Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez az oktatóanyag egy Azure Batch-számítási feladatot futtató Azure Data Factory-folyamat létrehozását és futtatását mutatja be. Egy Python-szkript fut a Batch-csomópontokon, és vesszővel tagolt (CSV) bemenetet kap egy Azure Blob Storage-tárolóból, módosítja az adatokat, majd a kimenetet egy másik tárolóba írja. A Batch Explorerrel fürtöket és csomópontokat hozhat létre, az Azure Storage Explorert pedig tárolók és fájlok kezelésére használhatja.
Ebben az oktatóanyagban az alábbiakkal fog megismerkedni:
- Batch-készlet és csomópontok létrehozásához használja a Batch Explorert.
- Tárolók létrehozásához és bemeneti fájlok feltöltéséhez használja a Storage Explorert.
- Python-szkript fejlesztése a bemeneti adatok kezeléséhez és a kimenet előállításához.
- Hozzon létre egy Data Factory-folyamatot, amely a Batch számítási feladatát futtatja.
- A Kimeneti naplófájlok megtekintéséhez használja a Batch Explorert.
Előfeltételek
- Egy Azure-fiók, aktív előfizetéssel. Ha még nincs előfizetése, hozzon létre egy ingyenes fiókot.
- Csatolt Azure Storage-fiókkal rendelkező Batch-fiók. A fiókokat az alábbi módszerek bármelyikével hozhatja létre: Azure Portal | Azure CLI | |
- Egy Data Factory példány. Az adat-előállító létrehozásához kövesse a Data Factory létrehozása című témakör utasításait.
- Letöltötte és telepítette a Batch Explorert .
- A Storage Explorer letöltve és telepítve van.
-
Python 3.8 vagy újabb, a azure-storage-blob csomag telepítve
piphasználatával. - A GitHubról letöltött iris.csv bemeneti adatkészlet .
Batch-készlet és csomópontok létrehozása a Batch Explorerrel
Számítási csomópontok készletének létrehozásához használja a Batch Explorert a számítási feladatok futtatásához.
Jelentkezzen be a Batch Explorerbe azure-beli hitelesítő adataival.
Válassza ki a Batch fiókot.
A bal oldali oldalsávon válassza a Készletek lehetőséget, majd a készlet hozzáadásához kattintson az + ikonra.
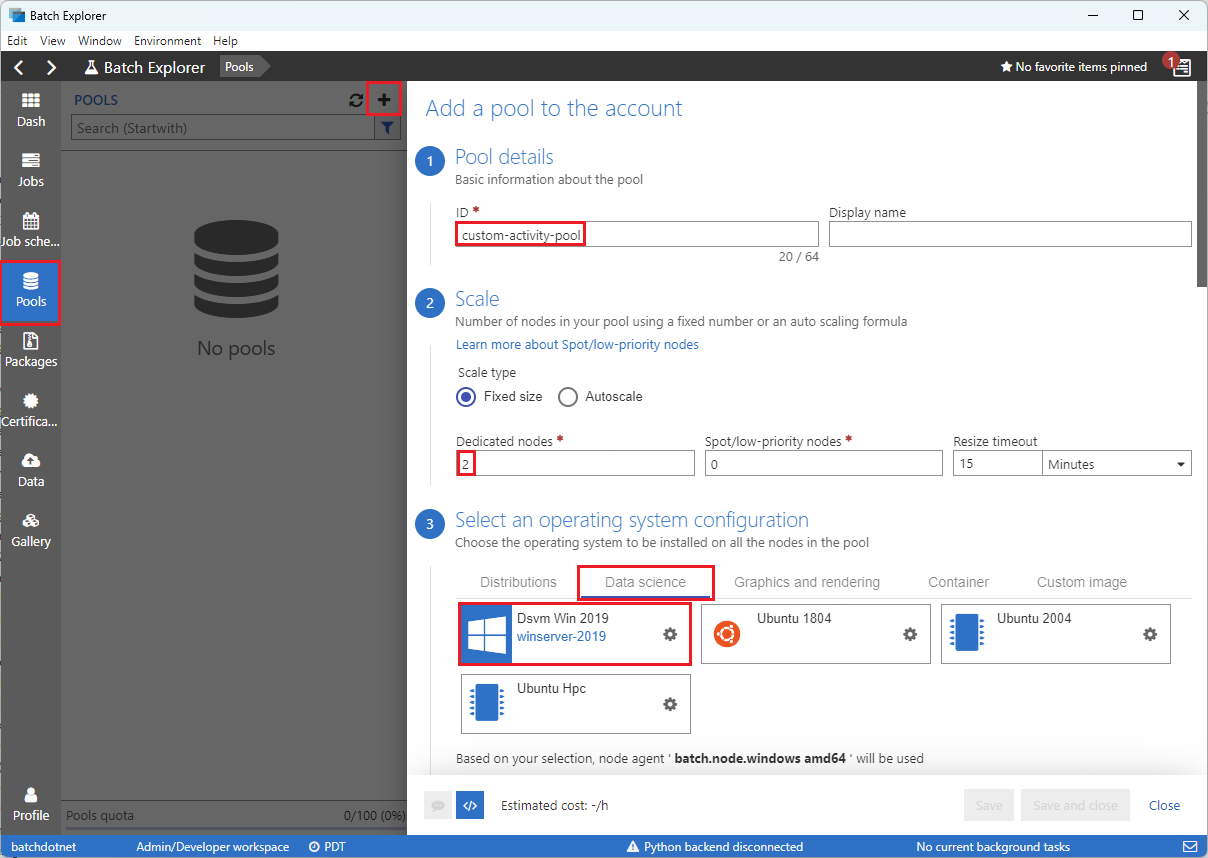
Töltse ki a Medence hozzáadása a fiókhoz űrlapot az alábbiak szerint:
- Az azonosító mezőbe írja be a custom-activity-pool értéket.
