Apache Spark strukturált streamelés használata az Apache Kafkával és az Azure Cosmos DB-vel
Megtudhatja, hogyan olvashatja be az Apache Sparkstrukturált streamelést az Apache Kafkából az Azure HDInsightban, majd hogyan tárolhatja az adatokat az Azure Cosmos DB-ben.
Az Azure Cosmos DB egy globálisan elosztott, többmodelles adatbázis. Ez a példa egy Azure Cosmos DB for NoSQL-adatbázismodellt használ. További információkért tekintse meg az Azure Cosmos DB üdvözli a dokumentumot.
A Spark strukturált stream egy Spark SQL-alapú streamfeldolgozó rendszer. Lehetővé teszi, hogy ugyanúgy fejezze ki a streamszámításokat, mint a kötegelt számításokat a statikus adatok esetében. A strukturált streamelésről további információt a strukturált streamelési programozási útmutatóban talál a Apache.org.
Fontos
Ez a példa a Spark 2.4-et használja a HDInsight 4.0-n.
A dokumentum lépései olyan Azure-erőforráscsoportot hoznak létre, amely Spark on HDInsight- és Kafka on HDInsight-fürtöt is tartalmaz. Mindkét fürt Azure virtuális hálózatban található, így a Spark-fürt közvetlenül kommunikálhat a Kafka-fürttel.
Amikor végzett a dokumentum lépéseivel, ne felejtse el törölni a fürtöket a további díjak elkerülése érdekében.
A fürtök létrehozása
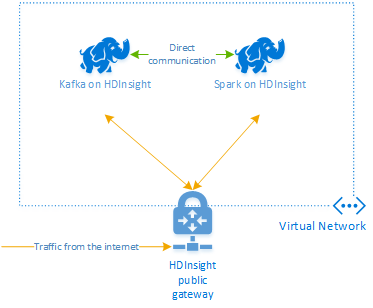
A HDInsighton futó Apache Kafka nem biztosít hozzáférést a Kafka-közvetítőkhöz a nyilvános interneten keresztül. A Kafkával folytatott beszélgetéseknek ugyanabban az Azure-beli virtuális hálózatban kell lenniük, mint a Kafka-fürt csomópontjai. Ebben a példában a Kafka és a Spark-fürtök egy Azure-beli virtuális hálózaton találhatók. Az alábbi ábra bemutatja, hogyan zajlik a kommunikáció a fürtök között:
Feljegyzés
A Kafka szolgáltatás a virtuális hálózaton belüli kommunikációra van korlátozva. A fürtön lévő többi szolgáltatás, például az SSH és az Ambari az interneten keresztül is elérhető. További információ a HDInsighttal elérhető nyilvános portokról: A HDInsight által használt portok és URI-k.
Bár manuálisan is létrehozhat Azure-beli virtuális hálózatot, Kafkát és Spark-fürtöt, egyszerűbben használhat Azure Resource Manager-sablont. Az alábbi lépésekkel üzembe helyezhet egy Azure-beli virtuális hálózatot, Kafkát és Spark-fürtöt az Azure-előfizetésében.
Az alábbi gombbal jelentkezzen be az Azure szolgáltatásba, és nyissa meg a sablont az Azure Portalon.

Az Azure Resource Manager-sablon a projekt (https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb)GitHub-adattárában található.
Ez a sablon a következő erőforrásokat hozza létre:
Kafka a HDInsight 4.0-fürtön.
Spark on HDInsight 4.0-fürt.
Egy Azure virtuális hálózat, amely tartalmazza a HDInsight-fürtöket. A sablon által létrehozott virtuális hálózat a 10.0.0.0/16 címteret használja.
Egy Azure Cosmos DB for NoSQL-adatbázis.
Fontos
A példában használt strukturált streamelési jegyzetfüzethez a Spark on HDInsight 4.0 szükséges. Ha a Spark on HDInsight korábbi verzióját használja, hibák lépnek fel a notebook használatakor.
Az egyéni üzembe helyezés szakasz bejegyzéseinek feltöltéséhez használja az alábbi információkat:
Tulajdonság Érték Előfizetés Válassza ki az Azure-előfizetését. Erőforráscsoport Hozzon létre egy csoportot, vagy válasszon ki egy meglévőt. Ez a csoport a HDInsight-fürtöt tartalmazza. Azure Cosmos DB-fiók neve A rendszer ezt az értéket használja az Azure Cosmos DB-fiók neveként. A név csak kisbetűket, számokat és a kötőjel (-) karaktert tartalmazhatja. A név 3–31 karakter hosszú lehet. Alapfürt neve Ez az érték a Spark- és Kafka-fürtök alapneve. A myhdi beírása például létrehoz egy Spark-myhdi nevű Spark-fürtöt és egy kafka-myhdi nevű Kafka-fürtöt. Fürt verziója A HDInsight-fürt verziója. Ez a példa a HDInsight 4.0-val van tesztelve, és nem feltétlenül működik más fürttípusokkal. Fürt bejelentkezési felhasználóneve A Spark- és Kafka-fürtök rendszergazdai felhasználóneve. Fürt bejelentkezési jelszava A Spark- és Kafka-fürtök rendszergazdai felhasználói jelszava. SSH-felhasználónév A Spark- és Kafka-fürtökhöz létrehozandó SSH-felhasználó. SSH-jelszó A Spark- és Kafka-fürtök SSH-felhasználójának jelszava. 
