Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk a köteg és a streamelés közötti fő különbségeket ismerteti, az adatelemzési számítási feladatokhoz használt két különböző adatfeldolgozási szemantikát, köztük a betöltést, az átalakítást és a valós idejű feldolgozást.
A streamelés általában alacsony késéssel és az üzenetbuszok, például az Apache Kafka folyamatos feldolgozásával jár.
Az Azure Databricksben azonban kiterjedtebb definícióval rendelkezik. A Lakeflow Spark Deklaratív folyamatok (Apache Spark és Strukturált streamelés) mögöttes motorja egységes architektúrával rendelkezik a kötegelt és streamelési feldolgozáshoz:
- A motor a hatékony növekményes feldolgozás érdekében streamforrásként kezelheti az olyan forrásokat, mint a felhőobjektum-tárolás és a Delta Lake .
- A streamfeldolgozás aktivált és folyamatos módon is futtatható, így rugalmasan szabályozhatja a streamelési számítási feladatok költségeinek és teljesítménybeli kompromisszumoit.
Az alábbiakban az alapvető szemantikai különbségeket mutatjuk be, amelyek megkülönböztetik a kötegeket és a streamelést, beleértve azok előnyeit és hátrányait, valamint a számítási feladatokhoz való kiválasztásának szempontjait.
Köteg szemantika
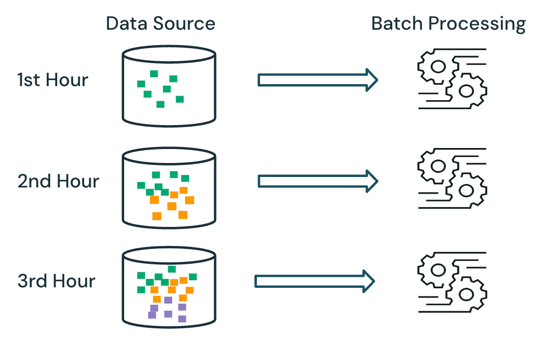
Kötegelt feldolgozás esetén a feldolgozó rendszer nem tartja nyilván, hogy a forrásban milyen adatok vannak már feldolgozás alatt. A forrásban jelenleg elérhető összes adat feldolgozása a feldolgozás időpontjában történik. A gyakorlatban a kötegelt adatforrásokat általában logikailag particionálják, például napok vagy régiók szerint, az adatok újrafeldolgozásának korlátozása érdekében.
Például egy e-kereskedelmi vállalat által szervezett értékesítési esemény során az óránkénti részletességgel összesített átlagos cikkeladási ár kiszámítása ütemezhető kötegelt feldolgozásként, hogy az átlagos eladási árat minden órában meghatározza. A köteg esetében az előző órák adatai óránként újrafeldolgozódnak, és a korábban kiszámított eredmények felülíródnak a legújabb eredményeknek megfelelően.
Streamelési szemantikák
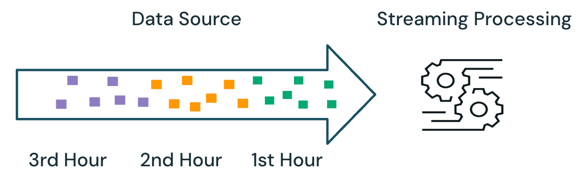
A streamelési feldolgozással a motor nyomon követi, hogy milyen adatokat dolgoznak fel, és csak a későbbi futtatások során dolgoz fel új adatokat. A fenti példában kötegfeldolgozás helyett ütemezheti a streamfeldolgozást az átlagos értékesítési ár óránkénti kiszámításához. Streamelés esetén a rendszer csak az utolsó futtatás óta hozzáadott új adatokat dolgozza fel a forráshoz. Az újonnan kiszámított eredményeket hozzá kell fűzni a korábban kiszámított eredményekhez a teljes eredmények ellenőrzéséhez.
Batch és streamelés
A fenti példában a streamelés jobb, mint a kötegelt feldolgozás, mivel nem dolgozza fel az előző futtatások során feldolgozott adatokat. A folyamfeldolgozás azonban bonyolultabbá válik olyan forgatókönyvek esetén, mint a nem sorrendi és a késve érkező adatok a forrásban.
A késői érkezési adatokra példa az, ha az első óra néhány értékesítési adata csak a második órában érkezik meg a forráshoz:
- A kötegelt feldolgozás során az első óra késői érkezési adatai a második órából származó adatokkal és az első órából származó meglévő adatokkal lesznek feldolgozva. Az első óra korábbi eredményeit felülírjuk és kijavítjuk a késői érkezési adatokkal.
- A streamfeldolgozás során a rendszer az első órából érkező késői adatokat a többi, az első órában feldolgozott adat nélkül dolgozza fel. A feldolgozási logikának az első óra átlagos számításainak összeg- és darabszámadatait kell tárolnia az előző eredmények helyes frissítéséhez.
Ezeket a streamelési összetettségeket általában akkor vezetik be, ha a feldolgozás állapotalapú, például illesztések, összesítések és deduplikációk.
Az állapot nélküli streamelési feldolgozás, például az új adatok forrásból való hozzáfűzése, a rendelésen kívüli és a késői érkezési adatok kezelése kevésbé összetett, mivel a késői érkező adatok hozzáfűzhetők az előző eredményekhez, amikor az adatok a forrásba érkeznek.
Az alábbi táblázat a kötegelt és streamelési feldolgozás előnyeit és hátrányait, valamint a Databricks Lakeflow két feldolgozási szemantikáját támogató különböző termékfunkciókat ismerteti.
| Szemantikai feldolgozás | Előnyök | Hátrányok | Adatmérnöki termékek |
|---|---|---|---|
| Batch |
|
|
|
| Online közvetítés |
|
|
|
Ajánlások
Az alábbi táblázat a medálarchion architektúra egyes rétegeinek adatfeldolgozási számítási feladatainak jellemzői alapján vázolja fel az ajánlott feldolgozási szemantikát.
| Medálréteg | A munkaterhelés jellemzői | Ajánlás |
|---|---|---|
| Bronz |
|
|
| Ezüst |
|
|
| Arany |
|
|