- A Dedikált csomópontok területen adja meg a 2 értéket.
- Az operációs rendszer konfigurációjának kiválasztásához válassza az Adatelemzés lapot, majd a Dsvm Win 2019 lehetőséget.
- A virtuális gép méretének kiválasztásához válassza a Standard_F2s_v2 lehetőséget.
-
Folyamat Indítás esetén válassza a Kezdő feladat hozzáadása lehetőséget.
A kezdőfeladat képernyőn, a Parancssor alatt adja meg
cmd /c "pip install azure-storage-blob pandas", majd válassza a Kiválasztás lehetőséget. Ez a parancs az indításkor telepíti aazure-storage-blobcsomagot az egyes csomópontokra.
Válassza a Mentés és bezárás lehetőséget.

Blobtárolók létrehozása a Storage Explorer használatával
A Storage Explorer használatával blobtárolókat hozhat létre a bemeneti és kimeneti fájlok tárolásához, majd feltöltheti a bemeneti fájlokat.
- Jelentkezzen be a Storage Explorerbe azure-beli hitelesítő adataival.
- A bal oldali oldalsávon keresse meg és bontsa ki a Batch-fiókhoz társított tárfiókot.
- Kattintson a jobb gombbal a BlobTárolók elemre, és válassza a Blobtároló létrehozása parancsot, vagy válassza a Blobtároló létrehozása az oldalsáv alján található Műveletek parancsot.
- Írja be a bemenetet a beviteli mezőbe.
- Hozzon létre egy másik, kimenetnek nevezett blobtárolót.
- Válassza ki a bemeneti tárolót, majd válassza >lehetőséget a jobb oldali panelen.
- A Fájlok feltöltése képernyőn, a Kijelölt fájlok csoportban válassza ki a három pontot ... a beviteli mező mellett.
- Keresse meg a letöltött iris.csv fájl helyét, válassza a Megnyitás, majd a Feltöltés lehetőséget.

Python-szkript fejlesztése
Az alábbi Python-szkript betölti a iris.csv adathalmazfájlt a Storage Explorer bemeneti tárolójából, módosítja az adatokat, és menti az eredményeket a kimeneti tárolóba.
A szkriptnek a Batch-fiókhoz társított Azure Storage-fiók kapcsolati sztringet kell használnia. A kapcsolati karakterlánc lekérése:
- Az Azure Portalon keresse meg és válassza ki a Batch-fiókhoz társított tárfiók nevét.
- A tárfiók oldalán válassza az Access-kulcsokat a bal oldali navigációs sáv Biztonság + hálózatkezelés területén.
