Oktatóanyag: Modell betanítása az Azure Machine Learningben
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azure-ai-ml v2 (aktuális)
Python SDK azure-ai-ml v2 (aktuális)
Megtudhatja, hogyan tanít be egy modellt egy adattudós az Azure Machine Learning használatával. Ebben a példában egy hitelkártya-adatkészlet használatával megtudhatja, hogyan használhatja az Azure Machine Learninget besorolási problémák esetén. A cél annak előrejelzése, hogy az ügyfél nagy valószínűséggel fizet-e hitelkártyás fizetést. A betanítási szkript kezeli az adatok előkészítését. A szkript ezután betanít és regisztrál egy modellt.
Ez az oktatóanyag végigvezeti egy felhőalapú betanítási feladat (parancsfeladat) beküldésének lépésein.
- Fogópont lekérése az Azure Machine Learning-munkaterületre
- Számítási erőforrás- és feladatkörnyezet létrehozása
- Betanítási szkript létrehozása
- Hozza létre és futtassa a parancsfeladatot a betanítási szkript futtatásához a számítási erőforráson
- A betanítási szkript kimenetének megtekintése
- Az újonnan betanított modell üzembe helyezése végpontként
- Az Azure Machine Learning-végpont meghívása következtetéshez
Ha többet szeretne megtudni arról, hogyan töltheti be az adatokat az Azure-ba, tekintse meg az Azure Machine Learningben az adatok feltöltését, elérését és felderítését ismertető oktatóanyagot.
Ez a videó bemutatja, hogyan kezdheti meg az Azure Machine Learning Studiót, hogy követni tudja az oktatóanyag lépéseit. A videó bemutatja, hogyan hozhat létre jegyzetfüzetet, hozhat létre számítási példányt, és klónozhatja a jegyzetfüzetet. A lépéseket a következő szakaszokban is ismertetjük.
Előfeltételek
-
Az Azure Machine Learning használatához munkaterületre van szüksége. Ha nem rendelkezik ilyen erőforrással, végezze el a munkaterület létrehozásához szükséges erőforrások létrehozását, és tudjon meg többet a használatáról.
-
Jelentkezzen be a stúdióba , és válassza ki a munkaterületet, ha még nincs megnyitva.
-
Jegyzetfüzet megnyitása vagy létrehozása a munkaterületen:
- Ha kódot szeretne másolni és beilleszteni a cellákba, hozzon létre egy új jegyzetfüzetet.
- Vagy nyisson meg oktatóanyagokat/get-started-notebooks/train-model.ipynb-t a Studio Minták szakaszából. Ezután válassza a Klónozás lehetőséget a jegyzetfüzet fájlokhoz való hozzáadásához. A mintajegyzetfüzetek megkereséséhez lásd : Learn from sample notebooks.
A kernel beállítása és megnyitása a Visual Studio Code-ban (VS Code)
A megnyitott jegyzetfüzet fölötti felső sávon hozzon létre egy számítási példányt, ha még nem rendelkezik ilyenrel.

Ha a számítási példány le van állítva, válassza a Számítás indítása lehetőséget, és várja meg, amíg fut.

Várjon, amíg a számítási példány fut. Ezután győződjön meg arról, hogy a jobb felső sarokban található kernel az
Python 3.10 - SDK v2. Ha nem, válassza ki a kernelt a legördülő listából.
Ha nem látja ezt a kernelt, ellenőrizze, hogy fut-e a számítási példány. Ha igen, válassza a jegyzetfüzet jobb felső sarkában található Frissítés gombot.
Ha megjelenik egy szalagcím, amely azt jelzi, hogy hitelesíteni kell, válassza a Hitelesítés lehetőséget.
A jegyzetfüzetet itt futtathatja, vagy megnyithatja a VS Code-ban egy teljes integrált fejlesztési környezethez (IDE) az Azure Machine Learning-erőforrások segítségével. Válassza a Megnyitás a VS Code-ban lehetőséget, majd válassza a webes vagy asztali lehetőséget. Ha így indul el, a VS Code a számítási példányhoz, a kernelhez és a munkaterület fájlrendszeréhez lesz csatolva.