Olvassa át a használati feltételeket, majd válassza az Elfogadom a fenti feltételeket és kikötéseket lehetőséget.
Végül válassza a Vásárlás lehetőséget. A fürtök, a virtuális hálózat és az Azure Cosmos DB-fiók létrehozása akár 45 percet is igénybe vehet.
Az Azure Cosmos DB-adatbázis és -gyűjtemény létrehozása
A dokumentumban használt projekt az Azure Cosmos DB-ben tárolja az adatokat. A kód futtatása előtt először létre kell hoznia egy adatbázist és gyűjteményt az Azure Cosmos DB-példányban. Le kell kérnie a dokumentumvégpontot és az Azure Cosmos DB felé irányuló kérelmek hitelesítéséhez használt kulcsot is.
Ennek egyik módja az Azure CLI használata. A következő szkript létrehoz egy adatbázist és kafkadata egy nevű gyűjteményt kafkacollection. Ezután visszaadja az elsődleges kulcsot.
#!/bin/bash
# Replace 'myresourcegroup' with the name of your resource group
resourceGroupName='myresourcegroup'
# Replace 'mycosmosaccount' with the name of your Azure Cosmos DB account name
name='mycosmosaccount'
# WARNING: If you change the databaseName or collectionName
# then you must update the values in the Jupyter Notebook
databaseName='kafkadata'
collectionName='kafkacollection'
# Create the database
az cosmosdb sql database create --account-name $name --name $databaseName --resource-group $resourceGroupName
# Create the collection
az cosmosdb sql container create --account-name $name --database-name $databaseName --name $collectionName --partition-key-path "/my/path" --resource-group $resourceGroupName
# Get the endpoint
az cosmosdb show --name $name --resource-group $resourceGroupName --query documentEndpoint
# Get the primary key
az cosmosdb keys list --name $name --resource-group $resourceGroupName --type keys
A dokumentumvégpont és az elsődleges kulcs adatai az alábbi szöveghez hasonlóak:
# endpoint
"https://mycosmosaccount.documents.azure.com:443/"
# key
"YqPXw3RP7TsJoBF5imkYR0QNA02IrreNAlkrUMkL8EW94YHs41bktBhIgWq4pqj6HCGYijQKMRkCTsSaKUO2pw=="
Fontos
Mentse a végpontot és a kulcsértékeket, ahogy a Jupyter-jegyzetfüzetekben szükség van rájuk.
A jegyzetfüzetek lekérése
A dokumentumban leírt példa kódja a következő helyen található: https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb.
A notebookok feltöltése
A következő lépésekkel töltse fel a jegyzetfüzeteket a projektből a Spark on HDInsight-fürtbe:
A webböngészőben csatlakozzon a Jupyter Notebookhoz a Spark-fürtön. A következő URL-címben cserélje le a
CLUSTERNAMEelemet a Spark-fürt nevére.https://CLUSTERNAME.azurehdinsight.net/jupyterAmikor a rendszer kéri, írja be a fürt létrehozásakor használt bejelentkezési (rendszergazdai) nevet és jelszót.
A lap jobb felső sarkában a Feltöltés gombbal töltse fel a Stream-taxi-data-to-kafka.ipynb fájlt a fürtbe. A feltöltés elindításához válassza a Megnyitás elemet.
Keresse meg a Stream-taxi-data-to-kafka.ipynb bejegyzést a jegyzetfüzetek listájában, és válassza a Feltöltés gombot mellette.
Ismételje meg az 1–3. lépést a Stream-data-from-Kafka-to-Cosmos-DB.ipynb notebook betöltéséhez.
Taxiadatok betöltése a Kafkába
A fájlok feltöltése után válassza a Stream-taxi-data-to-kafka.ipynb bejegyzést a jegyzetfüzet megnyitásához. Kövesse a jegyzetfüzet lépéseit az adatok Kafkába való betöltéséhez.
Taxiadatok feldolgozása a Spark strukturált streameléssel
A Jupyter Notebook kezdőlapján válassza a Stream-data-from-Kafka-to-Cosmos-DB.ipynb bejegyzést. A jegyzetfüzet lépéseit követve streamelhet adatokat a Kafkából és az Azure Cosmos DB-be a Spark Strukturált streamelés használatával.
Következő lépések
Most, hogy megismerte az Apache Spark strukturált streamelés használatát, az alábbi dokumentumokból többet tudhat meg az Apache Spark, az Apache Kafka és az Azure Cosmos DB használatáról: