Synapse Spark-készlet csatolása és kezelése az Azure Machine Learningben
ÉRVÉNYES: Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Ebben a cikkben megtudhatja, hogyan csatolhat Synapse Spark-készletet az Azure Machine Learningben. A Synapse Spark-készletet az Azure Machine Learningben az alábbi módok egyikével csatolhatja:
- Az Azure Machine Learning Studio felhasználói felületének használata
- Az Azure Machine Learning parancssori felületének használata
- Az Azure Machine Learning Python SDK használata
Előfeltételek
- Azure-előfizetés; ha nem rendelkezik Azure-előfizetéssel, a kezdés előtt hozzon létre egy ingyenes fiókot .
- Egy Azure Machine Learning-munkaterület. Lásd: Munkaterület-erőforrások létrehozása.
- Azure Synapse Analytics-munkaterület létrehozása az Azure Portalon.
- Apache Spark-készlet létrehozása az Azure Portal használatával.
Synapse Spark-készlet csatolása az Azure Machine Learningben
Az Azure Machine Learning különböző módszereket kínál a Synapse Spark-készlet csatolására és kezelésére.
Synapse Spark-készlet csatolása a Studio Compute laphoz:

- A bal oldali panel Kezelés szakaszában válassza a Számítás lehetőséget.
- Válassza a Csatolt számítások lehetőséget.
- A Csatolt számítások képernyőn válassza az Új lehetőséget a különböző típusú számítások csatolásának lehetőségeinek megtekintéséhez.
- Válassza a Synapse Spark-készletet.
Megnyílik a Synapse Spark-készlet csatolása panel a képernyő jobb oldalán. Ebben a panelen:
Adjon meg egy nevet, amely a csatolt Synapse Spark-készletre hivatkozik az Azure Machine Learning-erőforrásban.
Válasszon egy Azure-előfizetést a legördülő menüből.
Válasszon ki egy Synapse-munkaterületet a legördülő menüből.
Válasszon egy Spark-készletet a legördülő menüből.
A felügyelt identitás hozzárendelése beállítás váltása annak engedélyezéséhez.
Válassza ki a csatolt Synapse Spark-készlethez használni kívánt felügyelt identitástípust .
Válassza a Frissítés lehetőséget a Synapse Spark-készlet csatolási folyamatának befejezéséhez.
Szerepkör-hozzárendelések hozzáadása az Azure Synapse Analyticsben
Annak érdekében, hogy a csatolt Synapse Spark-készlet megfelelően működjön, rendelje hozzá a rendszergazdai szerepkört az Azure Synapse Analytics studio felhasználói felületéről. Az alábbi lépések a következőket mutatják be:
Nyissa meg a Synapse-munkaterületet az Azure Portalon.
A bal oldali panelen válassza az Áttekintés lehetőséget.
Válassza a Synapse Studio megnyitása lehetőséget.
Az Azure Synapse Analytics studióban válassza a Kezelés lehetőséget a bal oldali panelen.
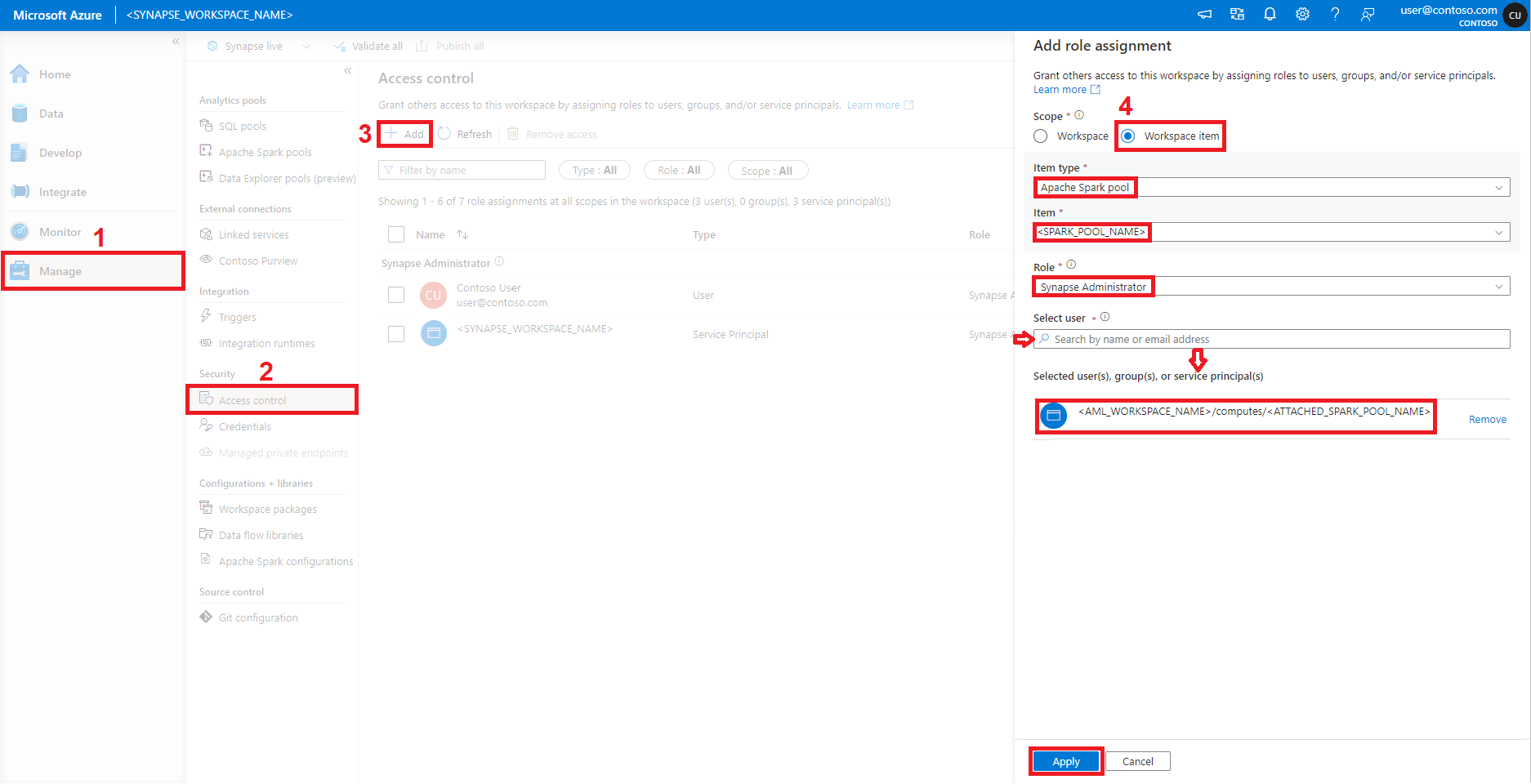
A bal oldali panel Biztonság szakaszában válassza a Hozzáférés-vezérlés lehetőséget, balról a másodikat.
Válassza a Hozzáadás lehetőséget.
A szerepkör-hozzárendelés hozzáadása panel a képernyő jobb oldalán nyílik meg. Ebben a panelen:
Válassza ki a Hatókör munkaterület elemét.
Az Elemtípus legördülő menüben válassza az Apache Spark-készletet.
Az Elem legördülő menüben válassza ki az Apache Spark-készletet.
A Szerepkör legördülő menüben válassza a Synapse-rendszergazda lehetőséget.
A Felhasználó kiválasztása keresőmezőbe kezdje el beírni az Azure Machine Learning-munkaterület nevét. A csatolt Synapse Spark-készletek listáját jeleníti meg. Válassza ki a kívánt Synapse Spark-készletet a listából.
Válassza az Alkalmazás lehetőséget.


A Synapse Spark-készlet frissítése
A csatolt Synapse Spark-készletet az Azure Machine Learning Studio felhasználói felületén kezelheti. A Spark-készlet felügyeleti funkciója magában foglalja a társított felügyelt identitásfrissítéseket egy csatolt Synapse Spark-készlethez. A Synapse Spark-készlet frissítésekor hozzárendelhet egy rendszer által hozzárendelt vagy felhasználó által hozzárendelt identitást. A Synapse Spark-készlethez való hozzárendelés előtt létre kell hoznia egy felhasználó által hozzárendelt felügyelt identitást az Azure Portalon.
A csatolt Synapse Spark-készlet felügyelt identitásának frissítése:

Nyissa meg a Synapse Spark-készlet Részletek lapját az Azure Machine Learning Studióban.
Keresse meg a felügyelt identitás szakasz jobb oldalán található szerkesztés ikont.
Ha először szeretne hozzárendelni egy felügyelt identitást, kapcsolja ki a felügyelt identitás hozzárendelése kapcsolót az engedélyezéshez.
Rendszer által hozzárendelt felügyelt identitás hozzárendelése:
- Válassza ki a rendszer által hozzárendelt identitástípust.
- Válassza a Frissítés lehetőséget.
Felhasználó által hozzárendelt felügyelt identitás hozzárendelése:
- Válassza ki a felhasználó által hozzárendelt identitástípust.
- Válasszon egy Azure-előfizetést a legördülő menüből.
- Írja be a felhasználó által hozzárendelt felügyelt identitás nevének első néhány betűét a név szerinti keresés szöveget megjelenítő mezőbe. Megjelenik egy felhasználó által hozzárendelt felügyelt identitásneveket tartalmazó lista. Válassza ki a felhasználó által hozzárendelt felügyelt identitást a listából. Több felhasználó által hozzárendelt felügyelt identitást is kijelölhet, és hozzárendelheti őket a csatolt Synapse Spark-készlethez.
- Válassza a Frissítés lehetőséget.
A Synapse Spark-készlet leválasztása
Előfordulhat, hogy leválasztunk egy csatolt Synapse Spark-készletet, hogy megtisztítsunk egy munkaterületet.
Az Azure Machine Learning Studio felhasználói felülete lehetővé teszi a csatlakoztatott Synapse Spark-készlet leválasztásának módját is. Ehhez kövesse az alábbi lépéseket:
Nyissa meg a Synapse Spark-készlet Részletek lapját az Azure Machine Learning Studióban.
Válassza a Leválasztás lehetőséget a csatolt Synapse Spark-készlet leválasztásához.
Kiszolgáló nélküli Spark-számítás az Azure Machine Learningben
Egyes felhasználói forgatókönyvek esetében szükség lehet egy kiszolgáló nélküli Spark számítási erőforráshoz való hozzáférésre egy Azure Machine Learning-feladat beküldése során anélkül, hogy Spark-készletet kellene csatolnia. Az Azure Synapse Analytics és az Azure Machine Learning integrációja kiszolgáló nélküli Spark számítási élményt is biztosít. Ez lehetővé teszi a Spark-számítási feladatokhoz való hozzáférést anélkül, hogy először hozzá kellene kapcsolnia a számítást egy munkaterülethez. További információ a kiszolgáló nélküli Spark számítási felületéről.
Következő lépések
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: