Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk az Azure Machine Learning designer egy összetevőjét ismerteti.
Ezzel az összetevővel mérhet egy betanított modell pontosságát. Egy modellből létrehozott pontszámokat tartalmazó adathalmazt ad meg, a Modell kiértékelése összetevő pedig iparági szabvány szerinti értékelési metrikákat számít ki.
A Modell kiértékelése által visszaadott metrikák az éppen kiértékelt modell típusától függnek:
- Besorolási modellek
- Regressziós modellek
- Fürtözési modellek
Tipp.
Ha még nem ismerkedik a modellértékeléssel, dr. Stephen Elston videósorozatát ajánljuk az EdX gépi tanulási kurzusának részeként.
Modell kiértékelése
Csatlakoztassa a Score Model vagy a Result dataset output scored dataset output of the Assign Data to Clusters to clusters to the left input port of Evaluate Model.
Feljegyzés
Ha olyan összetevőket használ, mint az "Oszlopok kiválasztása az adathalmazban" a bemeneti adathalmaz egy részének kiválasztásához, győződjön meg arról, hogy a tényleges címkeoszlop (a betanításban használt), a "Pontozott valószínűség" oszlop és a "Pontozott címkék" oszlop létezik az olyan metrikák kiszámításához, mint az AUC, a bináris besorolás pontossága/anomáliadetektálása. A tényleges címkeoszlop, a "Pontozott címkék" oszlop a többosztályos besorolás/regresszió metrikáinak kiszámításához létezik. A "Hozzárendelések" oszlopban a "DistancesToClusterCenter no.X" (X a centroid index, 0, ..., A centroidok száma-1) oszlop létezik a fürtözés metrikáinak kiszámításához.
Fontos
- Az eredmények kiértékeléséhez a kimeneti adatkészletnek adott pontszámoszlopneveket kell tartalmaznia, amelyek megfelelnek a modell összetevő követelményeinek.
- Az
Labelsoszlop tényleges címkéknek minősül. - A regressziós tevékenységhez a kiértékelendő adathalmaznak egy oszlopnak kell lennie, amelynek neve
Regression Scored Labelspontozott címkéket jelöl. - Bináris besorolási feladat esetén a kiértékelendő adatkészletnek két oszlopból kell lennie,
Binary Class Scored LabelsBinary Class Scored Probabilitiesamelyek pontozott címkéket és valószínűségeket jelölnek. - Többbesorolási feladat esetén a kiértékelendő adatkészletnek egy oszlopmal kell rendelkeznie, amelynek neve
Multi Class Scored Labelspontozott címkéket jelöl. Ha a felsőbb rétegbeli összetevő kimenetei nem rendelkeznek ezekkel az oszlopokkal, a fenti követelményeknek megfelelően kell módosítania.
[Nem kötelező] Csatlakoztassa a score model vagy result dataset output scored dataset output of the Assign Data to Clusters for the second model for the second model to right input port of Evaluate Model. Ugyanazon adatok két különböző modelljének eredményeit egyszerűen összehasonlíthatja. A két bemeneti algoritmusnak azonos algoritmustípusnak kell lennie. Vagy összehasonlíthatja két különböző futtatás pontszámait ugyanazon adatokon különböző paraméterekkel.
Feljegyzés
Az algoritmus típusa a "Gépi tanulási algoritmusok" alatt a "Kétosztályos besorolás", a "Többosztályos besorolás", a "Regresszió", a "Fürtözés" kifejezésre utal.
Küldje el a folyamatot a kiértékelési pontszámok létrehozásához.
Results (Eredmények)
A Modell kiértékelése parancs futtatása után válassza ki az összetevőt a modell kiértékelése navigációs panel jobb oldalán való megnyitásához. Ezután válassza a Kimenetek + Naplók lapot, és ezen a lapon az Adatkimenetek szakasz több ikonnal is rendelkezik. A Vizualizáció ikon sávdiagram ikonnal rendelkezik, és ez az első módja az eredmények megtekintésének.
Bináris besorolás esetén a Vizualizáció ikonra kattintva megjelenítheti a bináris keveredési mátrixot. Többbesorolás esetén a keveredési mátrix ábrázoló fájlja a Kimenetek + Naplók lapon található, például:
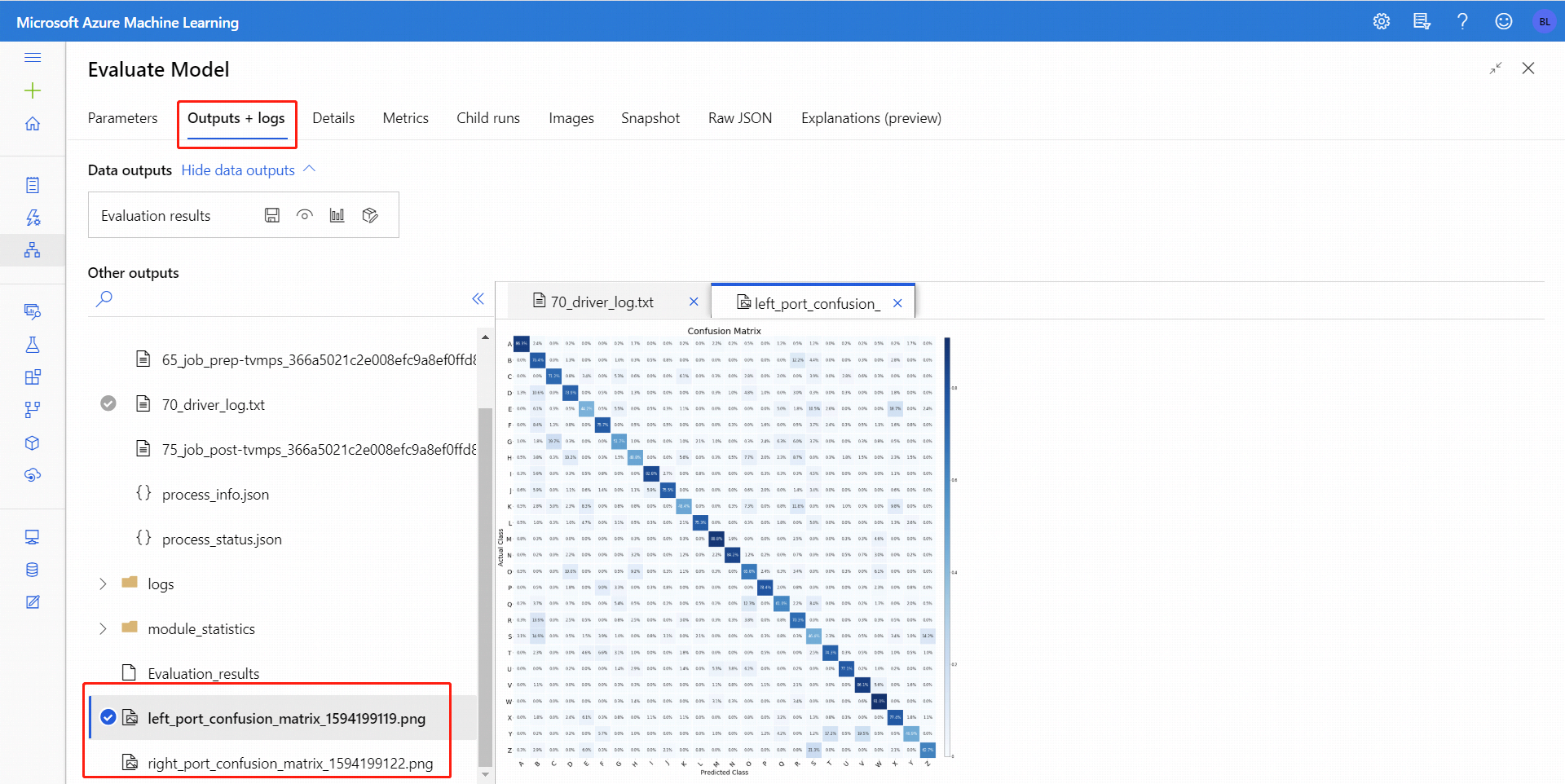
Ha az adatkészleteket a Modell kiértékelése mindkét bemenetéhez csatlakoztatja, az eredmények mindkét adatkészlet vagy mindkét modell metrikáit tartalmazzák. A bal oldali porthoz csatolt modell vagy adatok először a jelentésben jelennek meg, majd az adathalmaz metrikái, illetve a jobb porton csatolt modell.
Az alábbi képen például két, ugyanazon adatokra épülő, de különböző paraméterekkel rendelkező fürtözési modell eredményeinek összehasonlítása látható.
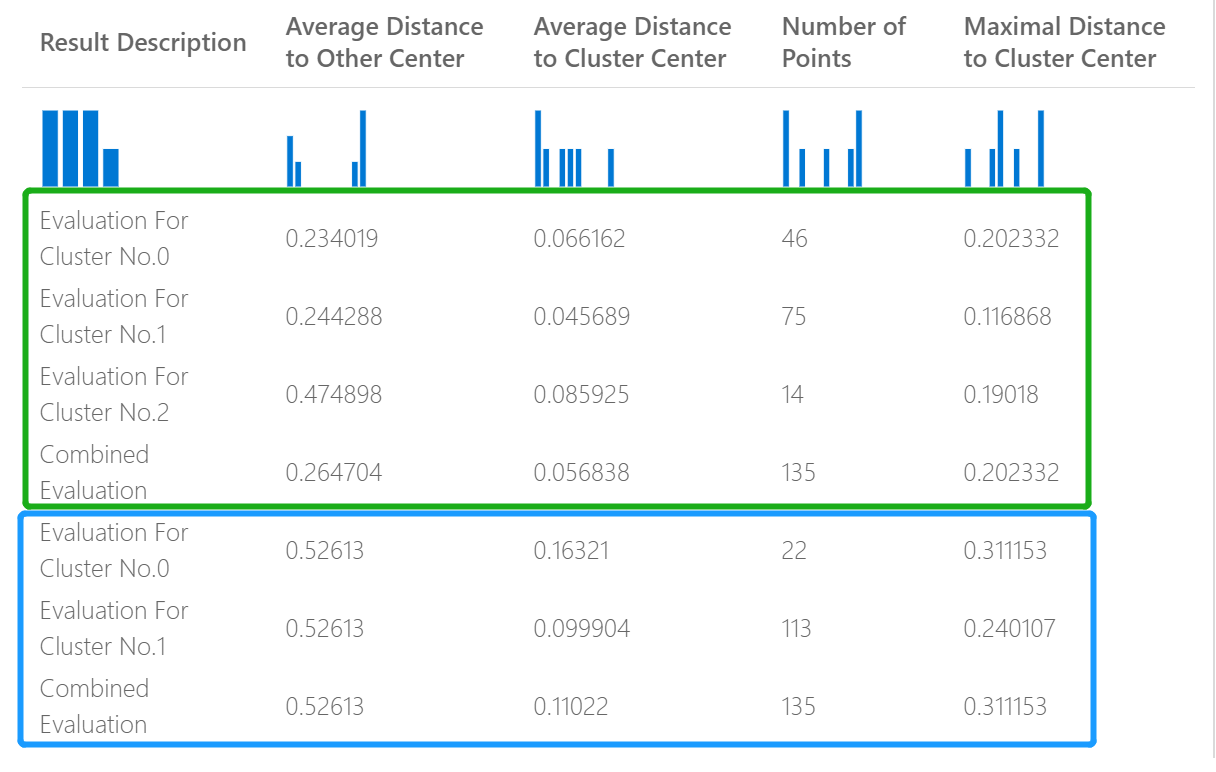
Mivel ez egy fürtözési modell, a kiértékelési eredmények eltérnek attól, hogy két regressziós modell pontszámait hasonlította össze, vagy összehasonlított két besorolási modellt. Az általános bemutató azonban ugyanaz.
Mérőszámok
Ez a szakasz a Modell kiértékelése funkcióval támogatott modellek adott típusaihoz visszaadott metrikákat ismerteti:
Metrikák besorolási modellekhez
A bináris besorolási modellek kiértékelésekor a következő metrikák jelennek meg.
A pontosság a besorolási modell jóságát méri a valódi eredmények arányaként az összes esethez.
A pontosság a valódi eredmények aránya az összes pozitív eredményhez. Pontosság = TP/(TP+FP)
A visszahívás a ténylegesen lekért releváns példányok teljes mennyiségének töredékét adja. Visszahívás = TP/(TP+FN)
Az F1 pontszám a pontosság és a visszahívás súlyozott átlagaként számítható ki 0 és 1 között, ahol az ideális F1 pontszám értéke 1.
Az AUC az y tengelyen valódi pozitív értékekkel ábrázolt görbe alatti területet, az x tengelyen pedig hamis pozitív értékeket mér. Ez a metrika azért hasznos, mert egyetlen számot biztosít, amely lehetővé teszi a különböző típusú modellek összehasonlítását. Az AUC besorolási küszöbérték-invariant. A modell előrejelzéseinek minőségét méri, függetlenül attól, hogy milyen besorolási küszöbértéket választ.
