2019. július
Ezek a funkciók és az Azure Databricks platform fejlesztései 2019 júliusában jelentek meg.
Feljegyzés
A kiadások szakaszosak. Előfordulhat, hogy az Azure Databricks-fiók csak a kezdeti kiadási dátum után egy héttel frissül.
Hamarosan: A Databricks 6.0 nem támogatja a Python 2-t
A 2020-ra bejelentett Python 2 közelgő élettartamának előrejelezésekor a Python 2 nem támogatott a Databricks Runtime 6.0-ban. A Databricks Runtime korábbi verziói továbbra is támogatják a Python 2-t. A Databricks Runtime 6.0-s verzióját várhatóan 2019 későbbi részében fogjuk kiadni.
A Databricks Runtime verziójának előzetes betöltése a készlet tétlen példányain
2019. július 30. – 2019. aug. 6.: 2.103-es verzió
Mostantól felgyorsíthatja a készlet által támogatott fürtindításokat, ha kiválaszt egy Databricks Runtime-verziót, amelyet a készlet inaktív példányaiba szeretne betölteni. A készlet felhasználói felületén lévő mező neve előre betöltött Spark-verzió.

Nagyobb az összhang az egyéni fürtcímkék és készletcímkék között
2019. július 30. – 2019. aug. 6.: 2.103-es verzió
A hónap elején az Azure Databricks bevezette a készleteket, amelyek tétlen példányok készletei segítenek a fürtök gyors elindításában. Az eredeti kiadásban a készlet által támogatott fürtök örökölték az alapértelmezett és egyéni címkéket a készletkonfigurációból, és ezeket a címkéket nem lehetett módosítani a fürt szintjén. Most már konfigurálhatja a készlet által támogatott fürtökre vonatkozó egyéni címkéket, és ez a fürt minden egyéni címkét alkalmaz, függetlenül attól, hogy a készlettől örökölt vagy kifejezetten az adott fürthöz van rendelve. Nem adhat hozzá fürtspecifikus egyéni címkét ugyanazzal a kulcsnévvel, mint egy készlettől örökölt egyéni címke (vagyis a készlettől örökölt egyéni címke nem bírálható felül). További információ: Készletcímkék.
Az MLflow 1.1 számos felhasználói felületi és API-fejlesztése
2019. július 30. – 2019. aug. 6.: 2.103-es verzió
Az MLflow 1.1 számos új funkciót vezet be a felhasználói felület és az API használhatóságának javítása érdekében:
A futtatások áttekintési felhasználói felülete lehetővé teszi több oldalnyi futtatás tallózását, ha a futtatások száma meghaladja a 100-t. A 100. futtatás után kattintson a Továbbiak betöltése gombra a következő 100 futtatás betöltéséhez.
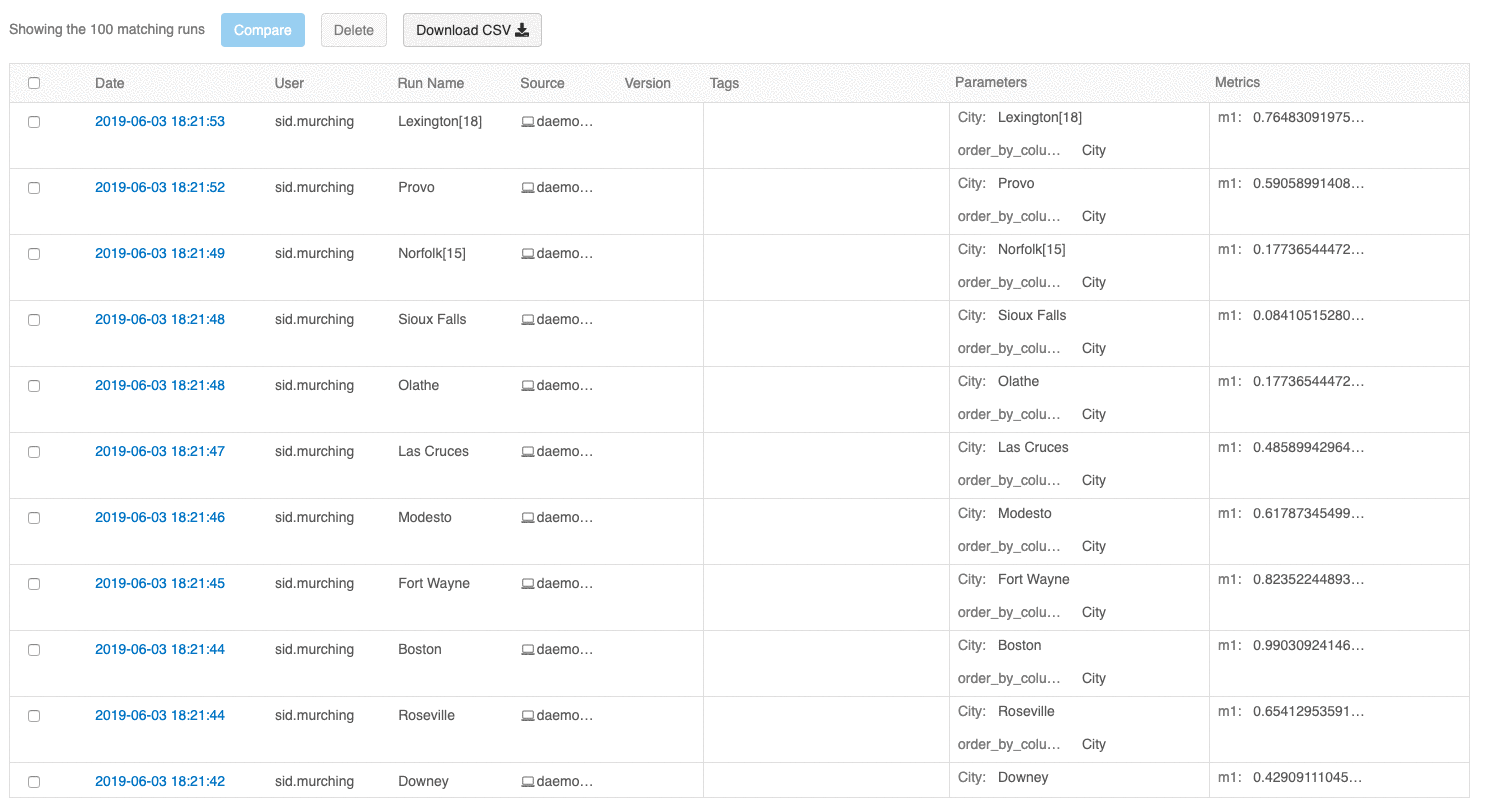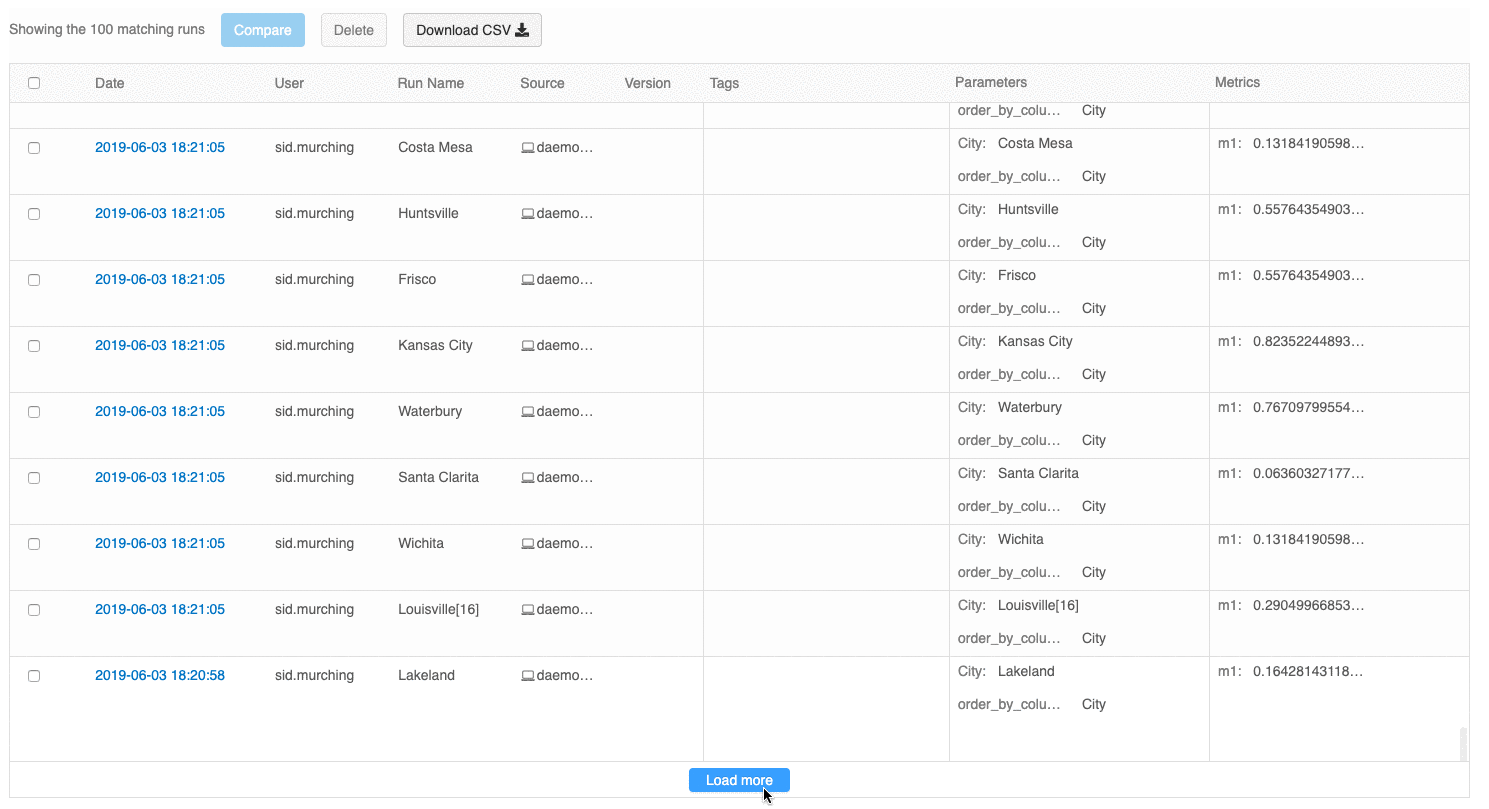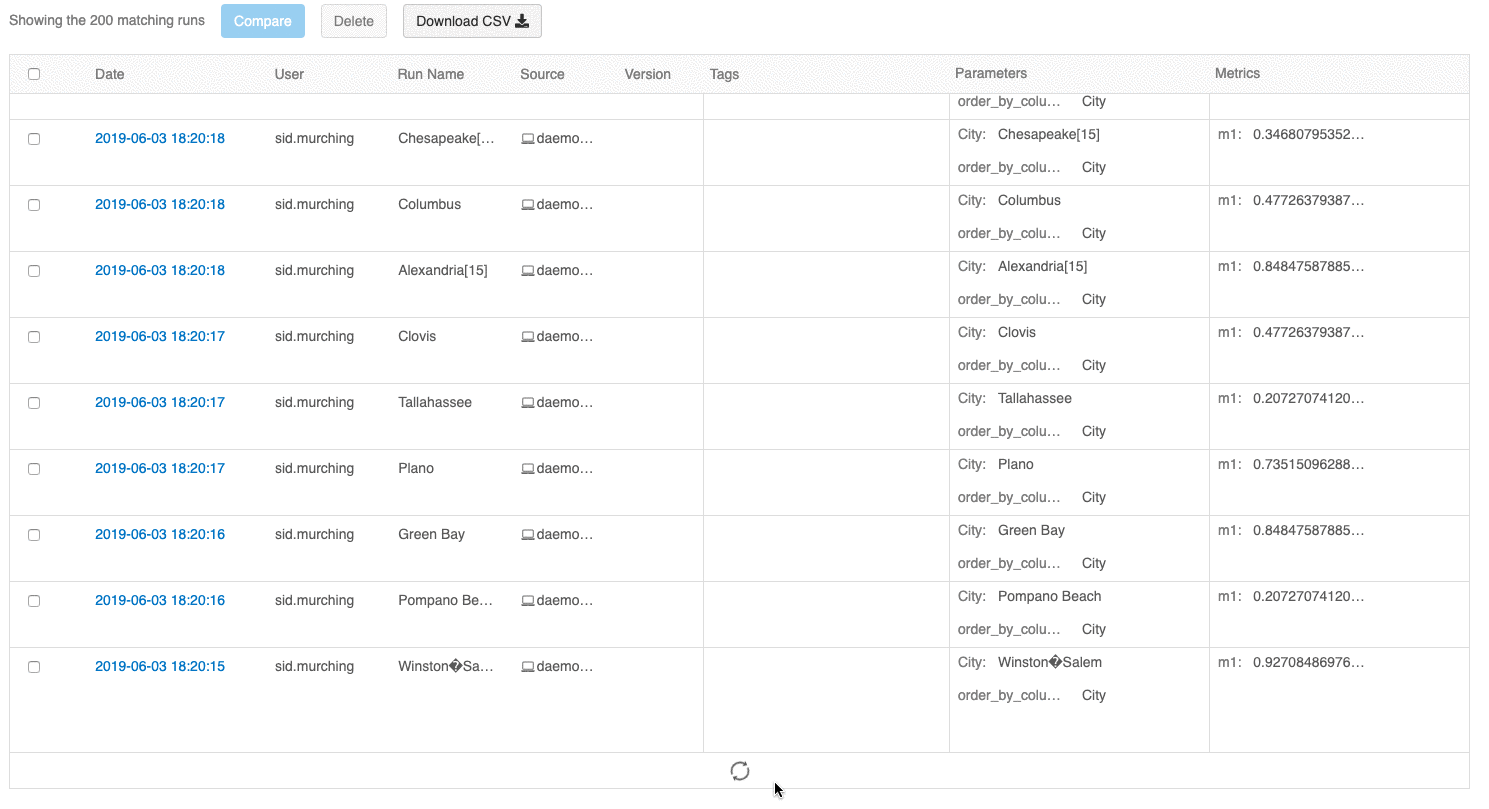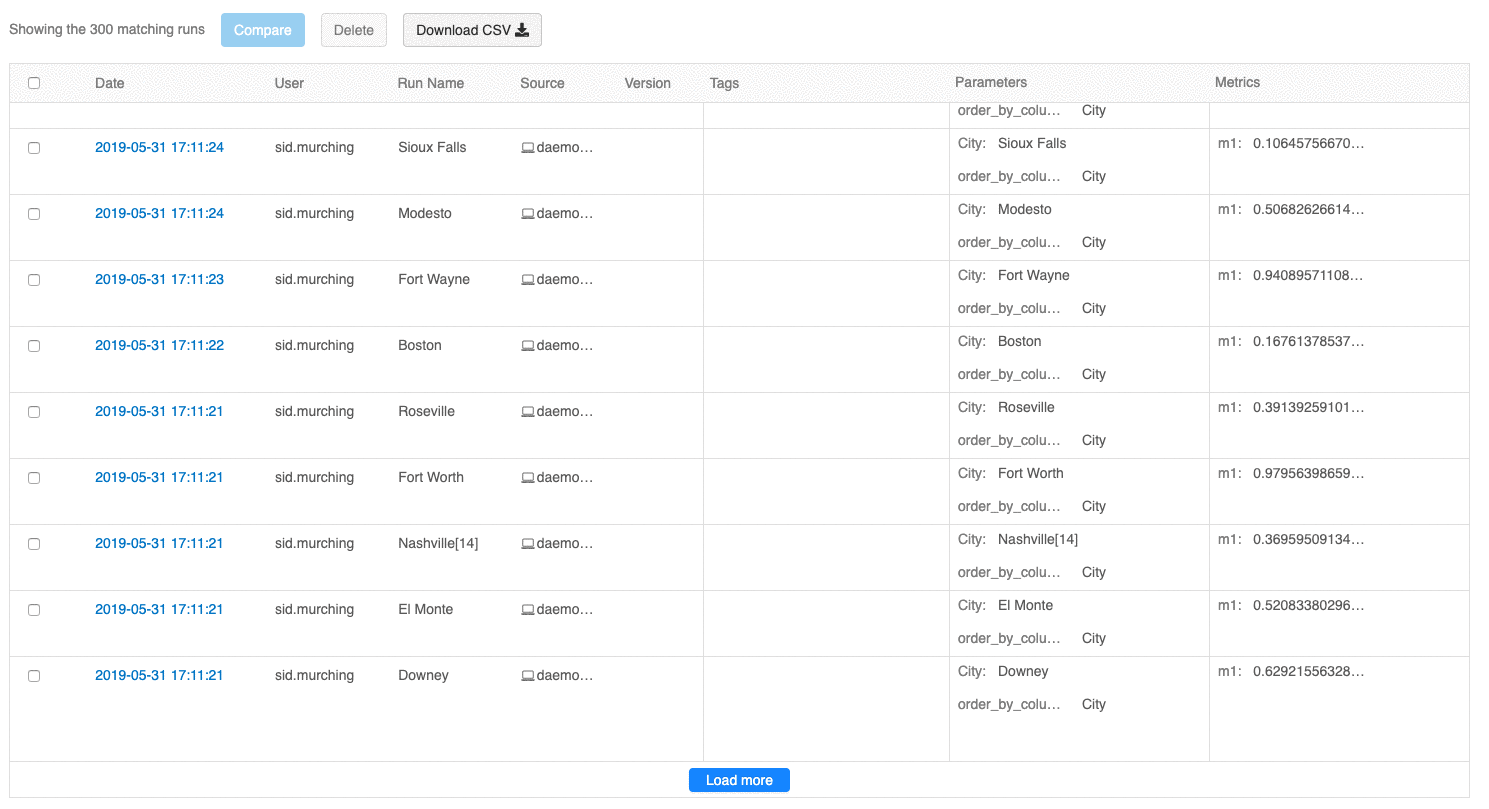
Az összehasonlítási futtatások felhasználói felülete mostantól párhuzamos koordinátákat ábrázol. A diagram lehetővé teszi a paraméterek és metrikák n dimenziós készlete közötti kapcsolatok megfigyelését. Az összes futtatás egy metrika értéke (például pontosság) alapján színkódolt vonalként jelenik meg, és megjeleníti az egyes futtatások paraméterértékeit.

Most már hozzáadhat és szerkeszthet címkéket a futtatás áttekintési felhasználói felületén, és megtekintheti a címkéket a kísérletkeresési nézetben.
Az új MLflowContext API-val a Python API-hoz hasonló módon hozhat létre és naplózhat. Ez az API ellentétben áll a meglévő alacsony szintű
MlflowClientAPI-val, amely egyszerűen körbefuttatja a REST API-kat.Mostantól törölheti a címkéket az MLflow-futtatásokból a DeleteTag API használatával.
További részletekért tekintse meg az MLflow 1.1 blogbejegyzést. A funkciók és javítások teljes listáját az MLflow changelogban találja.
A pandas-adatkeretek renderelése ugyanolyan, mint a Jupyterben
2019. július 30. – 2019. aug. 6.: 2.103-es verzió
Most, amikor meghív egy pandas DataFrame-et, ugyanúgy jelenik meg, mint a Jupyterben.
Új régiók
2019. július 30.
Az Azure Databricks a következő további régiókban érhető el:
- Dél-Korea középső régiója
- Dél-Afrika északi régiója
A metaadattár kapcsolati korlátjának frissítése
2019. július 16– 23.: 2.102-es verzió
Az eastus, eastus2, centralus, westus, westus2, westeurope és northeurope régióban található új Azure Databricks-munkaterületek esetében a metaadattár-kapcsolat felső határa 250 lesz. A meglévő munkaterületek továbbra is az aktuális metaadattárat használják megszakítás nélkül, és továbbra is 100-ra korlátozza a kapcsolati korlátot.
A készletek engedélyeinek beállítása (előzetes verzió)
2019. július 16– 23.: 2.102-es verzió
A készlet felhasználói felülete mostantól támogatja annak beállítását, hogy ki kezelheti a készleteket, és ki csatolhat fürtöket a készletekhez.
További információ: Készletengedélyek.
Databricks Runtime 5.5 for Machine Learning
2019. július 15.
A Databricks Runtime 5.5 ML a Databricks Runtime 5.5 LTS (EoS) fölé épül. Számos népszerű gépi tanulási kódtárat tartalmaz, köztük a TensorFlow, a PyTorch, a Keras és az XGBoost, és elosztott TensorFlow-képzést biztosít a Horovod használatával.
Ez a kiadás a következő új funkciókat és fejlesztéseket tartalmazza:
- Hozzáadta az MLflow 1.0 Python-csomagot
- Frissített gépi tanulási kódtárak
- A TensorFlow 1.12.0-ról 1.13.1-re frissült
- A PyTorch 0.4.1-ről 1.1.0-ra frissült
- scikit-learn frissítve 0.19.1-ről 0.20.3-ra
- Egycsomópontos művelet a HorovodRunnerhez
További részletekért lásd: Databricks Runtime 5.5 LTS for ML (EoS).
Databricks Runtime 5.5
2019. július 15.
A Databricks Runtime 5.5 már elérhető. A Databricks Runtime 5.5 tartalmazza az Apache Spark 2.4.3-at, a frissített Python-, R-, Java- és Scala-kódtárakat, valamint az alábbi új funkciókat:
- Delta Lake az Azure Databricks automatikus optimalizálása – GA
- A Delta Lake az Azure Databricksen javította az összesítő lekérdezések minimális, maximális és darabszámbeli teljesítményét
- Gyorsabb modellkövetkeztetési folyamatok továbbfejlesztett bináris fájladatforrással és skaláris iterátorral pandas UDF (nyilvános előzetes verzió)
- Titkos kódok API R-jegyzetfüzetekben
További információ: Databricks Runtime 5.5 LTS (EoS).
Példánykészlet készenléti állapotban tartása fürtök gyors indításához (nyilvános előzetes verzió)
2019. július 9– 11.: 2.101-es verzió
A fürt kezdési idejének csökkentése érdekében az Azure Databricks mostantól támogatja a fürtök egy előre meghatározott üresjárati példánykészlethez való csatolását. Készlethez csatolva a fürt lefoglalja az illesztőprogram- és feldolgozó csomópontokat a készletből. Ha a készlet nem rendelkezik elegendő tétlen erőforrással a fürt kérésének kielégítéséhez, a készlet úgy bővül, hogy új példányokat helyez ki a felhőszolgáltatótól. Ha egy csatolt fürt leáll, a használt példányok visszakerülnek a készletbe, és egy másik fürt újra felhasználhatja.
Az Azure Databricks nem számít fel díjat a DBU-kért, ha a készletben lévő példányok tétlenek. A példányszolgáltató számlázása érvényes. Lásd a díjszabást.
További információ: Készletkonfigurációs referencia.
Ganglia-metrikák
2019. július 9– 11.: 2.101-es verzió
A Ganglia egy skálázható elosztott monitorozási rendszer, amely mostantól elérhető az Azure Databricks-fürtökön. A Ganglia-metrikák segítenek a fürt teljesítményének és állapotának monitorozásában. A Ganglia-metrikák a fürt részleteinek oldaláról érhetők el:
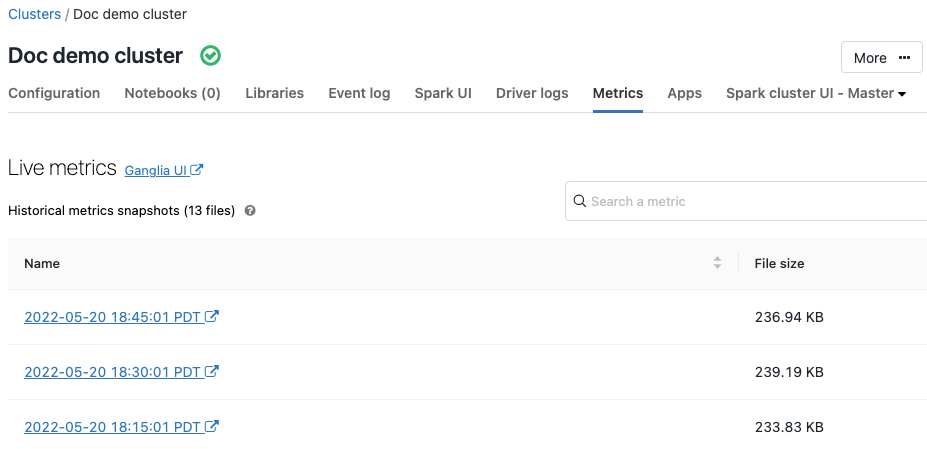
A metrikák használatával és konfigurálásával kapcsolatos részletekért tekintse meg a Ganglia-metrikákat.