- Key1 alatt válassza a Megjelenítés lehetőséget a Kapcsolati sztring mellett, majd kattintson a Másolás ikonra a kapcsolati sztring másolásához.
Illessze be a kapcsolati karakterláncot a következő szkriptbe, és cserélje le a <storage-account-connection-string> helyőrzőt. Mentse a szkriptet main.py nevű fájlként.
Fontos
Az alkalmazás forrásában lévő fiókkulcsok közzététele éles használat esetén nem ajánlott. Korlátoznia kell a hitelesítő adatokhoz való hozzáférést, és változók vagy konfigurációs fájlok használatával hivatkoznia kell rájuk a kódban. A Legjobb, ha Batch- és Storage-fiókkulcsokat tárol az Azure Key Vaultban.
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Az Azure Blob Storage használatával kapcsolatos további információkért tekintse meg az Azure Blob Storage dokumentációját.
Futtassa a szkriptet helyileg a funkciók teszteléséhez és ellenőrzéséhez.
python main.py
A szkriptnek egy iris_setosa.csv nevű kimeneti fájlt kell létrehoznia, amely csak a Species = setosa nevű adatrekordokat tartalmazza. Miután ellenőrizte, hogy megfelelően működik-e, töltse fel a main.py szkriptfájlt a Storage Explorer bemeneti tárolóba .
Data Factory-pipeline beállítása
Hozzon létre és érvényesítsen egy Data Factory-folyamatot, amely a Python-szkriptet használja.
Fiókadatok lekérése
A Data Factory-folyamat a Batch- és Storage-fiókneveket, a fiókkulcsértékeket és a Batch-fiókvégpontot használja. Az Azure portálról ezek az információk lekérhetők:
Az Azure Search sávon keresse meg és válassza ki a Batch-fiók nevét.
A Batch-fiók lapján válassza a bal oldali navigációs sáv Kulcsok elemét.
Másolja a következő értékeket a Kulcsok lapra:
- Batch-fiók
- Felhasználói fiók végpont
- Elsődleges hozzáférési kulcs
- Tárolófiók neve
- 1. kulcs
A folyamat létrehozása és futtatása
Ha az Azure Data Factory Studio még nem fut, válassza a Stúdió indítása lehetőséget a Data Factory oldalán az Azure portálon.
A Data Factory Studióban válassza a Szerző ceruza ikont a bal oldali navigációs sávon.
A Gyári erőforrások területen válassza a + ikont, majd válassza a Folyamat lehetőséget.
A jobb oldali Tulajdonságok panelen módosítsa a folyamat nevét Python-futtatásra.
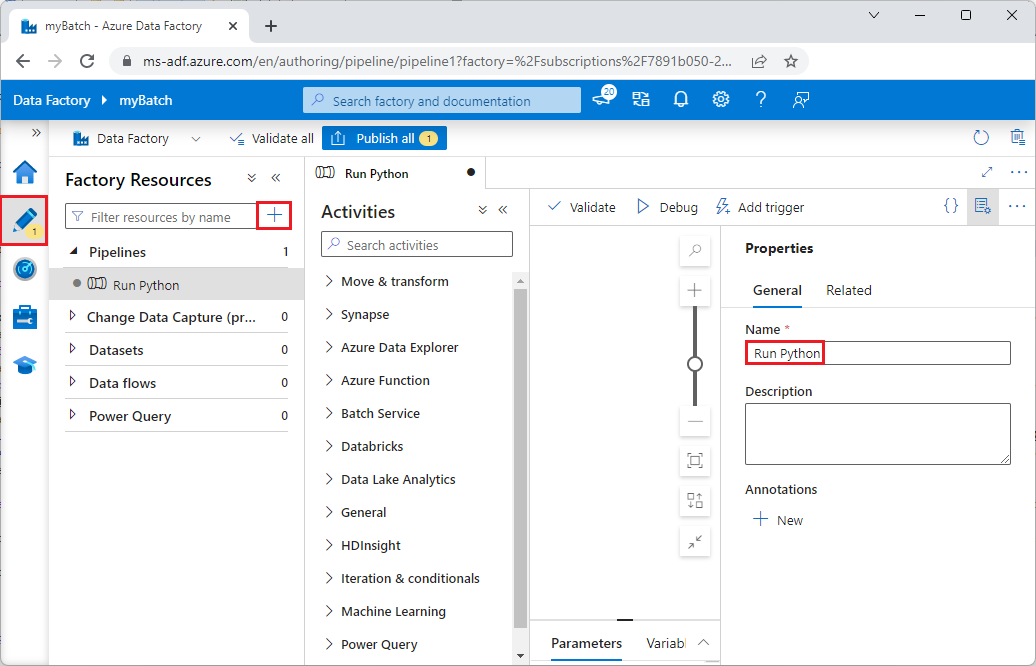
A Tevékenységek panelen bontsa ki a Batch Service elemet, és húzza az egyedi tevékenységet a folyamattervező felületére.
A tervezővászon alatt, az Általános lapon írja be a testPipeline nevet a Név mezőbe.
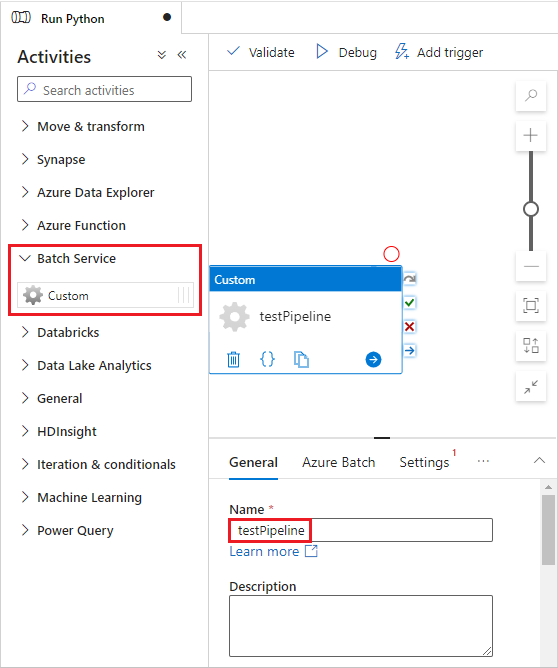
Válassza az Azure Batch lapot, majd az Új lehetőséget.
Töltse ki az Új társított szolgáltatás űrlapot az alábbiak szerint:
- Név: Adja meg a társított szolgáltatás nevét, például az AzureBatch1 nevet.
- Hozzáférési kulcs: Adja meg a Batch-fiókból másolt elsődleges hozzáférési kulcsot.
- Fiók neve: Adja meg a Batch-fiók nevét.
-
Batch URL-cím: Adja meg a Batch-fiókból másolt fiókvégpontot, például
https://batchdotnet.eastus.batch.azure.com. - Készlet neve: Adja meg az egyéni tevékenységkészletet, a Batch Explorerben létrehozott készletet.
- Tárfiók társított szolgáltatásnév: Válassza az Új lehetőséget. A következő képernyőn adja meg a társított társzolgáltatás nevét (például AzureBlobStorage1), válassza ki az Azure-előfizetést és a társított tárfiókot, majd válassza a Létrehozás lehetőséget.
A Batch Új társított szolgáltatás képernyő alján válassza a Kapcsolat tesztelése lehetőséget. Ha a kapcsolat sikeres, válassza a Létrehozást.
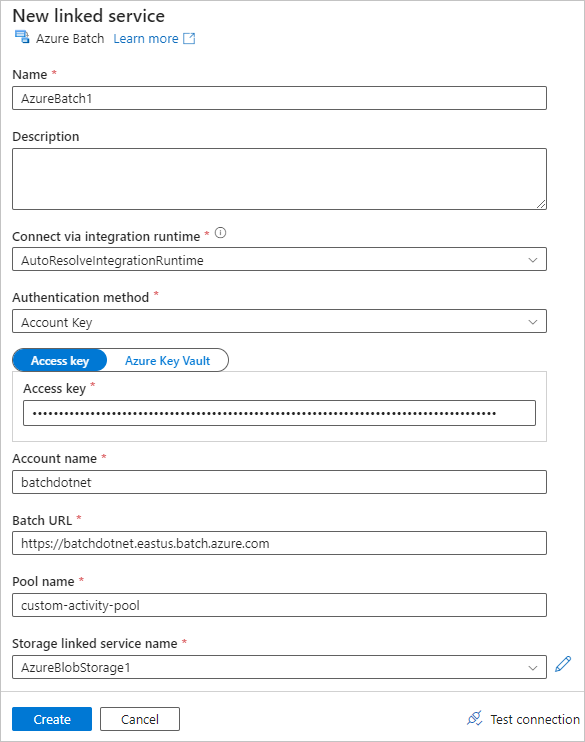
Válassza a Beállítások lapot, és adja meg vagy válassza ki a következő beállításokat:
-
Parancs: Nyomja meg az
cmd /C python main.pybillentyűt. - Erőforráshoz társított szolgáltatás: Válassza ki a létrehozott társított tárolási szolgáltatást (például az AzureBlobStorage1 szolgáltatást), és tesztelje a kapcsolatot, hogy biztosan sikeres legyen.
- Mappa elérési útja: Válassza ki a mappa ikont, majd válassza a bemeneti tárolót, majd kattintson az OK gombra. A mappa fájljai a Python-szkript futtatása előtt letöltődnek a tárolóból a készletcsomópontokra.
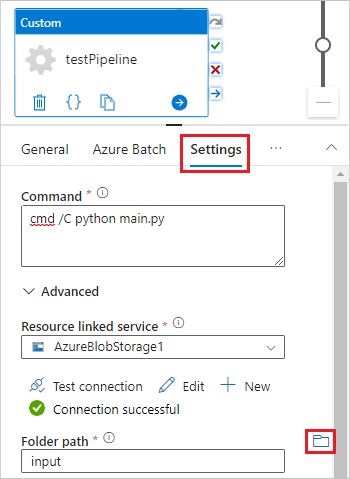
-
Parancs: Nyomja meg az
A folyamat ellenőrzéséhez válassza az Ellenőrzés lehetőséget a folyamat eszköztárán.
Válassza a Hibakeresés lehetőséget a folyamat teszteléséhez és megfelelő működésének biztosításához.
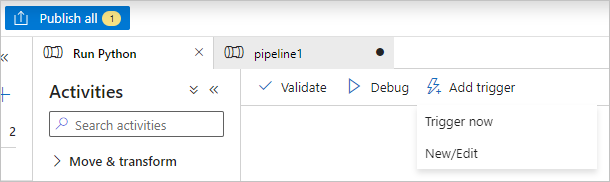
Válassza az Összes közzététele lehetőséget a folyamat közzétételéhez.
Válassza az Eseményindító hozzáadása lehetőséget, majd válassza az Eseményindító lehetőséget a folyamat futtatásához, vagy az Új/Szerkesztés lehetőséget a folyamat ütemezéséhez.

Naplófájlok megtekintése a Batch Explorerrel
Ha a folyamat futtatása figyelmeztetéseket vagy hibákat okoz, a Batch Explorerrel további információkért tekintheti meg a stdout.txt és stderr.txt kimeneti fájlokat.
- A Batch Explorerben válassza a Feladatok lehetőséget a bal oldali oldalsávon.
- Válassza ki az adfv2-custom-activity-pool feladatot.
- Válasszon ki egy hibát tartalmazó kilépési kódot tartalmazó feladatot.
- Tekintse meg a stdout.txt és stderr.txt fájlokat a probléma kivizsgálásához és diagnosztizálásához.
Az erőforrások rendbetétele
A Batch-fiókok, munkák és feladatok ingyenesek, de a számítási egységek akkor is költséget generálnak, amikor nem futtatnak munkákat. A legideálisabb, ha a csomópontkészleteket csak szükség szerint foglalja le, és ha már nincs rájuk szükség, törölje a csomópontkészleteket. A készletek törlése törli a csomópontok összes tevékenységkimenetét, és maguk a csomópontok is.
A bemeneti és kimeneti fájlok a tárfiókban maradnak, és díjakat vonhatnak maga után. Ha már nincs szüksége a fájlokra, törölheti a fájlokat vagy tárolókat. Ha már nincs szüksége a Batch-fiókra vagy a csatolt tárfiókra, törölheti őket.
Következő lépések
Ebben az oktatóanyagban megtanulta, hogyan futtathat Python-szkripteket a Batch Explorerrel, a Storage Explorerrel és a Data Factoryvel a Batch-számítási feladatok futtatásához. További információ a Data Factoryről: Mi az Az Azure Data Factory?