Regressziós modellek metrikái
A regressziós modellekhez visszaadott metrikák a hiba mennyiségének becslésére szolgálnak. A modell jól illeszkedik az adatokhoz, ha a megfigyelt és az előrejelzett értékek közötti különbség kicsi. A reziduálisok mintázatának (bármely előrejelzett pont és a hozzá tartozó tényleges érték közötti különbség) megvizsgálása azonban sokat elárulhat a modell lehetséges torzításairól.
A lineáris regressziós modellek kiértékeléséhez a következő metrikákat jelenti a rendszer. Más regressziós modellek, például a Fast Forest Quantile Regresszió különböző metrikákkal rendelkezhetnek.
Az átlagos abszolút hiba (MAE) azt méri, hogy az előrejelzések milyen közel vannak a tényleges eredményekhez, így az alacsonyabb pontszám jobb.
A fő középérték négyzetes hiba (RMSE) egyetlen értéket hoz létre, amely összegzi a modell hibáját. A különbség guggolásával a metrika figyelmen kívül hagyja a túljóslás és az alulredikció közötti különbséget.
A relatív abszolút hiba (RAE) a várt és a tényleges értékek relatív abszolút különbsége; relatív, mivel a középérték különbsége el van osztva az aritmetikai középértékel.
A relatív négyzetes hiba (RSE) hasonlóan normalizálja az előrejelzett értékek teljes négyzetes hibáját úgy, hogy elosztja a tényleges értékek teljes négyzetes hibájával.
A meghatározási együttható, amelyet gyakran R2-nek is neveznek, a modell prediktív erejét 0 és 1 közötti értékként jelöli. A nulla azt jelenti, hogy a modell véletlenszerű (nem magyaráz semmit); 1 azt jelenti, hogy van egy tökéletes illeszkedés. Az R2 értékek értelmezésekor azonban körültekintően kell eljárni, mivel az alacsony értékek teljesen normálisak lehetnek, és a magas értékek gyanúsak lehetnek.
Metrikák fürtözési modellekhez
Mivel a fürtözési modellek sok szempontból jelentősen eltérnek a besorolási és regressziós modellektől, a Modell kiértékelése a fürtözési modellek eltérő statisztikáit is visszaadja.
A fürtözési modellhez visszaadott statisztikák azt írják le, hogy hány adatpont lett hozzárendelve az egyes fürtökhöz, a fürtök közötti elkülönítés mértékét, valamint azt, hogy az adatpontok milyen szorosan vannak csoportosítva az egyes fürtökben.
A fürtmodell statisztikáit a rendszer a teljes adathalmazra átlagozza, és a fürtönkénti statisztikákat további sorok tartalmazzák.
A fürtmodellek kiértékeléséhez a következő metrikákat jelenti a rendszer.
Az "Átlag távolság az egyéb központtól" oszlop pontszámai azt jelzik, hogy a fürt minden pontja átlagosan milyen közel van az összes többi fürt centroidjaihoz.
A Fürtközponttól mért átlagos távolság oszlopban lévő pontszámok a fürt minden pontjának a fürt centroidjára való közelségét jelölik.
A Pontok száma oszlop azt mutatja, hogy hány adatpont lett hozzárendelve az egyes fürtökhöz, valamint az összes fürtben lévő adatpontok teljes számát.
Ha a fürtökhöz rendelt adatpontok száma kisebb, mint az elérhető adatpontok teljes száma, az azt jelenti, hogy az adatpontokat nem lehetett fürthöz rendelni.
A Fürtközponttól mért maximális távolság oszlopban lévő pontszámok az egyes pontok és a pont fürtjének centroidja közötti távolságok maximumát jelölik.
Ha ez a szám magas, az azt jelentheti, hogy a fürt széles körben eloszlott. A fürt eloszlásának meghatározásához tekintse át ezt a statisztikát a Fürtközponttól mért átlagos távolságtal együtt.
Az eredmények egyes szakaszainak alján található összesített kiértékelési pontszám az adott modellben létrehozott fürtök átlagolt pontszámait sorolja fel.
Következő lépések
Tekintse meg az Azure Machine Learning számára elérhető összetevőket.