Az Adatimportálás összetevő
Ez a cikk az Azure Machine Learning designer egy összetevőjét ismerteti.
Ezzel az összetevővel adatokat tölthet be egy meglévő felhőbeli adatszolgáltatásokból származó gépi tanulási folyamatba.
Feljegyzés
Az összetevő által biztosított összes funkciót a munkaterület kezdőlapján található adattárak és adatkészletek végezhetik el. Javasoljuk, hogy olyan adattárat és adatkészletet használjon, amely további funkciókat, például adatmonitorozást is tartalmaz. További információ: Az adatok elérése és az adathalmazok regisztrálása . Miután regisztrált egy adathalmazt, a tervezőfelület Adathalmazok ->Saját adathalmazok kategóriájában találja meg. Ez az összetevő a Studio(klasszikus) felhasználói számára van fenntartva egy ismerős élmény érdekében.
Az Adatok importálása összetevő a következő forrásokból származó adatok olvasását támogatja:
- URL HTTP-en keresztül
- Azure cloud storages through Datastores)
- Azure-blobtároló
- Azure-fájlmegosztás
- Azure Data Lake
- Azure Data Lake Gen2
- Azure SQL Database
- Azure PostgreSQL
A felhőalapú tárolás használata előtt először regisztrálnia kell egy adattárat az Azure Machine Learning-munkaterületen. További információt az Adatok elérése című témakörben talál.
Miután meghatározta a kívánt adatokat, és csatlakozott a forráshoz, az Adatok importálása az egyes oszlopok adattípusát a benne található értékek alapján következteti, és betölti az adatokat a tervezőfolyamatba. Az Adatok importálása olyan adatkészlet, amely bármely tervezőfolyamattal használható.
Ha a forrásadatok megváltoznak, frissítheti az adathalmazt, és új adatokat adhat hozzá az Adatok importálása újrafuttatásával.
Figyelmeztetés
Ha a munkaterület virtuális hálózaton található, konfigurálnia kell az adattárakat a tervező adatvizualizációs funkcióinak használatára. Az adattárak és adathalmazok virtuális hálózatokban való használatáról további információt az Azure Machine Learning Studio használata Azure-beli virtuális hálózatban című témakörben talál.
Adatok importálásának konfigurálása
Adja hozzá az Adatimportálás összetevőt a folyamathoz. Ezt az összetevőt a tervező Adatbemenet és kimenet kategóriájában találja.
Válassza ki az összetevőt a jobb oldali panel megnyitásához.
Válassza ki az Adatforrás lehetőséget, és válassza ki az adatforrás típusát. Lehet HTTP vagy adattár.
Ha az adattárat választja, kiválaszthatja az Azure Machine Learning-munkaterületen már regisztrált meglévő adattárakat, vagy létrehozhat egy új adattárat. Ezután határozza meg az adattárban importálandó adatok elérési útját. Egyszerűen tallózhat az elérési úton a Tallózás lehetőség kiválasztásával.
