Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
A Microsoft Azure Data Factoryben az adatfolyamok leképezésével rögzített szélességű szöveges fájlokból alakíthatja át az adatokat. Az alábbi feladatban meghatározunk egy adatkészletet egy elválasztójel nélküli szövegfájlhoz, majd beállítjuk a részszűrési felosztásokat az ordinális pozíció alapján.
Folyamat létrehozása
Új folyamat létrehozásához válassza az +Új folyamat lehetőséget.
Adjon hozzá egy adatfolyam-tevékenységet, amely rögzített szélességű fájlok feldolgozására szolgál:
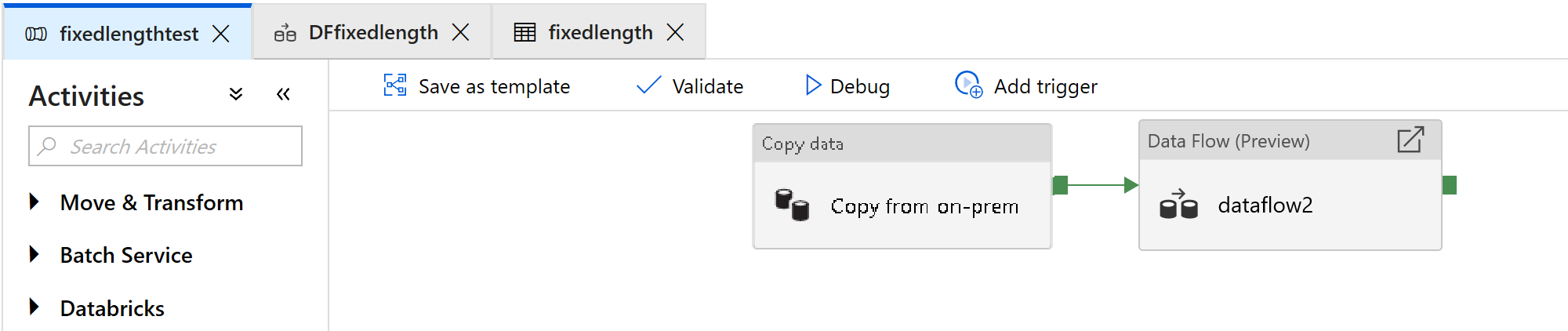
Az adatfolyam-tevékenységben válassza az Új leképezési adatfolyam lehetőséget.
Forrás-, származtatott oszlop-, kijelölés- és fogadóátalakítás hozzáadása:
