Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk az Azure Machine Learning Designer Python-szkriptjének végrehajtását ismerteti.
Ezen összetevő használatával python-kódot futtathat. A Python architektúrájáról és tervezési alapelveiről további információt a Python-kód Azure Machine Learning Designerben való futtatásával kapcsolatban talál.
A Pythonnal olyan feladatokat hajthat végre, amelyeket a meglévő összetevők nem támogatnak, például:
- Adatok vizualizációja a következő használatával
matplotlib: . - Python-kódtárak használata a munkaterület adatkészleteinek és modelljeinek számbavételéhez.
- Az Adatok importálása összetevő által nem támogatott forrásokból származó adatok olvasása, betöltése és manipulálása.
- Saját mélytanulási kód futtatása.
Támogatott Python-csomagok
Az Azure Machine Learning a Python Anaconda-disztribúcióját használja, amely számos általános segédprogramot tartalmaz az adatfeldolgozáshoz. Az Anaconda-verziót automatikusan frissítjük. Az aktuális verzió a következő:
- Anaconda-disztribúció Python 3.10-hez
A teljes listát az előre telepített Python-csomagok című szakaszban találja.
Ha olyan csomagokat szeretne telepíteni, amelyek nem szerepelnek az előre telepített listában (például scikit-misc), adja hozzá a következő kódot a szkripthez:
import os
os.system(f"pip install scikit-misc")
A következő kóddal telepíthet csomagokat a jobb teljesítmény érdekében, különösen a következtetéshez:
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
Feljegyzés
Ha a folyamat több Olyan Python-szkript-összetevőt tartalmaz, amelyeknek olyan csomagokra van szükségük, amelyek nem szerepelnek az előre telepített listában, telepítse a csomagokat az egyes összetevőkben.
Figyelmeztetés
Az Excute Python Script összetevő nem támogatja a további natív kódtáraktól függő csomagok telepítését olyan parancsokkal, mint az "apt-get", például Java, PyODBC stb. Ennek az az oka, hogy ezt az összetevőt egyszerű környezetben hajtja végre, csak előre telepített Pythonnal és nem rendszergazdai engedélyekkel.
Hozzáférés az aktuális munkaterülethez és a regisztrált adatkészletekhez
A munkaterület regisztrált adathalmazaihoz való hozzáféréshez tekintse meg az alábbi mintakódot:
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Fájlok feltöltése
A Python-szkript végrehajtása összetevő támogatja a fájlok feltöltését az Azure Machine Learning Python SDK használatával.
Az alábbi példa bemutatja, hogyan tölthet fel képfájlt a Python-szkript végrehajtása összetevőbe:
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
A folyamatfuttatás befejezése után megtekintheti a rendszerkép előnézetét az összetevő jobb oldali paneljén.
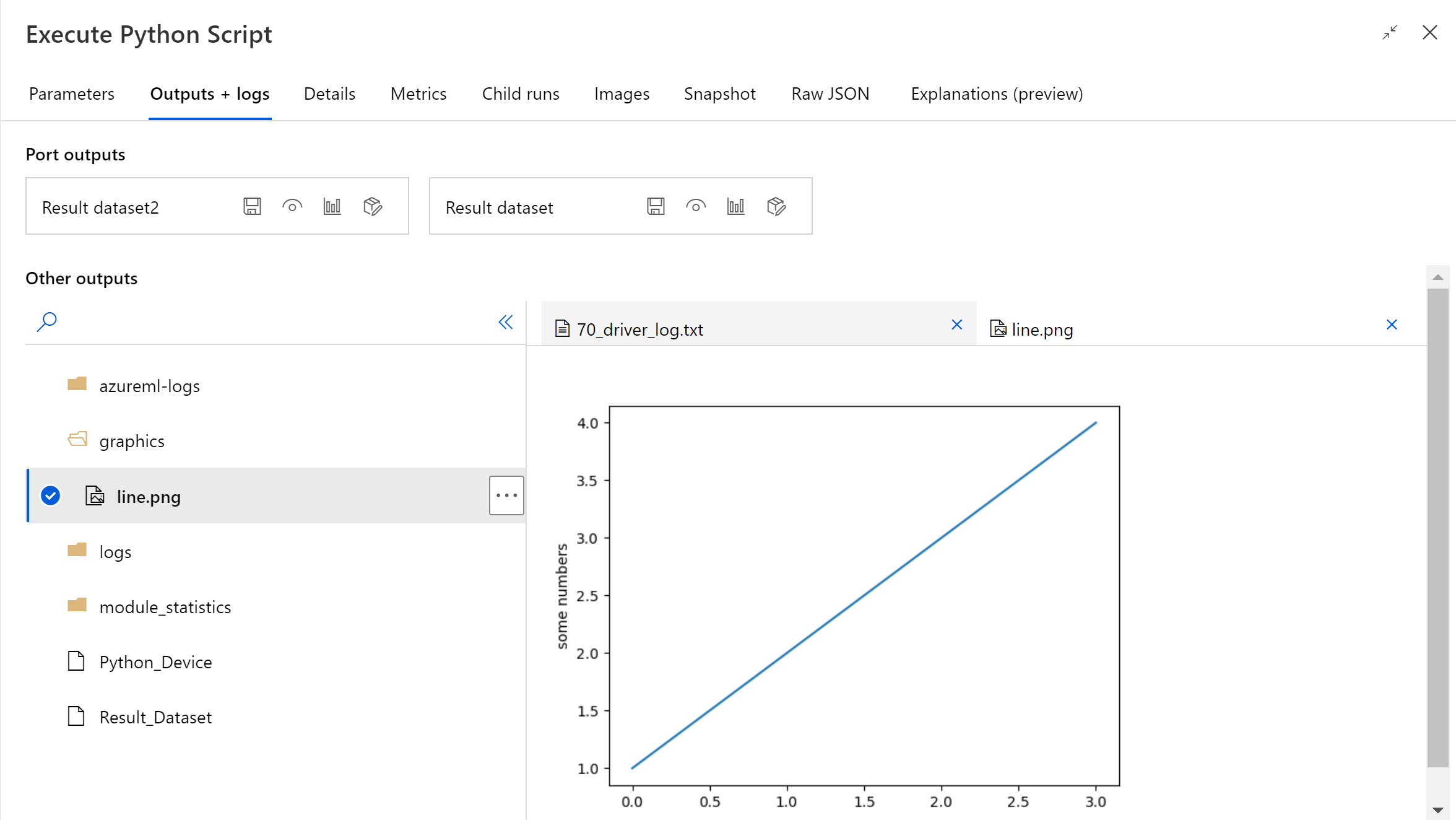
A következő kóddal bármely adattárba feltölthet fájlokat. A fájlt csak a tárfiókban tekintheti meg.
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Python-szkript végrehajtásának konfigurálása
A Python-szkript végrehajtása összetevő minta Python-kódot tartalmaz, amelyet kiindulási pontként használhat. A Python-szkript végrehajtása összetevő konfigurálásához adjon meg bemeneteket és Python-kódot a Python-szkript szövegmezőjében való futtatáshoz.
Adja hozzá a Python-szkript végrehajtása összetevőt a folyamathoz.
Adjon hozzá és csatlakozzon az Adathalmaz1-hez a tervezőtől származó adathalmazokhoz, amelyeket bemenetként szeretne használni. Hivatkozzon erre az adatkészletre a Python-szkriptben DataFrame1 néven.
Az adathalmaz használata nem kötelező. Akkor használja, ha a Python használatával szeretne adatokat létrehozni, vagy Python-kóddal közvetlenül importálja az adatokat az összetevőbe.
Ez az összetevő támogatja egy második adatkészlet hozzáadását az Adathalmaz2-ben. Hivatkozzon a Python-szkript második adatkészletére DataFrame2 néven.
Az Azure Machine Learningben tárolt adathalmazok automatikusan pandas-adatkeretekké alakulnak, amikor ezzel az összetevővel töltődik be.
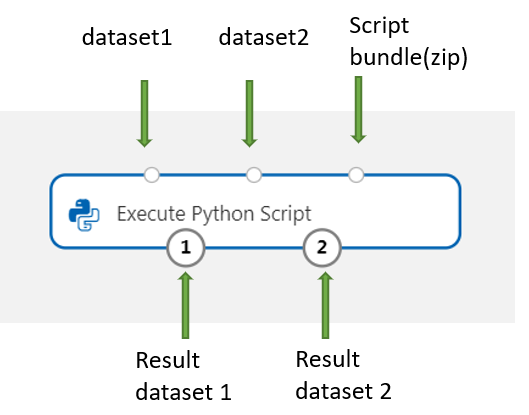
Új Python-csomagok vagy -kódok hozzáadásához csatlakoztassa az egyéni erőforrásokat tartalmazó tömörített fájlt a Script-csomag portjához. Vagy ha a szkript nagyobb, mint 16 KB, használja a Szkriptcsomag portot az olyan hibák elkerüléséhez, mint a CommandLine, amely meghaladja az 16597 karakteres korlátot.
- Kötegelje a szkriptet és más egyéni erőforrásokat egy zip-fájlba.
- Töltse fel a zip-fájlt Fájladatkészletként a stúdióba.
- Húzza az adathalmaz-összetevőt a tervező szerzői lapjának bal oldali összetevőpanelén található Adathalmazok listából.
- Csatlakoztassa az adathalmaz-összetevőt a Python-szkriptösszetevő Szkriptköteg portjához.
A feltöltött tömörített archívumban található összes fájl használható a folyamat végrehajtása során. Ha az archívum könyvtárszerkezetet tartalmaz, a struktúra megmarad.
Fontos
Használjon egyedi és értelmes nevet a szkriptcsomagban lévő fájlokhoz, mivel egyes gyakori szavak (például
test,appstb.) a beépített szolgáltatásokhoz vannak fenntartva.Az alábbi példa egy szkriptcsomagra mutat be, amely egy Python-szkriptfájlt és egy txt fájlt tartalmaz:
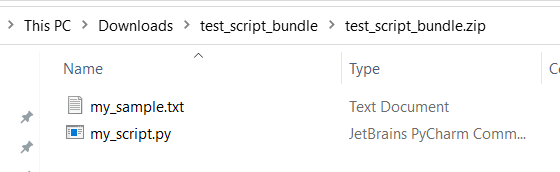
A következők tartalma
my_script.py:def my_func(dataframe1): return dataframe1Az alábbi mintakód bemutatja, hogyan lehet felhasználni a fájlokat a szkriptcsomagban:
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])A Python-szkript szövegmezőbe írja be vagy illessze be az érvényes Python-szkriptet.
Feljegyzés
Legyen óvatos a szkript írásakor. Győződjön meg arról, hogy nincsenek szintaxishibák, például be nem jelentett változók vagy nem fontos összetevők vagy függvények használata. Ügyeljen az előre telepített összetevők listájára. A listán nem szereplő összetevők importálásához telepítse a megfelelő csomagokat a szkriptbe, például:
import os os.system(f"pip install scikit-misc")A Python-szkript szövegmezője előre fel van töltve a megjegyzésekben szereplő utasítások, valamint az adathozzáférés és a kimenet mintakódjával. Ezt a kódot szerkesztenie vagy cserélnie kell. Kövesse a Python-konvenciókat a behúzáshoz és a burkolathoz:
- A szkriptnek tartalmaznia kell az összetevő belépési pontjaként elnevezett
azureml_mainfüggvényt. - A belépési pont függvénynek két bemeneti argumentumot kell tartalmaznia, és
Param<dataframe1>akkor is,Param<dataframe2>ha ezeket az argumentumokat nem használja a szkript. - A harmadik bemeneti porthoz csatlakoztatott tömörített fájlok kibontva lesznek, és a címtárban
.\Script Bundlevannak tárolva, amely szintén hozzáadódik a Pythonhozsys.path.
Ha a .zip fájl tartalmazza
mymodule.py, importálja a következővelimport mymodule: .Két adatkészlet adható vissza a tervezőnek, amelynek típusütemezésnek
pandas.DataFramekell lennie. Létrehozhat más kimeneteket a Python-kódban, és közvetlenül az Azure Storage-ba írhatja őket.Figyelmeztetés
Nem ajánlott adatbázishoz vagy más külső tárolóhoz csatlakozni a Python Script-összetevőben. Használhatja az Adatok importálása összetevőt és az Adatok exportálása összetevőt
- A szkriptnek tartalmaznia kell az összetevő belépési pontjaként elnevezett
Küldje el a folyamatot.
Ha az összetevő elkészült, ellenőrizze a kimenetet, ha a várt módon.
Ha az összetevő nem működik, hibaelhárítást kell végeznie. Jelölje ki az összetevőt, és nyissa meg az Outputs+logs elemet a jobb oldali panelen. Nyissa meg 70_driver_log.txt , és keressen a azureml_main, majd megtalálhatja, hogy melyik sor okozta a hibát. A "/tmp/tmp01_ID/user_script.py", 17. sor, azureml_main" például azt jelzi, hogy a hiba a Python-szkript 17 sorában történt.
Results (Eredmények)
A beágyazott Python-kód által végzett számítások eredményeit úgy kell megadni, hogy pandas.DataFrameaz automatikusan Azure Machine Learning-adathalmaz-formátumra konvertálva legyen. Ezután az eredményeket a folyamat más összetevőivel is használhatja.
Az összetevő két adatkészletet ad vissza:
Az 1. találati adatkészletet egy Python-szkript első visszaadott pandas-adatkerete határozza meg.
Result Dataset 2, amelyet a második visszaadott pandas-adatkeret definiál egy Python-szkriptben.
Előre telepített Python-csomagok
Az előre telepített csomagok a következők:
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob==1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetria==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- click==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- titkosítás==2,8
- cycler==0.10.0
- kapor==0.3.1.1
- distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2,9
- egyensúlyhiányos-learn==0.4.3
- isodate==0.6.0
- itsdangerous==1.1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0,2
- jsonpickle==1,3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- markupsafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0.16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2,20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- pyopenssl==19.1.0
- pyparsing==2.4.6
- pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1.3.0
- requests==2.23.0
- rsa==4,0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- secretstorage==3.1.2
- setuptools==46.1.1.post20200323
- six==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- wheel==0.34.2
Következő lépések
Tekintse meg az Azure Machine Learning számára elérhető összetevőket.