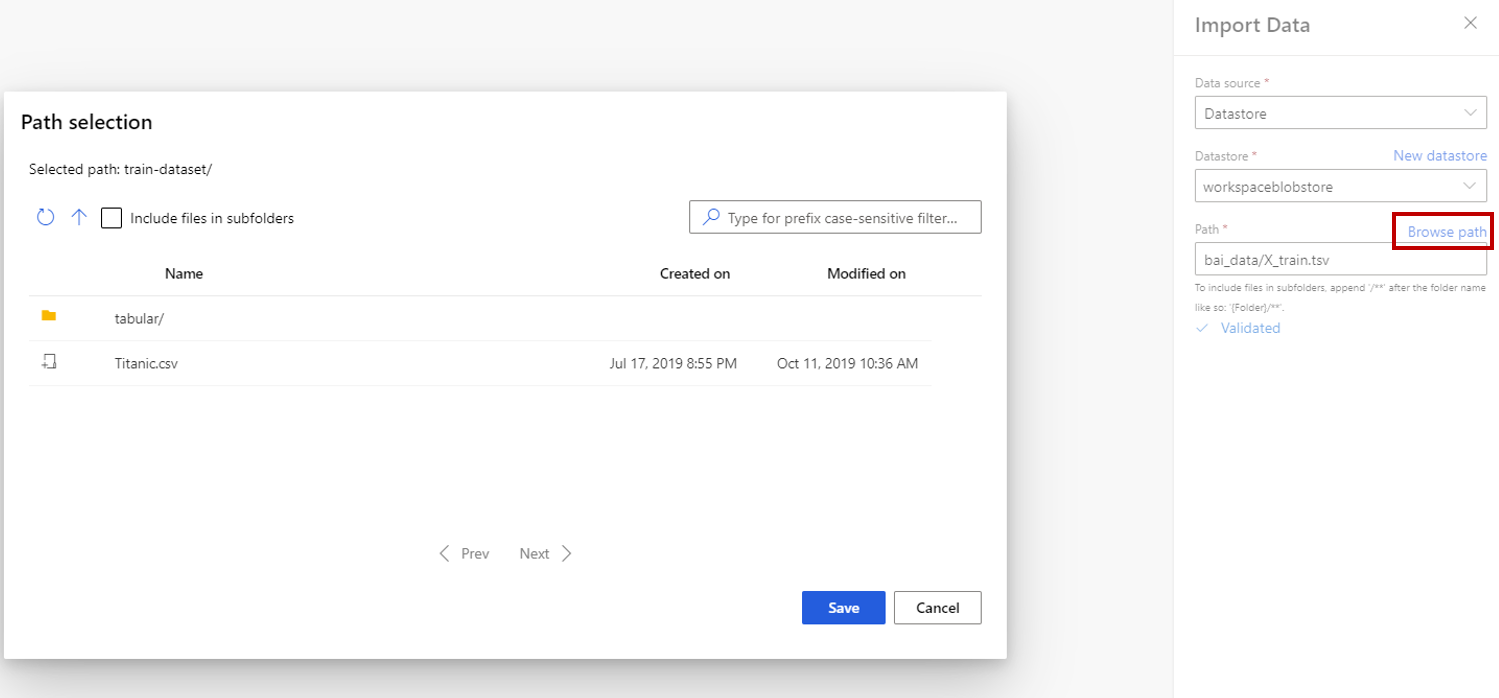
Feljegyzés
Az Adatimportálás összetevő csak táblázatos adatokhoz használható. Ha egyszerre több táblázatos adatfájlt szeretne importálni, az a következő feltételeket igényli, ellenkező esetben hibák lépnek fel:
- Ahhoz, hogy az összes adatfájlt belefoglalja a mappába, meg kell adnia
folder_name/**az elérési utat. - Minden adatfájlt Unicode-8 kóddal kell kódolni.
- Minden adatfájlnak azonos oszlopszámmal és oszlopnevekkel kell rendelkeznie.
- Több adatfájl importálásának eredménye az összes sor összefűzése több fájlból, sorrendben.
- Ahhoz, hogy az összes adatfájlt belefoglalja a mappába, meg kell adnia
Válassza ki az előnézeti sémát a belefoglalni kívánt oszlopok szűréséhez. Olyan speciális beállításokat is megadhat, mint a Delimiter a Elemzési beállításokban.
