Spark-feladatok küldése az Azure Machine Learningben
ÉRVÉNYES: Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Az Azure Machine Learning támogatja az önálló gépi tanulási feladatok beküldését és olyan gépi tanulási folyamatok létrehozását, amelyek több gépi tanulási munkafolyamat-lépést is magukban foglalnak. Az Azure Machine Learning kezeli az önálló Spark-feladatok létrehozását és az Azure Machine Learning-folyamatok által használható újrafelhasználható Spark-összetevők létrehozását. Ebből a cikkből megtudhatja, hogyan küldhet be Spark-feladatokat a következő módon:
- Azure Machine Learning Studio felhasználói felület
- Azure Machine Learning CLI
- Azure Machine Learning SDK
Az Apache Spark Azure Machine Learning-fogalmaival kapcsolatos további információkért tekintse meg ezt az erőforrást.
Előfeltételek
A KÖVETKEZŐRE VONATKOZIK: Azure CLI ml-bővítmény v2 (aktuális)
- Azure-előfizetés; ha nem rendelkezik Azure-előfizetéssel, a kezdés előtt hozzon létre egy ingyenes fiókot .
- Egy Azure Machine Learning-munkaterület. Lásd: Munkaterület-erőforrások létrehozása.
- Azure Machine Learning számítási példány létrehozása.
- Telepítse az Azure Machine Learning CLI-t.
- (Nem kötelező): Csatolt Synapse Spark-készlet az Azure Machine Learning-munkaterületen.
Feljegyzés
- Az Azure Machine Learning kiszolgáló nélküli Spark-számítás és a csatolt Synapse Spark-készlet használata során az erőforrás-hozzáférésről további információt a Spark-feladatok erőforrás-hozzáférésének biztosítása című témakörben talál.
- Az Azure Machine Learning egy megosztott kvótakészletet biztosít, amelyből minden felhasználó hozzáférhet a számítási kvótához, és korlátozott ideig végezhet tesztelést. A kiszolgáló nélküli Spark-számítás használatakor az Azure Machine Learning lehetővé teszi, hogy rövid ideig hozzáférjen ehhez a megosztott kvótához.
Felhasználó által hozzárendelt felügyelt identitás csatolása a CLI v2 használatával
- Hozzon létre egy YAML-fájlt, amely meghatározza a munkaterülethez csatolandó, felhasználó által hozzárendelt felügyelt identitást:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - A paraméterrel
--filea parancs YAML-fájljávalaz ml workspace updatecsatolja a felhasználó által hozzárendelt felügyelt identitást:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Felhasználó által hozzárendelt felügyelt identitás csatolása ARMClient
- Telepítsen
ARMClientegy egyszerű parancssori eszközt, amely meghívja az Azure Resource Manager API-t. - Hozzon létre egy JSON-fájlt, amely meghatározza a munkaterülethez csatolandó, felhasználó által hozzárendelt felügyelt identitást:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - A felhasználó által hozzárendelt felügyelt identitás munkaterülethez való csatolásához hajtsa végre a következő parancsot a PowerShell-parancssorban vagy a parancssorban.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Feljegyzés
- A Spark-feladat sikeres végrehajtásához rendelje hozzá a Közreműködői és a Storage-blobadat-közreműködői szerepköröket az adatbemenethez és -kimenethez használt Azure Storage-fiókhoz a Spark-feladat által használt identitáshoz
- Az Azure Synapse-munkaterületen engedélyezni kell a nyilvános hálózati hozzáférést a Spark-feladat sikeres végrehajtásához egy csatolt Synapse Spark-készlet használatával.
- Ha egy csatolt Synapse Spark-készlet egy Synapse Spark-készletre mutat, egy olyan Azure Synapse-munkaterületen, amelyhez felügyelt virtuális hálózat van társítva, konfigurálnia kell egy felügyelt privát végpontot a tárfiókhoz az adathozzáférés biztosítása érdekében.
