Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk bemutatja, hogyan fejleszthet betanítási szkriptet egy jegyzetfüzet használatával egy Azure Machine Learning-felhőbeli munkaállomáson. Az oktatóanyag az első lépésekhez szükséges alapvető lépéseket ismerteti:
- Állítsa be és konfigurálja a felhőbeli munkaállomást. A felhőalapú munkaállomást egy Azure Machine Learning számítási példány működteti, amely előre konfigurálva van környezetekkel a modellfejlesztési igények támogatására.
- Felhőalapú fejlesztési környezetek használata.
- Az MLflow használatával nyomon követheti a modellmetrikáit.
Előfeltételek
Az Azure Machine Learning használatához munkaterületre van szüksége. Ha nem rendelkezik ilyen erőforrással, végezze el a munkaterület létrehozásához szükséges erőforrások létrehozását, és tudjon meg többet a használatáról.
Fontos
Ha az Azure Machine Learning-munkaterület felügyelt virtuális hálózattal van konfigurálva, előfordulhat, hogy kimenő szabályokat kell hozzáadnia a nyilvános Python-csomagtárakhoz való hozzáférés engedélyezéséhez. További információ: Forgatókönyv: Nyilvános gépi tanulási csomagok elérése.
Számítás létrehozása vagy indítása
Számítási erőforrásokat a munkaterület Számítási szakaszában hozhat létre. A számítási példány egy felhőalapú munkaállomás, amelyet teljes mértékben az Azure Machine Learning felügyel. Ez az oktatóanyag-sorozat számítási példányt használ. Használhatja saját kód futtatására, modellek fejlesztésére és tesztelésére is.
- Jelentkezzen be az Azure Machine Learning Studióba.
- Válassza ki a munkaterületét, ha az még nincs megnyitva.
- A bal oldali panelen válassza a Számítás lehetőséget.
- Ha nincs számítási példány, a lap közepén látható az Új. Válassza az Új lehetőséget, és töltse ki az űrlapot. Az összes alapértelmezett beállítást használhatja.
- Ha rendelkezik számítási példánysal, válassza ki a listából. Ha le van állítva, válassza a Start lehetőséget.
A Visual Studio Code (VS Code) megnyitása
Miután rendelkezik egy futó számítási példánysal, különböző módokon érheti el. Ez az oktatóanyag bemutatja, hogyan használhatja a számítási példányt a Visual Studio Code-ból. A Visual Studio Code teljes körű integrált fejlesztési környezetet (IDE) biztosít a számítási példányok létrehozásához.
A számítási példányok listájában válassza ki a használni kívánt számítási példány VS Code (web) vagy VS Code (Asztali) hivatkozását. Ha a VS Code (Desktop) lehetőséget választja, egy üzenet jelenhet meg, amely megkérdezi, hogy meg szeretné-e nyitni az alkalmazást.

Ez a Visual Studio Code-példány a számítási példányhoz és a munkaterület fájlrendszeréhez van csatolva. Még akkor is, ha az asztalon nyitja meg, a megjelenő fájlok a munkaterület fájljai.
Új környezet beállítása prototípus-készítéshez
A szkript futtatásához olyan környezetben kell dolgoznia, amely a kód által várt függőségekkel és kódtárakkal van konfigurálva. Ez a szakasz segít létrehozni egy, a kódhoz szabott környezetet. Az új Jupyter-kernel létrehozásához, amelyhez a jegyzetfüzet csatlakozik, egy YAML-fájlt használ, amely meghatározza a függőségeket.
Töltsön fel egy fájlt.
A feltöltött fájlok egy Azure-fájlmegosztásban vannak tárolva, és ezek a fájlok az egyes számítási példányokra vannak csatlakoztatva, és meg vannak osztva a munkaterületen.
Nyissa meg az azureml-examples/tutorials/get-started-notebooks/workstation_env.yml.
Töltse le a Conda környezeti fájlt workstation_env.yml a számítógépre a lap jobb felső sarkában található három pont gombra (...), majd válassza a Letöltés lehetőséget.
Húzza a fájlt a számítógépről a Visual Studio Code ablakba. A rendszer feltölti a fájlt a munkaterületre.
Helyezze át a fájlt a felhasználónév mappájába.
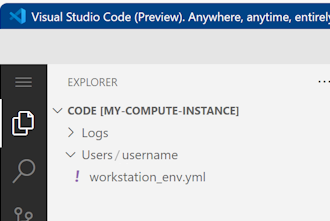
Válassza ki a fájlt az előnézet megtekintéséhez. Tekintse át a megadott függőségeket. Ehhez hasonlót kell látnia:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibHozzon létre egy kernelt.
Most a terminál használatával hozzon létre egy új Jupyter-kernelt, amely a workstation_env.yml fájlon alapul.
- A Visual Studio Code tetején lévő menüben válassza az Új terminál terminál lehetőséget>.
Tekintse meg az aktuális Conda-környezeteket. Az aktív környezet csillaggal (*) van megjelölve.
conda env listNavigáljon a
cdkönyvtárba, ahová feltöltötte a workstation_env.yml fájlt. Ha például feltöltötte a felhasználói mappába, használja ezt a parancsot:cd Users/myusernameGyőződjön meg arról, hogy workstation_env.yml a mappában van.
lsHozza létre a környezetet a megadott Conda-fájl alapján. A környezet létrehozása néhány percet vesz igénybe.
conda env create -f workstation_env.ymlAktiválja az új környezetet.
conda activate workstation_envFeljegyzés
Ha megjelenik a CommandNotFoundError, kövesse a futtatáshoz
conda init bashszükséges utasításokat, zárja be a terminált, majd nyisson meg egy újat. Ezután próbálkozzon újra aconda activate workstation_envparanccsal.Ellenőrizze, hogy a megfelelő környezet aktív-e, és keresse meg ismét a *-gal megjelölt környezetet.
conda env listHozzon létre egy új Jupyter-kernelt, amely az aktív környezeten alapul.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Zárja be a terminálablakot.
Most már van egy új kernele. Ezután megnyit egy jegyzetfüzetet, és ezt a kernelt fogja használni.
Jegyzetfüzet létrehozása
- A Visual Studio Code tetején lévő menüben válassza az Új fájl fájlja > lehetőséget.
- Nevezze el az új fájlt develop-tutorial.ipynb (vagy használjon másik nevet). Mindenképpen használja az .ipynb bővítményt.
A kernel beállítása
- Az új fájl jobb felső sarkában válassza a Kernel kiválasztása lehetőséget.
- Válassza ki az Azure ML számítási példányt (computeinstance-name).
- Válassza ki a létrehozott kernelt: Tutorial Workstation Env. Ha nem látja a kernelt, válassza a lista feletti frissítés gombot.
Betanítási szkript fejlesztése
Ebben a szakaszban egy Python-betanítási szkriptet fejleszt, amely az UCI-adatkészletből származó előkészített teszt- és betanítási adatkészletek használatával előrejelzi a hitelkártya alapértelmezett kifizetéseit.
Ez a kód sklearn-ot használ tanításra, és az MLflow-t a metrikák naplózására.
Kezdje a betanítási szkriptben használni kívánt csomagokat és kódtárakat importáló kóddal.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitEzután töltse be és dolgozza fel a kísérlet adatait. Ebben az oktatóanyagban egy internetes fájlból olvassa be az adatokat.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Készítse elő az adatokat a betanításhoz.
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesAdjon hozzá kódot az MLflow automatikus naplózásához, hogy követni tudja a metrikákat és az eredményeket. A modellfejlesztés iteratív jellegével az MLflow segít naplózni a modell paramétereit és eredményeit. A modell teljesítményének összehasonlításához és megértéséhez tekintse meg a különböző futtatásokat. A naplók kontextust is biztosítanak, amikor készen áll arra, hogy a fejlesztési fázisról a munkafolyamatok betanítási fázisára lépjen az Azure Machine Learningben.
# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Modell betanítása.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Feljegyzés
Figyelmen kívül hagyhatja az MLflow-figyelmeztetéseket. A szükséges eredmények továbbra is nyomon lesznek követve.
Válassza az Összes futtatása parancsot a kód felett.
Továbbhaladás
Most, hogy már rendelkezik modelleredményekkel, változtasson valamit, és futtassa újra a modellt. Próbálkozzon például egy másik besorolási technikával:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Feljegyzés
Figyelmen kívül hagyhatja az MLflow-figyelmeztetéseket. A szükséges eredmények továbbra is nyomon lesznek követve.
A modell futtatásához válassza az Összes futtatása lehetőséget.
Az eredmények vizsgálata
Most, hogy két különböző modellt kipróbált, az MLFfow által nyomon követett eredményeket használva döntse el, melyik modell a jobb. Olyan metrikákra hivatkozhat, mint a pontosság vagy más, a forgatókönyvek szempontjából leginkább fontos mutatók. Ezeket az eredményeket részletesebben is áttekintheti az MLflow által létrehozott feladatok megtekintésével.
Térjen vissza a munkaterületre az Azure Machine Learning Studióban.
A bal oldali panelen válassza a Feladatok lehetőséget.
Válassza a Fejlesztés felhőalapú oktatóanyagot.
Két feladat jelenik meg, egy-egy a kipróbált modellekhez. A nevek automatikusan létre lettek hozva. Ha át szeretné nevezni a feladatot, vigye az egérmutatót a név fölé, és válassza a mellette lévő ceruza gombot.
Válassza ki az első feladat hivatkozását. A név a lap tetején jelenik meg. A ceruzagombbal itt is átnevezheti.
A lapon a feladatok részletei láthatók, például tulajdonságok, kimenetek, címkék és paraméterek. A Címkék területen megjelenik a modell típusát leíró estimator_name.
Válassza a Metrikák lapot az MLflow által naplózott metrikák megtekintéséhez. (Az eredmények eltérőek lesznek, mert más betanítási készlettel rendelkezik.)
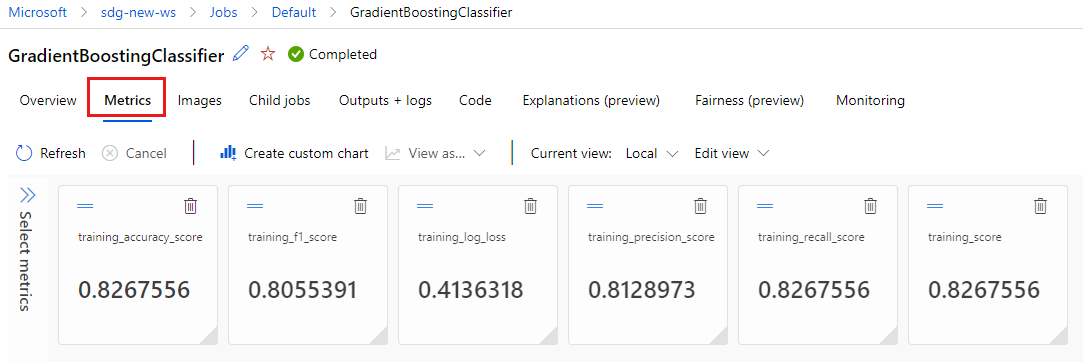
Az MLflow által létrehozott képek megtekintéséhez válassza a Képek lapot.
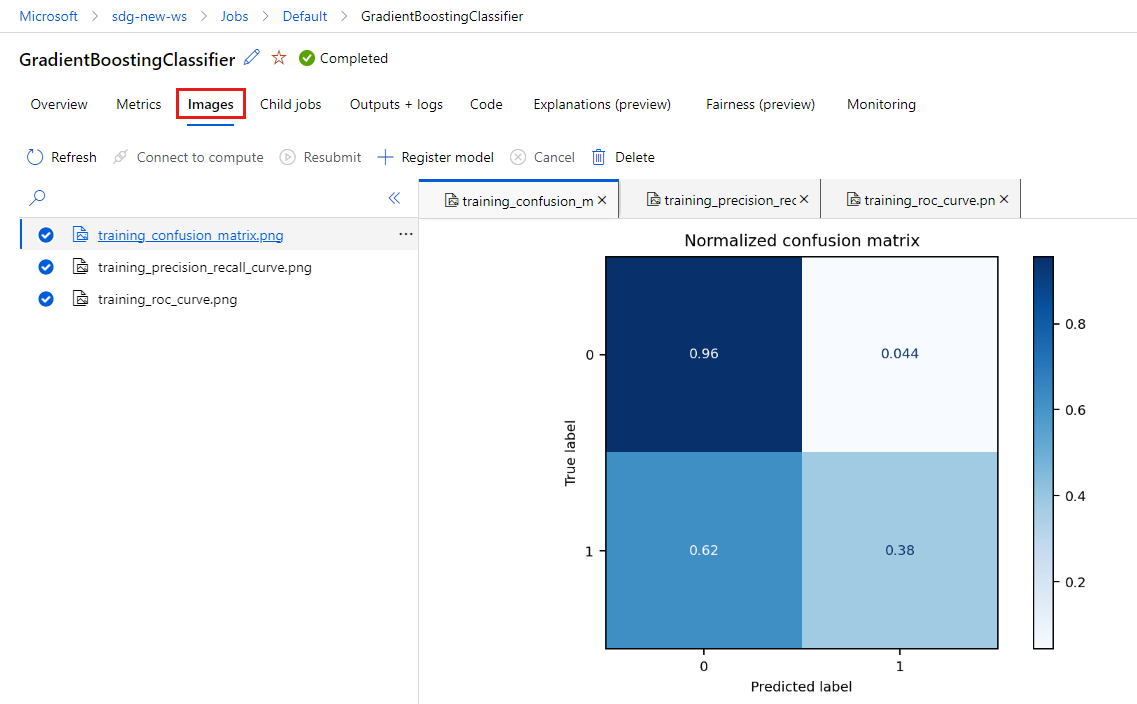
Térjen vissza, és tekintse át a másik modell metrikáit és rendszerképeit.

Python-szkript létrehozása
Most létrehoz egy Python-szkriptet a jegyzetfüzetből a modell betanításához.
A Visual Studio Code-ban kattintson a jobb gombbal a jegyzetfüzetfájl nevére, és válassza a Jegyzetfüzet importálása szkriptbe lehetőséget.
Válassza a Fájl > mentése lehetőséget az új szkriptfájl mentéséhez. Hívja train.py.
Tekintse át a fájlt, és törölje a betanítási szkriptben nem kívánt kódot. Megtarthatja például a használni kívánt modell kódját, és törölheti a nem használni kívánt modell kódját.
- Győződjön meg arról, hogy megtartja az automatikus naplózás kódját (
mlflow.sklearn.autolog()). - Amikor interaktívan futtatja a Python-szkriptet (ahogy itt is teszi), megtarthatja a kísérlet nevét (
mlflow.set_experiment("Develop on cloud tutorial")) meghatározó sort. Más nevet is adhat neki, ha a Feladatok szakaszban más bejegyzésként tekint rá. Amikor azonban előkészíti a szkriptet egy betanítási feladathoz, ez a sor nem érvényes, ezért el kell hagyni: a feladatdefiníció tartalmazza a kísérlet nevét. - Egyetlen modell betanításakor a futtatás megkezdésének és befejezésének sorai (
mlflow.start_run()ésmlflow.end_run()) nem szükségesek (nincs hatásuk), de benne hagyhatja őket.
- Győződjön meg arról, hogy megtartja az automatikus naplózás kódját (
Ha végzett a szerkesztésekkel, mentse a fájlt.
Most már rendelkezik egy Python-szkripttel az előnyben részesített modell betanításához.
A Python-szkript futtatása
Egyelőre ezt a kódot a számítási példányon futtatja, amely az Azure Machine Learning fejlesztési környezete. Oktatóanyag: A modell betanítása bemutatja, hogyan futtathat egy betanítási szkriptet skálázhatóbb módon a nagyobb teljesítményű számítási erőforrásokon.
Válassza ki az oktatóanyag korábbi részében létrehozott környezetet Python-verzióként (workstations_env). A jegyzetfüzet jobb alsó sarkában megjelenik a környezet neve. Jelölje ki, majd válassza ki a környezetet a Visual Studio Code tetején.
Futtassa a Python-szkriptet a kód fölött található Minden futtatása gombra kattintva.


Feljegyzés
Figyelmen kívül hagyhatja az MLflow-figyelmeztetéseket. Továbbra is lekérheti az összes metrikát és képet az automatikus kitöltésből.
A szkript eredményeinek vizsgálata
Térjen vissza a munkaterületen lévő Feladatokhoz az Azure Machine Learning Studióban, és tekintse meg a betanítási szkript eredményeit. Ne feledje, hogy a betanítási adatok az egyes felosztásokkal változnak, így az eredmények különbözőek a végrehajtások között.
Az erőforrások eltávolítása
Ha további oktatóanyagokat szeretne folytatni, ugorjon a Következő lépésekre.
A számítási példány leállítása
Ha most nem fogja használni, állítsa le a számítási példányt:
- A stúdió bal oldali paneljén válassza a Számítás lehetőséget.
- A lap tetején válassza a Számítási példányok lehetőséget.
- A listában válassza ki a számítógépes példányt.
- A lap tetején válassza a Leállítás lehetőséget.
Az összes erőforrás törlése
Fontos
A létrehozott erőforrások előfeltételként használhatók más Azure Machine Learning-oktatóanyagokhoz és útmutatókhoz.
Ha nem tervezi használni a létrehozott erőforrások egyikét sem, törölje őket, hogy ne járjon költséggel:
Az Azure Portal keresőmezőjében adja meg az erőforráscsoportokat , és válassza ki az eredmények közül.
A listából válassza ki a létrehozott erőforráscsoportot.
Az Áttekintés lapon válassza az Erőforráscsoport törlése lehetőséget.
Adja meg az erőforráscsoport nevét. Ezután válassza a Törlés elemet.
Következő lépések
További információkért tekintse meg az alábbi forrásanyagokat:
- Összetevők és modellek az MLflow-ban
- Git használata az Azure Machine Learninggel
- Jupyter-jegyzetfüzetek futtatása a munkaterületen
- Számításipéldány-terminál használata a munkaterületen
- Jegyzetfüzet- és terminál-munkamenetek kezelése
Ez az oktatóanyag bemutatja a modell létrehozásának korai lépéseit, és a prototípuskészítést ugyanazon a gépen, ahol a kód található. Az éles betanításhoz ismerje meg, hogyan használhatja ezt a betanítási szkriptet nagyobb teljesítményű távoli számítási erőforrásokon: