Sémaeltolódás a leképezési adatfolyamban
A következőkre vonatkozik:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
A sémaeltolódás az a helyzet, amikor a források gyakran módosítják a metaadatokat. A mezők, oszlopok és típusok menet közben hozzáadhatók, eltávolíthatók vagy módosíthatók. A sémaeltolódás kezelése nélkül az adatfolyam sebezhetővé válik a felsőbb rétegbeli adatforrások változásaival szemben. A tipikus ETL-minták sikertelenek, ha a bejövő oszlopok és mezők megváltoznak, mert általában ezekhez a forrásnevekhez vannak kötve.
A sémaelsodódás elleni védelem érdekében fontos, hogy az adatfolyam-eszközben található létesítmények lehetővé tegyék, hogy adatmérnök:
- Olyan források definiálása, amelyek mezőnevekkel, adattípusokkal, értékekkel és méretekkel rendelkeznek
- Olyan átalakítási paraméterek definiálása, amelyek a rögzített mezők és értékek helyett adatmintákkal is használhatók
- Definiáljon olyan kifejezéseket, amelyek úgy értelmezik a mintákat, hogy megfeleljenek a bejövő mezőknek nevesített mezők használata helyett
Az Azure Data Factory natív módon támogatja azokat a rugalmas sémákat, amelyek végrehajtásról végrehajtásra változnak, így általános adatátalakítási logikát hozhat létre az adatfolyamok újrafordítása nélkül.
Architekturális döntést kell hoznia az adatfolyamban, hogy elfogadja a sémaeltolódást a folyamat során. Ha ezt teszi, védelmet nyújthat a források sémamódosításai ellen. Az oszlopok és a típusok korai kötése azonban a teljes adatfolyamban elveszik. Az Azure Data Factory késő kötésű folyamatként kezeli a sémaeltolódási folyamatokat, így az átalakítások létrehozásakor a sodródott oszlopnevek nem lesznek elérhetők a sémanézetekben a folyamat során.
Ez a videó bemutatja az Azure Data Factoryben vagy a Synapse Analytics-folyamatokban könnyen építhető összetett megoldások némelyikét az adatfolyam sémaeltolódási funkciójával. Ebben a példában rugalmas adatbázisséma alapján készítünk újrahasználható mintákat:
Sémaeltolódás a forrásban
A forrásdefinícióból az adatfolyamba érkező oszlopok "sodródottként" vannak definiálva, ha nincsenek jelen a forrásvetítésben. A forrásvetítést a forrásátalakítás kivetítés lapján tekintheti meg. Amikor kiválaszt egy adathalmazt a forráshoz, a szolgáltatás automatikusan átveszi a sémát az adathalmazból, és létrehoz egy előrejelzést az adathalmaz sémadefiníciójából.
A forrásátalakítás során a sémaeltolódás olyan olvasóoszlopokként van definiálva, amelyek nincsenek definiálva az adathalmaz sémájában. A sémaeltolódás engedélyezéséhez ellenőrizze a sémaeltolódás engedélyezése a forrásátalakításban.
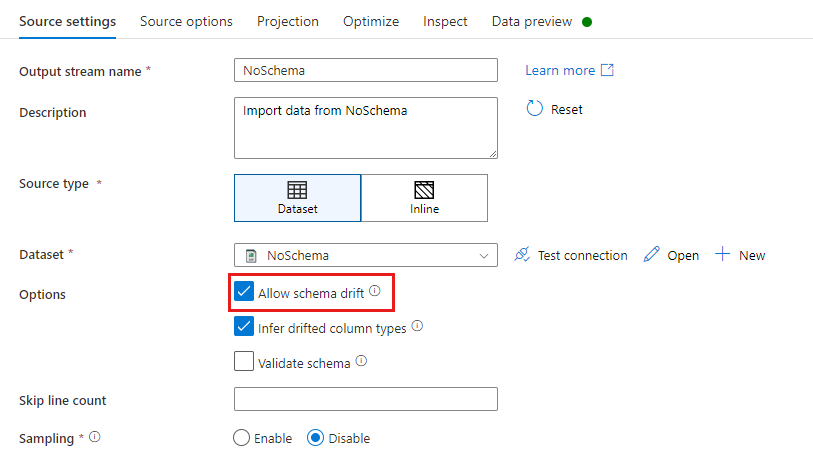
Ha a sémaeltolódás engedélyezve van, a rendszer a végrehajtás során beolvassa az összes bejövő mezőt a forrásból, és átadja a teljes folyamatot a fogadónak. Alapértelmezés szerint minden újonnan észlelt oszlop, más néven sodródott oszlop sztring típusú adattípusként érkezik. Ha azt szeretné, hogy az adatfolyam automatikusan következtetjen az elsodródott oszlopok adattípusára, ellenőrizze a forrásbeállítások között az elsodródott oszloptípusokat .
Sémaeltolódás a fogadóban
A fogadó transzformációjában a sémaeltolódás az, amikor további oszlopokat ír a fogadó adatsémában meghatározottak fölé. A sémaeltolódás engedélyezéséhez ellenőrizze a sémaeltolódás engedélyezése a fogadóátalakításban.
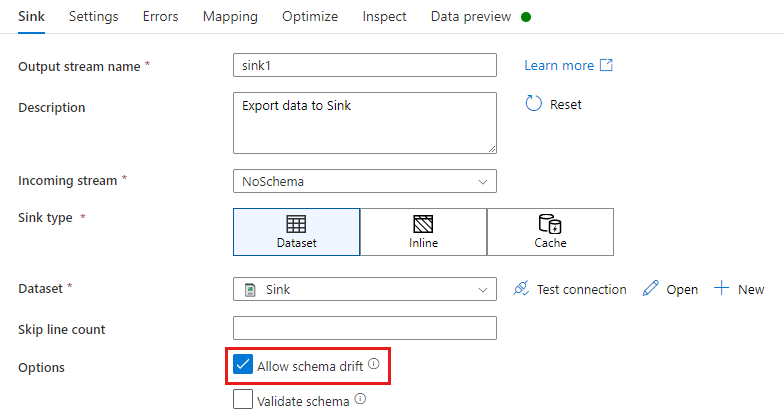
Ha a sémaeltolódás engedélyezve van, győződjön meg arról, hogy be van kapcsolva az Automatikus leképezés csúszka a Leképezés lapon. Ha be van kapcsolva ez a csúszka, a rendszer minden bejövő oszlopot a célhelyre ír. Ellenkező esetben szabályalapú leképezést kell használnia az elsodródott oszlopok írásához.
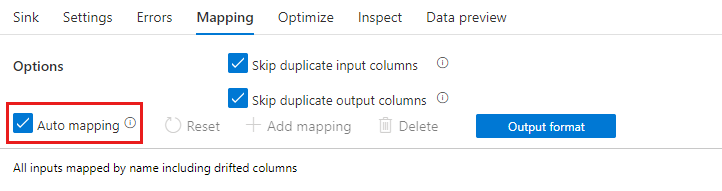
Elsodródott oszlopok átalakítása
Ha az adatfolyam sodródott oszlopokat tartalmaz, az alábbi módszerekkel érheti el őket az átalakításokban:
- Az és
byNameabyPositionkifejezések használatával explicit módon hivatkozhat egy oszlopra név vagy pozíciószám alapján. - Oszlopminta hozzáadása származtatott oszlop- vagy összesítési átalakításhoz a név, stream, pozíció, forrás vagy típus bármilyen kombinációjának megfelelően
- Szabályalapú megfeleltetés hozzáadása a Kijelölés vagy fogadó átalakításban az elsodródott oszlopok és az oszlopok aliasainak egy mintán keresztüli egyeztetése érdekében
Az oszlopminták implementálásával kapcsolatos további információkért lásd : Oszlopminták a leképezési adatfolyamban.
Elsodródott oszlopok leképezése – gyorsművelet
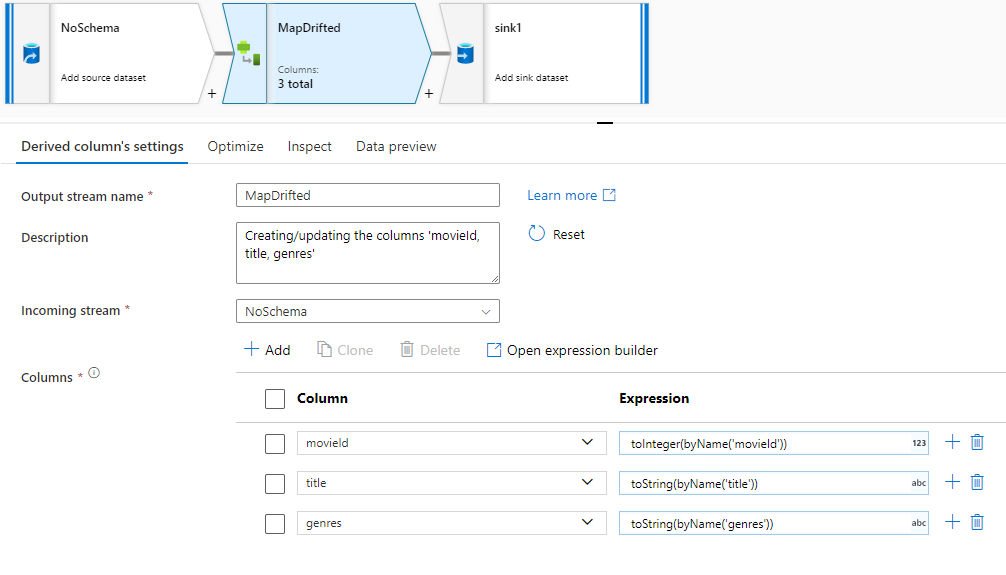
Ha explicit módon szeretne hivatkozni az elsodródott oszlopokra, gyorsan létrehozhat leképezéseket ezekhez az oszlopokhoz az adatelőnézet gyorsműveletének használatával. Ha be van kapcsolva a hibakeresési mód, lépjen az Adatok előnézete lapra, és kattintson a Frissítés gombra egy adatelőnézet lekéréséhez. Ha a Data Factory észleli, hogy az elsodródott oszlopok léteznek, kattintson az Elsodródott leképezés elemre, és hozzon létre egy származtatott oszlopot, amely lehetővé teszi, hogy a sémanézetek összes sodródott oszlopára hivatkozzon lefelé.
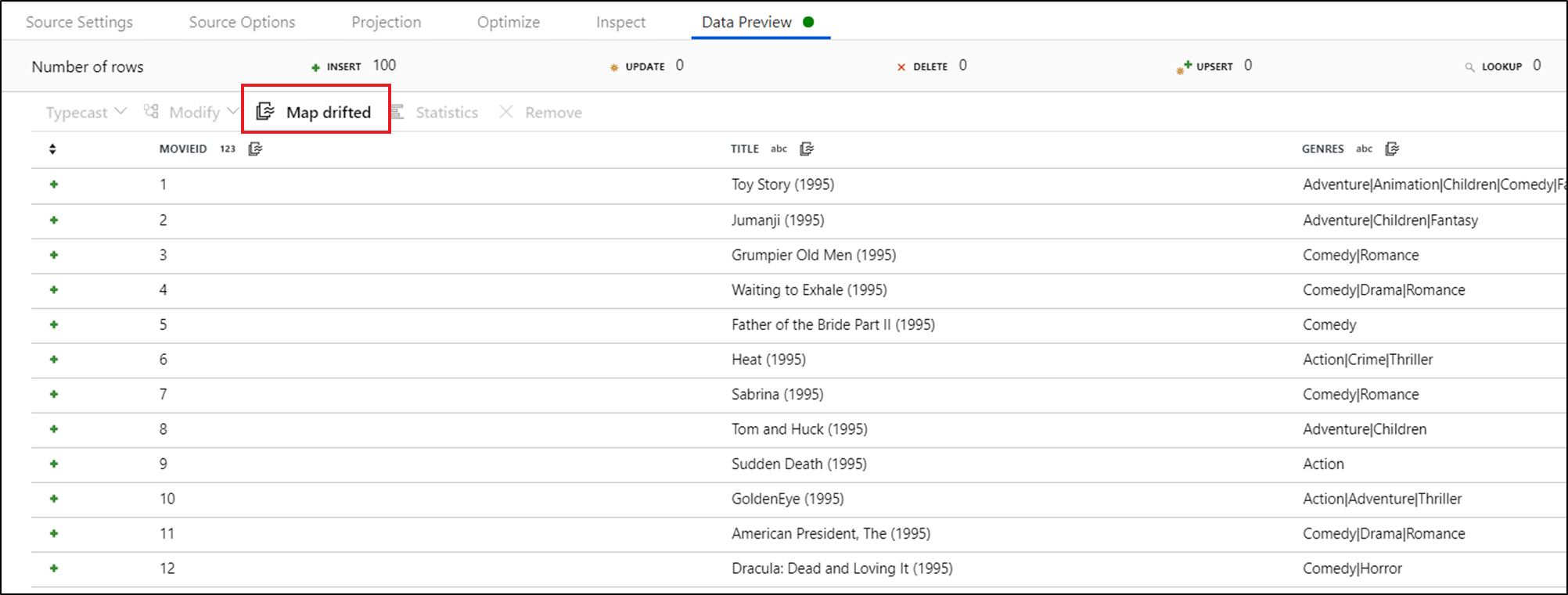
A létrehozott származtatott oszlop átalakítás során minden sodródott oszlop az észlelt névhez és adattípushoz van leképezve. A fenti adatelőnézetben a rendszer a movieId oszlopot egész számként észleli. Miután a Leképezés elmozdult elemére kattintott, a movieId a Származtatott oszlopban lesz definiálva, és toInteger(byName('movieId')) szerepel a sémanézetekben az alsóbb rétegbeli átalakításokban.
Kapcsolódó tartalom
A Adatfolyam Kifejezésnyelvben további lehetőségeket talál az oszlopmintákhoz és a sémaeltolódáshoz, beleértve a "byName" és a "byPosition" elemet.