Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Ha még nem ismerkedik a Azure Data Factory, tekintse meg a Bevezetés a Azure Data Factory című témakört.
Ebben az oktatóanyagban megismerheti azokat az ajánlott eljárásokat, amelyek akkor alkalmazhatók, ha fájlokat ír az ADLS Gen2-be vagy Azure Blob Storage adatfolyamok használatával. Egy Azure Blob Storage-fiókhoz vagy Azure Data Lake Store Gen2-fiókhoz kell hozzáférnie egy parquet-fájl olvasásához, majd az eredmények mappákban való tárolásához.
Előfeltételek
- Azure előfizetés. Ha nem rendelkezik Azure előfizetéssel, a kezdés előtt hozzon létre egy free Azure fiókot.
- Azure tárolófiók. Az ADLS-tárolót forrás- és fogadóadattárként használja. Ha nincs tárfiókja, a A Azure tárfiók létrehozása a létrehozás lépéseit ismerteti.
Az oktatóanyag lépései feltételezik, hogy rendelkezik
Adat-előállító létrehozása
Ebben a lépésben adatgyárat hoz létre, és megnyitja a Data Factory UX-t egy munkafolyamat létrehozásához az adatgyárban.
Nyissa meg Microsoft Edge vagy Google Chrome. A Data Factory felhasználói felülete jelenleg csak a Microsoft Edge és a Google Chrome böngészőkben támogatott.
A bal oldali menüben válassza a Erőforrás létrehozása, >, Adatgyár lehetőséget.
Az Új adatgyár lapján, a Név mezőben adja meg az ADFTutorialDataFactory nevet.
Válassza ki azt a Azure subscription, amelyben létre szeretné hozni az adat-előállítót.
Erőforráscsoport: hajtsa végre a következő lépések egyikét:
a). Kattintson a Meglévő használata elemre, majd a legördülő listából válasszon egy meglévő erőforráscsoportot.
b. Kattintson az Új létrehozása elemre, és adja meg az erőforráscsoport nevét. Az erőforráscsoportokról a A Azure erőforráscsoportok kezelése című témakörben olvashat.
A Verzió résznél válassza a V2 értéket.
A Hely területen válassza ki az adat-előállító helyét. A legördülő listán csak a támogatott helyek jelennek meg. Az adat-előállító által használt adattárak (például Azure Storage és SQL Database) és számítások (például Azure HDInsight) más régiókban is lehetnek.
Válassza a Létrehozás lehetőséget.
A létrehozás befejezése után megjelenik az értesítés az Értesítések központban. Válassza az Ugrás az erőforrásra lehetőséget a Data Factory lapra való navigáláshoz.
A Data Factory felhasználói felületének külön lapon történő elindításához válassza a Létrehozás és figyelés csempét.
Folyamat létrehozása adatfolyam-tevékenységgel
Ebben a lépésben egy adatfolyam-tevékenységet tartalmazó folyamatot fog létrehozni.
A Azure Data Factory kezdőlapján válassza a Orchestrate lehetőséget.
A folyamat Általános lapján adja meg a DeltaLake nevet a folyamat nevéhez.
A gyári felső sávon kapcsolja be a Data Flow hibakeresés csúszkát. A hibakeresési mód lehetővé teszi az átalakítási logika interaktív tesztelését egy élő Spark-fürtön. Data Flow fürtök bemelegedése 5-7 percet vesz igénybe, és a felhasználóknak ajánlott először bekapcsolniuk a hibakeresést, ha Data Flow fejlesztést terveznek. További információ: Hibakeresési mód.
A Tevékenységek panelen bontsa ki az Áthelyezés és átalakítás harmonika elemet. Húzza a Data Flow aktivitást a panelről a pipeline vászonra.
Átalakítási logika létrehozása az adatfolyam-vásznon
Minden forrásadatot (ebben az oktatóanyagban Parquet-fájlforrást fogunk használni) fogjuk használni, és fogadó-átalakítással parquet formátumban fogjuk lehozni az adatokat a data lake ETL leghatékonyabb mechanizmusainak használatával.

Oktatóanyag célkitűzései
- Válasszon ki bármelyik forrásadatkészletet egy új adatfolyamban 1. Adatfolyamok használata a fogadó adatkészlet hatékony particionálásához
- Tárold a particionált adatokat az ADLS Gen2 tározómappáiban
Kezdés egy üres adatfolyam-vászonról
Először is állítsuk be az adatfolyam-környezetet az ADLS Gen2-ben az alábbiakban ismertetett összes mechanizmushoz
- Kattintson a forrás átalakítására.
- Kattintson az adathalmaz melletti új gombra az alsó panelen.
- Válasszon egy adatkészletet, vagy hozzon létre egy újat. Ebben a bemutatóban egy Felhasználói adatok nevű Parquet-adatkészletet fogunk használni.
- Adjon hozzá egy származtatott oszlop transzformációt. Ezzel a módszerrel dinamikusan állíthatja be a kívánt mappaneveket.
- Mosogató átalakítás hozzáadása.
Hierarchikus mappa kimenet
Nagyon gyakori, hogy az adatok egyedi értékeit használva mappahierarchiákat hoz létre az adatok particionálásához a tóban. Ez egy nagyon optimális módszer az adatok rendszerezésére és feldolgozására a tóban és a Sparkban (az adatfolyamok mögötti számítási motorban). A kimenet ilyen módon történő rendszerezésének azonban kisebb teljesítményköltsége lesz. Csővezeték teljesítményének összességében kis mértékű csökkenésére számíthat a kimeneten ezzel a mechanizmussal.
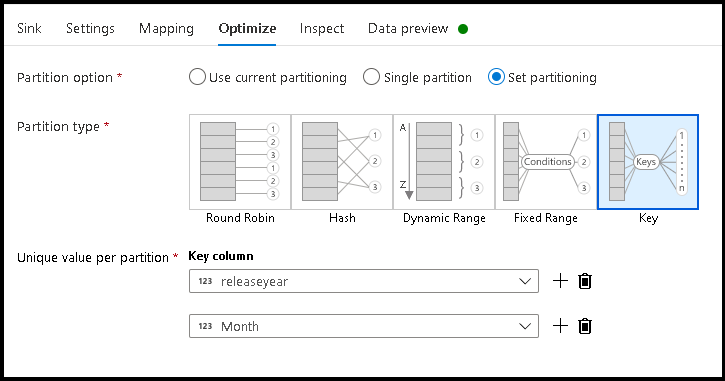
- Térjen vissza az adatfolyam-tervezőhöz, és szerkessze a fenti adatfolyam-létrehozást. Kattintson a csap átalakításra.
- Kattintson az Optimalizálás > Particionálási kulcs beállítása > elemre
- Válassza ki a hierarchikus mappastruktúra beállításához használni kívánt oszlop(ok)t.
- Az alábbi példában a mappaelnevezés oszlopai az év és a hónap nevet használják. Az eredmények az űrlap
releaseyear=1990/month=8mappái lesznek. - Amikor egy adatfolyam-forrás adatpartícióihoz fér hozzá, csak a fenti
releaseyearlegfelső szintű mappára mutat, és minden további mappához helyettesítő karaktermintát használ, például:**/**/*.parquet - Ha módosítani szeretné az adatértékeket, vagy akár szintetikus értékeket is létre szeretne hozni a mappanevekhez, a Származtatott oszlop átalakításával hozza létre a mappanevekben használni kívánt értékeket.
Névmappa adatértékként
Az ADLS Gen2-re épülő kimeneti technika, amely a lake data esetében valamivel jobban teljesít, de nem kínálja ugyanazokat az előnyöket, mint a kulcs-/értékparticionálás.Name folder as column data Míg a hierarchikus struktúra kulcsparticionálási stílusa lehetővé teszi az adatszeletek könnyebb feldolgozását, ez a technika egy lapított mappastruktúra, amely gyorsabban tud adatokat írni.
- Térjen vissza az adatfolyam-tervezőhöz, és szerkessze a fenti adatfolyam-létrehozást. Kattintson a csap átalakításra.
- Kattintson a Partíció optimalizálása > Partíciók beállítása > Jelenlegi partíció használata opcióra.
- Kattintson a Beállítások > Nevezze el a mappát oszlopadatokként.
- Válassza ki a mappanevek létrehozásához használni kívánt oszlopot.
- Ha módosítani szeretné az adatértékeket, vagy akár szintetikus értékeket is létre szeretne hozni a mappanevekhez, a Származtatott oszlop átalakításával hozza létre a mappanevekben használni kívánt értékeket.
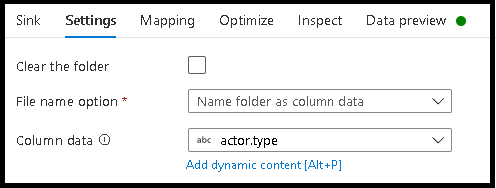
Névfájl adatértékként
A fenti oktatóanyagokban felsorolt technikák jól használhatók mappakategóriák létrehozására a data lake-ben. Az ilyen technikák által alkalmazott alapértelmezett fájlelnevezési séma a Spark-végrehajtói feladatazonosító használata. Előfordulhat, hogy a kimeneti fájl nevét egy adatfolyam szöveggyűjtőjében szeretné beállítani. Ez a technika csak kis fájlokhoz javasolt. A partíciófájlok egyetlen kimeneti fájlba való egyesítésének folyamata egy hosszú ideig futó folyamat.
- Térjen vissza az adatfolyam-tervezőhöz, és szerkessze a fenti adatfolyam-létrehozást. Kattintson a csap átalakításra.
- Kattintson az Optimalizálás > Particionálás beállítása > Egypartícióra elemre. Ez az egyetlen partíciókövetelmény szűk keresztmetszetet okoz a végrehajtási folyamatban a fájlok egyesítésekor. Ez a beállítás csak kis méretű fájlok esetén ajánlott.
- Kattintson a Beállítások > elemre, és nevezze el a fájlt oszlopadatok szerint.
- Válassza ki a fájlnevek létrehozásához használni kívánt oszlopot.
- Ha módosítani szeretné az adatértékeket, vagy akár szintetikus értékeket is létre szeretne hozni a fájlnevekhez, a Származtatott oszlop átalakításával hozza létre a fájlnevekben használni kívánt értékeket.