PyTorch-modell betanítása
Ez a cikk bemutatja, hogyan taníthatja be a PyTorch-modelleket az Azure Machine Learning designerBen a PyTorch-modell betanítása összetevőjével, például a DenseNet-et. A betanítás a modell definiálása és paramétereinek megadása után történik, és címkézett adatokat igényel.
Jelenleg a PyTorch-modell betanítása összetevő támogatja az egyetlen csomópontot és az elosztott betanítást is.
PyTorch-modell betanítása
A tervezőben adja hozzá a DenseNet összetevőt vagy a ResNetet a folyamatvázlathoz.
Adja hozzá a PyTorch-modell betanítása összetevőt a folyamathoz. Ezt az összetevőt a Modell betanítása kategóriában találja. Bontsa ki a Betanítás elemet, majd húzza a PyTorch-modell betanítása összetevőt a folyamatba.
Megjegyzés
A PyTorch-modell összetevő betanítása nagyobb adathalmazok GPU-típusú számítása esetén jobb, ha a folyamat sikertelen lesz. Az összetevő jobb oldali paneljén válassza ki az adott összetevő számítását a Másik számítási cél használata beállítással.
A bal oldali bemeneten csatoljon egy nem betanított modellt. Csatolja a betanítási és érvényesítési adatkészletet a PyTorch-modell betanításának középső és jobb oldali bemenetéhez.
Nem betanított modell esetén pyTorch-modellnek kell lennie, például a DenseNetnek; ellenkező esetben egy "InvalidModelDirectoryError" lesz dobva.
Adatkészlet esetén a betanítási adatkészletnek egy címkézett képkönyvtárnak kell lennie. A címkézett képkönyvtár beszerzéséről a Konvertálás képkönyvtárba című témakörben tájékozódhat. Ha nincs címkézve, a rendszer egy "NotLabeledDatasetError" értéket ad.
A betanítási adatkészlet és az érvényesítési adatkészlet címkéi azonosak, ellenkező esetben egy InvalidDatasetError elem jelenik meg.
Az Epochs beállításnál adja meg, hogy hány korszakot szeretne betaníteni. A teljes adatkészletet a rendszer minden korszakban meg fogja jeleníteni, alapértelmezés szerint 5.
A Batch méretéhez adja meg, hogy egy kötegben hány példány legyen betanítása alapértelmezés szerint 16.
A Bemelegítési lépés száma mezőben adja meg, hogy hány korszakban szeretné bemelegíteni a betanítást abban az esetben, ha a kezdeti tanulási arány kissé túl nagy a konvergens kezdéshez, alapértelmezés szerint 0.
A Tanulási arány beállításnál adjon meg egy értéket a tanulási arányhoz, az alapértelmezett érték pedig 0,001. A tanulási sebesség határozza meg az optimalizálóban használt lépés méretét, például az sgd-t minden alkalommal, amikor a modellt tesztelik és kijavítják.
A sebesség kisebbre állításával gyakrabban teszteli a modellt, és fennáll annak a kockázata, hogy elakad egy helyi fennsíkon. A nagyobb sebesség beállításával gyorsabban konvergálhat, és fennáll annak a veszélye, hogy túllépi a valódi minimumot.
Megjegyzés
Ha a betanítás során a vonatvesztés nanná válik, amelyet a túl nagy tanulási arány okozhat, a tanulási arány csökkentése segíthet. Az elosztott betanításban a színátmenetes süllyedés stabilan tartásához a tényleges tanulási arányt az határozza meg
lr * torch.distributed.get_world_size(), hogy a folyamatcsoport kötegmérete az egyetlen folyamathoz képest világméret-idő. A polinomiális tanulási sebesség romlása alkalmazható, és jobb teljesítményű modellt eredményezhet.Véletlenszerű magok esetén megadhat egy egész számértéket, amelyet magként szeretne használni. A mag használata akkor ajánlott, ha biztosítani szeretné a kísérlet reprodukálhatóságát a feladatok között.
A Türelem beállításnál adja meg, hogy hány idő után állítsa le a betanítást, ha az érvényesítési veszteség nem csökken egymás után. alapértelmezés szerint 3.
A Nyomtatási gyakoriság beállításnál adja meg a betanítási naplók nyomtatási gyakoriságát minden egyes korszakban, alapértelmezés szerint 10.
Küldje el a folyamatot. Ha az adathalmaz mérete nagyobb, az eltarthat egy ideig, és a GPU-számítás ajánlott.
Elosztott betanítás
Az elosztott betanítás során a modell betanításához használt számítási feladat fel van osztva és megosztva több miniprocesszor között, úgynevezett feldolgozó csomópontok között. Ezek a munkavégző csomópontok párhuzamosan működnek a modell betanításának felgyorsítása érdekében. A tervező jelenleg támogatja az elosztott betanítást a PyTorch-modell összetevő betanításához .
Betanítási idő
Az elosztott betanítás lehetővé teszi, hogy a PyTorch-modell betanításával néhány óra alatt betanítsunk egy nagy adatkészletet, például az ImageNetet (1000 osztály, 1,2 millió kép). Az alábbi táblázat betanítási időt és teljesítményt mutat be az ImageNeten futó Resnet50 50 éves betanítása során, különböző eszközök alapján.
| Eszközök | Betanítási idő | Betanítási átviteli sebesség | Első 1. ellenőrzési pontosság | Első 5 érvényesítési pontosság |
|---|---|---|---|---|
| 16 V100 GPU | 6h22min | ~3200 kép/mp | 68.83% | 88.84% |
| 8 V100 GPU | 12h21min | ~1670 kép/mp | 68.84% | 88.74% |
Kattintson erre az összetevő "Metrikák" fülére, és tekintse meg a betanítási metrikák grafikonjait, például a "Képek betanítása másodpercenként" és a "Top 1 pontosság" elemet.

