méretüket terabájtra és petabájtra skálázhassák. Az adatok általában több különböző forrásból származnak, és strukturált, részben strukturált vagy strukturálatlan adatokat is tartalmazhatnak. A data lake segítségével mindent eredeti, nem lefordított állapotban tárolhat. Ez a módszer eltér a hagyományos adattárháztól, amely a betöltéskor átalakítja és feldolgozza az adatokat.
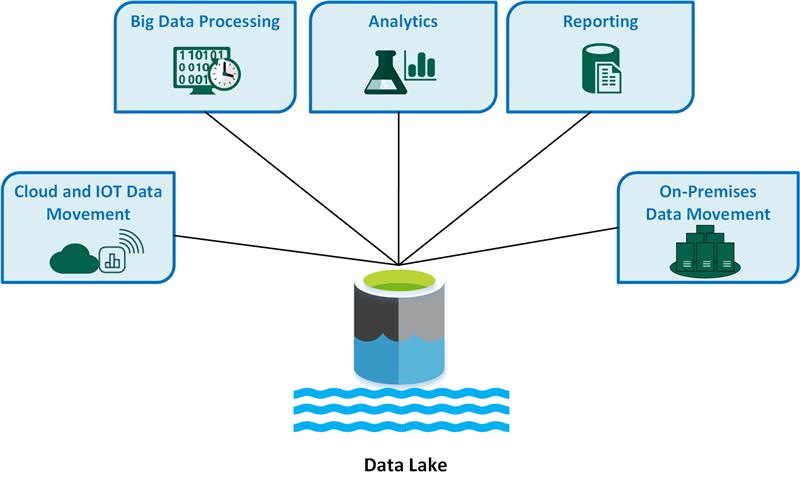
A Data Lake főbb használati esetei a következők:
- Felhőbeli és ioT-adatáthelyezés.
- Big Data-feldolgozás.
- Analitika.
- Jelentési.
- Helyszíni adatáthelyezés.
Vegye figyelembe a data lake következő előnyeit:
A data lake soha nem törli az adatokat, mert nyers formátumban tárolja az adatokat. Ez a funkció különösen hasznos big data-környezetben, mert lehet, hogy nem tudja előre, hogy milyen elemzéseket kaphat az adatokból.
A felhasználók megismerhetik az adatokat, és saját lekérdezéseket hozhatnak létre.
A data lake gyorsabb lehet, mint a hagyományos kinyerési, átalakítási, betöltési (ETL-) eszközök.
A data lake rugalmasabb, mint egy adattárház, mivel strukturálatlan és félig strukturált adatokat tárolhat.
A teljes data lake-megoldás tárolásból és feldolgozásból áll. A Data Lake Storage hibatűrésre, végtelen méretezhetőségre és a különböző alakzatok és adatméretek nagy átviteli sebességre való betöltésére szolgál. A data lake-feldolgozás egy vagy több olyan feldolgozómotort foglal magában, amely képes beépíteni ezeket a célokat, és nagy léptékben képes működni a data lake-ben tárolt adatokon.
Mikor érdemes data lake-t használni?
Javasoljuk, hogy data lake-t használjon adatfeltáráshoz, adatelemzéshez és gépi tanuláshoz.
A data lake az adattárház adatforrásaként is működhet. Ha ezt a módszert használja, a data lake betölti a nyers adatokat, majd strukturált, lekérdezhető formátummá alakítja őket. Ez az átalakítás általában egy kinyerési, betöltési, átalakítási (ELT) folyamatot használ, amelyben az adatok betöltése és átalakítása a helyén történik. Előfordulhat, hogy a relációs forrásadatok közvetlenül az adattárházba kerülnek egy ETL-folyamaton keresztül, és kihagyják a data lake-t.
A data lake-tárolókat eseménystreamelési vagy IoT-forgatókönyvekben is használhatja, mivel az adattavak nagy mennyiségű relációs és nem kapcsolati adatot tárolhatnak átalakítás vagy sémadefiníció nélkül. A data lake-k nagy mennyiségű kis írást képesek kezelni alacsony késéssel, és nagy átviteli sebességre vannak optimalizálva.