- A kiszolgáló nélküli Spark-számítás támogatja az Azure Machine Learning által felügyelt virtuális hálózatot. Ha egy felügyelt hálózat ki van építve a kiszolgáló nélküli Spark-számításhoz, a tárfiók megfelelő privát végpontjait is ki kellépíteni az adathozzáférés biztosítása érdekében.
Önálló Spark-feladat elküldése
Miután elvégezte a Python-szkriptparaméterezéshez szükséges módosításokat, az interaktív adatkonvergálás által kifejlesztett Python-szkriptek felhasználhatók egy kötegelt feladat elküldésére, hogy nagyobb mennyiségű adatot dolgozzanak fel. Egy egyszerű adatkonfiguráló kötegfeladat önálló Spark-feladatként küldhető el.
A Spark-feladatokhoz olyan Python-szkriptre van szükség, amely argumentumokat használ, és amely az interaktív adatmeghatolásból kifejlesztett Python-kód módosításával fejleszthető. Itt egy Python-példaszkript jelenik meg.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Feljegyzés
Ez a Python-kódminta a következőt használja pyspark.pandas: . Ezt csak a Spark 3.2-es vagy újabb verziója támogatja.
A fenti szkript két argumentumot --titanic_data használ, amelyek --wrangled_dataa bemeneti adatok és a kimeneti mappa elérési útját adják át.
A KÖVETKEZŐRE VONATKOZIK: Azure CLI ml-bővítmény v2 (aktuális)
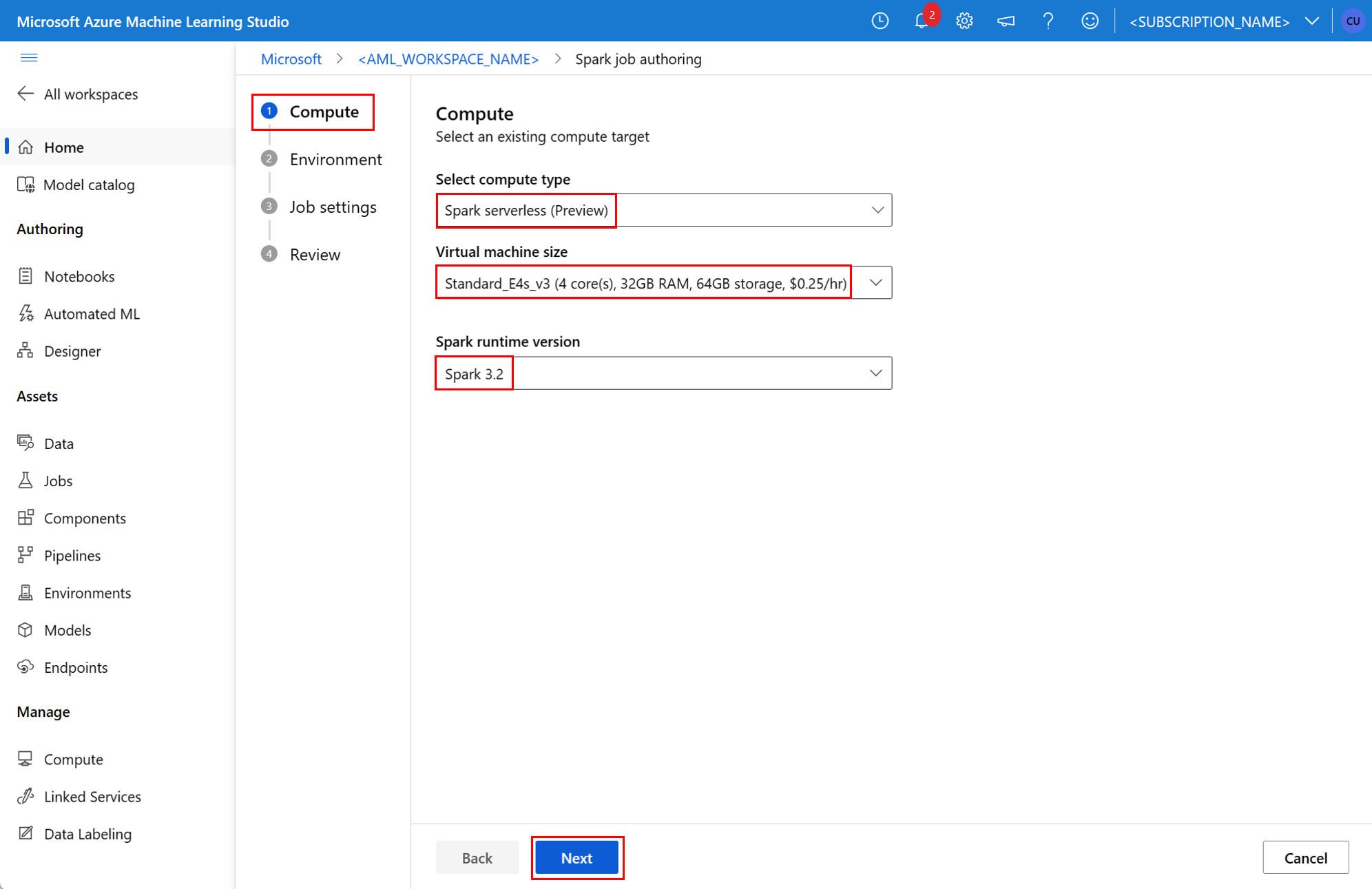
Feladat létrehozásához az önálló Spark-feladat yaML-specifikációs fájlként definiálható, amely a paraméterrel --file együtt használható a az ml job create parancsban. Adja meg ezeket a tulajdonságokat a YAML-fájlban:
YAML-tulajdonságok a Spark-feladat specifikációjában
type- a következőre vansparkállítva: .code- meghatározza a feladat forráskódját és szkripteit tartalmazó mappa helyét.entry- a feladat belépési pontjának meghatározása. A következő tulajdonságok egyikét kell lefednie:file- meghatározza annak a Python-szkriptnek a nevét, amely belépési pontként szolgál a feladathoz.
py_files- meghatározza a.zip.eggfeladat sikeres végrehajtásához elhelyezendőPYTHONPATHfájlok vagy.pyfájlok listáját. Ez a tulajdonság opcionális.jars- meghatározza a.jarSpark-illesztőprogramon és a végrehajtónCLASSPATHa feladat sikeres végrehajtásához belefoglalandó fájlok listáját. Ez a tulajdonság opcionális.files- meghatározza azoknak a fájloknak a listáját, amelyeket az egyes végrehajtók munkakönyvtárába kell másolni a sikeres feladatvégrehajtás érdekében. Ez a tulajdonság opcionális.archives- meghatározza az archívumok listáját, amelyeket az egyes végrehajtók munkakönyvtárába kell kinyerni a sikeres feladatvégrehajtás érdekében. Ez a tulajdonság opcionális.conf- az alábbi Spark-illesztőprogram- és végrehajtótulajdonságokat határozza meg:spark.driver.cores: a Spark-illesztőprogram magjainak száma.spark.driver.memory: lefoglalt memória a Spark-illesztőprogramhoz gigabájtban (GB).spark.executor.cores: a Spark-végrehajtó magjainak száma.spark.executor.memory: a Spark-végrehajtó memóriafoglalása gigabájtban (GB).spark.dynamicAllocation.enabled- hogy a végrehajtókat dinamikusan kell-e lefoglalni, értékként vagyFalseértékkéntTrue.- Ha engedélyezve van a végrehajtók dinamikus lefoglalása, adja meg az alábbi tulajdonságokat:
spark.dynamicAllocation.minExecutors- a Spark-végrehajtópéldányok minimális száma dinamikus lefoglaláshoz.spark.dynamicAllocation.maxExecutors- a Spark-végrehajtó példányok maximális száma dinamikus lefoglaláshoz.
- Ha a végrehajtók dinamikus lefoglalása le van tiltva, adja meg ezt a tulajdonságot:
spark.executor.instances- a Spark-végrehajtópéldányok száma.
environment- egy Azure Machine Learning-környezet a feladat futtatásához.args- azokat a parancssori argumentumokat, amelyeket át kell adni a feladatbeviteli pont Python-szkriptjének. Példaként tekintse meg az itt megadott YAML-specifikációs fájlt.resources- ez a tulajdonság határozza meg az Azure Machine Learning kiszolgáló nélküli Spark-számítás által használandó erőforrásokat. A következő tulajdonságokat használja:instance_type- a Spark-készlethez használandó számítási példány típusa. Jelenleg a következő példánytípusok támogatottak:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version- meghatározza a Spark futtatókörnyezet verzióját. Jelenleg a következő Spark-futtatókörnyezeti verziók támogatottak:3.33.4Fontos
Azure Synapse Runtime for Apache Spark: Announcements
- Azure Synapse Runtime for Apache Spark 3.3:
- EOLA közlemény dátuma: 2024. július 12.
- Támogatási dátum vége: 2025. március 31. A dátum után a futtatókörnyezet le lesz tiltva.
- A folyamatos támogatás és az optimális teljesítmény érdekében javasoljuk az Apache Spark 3.4-re való migrálást.
- Azure Synapse Runtime for Apache Spark 3.3:
Ez egy példa:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute- ez a tulajdonság egy csatolt Synapse Spark-készlet nevét határozza meg, az alábbi példában látható módon:compute: mysparkpoolinputs- ez a tulajdonság a Spark-feladat bemeneteit határozza meg. A Spark-feladatok bemenetei lehetnek literálértékek, vagy fájlokban vagy mappákban tárolt adatok.- A literális érték lehet szám, logikai érték vagy sztring. Néhány példa itt látható:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - A fájlban vagy mappában tárolt adatokat az alábbi tulajdonságok használatával kell definiálni:
type- állítsa be ezt a tulajdonságoturi_fileegy fájlban vagy mappában tárolt bemeneti adatokra, vagyuri_folderállítsa be ezt a tulajdonságot.path- a bemeneti adatok URI-ja, példáulazureml://: ,abfss://vagywasbs://.mode- állítsa be ezt a tulajdonságot a következőredirect: . Ez a minta egy feladatbemenet definícióját mutatja be, amely a következőnek$${inputs.titanic_data}}nevezhető:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- A literális érték lehet szám, logikai érték vagy sztring. Néhány példa itt látható:
outputs- ez a tulajdonság határozza meg a Spark-feladat kimeneteit. A Spark-feladatok kimenetei fájlba vagy mappába írhatók, amely a következő három tulajdonsággal van definiálva:type- ezt a tulajdonságot beállíthatja úgyuri_file, hogyuri_foldera kimeneti adatokat fájlba vagy mappába írja.path- ez a tulajdonság határozza meg a kimeneti hely URI-t, példáulazureml://: ,abfss://vagywasbs://.mode- állítsa be ezt a tulajdonságot a következőredirect: . Ez a minta egy feladatkimenet definícióját mutatja be, amely a következőnek${{outputs.wrangled_data}}nevezhető:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity- ez az opcionális tulajdonság határozza meg a feladat elküldéséhez használt identitást. Lehetnekuser_identityésmanagedlehetnek értékei. Ha a YAML-specifikáció nem definiál identitást, a Spark-feladat az alapértelmezett identitást használja.
Önálló Spark-feladat
Ez a példa YAML-specifikáció egy különálló Spark-feladatot mutat be. Kiszolgáló nélküli Azure Machine Learning Spark-számítást használ:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Feljegyzés
Csatolt Synapse Spark-készlet használatához a compute tulajdonság helyett a korábban bemutatott YAML-specifikációs fájlban adja meg a resources tulajdonságot.
A korábban bemutatott YAML-fájlok a az ml job create paraméterrel --file együtt használhatók önálló Spark-feladat létrehozásához a következő módon:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
A fenti parancsot a következő forrásból hajthatja végre:
- egy Azure Machine Learning számítási példány terminálja.
- egy Azure Machine Learning számítási példányhoz csatlakoztatott Visual Studio Code-terminál.
- a helyi számítógépre, amely telepítette az Azure Machine Learning CLI-t .
Spark-összetevő egy folyamatfeladatban
A Spark-összetevők rugalmasan használhatják ugyanazt az összetevőt több Azure Machine Learning-folyamatban is, folyamatlépésként.
A KÖVETKEZŐRE VONATKOZIK: Azure CLI ml-bővítmény v2 (aktuális)
A Spark-összetevők YAML-szintaxisa a Legtöbb módon hasonlít a Spark-feladat specifikációjának YAML-szintaxisára. Ezek a tulajdonságok eltérően vannak definiálva a Spark-összetevő YAML-specifikációjában:
name- a Spark-összetevő neve.version- a Spark-összetevő verziója.display_name- a felhasználói felületen és máshol megjelenítendő Spark-összetevő neve.description- a Spark-összetevő leírása.inputs- ez a tulajdonság hasonló a Spark-feladat specifikációjának YAML-szintaxisában leírt tulajdonsághozinputs, azzal a kivételt leszámítva, hogy nem határozza meg a tulajdonságotpath. Ez a kódrészlet a Spark-összetevőinputstulajdonság egy példáját mutatja be:inputs: titanic_data: type: uri_file mode: directoutputs- ez a tulajdonság hasonló aoutputsSpark-feladat specifikációjának YAML-szintaxisában leírt tulajdonsághoz, azzal a kivételt leszámítva, hogy nem határozza meg a tulajdonságotpath. Ez a kódrészlet a Spark-összetevőoutputstulajdonság egy példáját mutatja be:outputs: wrangled_data: type: uri_folder mode: direct
Feljegyzés
A Spark-összetevők nem határoznak meg vagy compute resources nem határoznak meg identitytulajdonságokat. A folyamat YAML specifikációs fájlja határozza meg ezeket a tulajdonságokat.
Ez a YAML-specifikációs fájl egy Spark-összetevőre mutat példát:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
A fenti YAML-specifikációs fájlban definiált Spark-összetevő egy Azure Machine Learning-folyamatfeladatban használható. A folyamatfeladat YAML-sémája további információt a folyamatfeladatot meghatározó YAML-szintaxisról talál. Ez a példa egy folyamatfeladat YAML-specifikációs fájlját mutatja be Egy Spark-összetevővel és egy Kiszolgáló nélküli Azure Machine Learning Spark-számítással:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
Feljegyzés
Csatolt Synapse Spark-készlet használatához tulajdonság helyett resources adja meg a compute tulajdonságot a fent látható YAML-mintafájlban.
A fenti YAML-specifikációs fájl a paraméterrel --file használható a az ml job create parancsban egy folyamatfeladat létrehozásához az alábbi módon:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
A fenti parancsot a következő forrásból hajthatja végre:
- egy Azure Machine Learning számítási példány terminálja.
- egy Azure Machine Learning számítási példányhoz csatlakoztatott Visual Studio Code-terminál.
- a helyi számítógépre, amely telepítette az Azure Machine Learning CLI-t .
Spark-feladatok hibaelhárítása
A Spark-feladatok hibaelhárításához hozzáférhet a feladathoz létrehozott naplókhoz az Azure Machine Learning Studióban. Spark-feladat naplóinak megtekintése:
- Navigáljon a Feladatok lapra az Azure Machine Learning Studio felhasználói felületén a bal oldali panelen
- A Minden feladat lap kiválasztása
- Válassza ki a feladat megjelenítendő névértékét
- A feladat részletei lapon válassza a Kimenet + naplók lapot
- A fájlkezelőben bontsa ki a naplók mappát, majd bontsa ki az azureml mappát
- A Spark-feladatnaplók elérése az illesztőprogram és a tárkezelő mappájában
Feljegyzés
A jegyzetfüzet-munkamenetben az interaktív adatátvétel során létrehozott Spark-feladatok hibaelhárításához válassza a jegyzetfüzet felhasználói felületének jobb felső sarkában található Feladat részletei lehetőséget. Az interaktív jegyzetfüzet-munkamenetekből létrehozott Spark-feladatok jegyzetfüzetfuttatások néven jönnek létre.