Elosztott betanítás engedélyezése
Ha engedélyezni szeretné az elosztott betanítást a PyTorch-modell betanítása összetevőhöz, az összetevő jobb oldali paneljén a Feladatbeállítások területen állíthatja be. Elosztott betanításhoz csak az AML Compute-fürt támogatott.
Megjegyzés
Az elosztott betanítás aktiválásához több GPU-ra van szükség, mivel az NCCL háttérrendszere, a PyTorch-modell betanítása összetevőnek cuda-ra van szüksége.
Jelölje ki az összetevőt, és nyissa meg a jobb oldali panelt. Bontsa ki a Feladatbeállítások szakaszt .

Győződjön meg arról, hogy az AML-számítás lehetőséget választja a számítási célhoz.
Az Erőforrás elrendezése szakaszban a következő értékeket kell megadnia:
Csomópontok száma : A betanításhoz használt számítási cél csomópontjainak száma. Ennek kisebbnek vagy egyenlőnek kell lennie a számítási fürt maximális csomópontjainak számánál . Alapértelmezés szerint 1, ami egy csomópontos feladatot jelent.
Folyamatszám csomópontonként: Csomópontonként aktivált folyamatok száma. Ennek kisebbnek vagy egyenlőnek kell lennie a számítás feldolgozási egységével . Alapértelmezés szerint 1, ami egyetlen folyamatfeladatot jelent.
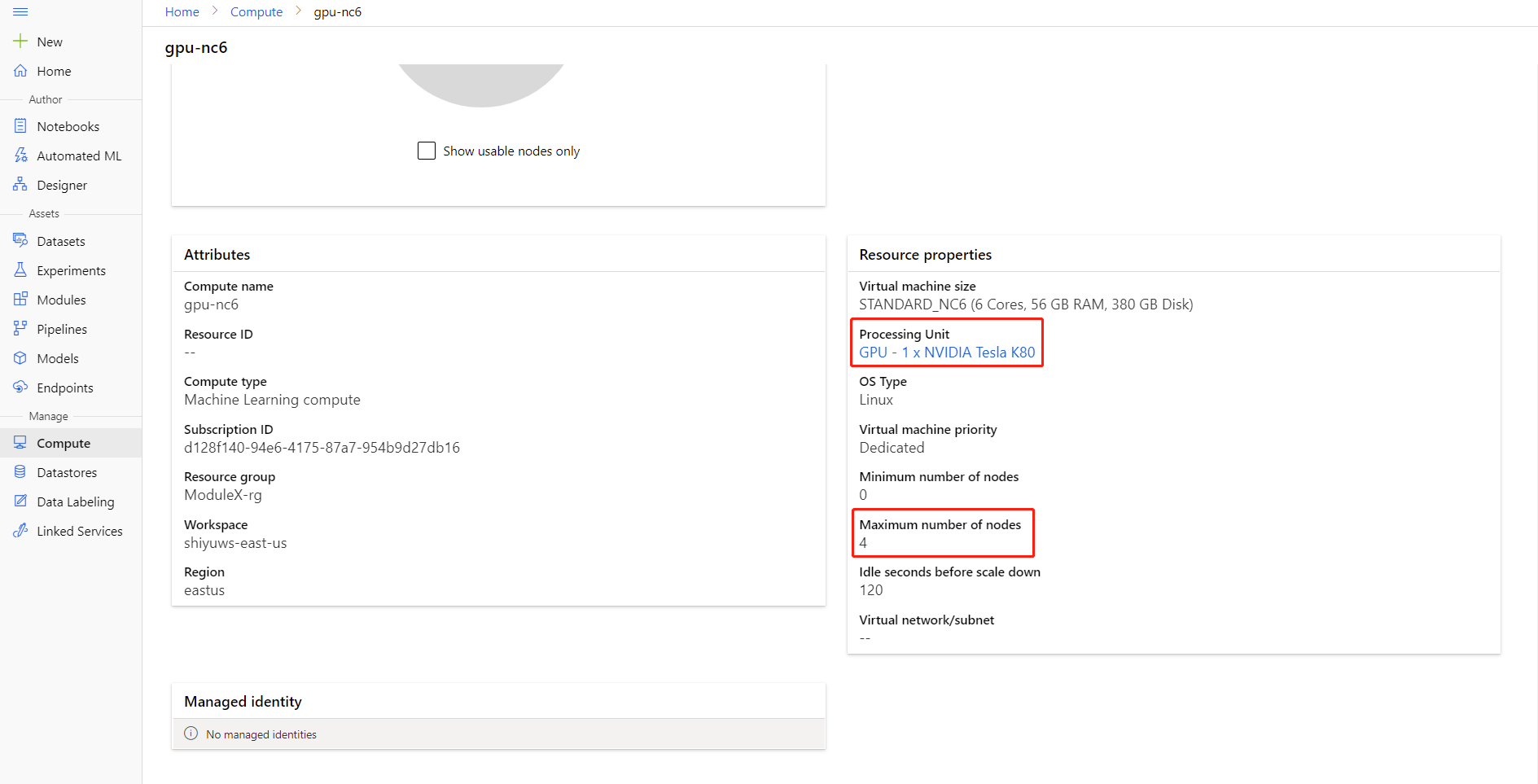
A számítási adatok lapon a számítási névre kattintva ellenőrizheti a csomópontok maximális számát és a számítási egység feldolgozási egységét .