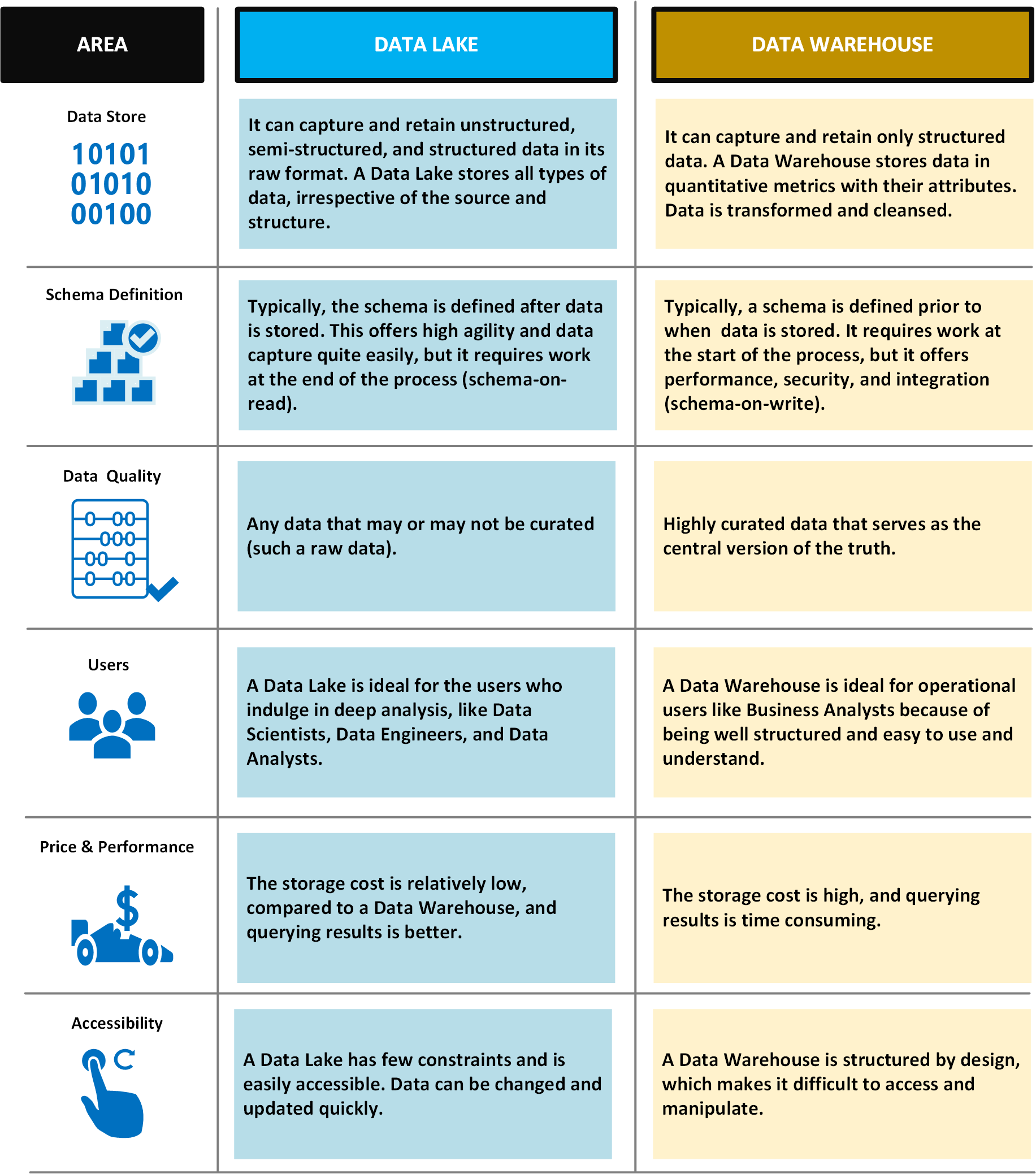
Az alábbi táblázat a data lake-eket és az adattárházakat hasonlítja össze.
Problémák
Nagy mennyiségű adat: A nagy mennyiségű nyers és strukturálatlan adat kezelése összetett és erőforrás-igényes lehet, ezért robusztus infrastruktúrára és eszközökre van szüksége.
Lehetséges szűk keresztmetszetek: Az adatfeldolgozás késéseket és hatékonysági problémákat okozhat, különösen akkor, ha nagy mennyiségű adatot és különböző adattípust tartalmaz.
Adatsérülési kockázatok: A helytelen adatérvényesítés és -figyelés adatsérülési kockázatot jelent, ami veszélyeztetheti az adattó integritását.
Minőségellenőrzési problémák: A megfelelő adatminőség kihívást jelent az adatforrások és formátumok változatossága miatt. Szigorú adatszabályozási eljárásokat kell alkalmaznia.
Teljesítményproblémák: A lekérdezési teljesítmény a data lake növekedésével csökkenhet, ezért optimalizálnia kell a tárolási és feldolgozási stratégiákat.
Technológiai lehetőségek
Ha átfogó Data Lake-megoldást hoz létre az Azure-ban, vegye figyelembe a következő technológiákat:
Az Azure Data Lake Storage egyesíti az Azure Blob Storage-t a Data Lake képességeivel, amely Apache Hadoop-kompatibilis hozzáférést, hierarchikus névtér-képességeket és fokozott biztonságot biztosít a hatékony big data-elemzéshez.
Az Azure Databricks egy egységes platform, amellyel adatokat dolgozhat fel, tárolhat, elemezhet és bevételt érhet el. Támogatja az ETL-folyamatokat, az irányítópultokat, a biztonságot, az adatfeltárást, a gépi tanulást és a generatív AI-t.
Az Azure Synapse Analytics egy egységes szolgáltatás, amellyel az azonnali üzletiintelligencia- és gépi tanulási igényeknek megfelelő adatok betöltésére, feltárására, előkészítésére, kezelésére és kiszolgálására használható. Mélyen integrálható az Azure data lake-ekkel, így nagy adathalmazokat kérdezhet le és elemezhet hatékonyan.
Az Azure Data Factory egy felhőalapú adatintegrációs szolgáltatás, amellyel adatvezérelt munkafolyamatokat hozhat létre az adatáthelyezés és -átalakítás vezényléséhez és automatizálásához.
A Microsoft Fabric egy átfogó adatplatform, amely egyetlen megoldásban egyesíti az adatmérnöki, adatelemzési, adattárházi, valós idejű elemzési és üzleti intelligenciát.
Közreműködők
Ezt a cikket a Microsoft tartja karban. Eredetileg a következő közreműködők írták.
Fő szerző:
- Avijit Prasad | Felhőtanácsadó
A nem nyilvános LinkedIn-profilok megtekintéséhez jelentkezzen be a LinkedInbe.
Következő lépések
- Mi az a OneLake?
- Bevezetés a Data Lake Storage-ba
- Az Azure Data Lake Analytics dokumentációja
- Oktatás: Bevezetés a Data Lake Storage használatába
- A Hadoop és az Azure Data Lake Storage integrációja
- Csatlakozás a Data Lake Storage-hoz és a Blob Storage-hoz
- Adatok betöltése a Data Lake Storage-ba az Azure Data Factoryvel