Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőre vonatkozik: :![]() Azure SQL Database
Azure SQL Database
A Serverless egy számítási réteg az Azure SQL Database egyetlen adatbázisához, amely automatikusan skálázza a számításhoz szükséges erőforrásokat a munkaterhelés igényei alapján, és másodpercenként a használt számítási mennyiség alapján számláz. A kiszolgáló nélküli számítási szint emellett automatikusan szünetelteti az adatbázisokat az inaktív időszakok során, amikor csak a tárterület használati díját számlázzuk ki, és automatikusan folytatja az adatbázisok működését, amikor ismét előfordulnak tevékenységek. A kiszolgáló nélküli számítási szint az Általános célú szolgáltatási szinten és a Rugalmas skálázási szolgáltatási szinten érhető el.
Az automatikus szüneteltetés és az automatikus folytatás jelenleg csak az Általános célú szolgáltatási szinten támogatott.
Áttekintés
A kiszolgáló nélküli számítási szint fontos paraméterei a számítási automatikus skálázási tartomány és az automatikus szüneteltetés késleltetése. Ezeknek a paramétereknek a konfigurációja meghatározza az adatbázis teljesítményét és a számítási költségeket.
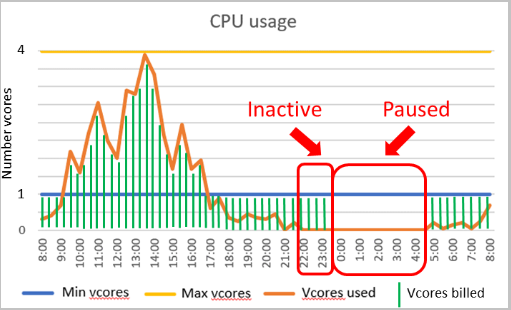
Teljesítménykonfiguráció
- A minimális virtuális magok és a maximális virtuális magok olyan konfigurálható paraméterek, amelyek meghatározzák az adatbázishoz elérhető számítási kapacitás tartományát. A memória- és I/O-korlátok arányosak a megadott vCore tartománnyal.
- Az automatikus szüneteltetési késleltetés egy konfigurálható paraméter, amely meghatározza, hogy az adatbázisnak az automatikus szüneteltetés előtt inaktívnak kell lennie. Az adatbázis automatikusan folytatódik, amikor a következő bejelentkezés vagy egyéb tevékenység történik. Másik lehetőségként az automatikus szüneteltetés le is tiltható.
Költség
A kiszolgáló nélküli adatbázisok költsége a számítási költség és a tárolási költség összegzése. A tárolási költség meghatározása ugyanúgy történik, mint a kiosztott számítási szinten.
- Ha a számítási használat a konfigurált minimális és maximális korlátok között van, a számítási költség a virtuális magon és a felhasznált memórián alapul.
- Ha a számítási használat a konfigurált minimális korlátok alatt van, a számítási költség a minimális virtuális magokon és a minimálisan konfigurált memórián alapul.
- Az adatbázis szüneteltetésekor a számítási költség nulla, és csak a tárolási költségek merülnek fel.
További költségadatokért tekintse meg a Számlázás című témakört.
Lehetséges helyzetek
A kiszolgáló nélküli adatbázisok ár–teljesítmény aránya az időszakos, kiszámíthatatlan használati mintázatú önálló adatbázisokhoz van optimalizálva, ahol elfogadható némi késés a növekvő mennyiségű számítási feladatok elvégzésében a tétlen időszakok után. Ezzel szemben a kiosztott számítási szint ár-teljesítményre optimalizált az egyetlen vagy több rugalmas készletben lévő, magasabb átlagos használatú adatbázis esetében, ami nem engedheti meg a számítási bemelegítés késleltetését.
Kiszolgáló nélküli számításhoz megfelelő forgatókönyvek
- Önálló adatbázisok időszakos, kiszámíthatatlan használati mintázattal, ahol szórványosan előfordulnak inaktív és átlagosan alacsonyabb számítási igényű időszakok.
- A kiépített számítási rétegben gyakran újraskálázott önálló adatbázisok és azok az ügyfelek, akik inkább delegálják a számítási újraskálázást a szolgáltatásnak.
- Új, használatelőzmény nélküli adatbázisok, ahol a számítási méretezés nehezen vagy nem becsülhető meg egy Azure SQL Database üzembe helyezése előtt.
Az előre kialakított számítási kapacitáshoz illő forgatókönyvek
- Önálló adatbázisok rendszeresebb, kiszámíthatóbb használati mintákkal és magasabb átlagos számítási kihasználtsággal az idő függvényében.
- Azok az adatbázisok, amelyek nem tudják elviselni a teljesítménybeli kompromisszumokat, amelyek a memória gyakoribb levágása vagy a szüneteltetett állapotból való folytatás késleltetése miatt nem tolerálhatók.
- Több adatbázis időszakos, kiszámíthatatlan használati mintákkal, amelyek rugalmas készletekbe konszolidálhatók a jobb ár-teljesítmény optimalizálás érdekében.