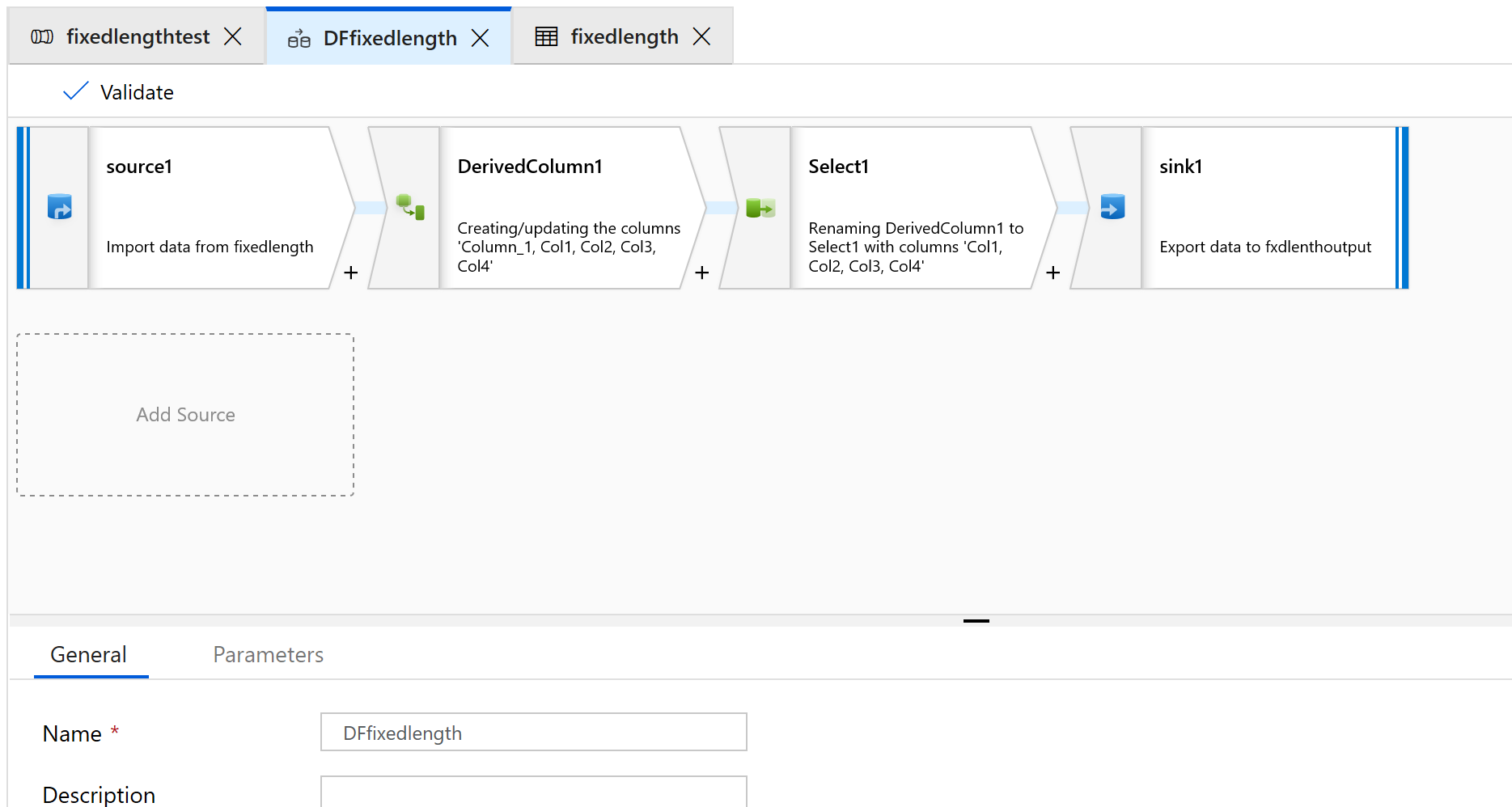
Konfigurálja a forrásátalakítást úgy, hogy egy új adatkészletet használjon, amely tagolt szöveg típusú lesz.
Ne állítson be oszlopelválasztót vagy fejlécet.
Most meg fogjuk adni a mező kezdőpontjait és hosszát a fájl tartalmához:
1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468A Forrásátalakítás Előrejelzés lapján egy Column_1 nevű karakterláncoszlopnak kell megjelennie.
A Származtatott oszlopban hozzon létre egy új oszlopot.
Egyszerű neveket adunk az oszlopoknak, például az 1.
A kifejezésszerkesztőben írja be a következőket:
substring(Column_1,1,4)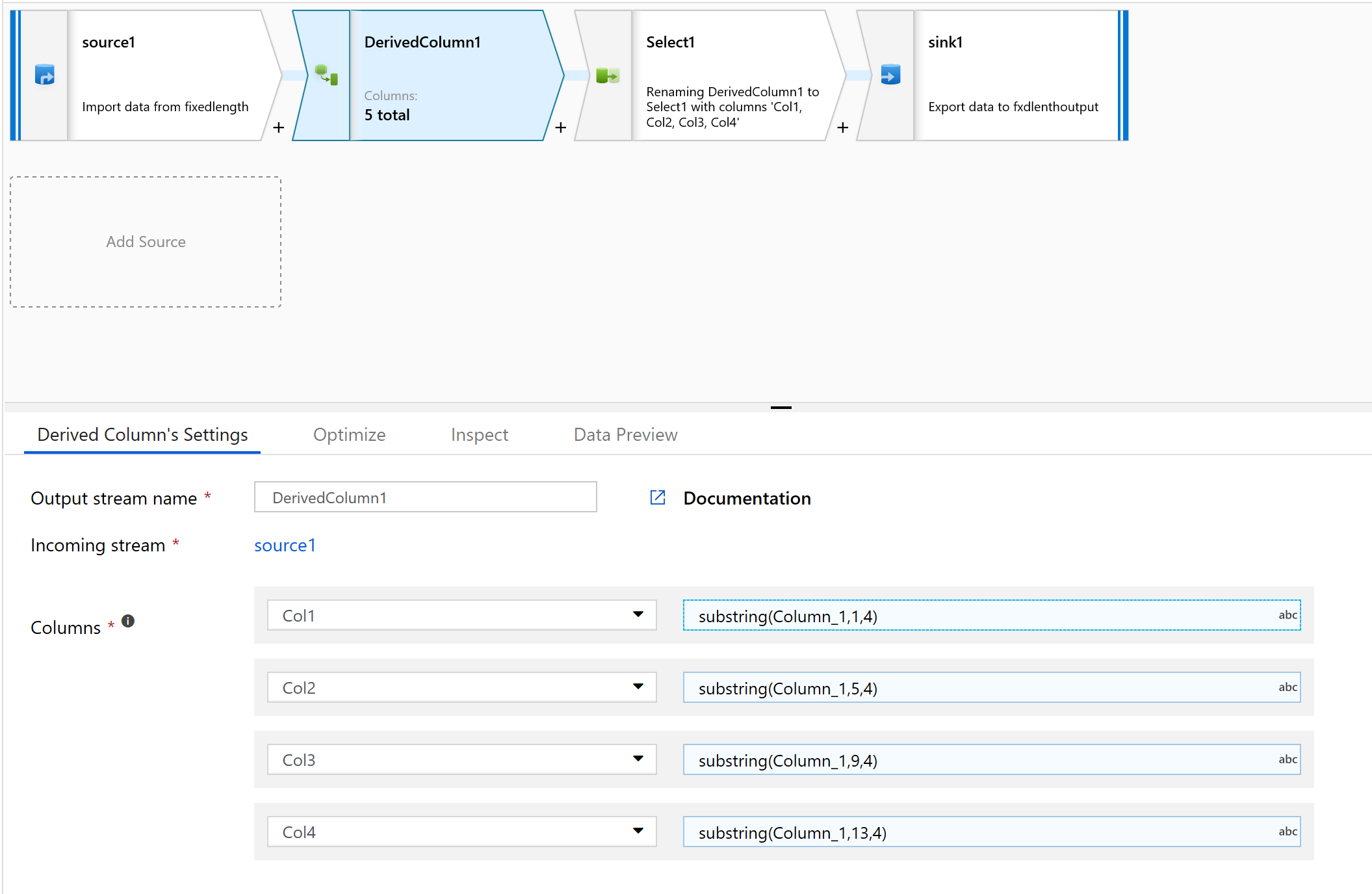
Ismételje meg a 10. lépést az összes elemezni kívánt oszlop esetében.
Válassza a Vizsgálat lapot a létrehozandó új oszlopok megtekintéséhez:
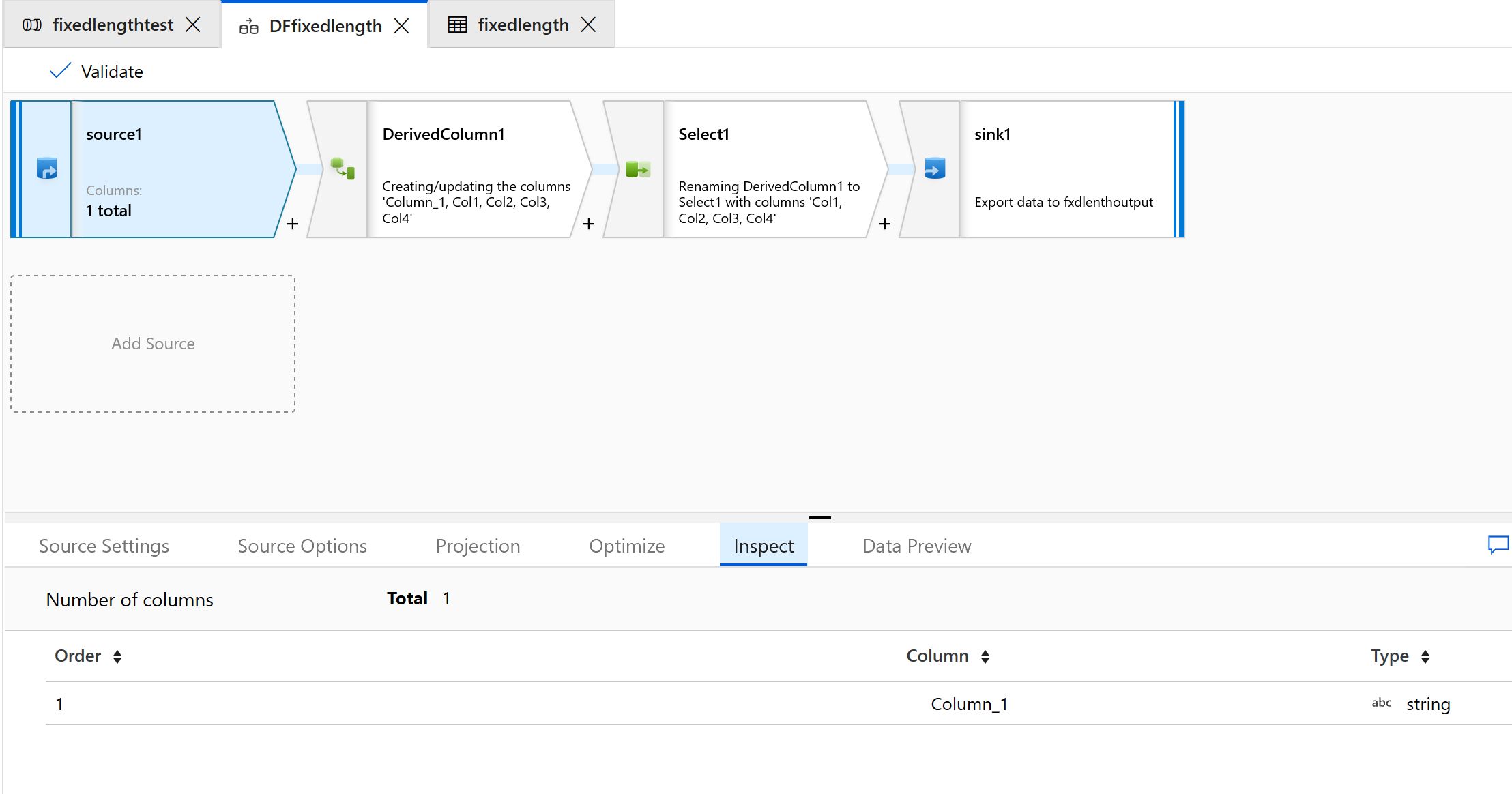
A Kijelölés átalakítás használatával eltávolíthatja az átalakításhoz nem szükséges oszlopokat:
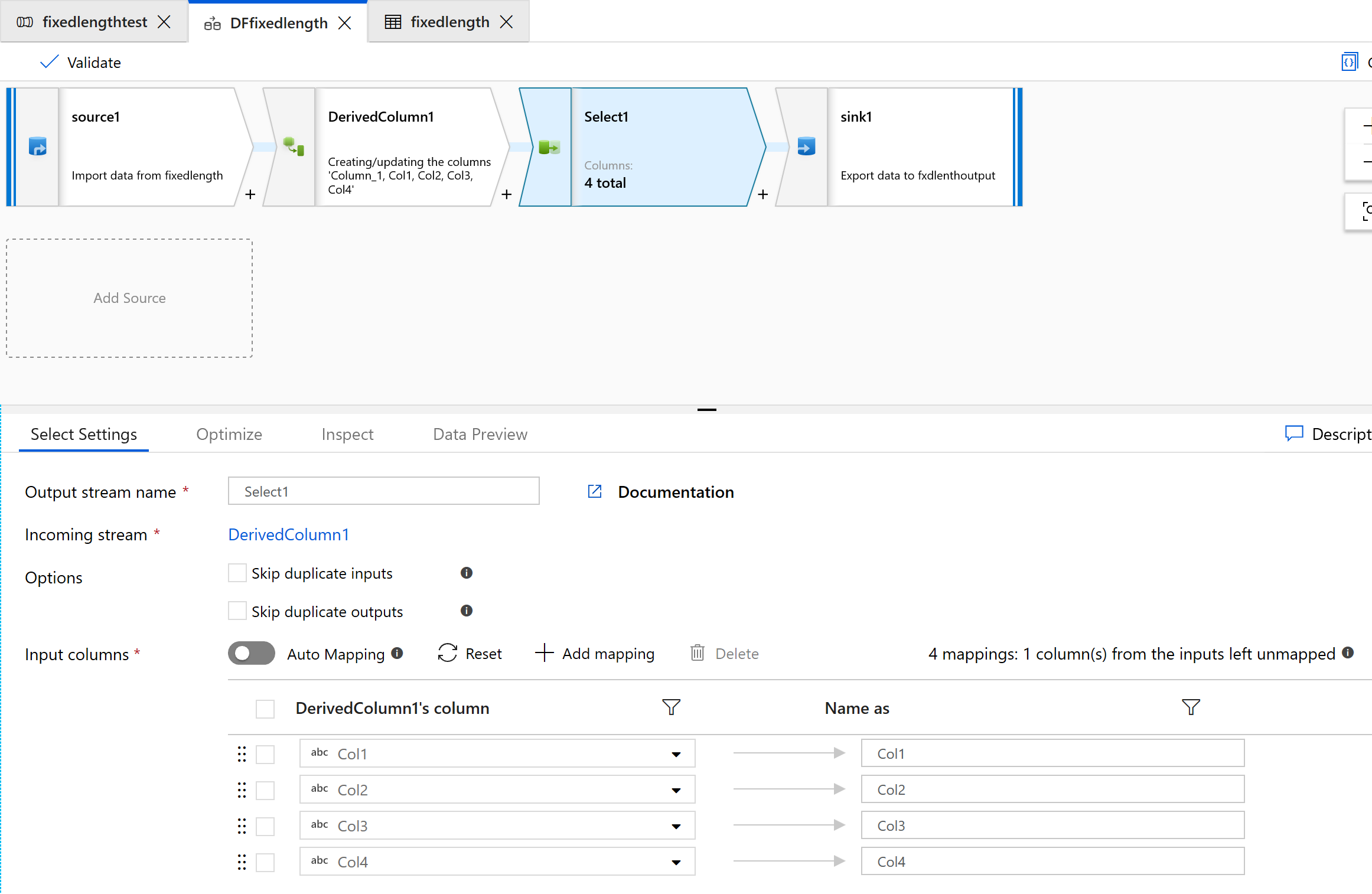
A Fogadóval az adatokat egy mappába lehet kihozni:
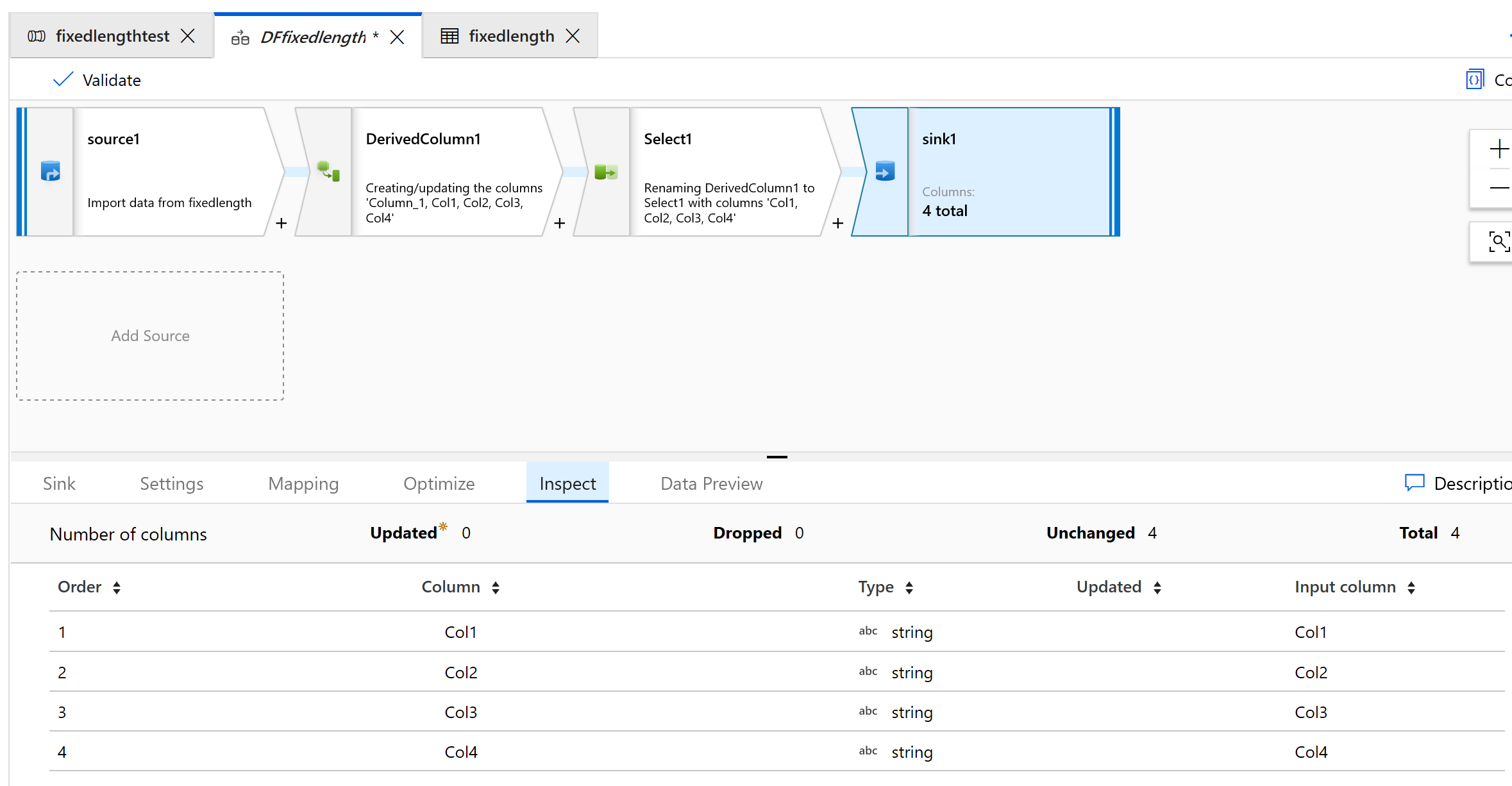
A kimenet a következőképpen fog kinézni:
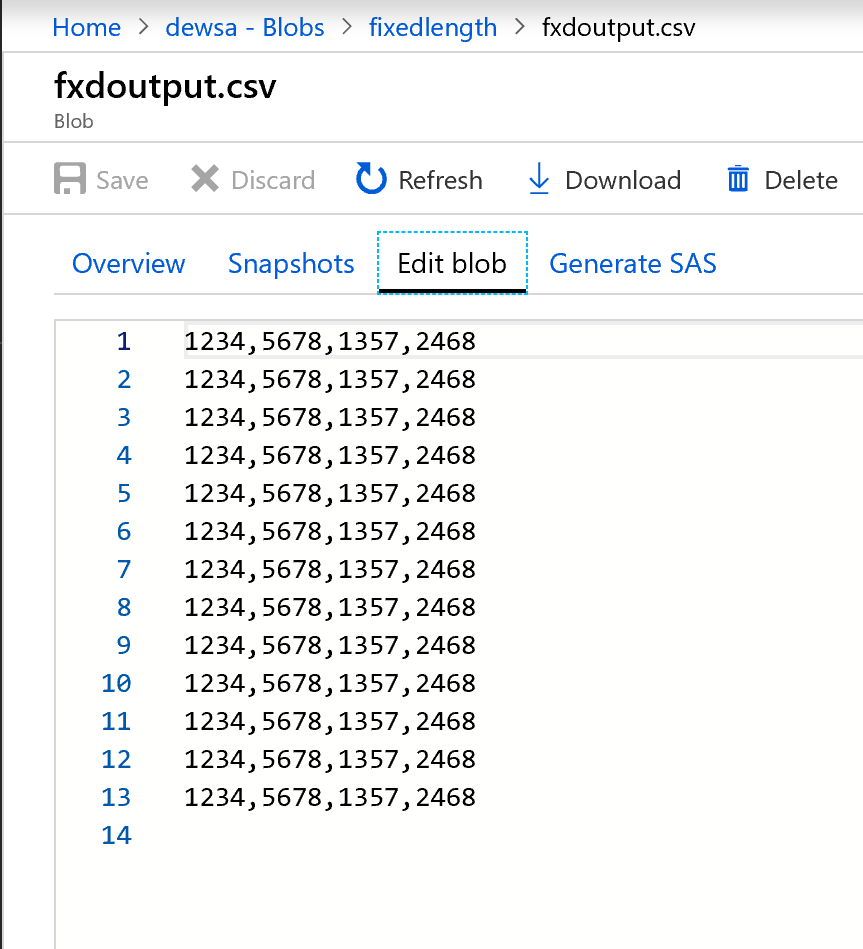
A rögzített szélességű adatok most fel vannak osztva négy karakterrel, és a Col1, Col2, Col3, Col4 stb. Az előző példa alapján az adatok négy oszlopra oszlanak.
Kapcsolódó tartalom
- Az adatfolyam-átalakítások leképezésével hozza létre a többi adatfolyam-logikát.