Ez a példaforgatókönyv bemutatja, hogyan lehet adatokat beszúrni egy felhőalapú környezetbe egy helyszíni adattárházból, majd hogyan lehet őket üzletiintelligencia-modellel kiszolgálni. Ez a megközelítés végső cél lehet, vagy egy első lépés a teljes modernizáció felé a felhőalapú összetevőkkel.
Az alábbi lépések az Azure Synapse Analytics végpontok közötti forgatókönyvére épülnek. Az Azure Pipelines használatával betölti az adatokat egy SQL-adatbázisból az Azure Synapse SQL-készletekbe, majd átalakítja az adatokat elemzésre.
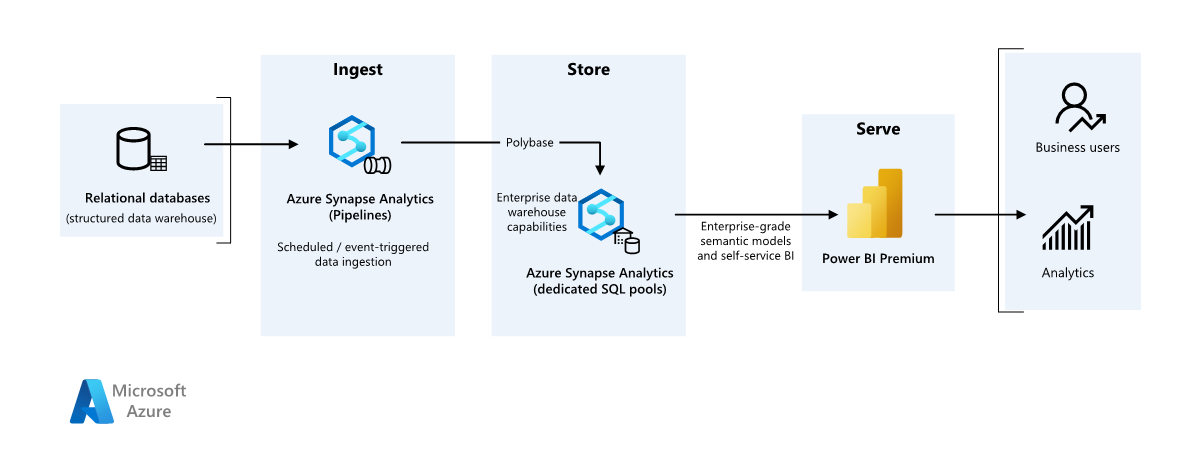
Architektúra

Töltse le az architektúra Visio-fájlját.
Munkafolyamat
Adatforrás
- A forrásadatok egy Azure-beli SQL Server-adatbázisban találhatók. A helyszíni környezet szimulálásához az ehhez a forgatókönyvhöz tartozó üzembehelyezési szkriptek kiépítenek egy Azure SQL-adatbázist. A rendszer az AdventureWorks mintaadatbázist használja forrásadatsémaként és mintaadatként. Az adatok helyszíni adatbázisból való másolásáról további információt az ADATOK másolása és átalakítása az SQL Serverről és az sql serverről című témakörben talál.
Betöltés és adattárolás
Az Azure Data Lake Gen2 átmeneti átmeneti területként használatos az adatbetöltés során. Ezután a PolyBase használatával adatokat másolhat egy dedikált Azure Synapse SQL-készletbe.
Az Azure Synapse Analytics egy elosztott rendszer, amely nagy méretű adatok elemzésére szolgál. Támogatja a nagy teljesítményű párhuzamos feldolgozást (MPP), ami alkalmassá teszi a nagy teljesítményű elemzések futtatására. A dedikált Azure Synapse SQL-készlet a helyszíni adatok folyamatos betöltésének célja. További feldolgozásra, valamint a Power BI-adatok DirectQueryn keresztüli kiszolgálására is használható.
Az Azure Pipelines segítségével vezényelheti az adatok betöltését és átalakítását az Azure Synapse-munkaterületen belül.
Elemzés és jelentéskészítés
- Ebben a forgatókönyvben az adatmodellezési megközelítés a vállalati modell és a BI Szemantikai modell kombinálásával jelenik meg. A vállalati modell egy dedikált Azure Synapse SQL-készletben van tárolva, a BI Szemantikai modell pedig Power BI Premium-kapacitásokban van tárolva. A Power BI a DirectQueryn keresztül fér hozzá az adatokhoz.
Összetevők
Ez a forgatókönyv a következő összetevőket használja:
Egyszerűsített architektúra
Forgatókönyv részletei
A szervezet nagy helyszíni adattárházzal rendelkezik, amely egy SQL-adatbázisban van tárolva. A szervezet az Azure Synapse-t szeretné használni az elemzéshez, majd ezeket az elemzéseket a Power BI használatával szeretné kiszolgálni.
Hitelesítés
A Microsoft Entra hitelesíti a Power BI-irányítópultokhoz és -alkalmazásokhoz csatlakozó felhasználókat. Az egyszeri bejelentkezés az Azure Synapse kiépített készletében lévő adatforráshoz való csatlakozásra szolgál. Az engedélyezés a forráson történik.
Növekményes betöltés
Automatizált kinyerés, átalakítás, betöltés (ETL) vagy kinyerési, betöltési, átalakítási (ELT) folyamat futtatásakor a leghatékonyabb, ha csak az előző futtatás óta megváltozott adatokat tölti be. Ezt növekményes terhelésnek nevezzük, szemben a teljes terheléssel, amely betölti az összes adatot. Növekményes terhelés végrehajtásához meg kell határoznia, hogy mely adatok módosultak. A leggyakoribb módszer a magas vízjelérték használata, amely nyomon követi a forrástábla egyes oszlopainak legújabb értékét, akár datetime oszlopot, akár egyedi egész szám oszlopot.
Az SQL Server 2016-tól kezdve használhat temporális táblákat, amelyek rendszerverziójú táblák, amelyek az adatváltozások teljes előzményeit őrzik meg. Az adatbázismotor automatikusan rögzíti a változások előzményeit egy külön előzménytáblában. Az előzményadatok lekérdezéséhez adjon hozzá egy záradékot FOR SYSTEM_TIME egy lekérdezéshez. Az adatbázismotor belsőleg lekérdezi az előzménytáblát, de átlátható az alkalmazás számára.
Feljegyzés
Az SQL Server korábbi verzióihoz használhatja a módosítási adatrögzítést (CDC). Ez a módszer kevésbé kényelmes, mint az időbeli táblák, mivel külön változástáblát kell lekérdeznie, és a változásokat egy naplóütemezési szám követi nyomon időbélyeg helyett.
Az időbeli táblák hasznosak a dimenzióadatokhoz, amelyek idővel változhatnak. A ténytáblák általában nem módosítható tranzakciót, például eladást jelölnek, ebben az esetben a rendszer verzióelőzményeinek megtartása nem logikus. Ehelyett a tranzakciók általában egy olyan oszlopmal rendelkeznek, amely a tranzakció dátumát jelöli, amely vízjelértékként használható. Az AdventureWorks Adattárházban például a SalesLT.* táblák mezővel LastModified rendelkeznek.
Az ELT-folyamat általános folyamata a következő:
A forrásadatbázis minden táblájában kövesse nyomon az utolsó ELT-feladat futásának kivágási idejét. Ezeket az adatokat az adattárházban tárolhatja. A kezdeti beállításkor minden alkalommal a következőre van állítva:
1-1-1900.Az adatexportálási lépés során a kivágás ideje paraméterként a forrásadatbázisban tárolt eljárások egy halmazának lesz átadva. Ezek a tárolt eljárások lekérdezik azokat a rekordokat, amelyeket a kivágás után módosítottak vagy hoztak létre. A példában szereplő összes táblához használhatja az oszlopot
ModifiedDate.Ha az adatmigrálás befejeződött, frissítse a kivágási időket tároló táblát.
Adat prognózis
Ez a forgatókönyv az AdventureWorks mintaadatbázist használja adatforrásként. A növekményes adatbetöltési minta implementálva biztosítja, hogy csak a legutóbbi folyamatfuttatás után módosított vagy hozzáadott adatokat töltjük be.
Metaadat-alapú másolási eszköz
Az Azure Pipelines beépített metaadat-alapú másolási eszköze növekményesen betölti a relációs adatbázisban található összes táblát. A varázslóalapú felületen való navigálással csatlakoztathatja az Adatok másolása eszközt a forrásadatbázishoz, és konfigurálhatja az egyes táblák növekményes vagy teljes betöltését. Az Adatok másolása eszköz ezután létrehozza a folyamatokat és az SQL-szkripteket is, hogy létrehozza a növekményes betöltési folyamat adatainak tárolásához szükséges vezérlőtáblát – például az egyes táblák magas vízjelértékét/oszlopát. A szkriptek futtatása után a folyamat készen áll arra, hogy a forrásadatraktárban lévő összes táblát betöltse a Synapse dedikált készletébe.
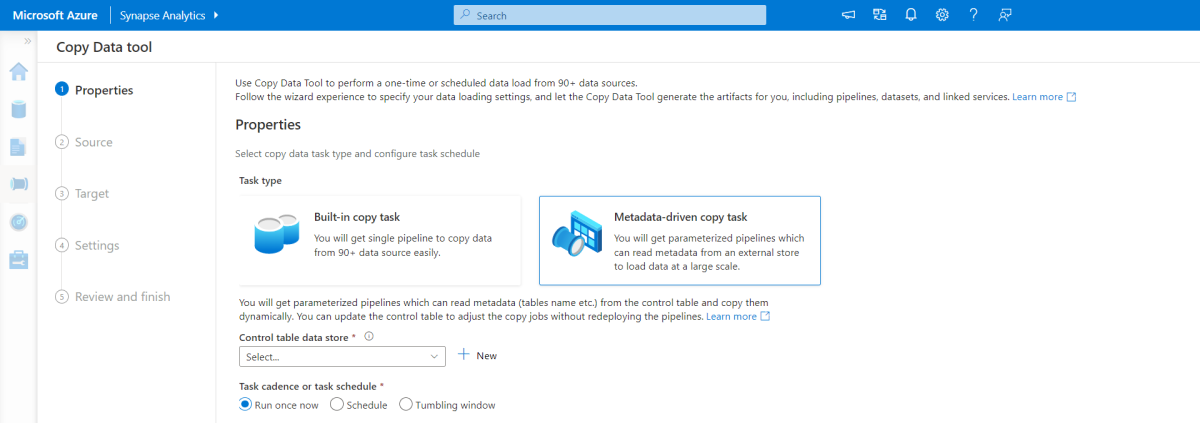
Az eszköz három folyamatot hoz létre az adatbázis összes táblájának iterálásához, mielőtt betöltené az adatokat.
Az eszköz által létrehozott folyamatok:
- Megszámolja a folyamatfuttatásban másolandó objektumok( például táblák) számát.
- Iterálja át az egyes betöltendő/másolandó objektumokat, majd:
- Ellenőrizze, hogy szükség van-e változásterhelésre; egyéb esetben végezzen el egy normál teljes terhelést.
- Kérje le a magas vízjel értékét a vezérlőtáblából.
- Másolja az adatokat a forrástáblákból a Data Lake Storage Gen2 átmeneti fiókjába.
- Adatok betöltése a dedikált SQL-készletbe a kijelölt másolási módszerrel – például PolyBase, Másolás parancs.
- Frissítse a felső vízjel értékét a vezérlőtáblában.
Adatok betöltése az Azure Synapse SQL-készletbe
A másolási tevékenység adatokat másol az SQL-adatbázisból az Azure Synapse SQL-készletbe. Ebben a példában, mivel az SQL-adatbázis az Azure-ban található, az Azure integrációs moduljával adatokat olvasunk az SQL-adatbázisból, és az adatokat a megadott átmeneti környezetbe írjuk.
A másolási utasítás ezután arra szolgál, hogy adatokat töltsön be az átmeneti környezetből a Dedikált Synapse-készletbe.
Az Azure Pipelines használata
Az Azure Synapse folyamatait a növekményes terhelési minta végrehajtásához szükséges tevékenységek rendezett készletének meghatározására használják. Az eseményindítók a folyamat elindítására szolgálnak, amelyek manuálisan vagy a megadott időpontban aktiválhatók.
Az adatok átalakítása
Mivel a referenciaarchitektúra mintaadatbázisa nem nagy, partíciók nélküli replikált táblákat hoztunk létre. Éles számítási feladatok esetén az elosztott táblák használata valószínűleg javítja a lekérdezési teljesítményt. További információ: Útmutató elosztott táblák tervezéséhez az Azure Synapse-ban. A példaszkriptek statikus erőforrásosztály használatával futtatják a lekérdezéseket.
Éles környezetben érdemes lehet átmeneti táblákat létrehozni ciklikus időszeleteléses eloszlással. Ezután alakítsa át és helyezze át az adatokat éles táblákba csoportosított oszlopcentrikus indexekkel, amelyek a legjobb általános lekérdezési teljesítményt nyújtják. Az oszlopcentrikus indexek olyan lekérdezésekhez vannak optimalizálva, amelyek sok rekordot vizsgálnak. Az oszlopcentrikus indexek nem teljesítenek olyan jól az egyszeri keresések esetében, vagyis egyetlen sor keresésekor. Ha gyakori egyszeri kereséseket kell végrehajtania, hozzáadhat egy nem fürtözött indexet egy táblához. Az egyszeri keresések sokkal gyorsabban futtathatók nem fürtözött indexek használatával. Az egyszeri keresések azonban általában ritkábban fordulnak elő adatraktár-forgatókönyvekben, mint az OLTP-számítási feladatok. További információ: Indexelő táblák az Azure Synapse-ban.
Feljegyzés
A fürtözött oszlopcentrikus táblák nem támogatják varchar(max)az nvarchar(max)adattípusokat.varbinary(max) Ebben az esetben fontolja meg a halom vagy a fürtözött index használatát. Ezeket az oszlopokat egy külön táblába helyezheti.
Adatok elérése, modellezése és vizualizációja a Power BI Premium használatával
A Power BI Premium számos lehetőséget támogat az Azure-beli adatforrásokhoz való csatlakozáshoz, különösen az Azure Synapse kiépített készletéhez:
- Importálás: Az adatok importálása a Power BI-modellbe történik.
- DirectQuery: Az adatok közvetlenül a relációs tárolóból lesznek lekérve.
- Összetett modell: Egyesítse az importálást egyes táblákhoz és a DirectQueryt másokhoz.
Ez a forgatókönyv a DirectQuery-irányítópulton érhető el, mivel a felhasznált adatok mennyisége és a modell összetettsége nem magas, így jó felhasználói élményt tudunk nyújtani. A DirectQuery a lekérdezést a nagy teljesítményű számítási motor alá delegálja, és széles körű biztonsági képességeket használ a forráson. Emellett a DirectQuery használatával biztosítható, hogy az eredmények mindig összhangban legyenek a legújabb forrásadatokkal.
Az importálási mód biztosítja a leggyorsabb lekérdezési válaszidőt, és figyelembe kell venni, ha a modell teljes mértékben a Power BI memóriájába illeszkedik, a frissítések közötti adatkésés elviselhető, és a forrásrendszer és a végső modell között összetett átalakítások is előfordulhatnak. Ebben az esetben a végfelhasználók teljes hozzáférést szeretnének a legújabb adatokhoz a Power BI frissítésének késleltetése nélkül, és minden előzményadathoz, amely nagyobb, mint amit egy Power BI-adatkészlet képes kezelni – a kapacitás méretétől függően 25–400 GB között. Mivel a dedikált SQL-készlet adatmodellje már csillagsémában van, és nem igényel átalakítást, a DirectQuery megfelelő választás.
A Power BI Premium Gen2 lehetővé teszi a nagyméretű modellek, lapszámozott jelentések, üzembehelyezési folyamatok és beépített Analysis Services-végpontok kezelését. Dedikált kapacitással is rendelkezhet, egyedi értékajánlattal.
A BI-modell növekedésével vagy az irányítópultok összetettségének növekedésével összetett modellekre válthat, és hibrid táblákon és néhány előre összesített adaton keresztül importálhatja a keresési táblák részeit. Az importált adathalmazok lekérdezési gyorsítótárazásának engedélyezése a Power BI-ban lehetőség, valamint kettős táblák használata a tárolási mód tulajdonságához.
Az összetett modellben az adathalmazok virtuális átmenő rétegként működnek. Amikor a felhasználó interakcióba lép a vizualizációkkal, a Power BI SQL-lekérdezéseket hoz létre a Synapse SQL-készletekben kettős tárterületet hoz létre: a memóriában vagy a közvetlen lekérdezésben attól függően, hogy melyik hatékonyabb. A motor dönti el, hogy mikor váltson a memóriában lévőről a közvetlen lekérdezésre, és leküldi a logikát a Synapse SQL-készletbe. A lekérdezéstáblák környezetétől függően gyorsítótárazottként (importáltként) vagy nem gyorsítótárazott összetett modellként is működhetnek. Válassza ki és válassza ki a memóriába gyorsítótárazandó táblát, egyesítse egy vagy több DirectQuery-forrás adatait, és/vagy egyesítse a DirectQuery-források és az importált adatok kombinációjából származó adatokat.
Javaslatok: Ha DirectQueryt használ az Azure Synapse Analytics által kiépített készleten:
- Az Azure Synapse-eredménykészlet gyorsítótárazásával gyorsítótárazhatja a lekérdezési eredményeket a felhasználói adatbázisban ismétlődő használatra, javíthatja a lekérdezési teljesítményt ezredmásodpercre, és csökkentheti a számítási erőforrások használatát. A gyorsítótárazott eredménykészleteket használó lekérdezések nem használnak egyidejűségi pontokat az Azure Synapse Analyticsben, így nem számítanak bele a meglévő egyidejűségi korlátokba.
- Az Azure Synapse materializált nézeteivel ugyanúgy előre kiszámíthatja, tárolhatja és karbantarthatja az adatokat, mint egy táblázatot. Azok a lekérdezések, amelyek az adatok egy részét vagy egészét materializált nézetben használják, gyorsabb teljesítményt érhetnek el, és nem kell közvetlenül hivatkozniuk a definiált materializált nézetre a használatukhoz.
Megfontolások
Ezek a szempontok implementálják az Azure Well-Architected Framework alappilléreit, amely a számítási feladatok minőségének javítására használható vezérelvek halmaza. További információ: Microsoft Azure Well-Architected Framework.
Biztonság
A biztonság biztosítékokat nyújt a szándékos támadások és az értékes adatokkal és rendszerekkel való visszaélés ellen. További információ: A biztonsági pillér áttekintése.
Az adatsértések, a kártevő-fertőzések és a rosszindulatú kódinjektálás gyakori főcímei a felhő modernizálását kereső vállalatok biztonsági problémáinak széles listában szerepelnek. A nagyvállalati ügyfeleknek olyan felhőszolgáltatóra vagy szolgáltatásmegoldásra van szükségük, amely kezelni tudja a problémáikat, mivel nem engedhetik meg maguknak, hogy tévedjenek.
Ez a forgatókönyv a rétegzett biztonsági vezérlők kombinációjával kezeli a legigényesebb biztonsági problémákat: hálózat, identitás, adatvédelem és engedélyezés. Az adatok nagy része az Azure Synapse kiépített készletében van tárolva, és a Power BI a DirectQueryt használja egyszeri bejelentkezéssel. A hitelesítéshez használhatja a Microsoft Entra-azonosítót. A kiépített készletek adatengedélyezési funkcióinak széles körű biztonsági vezérlői is vannak.
Néhány gyakori biztonsági kérdés:
- Hogyan szabályozhatom, hogy ki lát milyen adatokat?
- A szervezeteknek meg kell védeniük adataikat, hogy megfeleljenek a szövetségi, helyi és vállalati irányelveknek az adatszivárgás kockázatának csökkentése érdekében. Az Azure Synapse több adatvédelmi funkciót is kínál a megfelelőség eléréséhez.
- Milyen lehetőségek vannak a felhasználó identitásának ellenőrzésére?
- Az Azure Synapse számos képességet támogat annak szabályozására, hogy ki férhet hozzá milyen adatokhoz hozzáférés-vezérléssel és hitelesítéssel.
- Milyen hálózati biztonsági technológiát használhatok a hálózataim és adataim integritásának, titkosságának és hozzáférésének védelmére?
- Az Azure Synapse védelméhez számos hálózati biztonsági lehetőség közül választhat.
- Mik azok az eszközök, amelyek észlelik és értesítik a fenyegetéseket?
- Az Azure Synapse számos fenyegetésészlelési funkciót kínál, például: SQL-naplózás, SQL-fenyegetésészlelés és sebezhetőségi felmérés adatbázisok naplózásához, védelméhez és monitorozásához.
- Mit tehetek a tárfiókom adatainak védelme érdekében?
- Az Azure Storage-fiókok ideálisak olyan számítási feladatokhoz, amelyek gyors és konzisztens válaszidőt igényelnek, vagy nagy számú bemeneti-kimeneti művelettel (IOP) rendelkeznek másodpercenként. A tárfiókok tartalmazzák az összes Azure Storage-adatobjektumot, és számos lehetőség van a tárfiókok biztonságára.
Költségoptimalizálás
A költségoptimalizálás a szükségtelen kiadások csökkentésének és a működési hatékonyság javításának módjairól szól. További információ: A költségoptimalizálási pillér áttekintése.
Ez a szakasz tájékoztatást nyújt a megoldásban érintett különböző szolgáltatások díjszabásáról, és egy mintaadatkészlettel említi meg az ehhez a forgatókönyvhöz hozott döntéseket.
Azure Synapse
Az Azure Synapse Analytics kiszolgáló nélküli architektúrája lehetővé teszi a számítási és tárolási szintek egymástól függetlenül történő skálázását. A számítási erőforrások terhelése a használat alapján történik, és igény szerint skálázhatja vagy szüneteltetheti ezeket az erőforrásokat. A tárolási erőforrásokat terabájtonként számlázzák, így a költségek növekedni fognak, amikor több adatot vesz fel.
Azure Pipelines
Az Azure Synapse-beli folyamatok díjszabási részletei az Azure Synapse díjszabási oldalának adatintegráció lapján találhatók. A folyamat árát három fő összetevő befolyásolja:
- Adatfolyam-tevékenységek és integrációs futtatókörnyezeti órák
- Adatfolyamok fürtmérete és végrehajtása
- Műveleti díjak
Az ár az összetevőktől vagy tevékenységektől, a gyakoriságtól és az integrációs modulegységek számától függően változik.
A mintaadatkészlet esetében a standard Azure-beli integrációs modul, a folyamat magjának adattevékenységének másolása napi ütemezés szerint aktiválódik a forrásadatbázis összes entitása (táblája) számára. A forgatókönyv nem tartalmaz adatfolyamokat. Nincsenek üzemeltetési költségek, mivel havonta kevesebb mint 1 millió művelet van folyamatban.
Dedikált Azure Synapse-készlet és -tároló
A dedikált Azure Synapse-készlet díjszabási részletei az Azure Synapse díjszabási oldalának Adattárolás lapján találhatók. A dedikált használati modellben az ügyfelek számlázása kiépített adattárházegységek (DWU) egységenként, óránkénti üzemidőnként lesznek számlázva. Egy másik tényező az adattárolási költségek: az inaktív adatok mérete + pillanatképek + georedundancia, ha vannak ilyenek.
A mintaadatkészlethez kiépítheti az 500DWU-t, amely garantálja az elemzési terhelés megfelelő élményét. A számítást folyamatosan végezheti, és több órányi jelentéskészítési időt is igénybe vehet. Ha éles környezetbe kerül, a fenntartott adattárház-kapacitás vonzó lehetőség a költségkezeléshez. Az előző szakaszokban tárgyalt költség-/teljesítménymetrikák maximalizálásához különböző technikákat kell használni.
Blob Storage
Fontolja meg a fenntartott Azure Storage-kapacitás funkció használatát a tárolási költségek csökkentése érdekében. Ezzel a modellel kedvezményt kap, ha egy vagy három évre lefoglalja a rögzített tárkapacitást. További információ: A Blob Storage költségeinek optimalizálása fenntartott kapacitással.
Ebben a forgatókönyvben nincs állandó tároló.
Power BI Premium
A Power BI Premium díjszabásának részletei a Power BI díjszabási oldalán találhatók.
Ez a forgatókönyv a Power BI Premium-munkaterületeket használja, amelyek számos teljesítménybeli fejlesztéssel rendelkeznek, amelyek az igényes elemzési igények kielégítésére épülnek.
Működés eredményessége
Az üzemeltetési kiválóság azokat az üzemeltetési folyamatokat fedi le, amelyek üzembe helyeznek egy alkalmazást, és éles környezetben tartják azt. További információ: A működési kiválósági pillér áttekintése.
DevOps-javaslatok
Külön erőforráscsoportokat hozhat létre éles, fejlesztési és tesztelési környezetekhez. A külön erőforráscsoportok használata megkönnyíti az üzemelő példányok felügyeletét, a tesztkörnyezetek törlését és a hozzáférési jogok kiosztását.
Helyezze az egyes számítási feladatokat egy külön üzembehelyezési sablonba, és tárolja az erőforrásokat a forrásvezérlő rendszerekben. A sablonokat egy folyamatos integrációs és folyamatos kézbesítési (CI/CD) folyamat részeként is üzembe helyezheti, így egyszerűbbé teheti az automatizálási folyamatot. Ebben az architektúrában négy fő számítási feladat van:
- Az adattárház-kiszolgáló és a kapcsolódó erőforrások
- Azure Synapse-folyamatok
- Power BI-eszközök: irányítópultok, alkalmazások, adathalmazok
- Helyszíni és felhőbeli szimulált forgatókönyv
Törekedjen arra, hogy minden számítási feladathoz külön üzembehelyezési sablont használjon.
Érdemes lehet a számítási feladatokat olyan helyre átszűnni, ahol praktikus. Helyezze üzembe a különböző szakaszokban, és futtassa az érvényesítési ellenőrzéseket minden egyes szakaszban, mielőtt továbblépne a következő fázisra. Így szabályozott módon küldheti le a frissítéseket az éles környezetekbe, és minimalizálhatja a nem várt üzembe helyezési problémákat. Az élő éles környezetek frissítéséhez használjon kék-zöld üzembe helyezési és kanári-kibocsátási stratégiákat.
Jó visszaállítási stratégiával rendelkezik a sikertelen üzemelő példányok kezeléséhez. Például automatikusan újra üzembe helyezhet egy korábbi, sikeres üzembe helyezést az üzembe helyezési előzményekből. Tekintse meg a jelölőt
--rollback-on-erroraz Azure CLI-ben.Az Azure Monitor az adattárház teljesítményének és a teljes Azure Analytics-platformnak az integrált monitorozási élmény érdekében történő elemzéséhez ajánlott. Az Azure Synapse Analytics monitorozási felületet biztosít az Azure Portalon az adattárház számítási feladataival kapcsolatos elemzések megjelenítéséhez. Az Azure Portal az adattárház monitorozásához ajánlott eszköz, mivel konfigurálható megőrzési időszakokat, riasztásokat, javaslatokat és testre szabható diagramokat és irányítópultokat biztosít metrikákhoz és naplókhoz.
Első lépések
- Portál: Az Azure Synapse koncepcióigazolása (POC)
- Az Azure CLI: Azure Synapse-munkaterület létrehozása az Azure CLI-vel
- Terraform: Modern adattárház a Terraform és a Microsoft Azure használatával
Teljesítmény hatékonysága
A teljesítménybeli hatékonyság lehetővé teszi, hogy a számítási feladatok hatékonyan méretezhetők legyenek a felhasználók igényei szerint. További információ: Teljesítményhatékonysági pillér áttekintése.
Ez a szakasz részletesen ismerteti az adathalmazhoz igazodó méretezési döntéseket.
Azure Synapse kiépített készlet
Számos adattárház-konfiguráció közül választhat.
| Adattárházegységek | Számítási csomópontok száma | Csomópontonkénti eloszlások száma |
|---|---|---|
| DW100c | 0 | 60 |
-- TO -- |
||
| DW30000c | 60 | 0 |
A horizontális felskálázás teljesítménybeli előnyeinek megtekintéséhez, különösen a nagyobb adatraktár-egységek esetében, használjon legalább egy 1 TB-os adatkészletet. A dedikált SQL-készlethez tartozó adattárházegységek legjobb számának megkereséséhez próbálkozzon a vertikális fel- és leskálázással. Az adatok betöltése után futtasson néhány lekérdezést különböző számú adattárházegységgel. Mivel a skálázás gyors, a különböző teljesítményszinteket egy vagy kevesebb órán belül kipróbálhatja.
Az adattárházegységek legjobb számának megkeresése
A fejlesztés alatt álló dedikált SQL-készlet esetében először válasszon kisebb számú adattárházegységet. Jó kiindulópont a DW400c vagy DW200c. Az alkalmazás teljesítményének figyelése a megfigyelt teljesítményhez képest kiválasztott adattárházegységek számának megfigyelésével. Tételezzük fel a lineáris skálázást, és állapítsuk meg, hogy mennyit kell növelni vagy csökkenteni az adattárházegységeket. Folytassa a módosításokat, amíg el nem éri az üzleti követelményeknek megfelelő optimális teljesítményszintet.
Synapse SQL-készlet skálázása
- A Synapse SQL-készlet számítási skálázása az Azure Portallal
- Számítási feladatok méretezése dedikált SQL-készlethez az Azure PowerShell-lel
- Számítási feladatok méretezése dedikált SQL-készlethez az Azure Synapse Analyticsben a T-SQL használatával
- Szüneteltetés, monitorozás és automatizálás
Azure Pipelines
Az Azure Synapse-folyamatok skálázhatósági és teljesítményoptimalizálási funkcióiról és a használt másolási tevékenységről a Copy tevékenység teljesítmény- és méretezhetőségi útmutatóban tájékozódhat.
Power BI Premium
Ez a cikk a Power BI Premium Gen 2 használatával mutatja be a BI képességeit. A Power BI Premium kapacitás-termékváltozatai jelenleg P1 (nyolc virtuális mag) és P5 (128 virtuális mag) között mozognak. A szükséges kapacitás kiválasztásának legjobb módja a kapacitásbetöltés kiértékelése, a Gen 2 metrikák alkalmazás telepítése a folyamatos monitorozáshoz, valamint az Automatikus skálázás használata a Power BI Premium használatával.
Közreműködők
Ezt a cikket a Microsoft tartja karban. Eredetileg a következő közreműködők írták.
Fő szerzők:
- Galina Polyakova | Vezető felhőmegoldás-tervező
- Noah Costar | Felhőmegoldás-tervező
- George Stevens | Felhőmegoldás-tervező
Egyéb közreműködők:
- Jim McLeod | Felhőmegoldás-tervező
- Miguel Myers | Vezető programmenedzser
A nem nyilvános LinkedIn-profilok megtekintéséhez jelentkezzen be a LinkedInbe.
Következő lépések
- Mi a Power BI Premium?
- Mi a Microsoft Entra-azonosító?
- Az Azure Data Lake Storage Gen2 és a Blob Storage elérése az Azure Databricks használatával
- Mi az az Azure Synapse Analytics?
- Társított szolgáltatások az Azure Data Factoryben és az Azure Synapse Analyticsben
- Mi az Az Azure SQL?