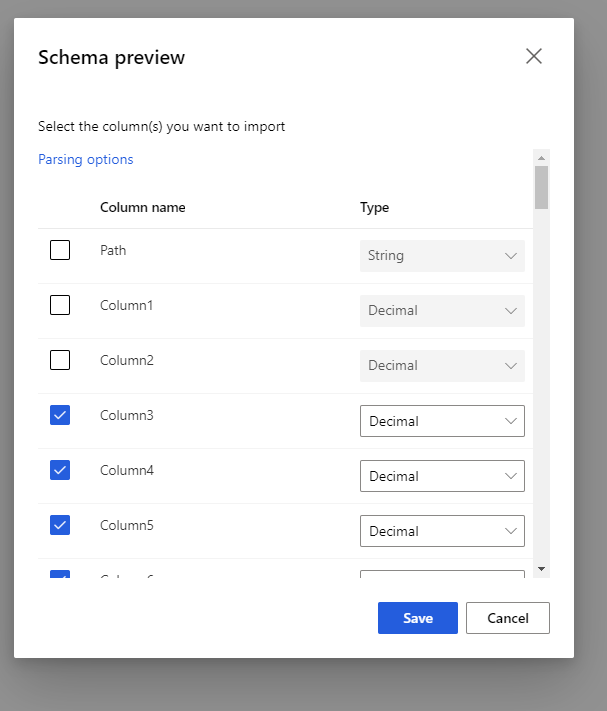
A kimenet újragenerálása jelölőnégyzet dönti el, hogy végrehajtja-e az összetevőt a kimenet futásidőben történő újragenerálásához.
Alapértelmezés szerint nincs kiválasztva, ami azt jelenti, hogy ha az összetevőt korábban ugyanazokkal a paraméterekkel hajtották végre, a rendszer újra felhasználja a legutóbbi futtatás kimenetét a futási idő csökkentése érdekében.
Ha ki van választva, a rendszer újra végrehajtja az összetevőt a kimenet újragenerálásához. Ezért válassza ezt a lehetőséget a tárolóban lévő mögöttes adatok frissítésekor, így segíthet a legújabb adatok beszerzésében.
Küldje el a folyamatot.
Amikor az Adatok importálása betölti az adatokat a tervezőbe, az egyes oszlopok adattípusát a benne található értékek alapján, numerikus vagy kategorikus értékek alapján következteti.
Ha van élőfej, a rendszer a kimeneti adathalmaz oszlopainak elnevezésére használja.
Ha nincsenek meglévő oszlopfejlécek az adatokban, a rendszer az új oszlopneveket col1, col2 formátummal hozza létre,... , coln*.

Results (Eredmények)
Amikor az importálás befejeződött, kattintson a jobb gombbal a kimeneti adatkészletre, és válassza a Vizualizáció lehetőséget annak megtekintéséhez, hogy az adatok importálása sikeresen megtörtént-e.
Ha a folyamat minden futtatásakor új adatkészlet importálása helyett újra szeretné menteni az adatokat, válassza az adathalmaz regisztrálása ikont az összetevő jobb oldali paneljén, a Kimenetek+naplók lapon. Válasszon nevet az adathalmaznak. A mentett adatkészlet a mentéskor megőrzi az adatokat. Az adatkészlet nem frissül a folyamat újrafuttatásakor, még akkor sem, ha a folyamat adathalmaza megváltozik. Ez hasznos lehet az adatok pillanatképeinek készítéséhez.
Az adatok importálása után szükség lehet néhány további előkészületre a modellezéshez és az elemzéshez:
A Metaadatok szerkesztése funkcióval módosíthatja az oszlopneveket, más adattípusként kezelhet egy oszlopot, vagy jelezheti, hogy egyes oszlopok címkék vagy szolgáltatások.
Az Adathalmaz oszlopainak kijelölése lehetőségével kiválaszthatja az átalakítandó vagy a modellezés során használni kívánt oszlopok egy részhalmazát. Az átalakított vagy eltávolított oszlopok egyszerűen újracsatlakozhatnak az eredeti adathalmazba az Oszlopok hozzáadása összetevővel.
A Partíció és a Minta használatával ossza el az adathalmazt, végezzen mintavételezést, vagy szerezze be a felső n sorokat.
Korlátozások
Az adattár-hozzáférés korlátozása miatt, ha a következtetési folyamat importálási adatösszetevőt tartalmaz, az automatikusan törlődik a valós idejű végponton való üzembe helyezéskor.
Következő lépések
Tekintse meg az Azure Machine Learning számára elérhető összetevőket.