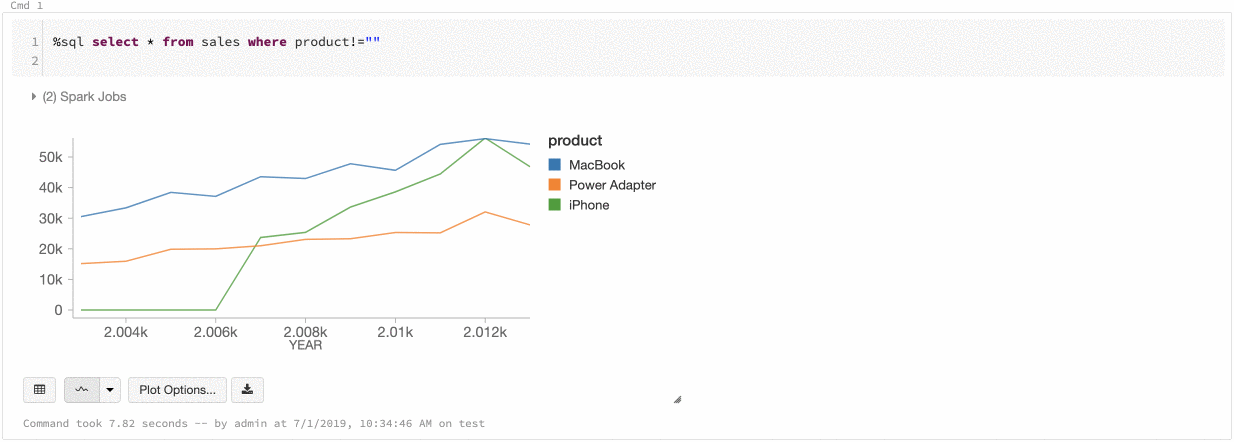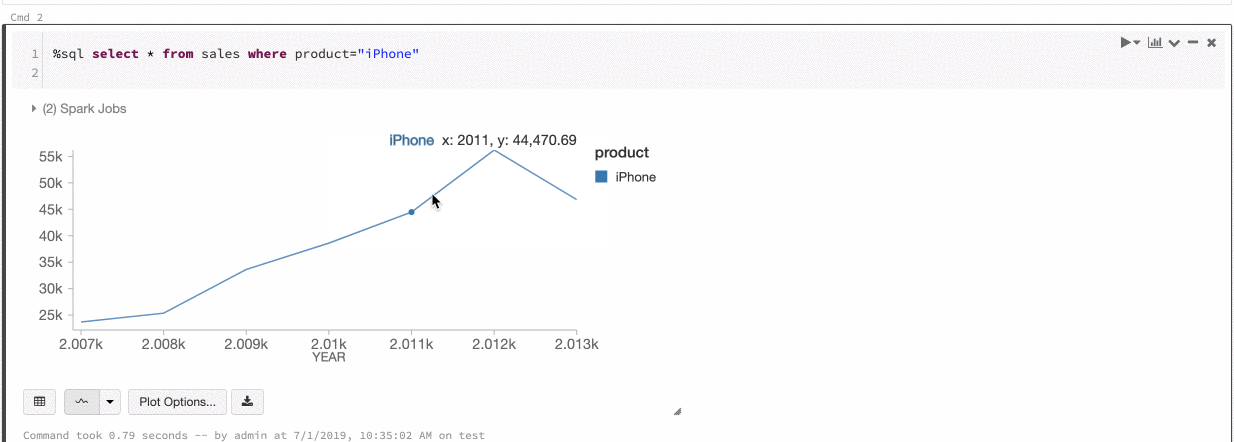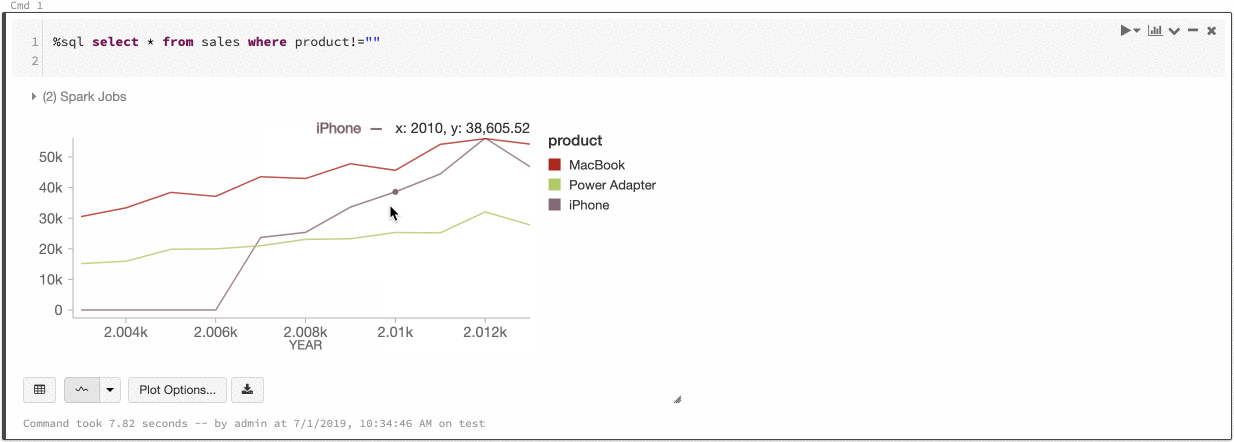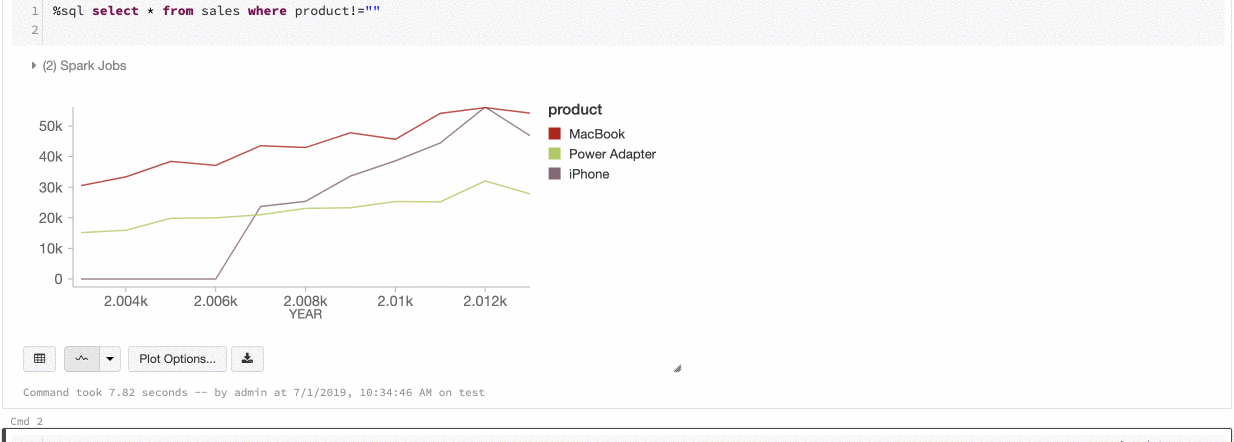
Globális sorozatszín
2019. július 9– 11.: 2.101-es verzió
Most már megadhatja, hogy az adatsorok színei konzisztensek legyenek a jegyzetfüzet összes diagramjában. Lásd a diagramok színkonzisztenciáját.