Számítási szintek összehasonlítása
Az alábbi táblázat a kiszolgáló nélküli számítási szint és a kiépített számítási szint közötti különbségeket foglalja össze:
| Kiszolgáló nélküli számítástechnika | Előre kiosztott számítási erőforrások | |
|---|---|---|
| Adatbázis-használati minta | Időszakos, kiszámíthatatlan használat, az idő múlásával alacsonyabb átlagos számítási kihasználtsággal. | Rendszeresebb használati minták, magasabb átlagos számítási kihasználtsággal, vagy rugalmas készleteket használó több adatbázissal. |
| Teljesítménykezelési munka | Alacsonyabb | Magasabb |
| Számítási skálázás | Automatikus | Kézikönyv |
| Számítási válaszkészség | Inaktív időszakok után alacsonyabb | Azonnali |
| Számlázás részletessége | Másodpercenként | óránként |
Vásárlási modell és szolgáltatási szint
Az alábbi táblázat a kiszolgáló nélküli támogatást ismerteti a vásárlási modell, a szolgáltatási szintek és a hardver alapján:
| Kategória | Támogatott | Nem támogatott |
|---|---|---|
| Vásárlási modell | vCore | DTU |
| Szolgáltatási szint |
általános cél hiperskálázható |
üzletileg kritikus |
| Hardver | Standard sorozat (5. generáció) | Minden más hardver |
Automatikus skálázás
A válaszreakciók skálázása
A kiszolgáló nélküli adatbázisok olyan gépen futnak, amely elegendő kapacitással rendelkezik ahhoz, hogy megszakítás nélkül kielégítse az erőforrás-igényeket a kért számítási mennyiséghez, a maximális virtuális magérték által meghatározott korlátokon belül. Időnként automatikusan megtörténik a terheléselosztás, ha a gép néhány percen belül nem tudja kielégíteni az erőforrás-igényeket. Ha például az erőforrás-igény 4 virtuális mag, de csak 2 virtuális mag érhető el, akkor akár néhány percbe is telhet a terheléselosztás, mielőtt biztosítanánk a 4 virtuális magot. Az adatbázis a terheléselosztás során is online állapotban marad, kivéve a művelet végén egy rövid időszakot, amikor megszakadnak a kapcsolatok.
Memóriakezelés
Az általános célú és a rugalmas skálázású szolgáltatási szinteken a kiszolgáló nélküli adatbázisok memóriája gyakrabban lesz visszanyerve, mint a kiépített számítási adatbázisok esetében. Ez a viselkedés fontos a kiszolgáló nélküli költségek szabályozásához, és hatással lehet a teljesítményre.
Gyorsítótár-reklamáció
A kiépített számítási adatbázisoktól eltérően az SQL-gyorsítótárból származó memória kiszolgáló nélküli adatbázisból lesz visszanyerve, ha a processzor- vagy az aktív gyorsítótár kihasználtsága alacsony.
- Az aktív gyorsítótár-kihasználtság akkor tekinthető alacsonynak, ha a legutóbb használt gyorsítótár-bejegyzések teljes mérete egy adott időtartamra a küszöbérték alá esik.
- A gyorsítótár-visszaállítás aktiválásakor a célgyorsítótár mérete növekményesen csökken a korábbi méret töredékére, és a visszaigénylés csak akkor folytatódik, ha a használat alacsony marad.
- Gyorsítótár-reklamáció esetén a kiürítendő gyorsítótár-bejegyzések kiválasztásának szabályzata ugyanaz a kiválasztási szabályzat, mint a kiépített számítási adatbázisok esetében, ha a memóriaterhelés magas.
- A gyorsítótár mérete soha nem csökken a minimális virtuális magok által meghatározott minimális memóriakorlát alatt.
A kiszolgáló nélküli és a kiépített számítási adatbázisokban a gyorsítótárbejegyzések kiüríthetők, ha az összes rendelkezésre álló memória használatban van.
Ha a CPU-kihasználtság alacsony, az aktív gyorsítótár kihasználtsága a használati mintától függően magas maradhat, és megakadályozhatja a memória helyrehozását. Más késések is lehetnek, ha a felhasználói tevékenység leáll, mielőtt a memória helyreállása a korábbi felhasználói tevékenységre reagáló periodikus háttérfolyamatok miatt következik be. A törlési műveletek és Query Store törlési feladatok például olyan szellemrekordokat hoznak létre, amelyek törlésre vannak megjelölve, de fizikailag nem törlődnek, amíg a szellemkarbantartási folyamat le nem fut. A ghost cleanup magában foglalhatja az adatoldalak gyorsítótárba való beolvasását.
Gyorsítótár hidratálása
Az SQL memóriagyorsítótára úgy nő, hogy az adatok ugyanúgy és ugyanolyan sebességgel lesznek lekérve a lemezről, mint a kiépített adatbázisok esetében. Ha az adatbázis foglalt, a gyorsítótár korlátlanul növekedhet, amíg rendelkezésre áll a memória.
Lemezgyorsítótár-kezelés
A kiszolgáló nélküli és a kiépített számítási szintek rugalmas skálázási szolgáltatási rétegében minden számítási replika egy Rugalmas pufferkészlet-bővítmény (RBPEX) gyorsítótárat használ, amely az adatoldalakat a helyi SSD-n tárolja az IO-teljesítmény javítása érdekében. A rugalmas skálázás kiszolgáló nélküli számítási rétegében azonban az egyes számítási replikákhoz tartozó RBPEX-gyorsítótár automatikusan növekszik és csökken a számítási feladatok iránti kereslet növekedésére és csökkentésére válaszul. Az RBPEX-gyorsítótár maximális mérete az adatbázishoz konfigurált maximális memória háromszorosa. A maximális memória- és RBPEX automatikus skálázási korlátokról a kiszolgáló nélküli rugalmas skálázási erőforráskorlátokat ismertető cikkben olvashat.
Automatikus szüneteltetés és automatikus folytatás
Jelenleg a kiszolgáló nélküli automatikus szüneteltetés és az automatikus folytatás csak az Általános célú szinten támogatott.
Automatikus szüneteltetés
Az automatikus szüneteltetés akkor aktiválódik, ha az automatikus szüneteltetés késleltetése során az alábbi feltételek teljesülnek:
- A munkamenetek száma = 0
- CPU = 0 (a felhasználói erőforráskészletben futó felhasználói számítási feladatok esetében)
Lehetőség van az automatikus szüneteltetés letiltására, ha szükséges.
Az alábbi funkciók nem támogatják az automatikus szüneteltetést, de támogatják az automatikus skálázást. Ha az alábbi funkciók bármelyikét használja, az automatikus szüneteltetést le kell tiltani, és az adatbázis az adatbázis inaktivitási időtartamától függetlenül online állapotban marad:
- Geo-replikáció (aktív geo-replikáció és átállási csoportok).
- Hosszú távú biztonsági mentési megőrzés (LTR).
- A
SQL Data Sync. A szinkronizálási adatbázisoktól eltérően a hub- és tagadatbázisok támogatják az automatikus szüneteltetést. - A kiszolgáló nélküli adatbázist tartalmazó logikai kiszolgálóhoz létrehozott DNS-alias.
- Elastic Jobs számára az automatikus szüneteltetéssel engedélyezett kiszolgáló nélküli adatbázis nem támogatott feladatadatbázisként. A rugalmas feladatok által megcélzott kiszolgáló nélküli adatbázisok támogatják az automatikus szüneteltetést. A munkakapcsolatok helyreállítják az adatbázist.
Az automatikus szüneteltetés ideiglenesen le van tiltva bizonyos szolgáltatásfrissítések telepítése során, amelyek megkövetelik az adatbázis online állapotba helyezését. Ilyen esetekben az automatikus szüneteltetés a szolgáltatásfrissítés befejeződése után ismét engedélyezve lesz.
Automatikus szüneteltetés hibaelhárítása
Ha az automatikus szüneteltetés engedélyezve van, és az automatikus szüneteltetést letiltó funkciók nem használhatók, de az adatbázis nem szünetelteti automatikusan a késleltetési idő után, akkor előfordulhat, hogy az alkalmazás- vagy felhasználói munkamenetek megakadályozzák az automatikus szüneteltetést.
Annak ellenőrzéséhez, hogy van-e alkalmazás- vagy felhasználói munkamenet, amely az adatbázishoz csatlakozik, csatlakozzon az adatbázishoz bármely ügyféleszköz használatával, és hajtsa végre a következő lekérdezést:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Jótanács
A lekérdezés futtatása után mindenképpen válassza le az adatbázist. Ellenkező esetben a lekérdezés által használt nyitott munkamenet megakadályozza az automatikus szüneteltetést.
- Ha az eredményhalmaz nem üres, az azt jelzi, hogy vannak olyan munkamenetek, amelyek jelenleg megakadályozzák az automatikus szüneteltetést.
- Ha az eredményhalmaz üres, akkor is lehetséges, hogy voltak akár rövid ideig nyitott munkamenetek az automatikus szüneteltetés késleltetési időszakának egy korábbi pontján. Ha a késleltetési időszak alatt szeretne tevékenységet keresni, használhatja a Auditing for Azure SQL Database és Azure Synapse Analytics lehetőséget, és megvizsgálhatja a vonatkozó időszakra vonatkozó naplózási adatokat.
Fontos
A felhasználói erőforráskészletben a nyitott munkamenetek egyidejű CPU-használat melletti vagy anélküli jelenléte a leggyakoribb oka annak, hogy egy kiszolgáló nélküli adatbázis nem szünetel automatikusan a várt módon.
Automatikus újraindítás
Az automatikus újralépés akkor aktiválódik, ha a következő feltételek bármelyike teljesül:
| Tulajdonság | Automatikus folytatásindító |
|---|---|
| Hitelesítés és engedélyezés | Bejelentkezési kísérlet |
| Fenyegetések észlelése | A fenyegetésészlelési beállítások engedélyezése/letiltása adatbázis- vagy kiszolgálószinten. A fenyegetésészlelési beállítások módosítása adatbázis- vagy kiszolgálószinten. |
| Adatfelderítés és -besorolás | Bizalmassági címkék hozzáadása, módosítása, törlése vagy megtekintése |
| Könyvvizsgálat | Audit naplók megtekintése. Auditálási szabályzat frissítése vagy megtekintése. |
| Adatmaszkolás | Adatmaszkoló szabályok hozzáadása, módosítása, törlése vagy megtekintése |
| Transzparens adattitkosítás | A transzparens adattitkosítás állapotának vagy státuszának megtekintése |
| Sebezhetőségi felmérés | Ha engedélyezve van, manuálisan kezdeményezett vizsgálatok és rendszeres vizsgálatok |
| Lekérdezési (teljesítmény-) adattár | Query Store beállításainak módosítása vagy megtekintése |
| Teljesítménnyel kapcsolatos javaslatok | Teljesítményjavaslatok megtekintése vagy alkalmazása |
| Automatikus hangolás | Az automatikus finomhangolási javaslatok, például az automatikus indexelés alkalmazása és ellenőrzése |
| Adatbázis-másolás | Adatbázis létrehozása másolatként. Exportálás BACPAC-fájlba. |
| SQL-adatszinkronizálás | Konfigurálható ütemezés szerint futó vagy manuálisan végrehajtott központi és tagadatbázisok közötti szinkronizálás |
| Bizonyos adatbázis-metaadatok módosítása | Azure címkék hozzáadása vagy módosítása az adatbázisban. A maximális vagy minimális virtuális magok, illetve az automatikus szüneteltetési késleltetés módosítása. |
| SQL Server Management Studio (SSMS) | Ha a 18.1-nél korábbi SSMS-verziókat használja, és új lekérdezési ablakot nyit meg a kiszolgálón található bármely adatbázishoz, az ugyanazon a kiszolgálón lévő automatikusan szüneteltetett adatbázisok újraindulnak. Ez a viselkedés nem fordul elő, ha az SSMS 18.1-es vagy újabb verzióját használja. |
A műveletek bármelyikét végrehajtó figyelési, felügyeleti vagy egyéb megoldások automatikus újraindítást váltanak ki. Az automatikus újramunkálás bizonyos szolgáltatásfrissítések telepítésekor is aktiválódik, amelyekhez az adatbázis online állapotba helyezése szükséges.
Az automatikus újraindítás triggerének azonosítása
Az automatikus folytatási eseményindítók a Azure Monitor tevékenységnaplóban jelennek meg az adatbázisok folytatása műveletekhez a Caller a Started és Sikeres események JSON-jában.
Konnektivitás
Ha egy kiszolgáló nélküli adatbázis szüneteltetve van, az első kapcsolati kísérlet folytatja az adatbázist, és hibaüzenetet ad vissza, amely szerint az adatbázis nem érhető el a 40613-os hibakóddal. Az adatbázis folytatása után próbálkozzon újra a kapcsolattal. A kapcsolat újrapróbálkozási logikai javaslatait követő adatbázis-ügyfeleket nem kell módosítani. A kapcsolat újrapróbálkozási logikai beállításai és javaslatai:
- Kapcsolat újrapróbálkozási logikája az SqlClientben
- Kapcsolódási újrapróbálkozási logika SQL Database-ben az Entity Framework Core használatával
- Kapcsolat újrapróbálkozási logikája az SQL Database-ben az Entity Framework 6 használatával
- Csatlakozási újrapróbálkozási logika az SQL Database használatával az ADO.NET-ben
Latencia
A késleltetés általában körülbelül egy perc az automatikus folytatáshoz, és 1–10 perc az automatikus szüneteltetéshez. Bármelyik művelet késése akár egy másodperces is lehet.
Ügyfél által felügyelt transzparens adattitkosítás (BYOK)
Kulcs törlése vagy visszavonása
Ha az ügyfél által felügyelt transzparens adattitkosítást (BYOK) használja, és a kiszolgáló nélküli adatbázis automatikusan szüneteltetve van a kulcs törlése vagy visszavonása során, akkor az adatbázis automatikusan szüneteltetett állapotban marad. Ebben az esetben az adatbázis következő folytatása után az adatbázis körülbelül 10 percen belül elérhetetlenné válik. Ha az adatbázis elérhetetlenné válik, a helyreállítási folyamat megegyezik a kiépített számítási adatbázisokéval. Ha a kiszolgáló nélküli adatbázis online állapotban van a kulcs törlése vagy visszavonásakor, akkor az adatbázis körülbelül 10 percen belül elérhetetlenné válik, ugyanúgy, mint a kiépített számítási adatbázisok esetében.
Kulcsforgatás
Ha az ügyfél által felügyelt transzparens adattitkosítás (BYOK) és a kiszolgáló nélküli automatikus szüneteltetés engedélyezve van, a kulcsok elforgatásakor az adatbázis automatikusan újraindul. Ezt követően az adatbázis automatikusan szüneteltetve lesz, ha az automatikus szüneteltetési feltételek teljesülnek.
Új kiszolgáló nélküli adatbázis létrehozása
Új adatbázis létrehozása vagy meglévő adatbázis kiszolgáló nélküli számítási szintre való áthelyezése ugyanazt a mintát követi, mint egy új adatbázis létrehozása a kiépített számítási rétegben, és az alábbi két lépést foglalja magában:
Adja meg a szolgáltatás célkitűzését. A szolgáltatási célkitűzés előírja a szolgáltatási szintet, a hardverkonfigurációt és a maximális virtuális magokat. A szolgáltatás célkitűzésének beállításaiért lásd: kiszolgáló nélküli erőforráskorlátok
Akarat szerint adja meg a minimális vCore-ok számát és az automatikus szüneteltetési késleltetést, hogy megváltoztassa az alapértelmezett értékeket. Az alábbi táblázat az ezekhez a paraméterekhez elérhető értékeket mutatja be.
Paraméter Értékválasztások Alapértelmezett érték Minimális vCores A maximális konfigurált virtuális magoktól függ – lásd az erőforráskorlátokat. 0,5 vCore Automatikus megállítás késleltetése Minimum: 15 perc
Maximum: 10 080 perc (hét nap)
Növekmények: 1 perc
Automatikus szüneteltetés letiltása: -160 perc
Az alábbi példák egy új adatbázist hoznak létre a kiszolgáló nélküli számítási szinten.
Azure portál használata
Használja a PowerShellt
Hozzon létre egy új kiszolgáló nélküli általános célú adatbázist a következő PowerShell-példával:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Azure CLI használata
Hozzon létre egy új kiszolgáló nélküli általános célú adatbázist a következő Azure CLI példával:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Transact-SQL (T-SQL) használata
Amikor t-SQL-t használ egy új kiszolgáló nélküli adatbázis létrehozásához, a rendszer az alapértelmezett értékeket alkalmazza a minimális virtuális magokra és az automatikus szüneteltetési késleltetésre. Az értékek később módosíthatók a Azure portálon vagy API-val, beleértve a PowerShellt, a Azure CLI és a REST-t.
További részletekért lásd: CREATE DATABASE.
Hozzon létre egy új, általános célú kiszolgáló nélküli adatbázist a következő T-SQL-példával:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Adatbázis áthelyezése számítási szintek vagy szolgáltatási szintek között
Az adatbázis áthelyezhető a kiépített számítási szint és a kiszolgáló nélküli számítási szint között.
A kiszolgáló nélküli adatbázisok az Általános célú szolgáltatási szintről a Rugalmas skálázás szolgáltatásszintre is áthelyezhetők. További információért lásd: Az adatbázis átalakítása Hyperscale-vá.
Adatbázis számítási szintek közötti áthelyezésekor adja meg a compute modell paramétert Serverless vagy Provisioned a PowerShell vagy a Azure CLI használatakor, vagy a SERVICE_OBJECTIVE t-SQL használatakor. Tekintse át az erőforráskorlátokat a megfelelő szolgáltatási célkitűzés azonosításához.
Az alábbi példák egy meglévő adatbázist helyeznek át a kiépített számításról kiszolgáló nélkülire.
Használja a PowerShellt
Helyezze át a kiépített általános célú számítási adatbázist a kiszolgáló nélküli számítási szintre az alábbi PowerShell-példával:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Azure CLI használata
Helyezze át a kiépített általános célú adatbázist a kiszolgáló nélküli számítási szintre a következő Azure CLI példával:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Transact-SQL (T-SQL) használata
Ha t-SQL-t használ egy adatbázis számítási szintek közötti áthelyezéséhez, a rendszer az alapértelmezett értékeket alkalmazza a minimális virtuális magokra és az automatikus szüneteltetési késleltetésre. Az értékek később módosíthatók a Azure portálon vagy API-val, beleértve a PowerShellt, a Azure CLI és a REST-et. További információkért lásd: ALTER DATABASE.
Helyezze át a kiépített általános célú adatbázist a kiszolgáló nélküli számítási szintre a következő T-SQL-példával:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Kiszolgáló nélküli konfiguráció módosítása
Használja a PowerShellt
A Set-AzSqlDatabase használatával módosíthatja a maximális vagy minimális virtuális magokat, és automatikusan szüneteltetheti a késleltetést. Használja a MaxVcore, MinVcoreés AutoPauseDelayInMinutes az argumentumokat. A rugalmas skálázási réteg jelenleg nem támogatja a kiszolgáló nélküli automatikus szüneteltetést, ezért az automatikus szüneteltetés késleltetési argumentuma csak az általános célú szintre érvényes.
Azure CLI használata
Az sql db-frissítéssel módosíthatja a maximális vagy minimális virtuális magokat, és automatikusan szüneteltetheti a késleltetést. Használja a capacity, min-capacityés auto-pause-delay az argumentumokat. A rugalmas skálázási réteg jelenleg nem támogatja a kiszolgáló nélküli automatikus szüneteltetést, ezért az automatikus szüneteltetés késleltetési argumentuma csak az általános célú szintre érvényes.
Kijelző
Felhasznált és számlázott erőforrások
A kiszolgáló nélküli adatbázisok erőforrásai közé tartoznak az alkalmazáscsomag, az SQL-példány és a felhasználói erőforráskészlet entitásai.
Alkalmazáscsomag
Az alkalmazáscsomag az adatbázis külső legtöbb erőforrás-kezelési határa, függetlenül attól, hogy az adatbázis kiszolgáló nélküli vagy kiépített számítási szinten van-e. Az alkalmazáscsomag tartalmazza az SQL-példányt és a külső szolgáltatásokat, például a teljes szöveges keresést, amelyek együttesen hatókörbe rendezik az adatbázis által az SQL Database-ben használt összes felhasználói és rendszererőforrást. Az SQL-példány általában az alkalmazáscsomag teljes erőforrás-kihasználtságát uralja.
Felhasználói erőforráskészlet
A felhasználói erőforráskészlet egy adatbázis belső erőforrás-kezelési határa, függetlenül attól, hogy az adatbázis kiszolgáló nélküli vagy kiépített számítási szinten van-e. A felhasználói erőforráskészlet hatóköre a DDL (CREATE és ALTER) és a DML (INSERT, UPDATE, DELETE, MERGE és SELECT) lekérdezések által létrehozott felhasználói számítási feladatok processzor- és I/O-hatóköre. Ezek a lekérdezések általában az alkalmazáscsomagban a legnagyobb mértékű kihasználtságot képviselik.
Mértékek
Az alábbi táblázat a kiszolgáló nélküli adatbázisok alkalmazáscsomagjának és felhasználói erőforráskészletének erőforrás-használatának figyelésére szolgáló metrikákat tartalmazza, beleértve a georeplikákat is:
| Entitás | Mértékegység | Leírás | Egységek |
|---|---|---|---|
| Alkalmazáscsomag | alkalmazás_cpu_százalék | Az alkalmazás által használt virtuális magok százalékos aránya az alkalmazás számára engedélyezett maximális virtuális magokhoz viszonyítva. Kiszolgáló nélküli rugalmas skálázás esetén ez a metrika az összes elsődleges replikához, elnevezett replikához és georeplikához elérhető. | Százalék |
| Alkalmazáscsomag | alkalmazás_cpu_számlázott | Az alkalmazásnak a jelentési időszakban számlázott számítási mennyisége. Az ebben az időszakban kifizetett összeg ennek a mutatónak és a vCore egységárának a szorzata. A metrika értékeit a felhasznált processzor és a másodpercenként használt memória maximális értékének összesítésével határozzuk meg. Ha a felhasznált mennyiség kisebb, mint a minimális virtuális magok és a minimális memória által meghatározott minimális kiosztott összeg, akkor a minimális kiosztott összeg lesz számlázva. A processzor és a memória számlázási célú összehasonlítása érdekében a memóriát vCore egységekre alakítjuk át: a memória mennyiségét gigabájtban (GB) 3 GB/vCore átváltással adjuk meg. A kiszolgáló nélküli rugalmas skálázás esetében ez a metrika az elsődleges replika és a nevesített replikák számára lesz közzétéve. |
virtuális mag másodpercben |
| Alkalmazáscsomag | app_cpu_számlázott_HA_replikák | Csak kiszolgáló nélküli rugalmas skálázás esetén alkalmazható. A HA-replikákhoz tartozó összes alkalmazásra kiszámlázott számítás összege a jelentési időszakban. Ez az összeg az elsődleges replikához tartozó HA-replikákra vagy az adott elnevezett replikához tartozó HA-replikákra terjed ki. Az összeg HA-replikák közötti kiszámítása előtt az egyes HA-replikákért számlázott számítási összeg ugyanúgy lesz meghatározva, mint az elsődleges vagy a nevesített replika esetében. Kiszolgáló nélküli rugalmas skálázás esetén ez a metrika az összes elsődleges replikához, elnevezett replikához és georeplikához elérhető. A jelentési időszakban kifizetett összeg ennek a mutatónak és a virtuális mag egységárának a szorzata. | virtuális mag másodpercben |
| Alkalmazáscsomag | alkalmazás_memória_százalék | Az alkalmazás által az alkalmazás által használt memória százalékos aránya az alkalmazás számára engedélyezett maximális memória függvényében. Kiszolgáló nélküli rugalmas skálázás esetén ez a metrika az összes elsődleges replikához, elnevezett replikához és georeplikához elérhető. | Százalék |
| Felhasználói erőforráskészlet | CPU százalék | A felhasználói számítási feladat által használt virtuális magok százalékos aránya a felhasználói számítási feladatokhoz engedélyezett maximális virtuális magokhoz képest. | Százalék |
| Felhasználói erőforráskészlet | adat_I/O_százalék | A felhasználói számítási feladatok által használt IOPS-adatok százalékos aránya a felhasználói számítási feladatokhoz engedélyezett maximális IOPS-adatokhoz képest. | Százalék |
| Felhasználói erőforráskészlet | log_IO_százalék | A felhasználói számítási feladat által használt napló MB/s százalékos aránya a felhasználói számítási feladatokhoz engedélyezett maximális napló MB/s-értékhez képest. | Százalék |
| Felhasználói erőforráskészlet | munkások százaléka | A felhasználói számítási feladatok által használt dolgozók százalékos aránya a felhasználói számítási feladatokhoz engedélyezett maximális feldolgozókhoz képest. | Százalék |
| Felhasználói erőforráskészlet | munkamenetek százaléka | A felhasználói számítási feladatok által használt munkamenetek százalékos aránya a felhasználói számítási feladatok számára engedélyezett maximális munkamenetekhez képest. | Százalék |
Szüneteltetés és folytatás állapota
Az automatikus szüneteltetést engedélyező kiszolgáló nélküli adatbázisok esetében a jelentésekben szereplő állapot a következő értékeket tartalmazza:
| Státusz | Leírás |
|---|---|
| Online | Az adatbázis online állapotban van. |
| Megállítás | Az adatbázis online állapotról szüneteltetettre vált. |
| Szüneteltetett | Az adatbázis szüneteltetve van. |
| Folytatás | Az adatbázis átáll a szüneteltetettről az online állapotra. |
Azure portál használata
A Azure portálon az adatbázis állapota megjelenik az adatbázis áttekintési oldalán és a kiszolgáló áttekintési oldalán. A Azure portálon is megtekintheti a kiszolgáló nélküli adatbázisok szüneteltetési és folytatási eseményeinek előzményeit a Activity naplóban.
Használja a PowerShellt
Tekintse meg az adatbázis aktuális állapotát a következő PowerShell-példával:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Azure CLI használata
Tekintse meg az adatbázis aktuális állapotát a következő Azure CLI példával:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Erőforráskorlátok
Az erőforráskorlátokért tekintse meg a kiszolgáló nélküli számítási szintet.
Számlázás
A kiszolgáló nélküli adatbázisokhoz számlázott számítási mennyiség a felhasznált processzor és a másodpercenként használt memória maximális mennyisége. Ha a felhasznált processzor és memória mennyisége kisebb, mint az egyes erőforrásokhoz kiosztott minimális mennyiség, akkor a kiosztott összeg számlázása történik. A processzor és a memória számlázási célokra való összehasonlítása érdekében a rendszer a memóriát virtuális magok egységére normalizálja a GB-nak a virtuális magonkénti 3 GB-tal történő újraskálázásával.
- Erőforrás számlázása: CPU és memória
- Számlázott összeg: virtuális mag egységára * maximális (minimális virtuális magok, felhasznált virtuális magok, minimális memória GB * 1/3, felhasznált memória GB * 1/3)
- Számlázási gyakoriság: Másodpercenként
A vCore egységára az egy vCóra másodpercenkénti költsége.
Az adott régió egyes egységáraiért tekintse meg a Azure SQL Database díjszabási oldalt.
Az általános célú adatbázisok, illetve a rugalmas skálázású elsődleges vagy elnevezett replikák kiszolgáló nélküli számlázott számítási mennyiségét a következő metrika teszi közzé:
- Metrika: app_cpu_billed (virtuális mag másodperc)
- Definíció: maximális (minimális virtuális magok, használt virtuális magok, minimális memória GB * 1/3, felhasznált memória GB * 1/3)
- Jelentési gyakoriság: Másodpercenkénti mérések alapján, 1 perc alatt összesítve.
Az elsődleges replikához vagy bármely elnevezett replikához tartozó rugalmas skálázású HA-replikák kiszolgáló nélküli számlázott számítási mennyiségét a következő metrika teszi közzé:
- Metrika: app_cpu_billed_HA_replicas (virtuális mag másodperc)
- Definíció: A szülőerőforráshoz tartozó HA-replikák maximális (minimális virtuális magok, használt virtuális magok, minimális memória GB * 1/3, felhasznált memória GB * 1/3) összege.
- Szülőerőforrás és metrikavégpont: Az elsődleges replika és minden nevesített replika külön-külön teszi elérhetővé ezt a metrikát, amely a társított HA-replikákhoz számlázott számítást méri.
- Jelentési gyakoriság: Másodpercenkénti mérések alapján, 1 perc alatt összesítve.
Minimális számítási költség
Ha egy kiszolgáló nélküli adatbázis szüneteltetve van, akkor a számítási számla nulla. Ha egy kiszolgáló nélküli adatbázis nincs felfüggesztve, akkor a minimális számítási számla nem kisebb, mint a maximális virtuális magok mennyisége (minimális virtuális magok, minimális memória GB * 1/3).
Példák:
- Tegyük fel, hogy az Általános célú szinten egy kiszolgáló nélküli adatbázis nincs felfüggesztve, és 8 maximális virtuális maggal és 1 minimális virtuális maggal van konfigurálva, amely 3,0 GB minimális memóriának felel meg. Ezután a minimális számítási számla a maximális értéken alapul (1 virtuális mag, 3,0 GB * 1 virtuális mag / 3 GB) = 1 virtuális mag.
- Tegyük fel, hogy az Általános célú szinten egy kiszolgáló nélküli adatbázis nincs felfüggesztve, és 4 maximális virtuális maggal és 0,5 minimális virtuális maggal van konfigurálva, amely 2,1 GB minimális memóriának felel meg. Ezután a minimális számítási számla a maximális (0,5 virtuális mag, 2,1 GB * 1 virtuális mag / 3 GB) = 0,7 virtuális magon alapul.
- Tegyük fel, hogy egy serverless adatbázis a Hyperscale szinten rendelkezik egy elsődleges replikával, egy HA replikával és egy elnevezett replikával, amelynek nincsenek HA-replikái. Tegyük fel, hogy minden replika 8 maximális virtuális maggal és 1 minimális virtuális maggal van konfigurálva, amely 3 GB minimális memóriának felel meg. Ezután az elsődleges replika, a HA replika és az elnevezett replika minimális számítási számlája a maximális (1 virtuális mag, 3 GB * 1 virtuális mag / 3 GB) = 1 virtuális mag alapján történik.
A kiszolgáló nélküli Azure SQL Database díjszabási kalkulátor a maximális és minimális virtuális magok száma alapján konfigurálható minimális memória meghatározására használható. Ha a minimálisan konfigurált virtuális magok száma nagyobb, mint 0,5 virtuális mag, akkor a minimális számítási számla független a minimálisan konfigurált memóriától, és csak a konfigurált minimális virtuális magok számán alapul.
Példaforgatókönyvek
Fontolja meg egy kiszolgáló nélküli adatbázist az Általános célú szinten, amely 1 minimális virtuális maggal és 4 maximális virtuális maggal van konfigurálva. Ez a konfiguráció körülbelül 3 GB minimális memóriának és 12 GB maximális memóriának felel meg. Tegyük fel, hogy az automatikus szüneteltetés késleltetése 6 órára van állítva, és az adatbázis számítási feladatai aktívak egy 24 órás időszak első 2 órájában, és egyébként inaktívak.
Ebben az esetben az adatbázis számlázása az első 8 órában történik a számításért és a tárolásért. Annak ellenére, hogy az adatbázis a második óra után inaktív, a következő 6 órában továbbra is kiszámlázzuk a számításért az adatbázis online állapotában kiosztott minimális számítás alapján. Csak a tárterület számlázása történik a 24 órás időszak hátralévő részében, amíg az adatbázis szüneteltetve van.
Pontosabban az ebben a példában szereplő számítási számlát a következőképpen számítjuk ki:
| Időintervallum | Másodpercenként használt virtuális magok | Másodpercenként használt GB | A kiszámlázott számítási dimenzió | Időintervallumonként számlázott virtuális mag másodperce |
|---|---|---|---|---|
| 0:00-1:00 | 4 | 9 | Használt virtuális magok | 4 virtuális mag * 3600 másodperc = 14 400 virtuális mag másodperc |
| 1:00-2:00 | 1 | 12 | Felhasznált memória | 12 GB * 1/3 * 3600 másodperc = 14 400 virtuális mag másodperc |
| 2:00-8:00 | 0 | 0 | Minimálisan kiosztott memória | 3 GB * 1/3 * 21 600 másodperc = 21 600 virtuális mag másodperc |
| 8:00-24:00 | 0 | 0 | Szüneteltetés alatt nincs számlázás a számításért | 0 vCore másodperc |
| 24 óra alatt számlázott összes virtualis processzormag másodperc | 50 400 virtuális mag másodperc |
Tegyük fel, hogy a számítási egység ára $0.000145/vCore/second. Ezután a 24 órás időszakra kiszámlázott számítás a számítási egység árából és a számlázott virtuális mag másodpercek szorzatából áll: 0,000145 USD/vCore/másodperc * 50 400 virtuális mag másodperc ~ 7,31 USD.
Azure Hybrid Benefit és foglalások
Azure Hybrid Benefit (AHB) és Azure Foglalási kedvezmények nem vonatkoznak a kiszolgáló nélküli számítási szintre.
Elérhető régiók
A régiókra vonatkozó rendelkezésre állással kapcsolatban lásd: Az Azure SQL Database kiszolgáló nélküli rendelkezésre állása régiónként.
Kapcsolódó tartalom
- Első lépésként tekintse meg a Adatbázis létrehozása – Azure SQL Database című témakört.
- A kiszolgáló nélküli szolgáltatási szint választásával kapcsolatban lásd az Általános célú és a Rugalmas skálázás című témakört.