Fontos
Az oktatóanyag többi része az oktatóanyag-jegyzetfüzet celláit tartalmazza. Másolja és illessze be őket az új jegyzetfüzetbe, vagy váltson most a jegyzetfüzetre, ha klónozta.
Modell betanítása parancsfeladat használatával az Azure Machine Learningben
A modell betanítása érdekében be kell küldenie egy feladatot. Az Azure Machine Learning számos különböző típusú feladatot kínál a modellek betanítása érdekében. A felhasználók a modell összetettsége, az adatméret és a betanítási sebesség követelményei alapján választhatják ki a betanítási módszerüket. Ebben az oktatóanyagban megtudhatja, hogyan küldhet be egy parancsfeladatot egy betanítási szkript futtatásához.
A parancsfeladatok olyan függvények, amelyekkel egyéni betanítási szkriptet küldhet be a modell betanításához. Ez a feladat egyéni betanítási feladatként is definiálható. Az Azure Machine Learning parancsfeladata olyan feladattípus, amely szkriptet vagy parancsot futtat egy adott környezetben. A parancsfeladatok segítségével modelleket taníthat be, adatokat dolgozhat fel vagy bármely más egyéni kódot, amelyet a felhőben szeretne végrehajtani.
Ez az oktatóanyag a modell betanításához használt egyéni betanítási feladat létrehozására összpontosít egy parancsfeladat használatával. Minden egyéni betanítási feladathoz a következő elemek szükségesek:
- környezet
- adatok
- parancsfeladat
- betanítási szkript
Ez az oktatóanyag a következő elemeket mutatja be a példához: osztályozó létrehozása annak előrejelzéséhez, hogy az ügyfelek nagy valószínűséggel alapértelmezettek-e a hitelkártyás fizetések esetében.
Leíró létrehozása munkaterületre
Mielőtt belemerül a kódba, szüksége van egy módszerre a munkaterületre való hivatkozáshoz. Hozzon létre ml_client egy leírót a munkaterületen. Ezután erőforrások és feladatok kezelésére használható ml_client .
A következő cellában adja meg az előfizetés azonosítóját, az erőforráscsoport nevét és a munkaterület nevét. Az alábbi értékek megkeresése:
- A jobb felső Azure Machine Learning Studio eszköztáron válassza ki a munkaterület nevét.
- Másolja a munkaterület, az erőforráscsoport és az előfizetés azonosítójának értékét a kódba. Ki kell másolnia egy értéket, be kell zárnia a területet, és be kell illesztenie, majd vissza kell térnie a következőhöz.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Feljegyzés
Az MLClient létrehozása nem csatlakozik a munkaterülethez. Az ügyfél inicializálása lusta. Az első alkalommal várakozik, amikor hívást kell kezdeményeznie, ami a következő kódcellában történik.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Feladatkörnyezet létrehozása
Az Azure Machine Learning-feladat számítási erőforráson való futtatásához környezetre van szükség. Egy környezet felsorolja azokat a szoftveres futtatókörnyezeteket és kódtárakat, amelyeket telepíteni szeretne a számításra, ahol a betanítás történik. Hasonló a helyi gépen lévő Python-környezethez. További információ: Mik azok az Azure Machine Learning-környezetek?
Az Azure Machine Learning számos válogatott vagy kész környezetet biztosít, amelyek hasznosak a gyakori betanítási és következtetési forgatókönyvekhez.
Ebben a példában egy egyéni conda-környezetet hoz létre a feladatokhoz egy conda yaml-fájl használatával.
Először hozzon létre egy könyvtárat a fájl tárolásához.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
A következő cella az IPython magic használatával írja be a conda fájlt a létrehozott könyvtárba.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=1.0.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- mlflow==2.8.0
- mlflow-skinny==2.8.0
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- tqdm>=4.59,<4.60
- ipykernel~=6.0
- matplotlib
A specifikáció tartalmaz néhány, a feladathoz használt szokásos csomagot, például a numpy-t és a pipet.
Erre a yaml-fájlra hivatkozva hozza létre és regisztrálja ezt az egyéni környezetet a munkaterületen:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
custom_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults job",
tags={"scikit-learn": "1.0.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
custom_job_env = ml_client.environments.create_or_update(custom_job_env)
print(
f"Environment with name {custom_job_env.name} is registered to workspace, the environment version is {custom_job_env.version}"
)
Betanítási feladat konfigurálása a parancsfüggvény használatával
Létrehoz egy Azure Machine Learning-parancsfeladatot, amely betanít egy modellt a kredit alapértelmezett előrejelzéséhez. A parancsfeladat egy betanítási szkriptet futtat egy megadott környezetben egy adott számítási erőforráson. Már létrehozta a környezetet és a számítási fürtöt. Ezután hozza létre a betanítási szkriptet. Ebben az esetben betanítja az adathalmazt, hogy egy osztályozót állítsunk elő a GradientBoostingClassifier modell használatával.
A betanítási szkript kezeli a betanított modell adatelőkészítését, betanítását és regisztrálását. A módszer train_test_split az adathalmazt teszt- és betanítási adatokra osztja fel. Ebben az oktatóanyagban létrehoz egy Python-betanítási szkriptet.
A parancsfeladatok parancssori felületről, Python SDK-ból vagy stúdiófelületről futtathatók. Ebben az oktatóanyagban az Azure Machine Learning Python SDK v2 használatával hozza létre és futtassa a parancsfeladatot.
Betanítási szkript létrehozása
Először hozza létre a betanítási szkriptet: a main.py Python-fájlt. Először hozzon létre egy forrásmappát a szkripthez:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Ez a szkript előre feldolgozja az adatokat, és felosztja őket tesztelési és betanítási adatokra. Ezután felhasználja az adatokat egy faalapú modell betanítása és a kimeneti modell visszaadása érdekében.
Az MLFlow a feladat során a paraméterek és metrikák naplózására szolgál. Az MLFlow-csomag lehetővé teszi az egyes Modellek Azure-beli vonatainak metrikáinak és eredményeinek nyomon követését. Az MLFlow használatával a legjobb modellt érheti el az adatokhoz. Ezután tekintse meg a modell metrikáit az Azure Studióban. További információ: MLflow és Azure Machine Learning.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
#Split train and test datasets
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Ebben a szkriptben a modell betanítása után a rendszer menti és regisztrálja a modellfájlt a munkaterületen. A modell regisztrálása lehetővé teszi, hogy a modelleket az Azure-felhőben, a munkaterületen tárolja és verziószámozza. A modell regisztrálása után az összes többi regisztrált modellt egy helyen találja meg az Azure Studióban, a modellregisztrációs adatbázisban. A modellregisztrációs adatbázis segít a betanított modellek rendszerezésében és nyomon követésében.
A parancs konfigurálása
Most, hogy rendelkezik egy szkripttel, amely képes elvégezni a besorolási feladatot, használja az általános célú parancsot , amely parancssori műveleteket futtathat. Ez a parancssori művelet lehet közvetlenül rendszerparancsok hívása vagy szkript futtatása.
Bemeneti változók létrehozása a bemeneti adatok, a felosztási arány, a tanulási sebesség és a regisztrált modellnév megadásához. A parancsszkript:
- A korábban létrehozott környezetet használja. A jelölés használatával
@latestjelezheti a környezet legújabb verzióját a parancs futtatásakor. - Ebben az esetben magát
python main.pya parancssori műveletet konfigurálja. A parancs bemeneteit és kimeneteit a jelöléssel${{ ... }}érheti el. - Mivel nincs megadva számítási erőforrás, a szkript egy automatikusan létrehozott kiszolgáló nélküli számítási fürtön fut.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="aml-scikit-learn@latest",
display_name="credit_default_prediction",
)
Feladat küldése
Küldje el a feladatot az Azure Machine Learning Studióban való futtatáshoz. Ezúttal használja create_or_update a következőt ml_client: . ml_client Egy ügyfélosztály, amely lehetővé teszi az Azure-előfizetéshez való csatlakozást a Python használatával, és az Azure Machine Learning-szolgáltatásokkal való interakciót. ml_client Lehetővé teszi a feladatok Python használatával történő elküldését.
ml_client.create_or_update(job)
Feladat kimenetének megtekintése és várakozás a feladat befejezésére
Ha meg szeretné tekinteni a feladatot az Azure Machine Learning Studióban, válassza ki az előző cella kimenetében található hivatkozást. A feladat kimenete így néz ki az Azure Machine Learning Studióban. A különböző részletek, például metrikák, kimenetek stb. megismeréséhez tekintse meg a lapokat. A feladat befejezése után a betanítás eredményeként regisztrál egy modellt a munkaterületen.
Fontos
Várjon, amíg a feladat állapota befejeződik, mielőtt visszatér ehhez a jegyzetfüzethez a folytatáshoz. A feladat futtatása 2–3 percet vesz igénybe. Akár 10 percig is eltarthat, ha a számítási fürt nullára van skálázva, és az egyéni környezet még mindig épül.
A cella futtatásakor a jegyzetfüzet kimenete egy hivatkozást jelenít meg a Feladat részletei lapjára a Machine Learning Studióban. Másik lehetőségként a bal oldali navigációs menüBen a Feladatok lehetőséget is választhatja.
A feladatok egy adott szkriptből vagy kódrészletből származó számos futtatás csoportosítását képezik. A futtatásra vonatkozó információk a feladat alatt lesznek tárolva. A részletek lap áttekintést nyújt a feladatról, a futtatás idejéről, a létrehozásuk időpontjáról és egyéb információkról. A lapon lapfülek találhatók a feladat egyéb információihoz, például metrikákhoz, kimenetekhez és naplókhoz és kódhoz. A feladat részleteinek oldalán az alábbi lapok érhetők el:
- Áttekintés: Alapvető információk a feladatról, beleértve az állapotát, a kezdési és befejezési időpontokat, valamint a futtatott feladat típusát
- Bemenetek: A feladat bemeneteként használt adatok és kód. Ez a szakasz tartalmazhat adatkészleteket, szkripteket, környezeti konfigurációkat és a betanítás során használt egyéb erőforrásokat.
- Kimenetek + naplók: A feladat futtatása közben létrehozott naplók. Ez a lap segít a hibaelhárításban, ha bármi baj van a betanítási szkripttel vagy a modell létrehozásával.
- Metrikák: A modell fő teljesítménymetrikái, például a betanítási pontszám, az f1 pontszám és a pontossági pontszám.
Az erőforrások eltávolítása
Ha most további oktatóanyagokat szeretne folytatni, ugorjon a kapcsolódó tartalomra.
Számítási példány leállítása
Ha most nem fogja használni, állítsa le a számítási példányt:
- A stúdió bal oldali navigációs területén válassza a Számítás lehetőséget.
- A felső lapon válassza a Számítási példányok lehetőséget.
- Válassza ki a számítási példányt a listában.
- A felső eszköztáron válassza a Leállítás lehetőséget.
Az összes erőforrás törlése
Fontos
A létrehozott erőforrások előfeltételként használhatók más Azure Machine Learning-oktatóanyagokhoz és útmutatókhoz.
Ha nem tervezi használni a létrehozott erőforrások egyikét sem, törölje őket, hogy ne járjon költséggel:
Az Azure Portal keresőmezőjében adja meg az erőforráscsoportokat , és válassza ki az eredmények közül.
A listából válassza ki a létrehozott erőforráscsoportot.
Az Áttekintés lapon válassza az Erőforráscsoport törlése lehetőséget.
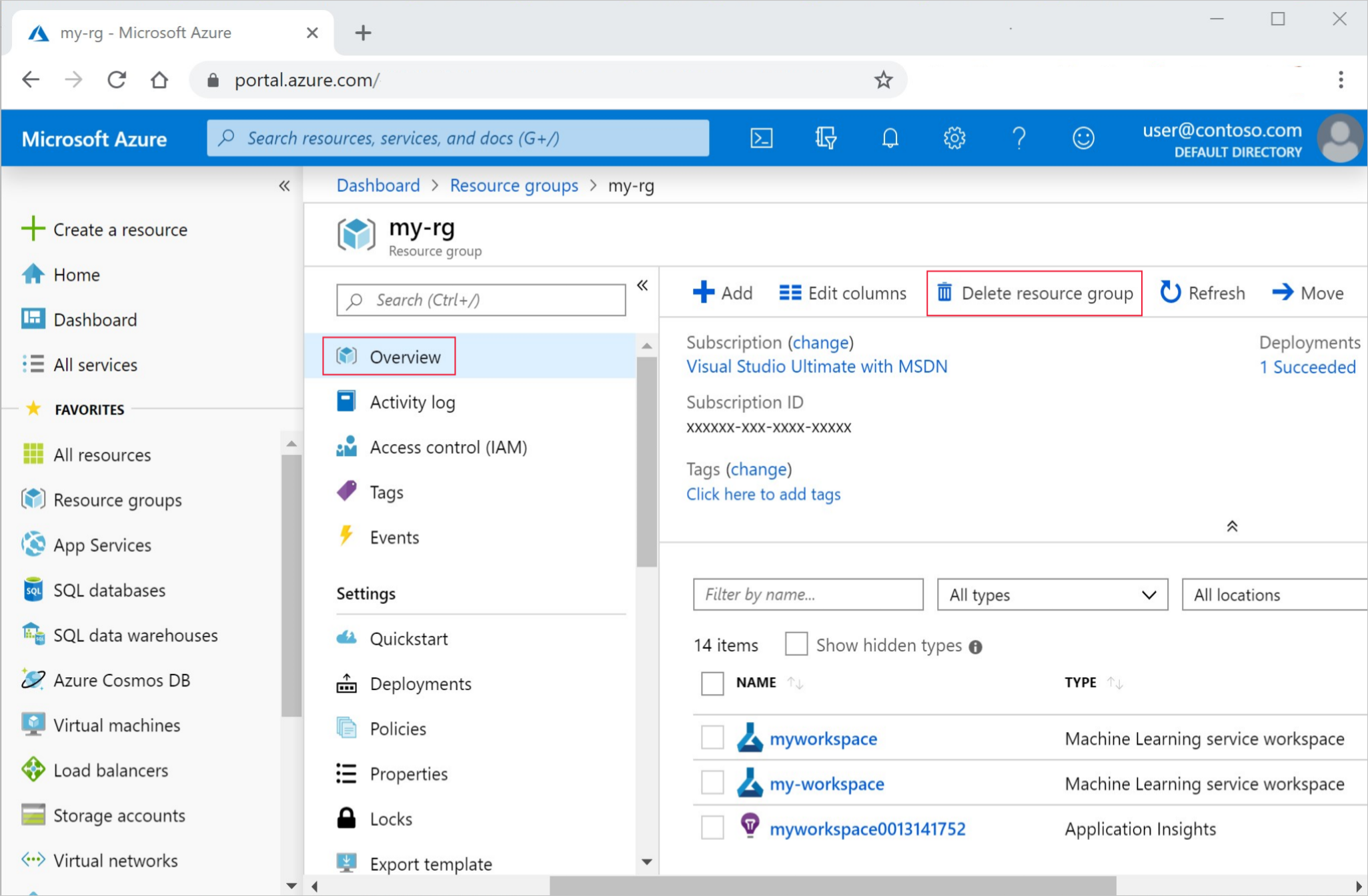
Adja meg az erőforráscsoport nevét. Ezután válassza a Törlés elemet.
Kapcsolódó tartalom
Tudnivalók a modell üzembe helyezéséről:
Modell üzembe helyezése.
Ez az oktatóanyag egy online adatfájlt használt. Az adatok elérésének egyéb módjairól a következő oktatóanyagban olvashat bővebben: Adatok feltöltése, elérése és feltárása az Azure Machine Learningben.
Az automatizált gépi tanulás egy kiegészítő eszköz, amely csökkenti az adatelemzők által az adataikkal legjobban működő modell megtalálásával töltött időt. További információ: Mi az automatizált gépi tanulás?
Ha az oktatóanyaghoz hasonló további példákat szeretne, tekintse meg a mintajegyzetfüzetekből való tanulást ismertető témakört. Ezek a minták a GitHub példák oldalán érhetők el. Ilyenek például a teljes Python-jegyzetfüzetek, amelyeket kód futtatásával és modell betanítása során ismerhet meg. A mintákból módosíthatja és futtathatja a meglévő szkripteket, beleértve a besorolást, a természetes nyelvi feldolgozást és az anomáliadetektálást.