Az Azure Machine Learning elosztott betanításáról itt tudhat meg többet.
Elosztott betanítás hibaelhárítása
Ha engedélyezi az elosztott betanítást ehhez az összetevőhöz, az egyes folyamatokhoz illesztőprogram-naplók lesznek.
70_driver_log_0 a főfolyamathoz tartozik. A jobb oldali panel Kimenetek+naplók lapján ellenőrizheti az egyes folyamatok hibaadatait az illesztőprogram-naplókban.

Ha az összetevő által engedélyezett elosztott betanítás naplók nélkül 70_driver meghiúsul, ellenőrizheti 70_mpi_log a hiba részleteit.
Az alábbi példa egy gyakori hibát mutat be, amely szerint a csomópontonkénti folyamatszám nagyobb, mint a számítási egység.

Az összetevők hibaelhárításával kapcsolatos további részletekért tekintse meg ezt a cikket .
Results (Eredmények)
A folyamatfeladat befejezése után a modell pontozáshoz való használatához csatlakoztassa a PyTorch-modell betanítása a képmodell pontozásához, hogy előrejelezhesse az új bemeneti példák értékeit.
Technikai megjegyzések
Várt bemenetek
| Név | Típus | Description |
|---|---|---|
| Nem betanított modell | Nem betanítottModelDirectory | Nem betanított modell, a PyTorch megkövetelése |
| Betanítási adatkészlet | ImageDirectory | Betanítási adatkészlet |
| Érvényesítési adatkészlet | ImageDirectory | Érvényesítési adatkészlet minden alapidőszakban kiértékelésre |
Összetevő paraméterei
| Name | Tartomány | Típus | Alapértelmezett | Description |
|---|---|---|---|---|
| Korszakok | >0 | Egész szám | 5 | Jelölje ki a címkét vagy az eredmény oszlopot tartalmazó oszlopot |
| Köteg mérete | >0 | Egész szám | 16 | Hány példányt kell betaníteni egy kötegben |
| Bemelegítési lépés száma | >=0 | Egész szám | 0 | Hány alapidőszakot kell bemelegíteni a bemelegítéshez? |
| Tanulási sebesség | >=dupla. Epsilon | Float | 0.1 | A sztochasztikus színátmenet-optimalizáló kezdeti tanulási sebessége. |
| Véletlenszerű mag | Bármelyik | Egész szám | 1 | A modell által használt véletlenszerű számgenerátor magja. |
| Türelem | >0 | Egész szám | 3 | Hány alapidőszakot kell korai leállítani a betanításhoz? |
| Nyomtatási gyakoriság | >0 | Egész szám | 10 | A betanítási napló nyomtatási gyakorisága az egyes alapidőszakok iterációinál |
Kimenetek
| Név | Típus | Description |
|---|---|---|
| Betanított modell | ModelDirectory | Betanított modell |
Következő lépések
Tekintse meg az Azure Machine Learning számára elérhető összetevőket .
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: