Oktatóanyag: Adatok feltöltése, elérése és feltárása az Azure Machine Tanulás
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azure-ai-ml v2 (aktuális)
Python SDK azure-ai-ml v2 (aktuális)
Ezen oktatóanyag segítségével megtanulhatja a következőket:
- Adatok feltöltése felhőbeli tárolóba
- Azure Machine-Tanulás adategység létrehozása
- Adatok elérése jegyzetfüzetben interaktív fejlesztés céljából
- Adategységek új verzióinak létrehozása
A gépi tanulási projekt indítása általában magában foglalja a feltáró adatelemzést (EDA), az adat-előfeldolgozást (tisztítást, funkciófejlesztést), valamint a gépi Tanulás modell prototípusainak elkészítését a hipotézisek ellenőrzéséhez. Ez a prototípus-fejlesztési projektszakasz rendkívül interaktív. Lehetővé teszi, hogy egy IDE-ben vagy Jupyter-notebookban fejlôdjön egy Python interaktív konzollal. Ez az oktatóanyag ezeket az ötleteket ismerteti.
Ez a videó bemutatja, hogyan kezdheti el az Azure Machine Tanulás Studióban, hogy követni tudja az oktatóanyag lépéseit. A videó bemutatja, hogyan hozhat létre jegyzetfüzetet, klónozza a jegyzetfüzetet, hozhat létre számítási példányt, és töltheti le az oktatóanyaghoz szükséges adatokat. A lépéseket a következő szakaszokban is ismertetjük.
Előfeltételek
-
Az Azure Machine Tanulás használatához először munkaterületre lesz szüksége. Ha nem rendelkezik ilyen erőforrással, végezze el a munkaterület létrehozásához szükséges erőforrások létrehozását, és tudjon meg többet a használatáról.
-
Jelentkezzen be a stúdióba , és válassza ki a munkaterületet, ha még nincs megnyitva.
-
Jegyzetfüzet megnyitása vagy létrehozása a munkaterületen:
- Hozzon létre egy új jegyzetfüzetet, ha kódot szeretne másolni/beilleszteni a cellákba.
- Vagy nyisson meg oktatóanyagokat/get-started-notebooks/explore-data.ipynb-t a Studio Minták szakaszából. Ezután válassza a Klónozás lehetőséget a jegyzetfüzet fájlokhoz való hozzáadásához. (Lásd a minták helyét.)
A kernel beállítása
A megnyitott jegyzetfüzet fölötti felső sávon hozzon létre egy számítási példányt, ha még nem rendelkezik ilyenrel.

Ha a számítási példány le van állítva, válassza a Számítás indítása lehetőséget, és várja meg, amíg fut.

Győződjön meg arról, hogy a jobb felső sarokban található kernel az
Python 3.10 - SDK v2. Ha nem, a legördülő menüben válassza ki ezt a kernelt.
Ha megjelenik egy szalagcím, amely azt jelzi, hogy hitelesíteni kell, válassza a Hitelesítés lehetőséget.



Fontos
Az oktatóanyag többi része az oktatóanyag-jegyzetfüzet celláit tartalmazza. Másolja vagy illessze be őket az új jegyzetfüzetbe, vagy váltson most a jegyzetfüzetre, ha klónozta.
Az oktatóanyagban használt adatok letöltése
Az adatbetöltéshez az Azure Data Explorer ezekben a formátumokban kezeli a nyers adatokat. Ez az oktatóanyag ezt a CSV formátumú hitelkártya-ügyféladat-mintát használja. Egy Azure Machine Tanulás-erőforrás lépéseit láthatjuk. Ebben az erőforrásban létrehozunk egy helyi mappát a javasolt adatok nevével közvetlenül abban a mappában, amelyben a jegyzetfüzet található.
Feljegyzés
Ez az oktatóanyag az Azure Machine Tanulás erőforrásmappában elhelyezett adatoktól függ. Ebben az oktatóanyagban a "helyi" az Azure Machine Tanulás erőforrás mappájának helye.
A három pont alatt válassza a Terminál megnyitása lehetőséget, ahogyan az a képen látható:
A terminálablak egy új lapon nyílik meg.
Győződjön meg arról, hogy
cdugyanabba a mappába kerül, ahol a jegyzetfüzet található. Ha például a jegyzetfüzet egy get-started-notebooks nevű mappában van:cd get-started-notebooks # modify this to the path where your notebook is locatedAdja meg ezeket a parancsokat a terminálablakban az adatok számítási példányba másolásához:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvMost már bezárhatja a terminálablakot.
További információ ezekről az adatokról az UCI Machine Tanulás-adattárban.
Leíró létrehozása munkaterületre
Mielőtt belemerülnénk a kódba, szüksége lesz egy módszerre a munkaterületre való hivatkozáshoz. Létre fog hozni ml_client egy leírót a munkaterületen. Ezután ml_client erőforrásokat és feladatokat fog kezelni.
A következő cellában adja meg az előfizetés azonosítóját, az erőforráscsoport nevét és a munkaterület nevét. Az alábbi értékek megkeresése:
- A jobb felső Azure Machine Tanulás studio eszköztáron válassza ki a munkaterület nevét.
- Másolja a munkaterület, az erőforráscsoport és az előfizetés azonosítójának értékét a kódba.
- Ki kell másolnia egy értéket, be kell zárnia a területet és be kell illesztenie, majd vissza kell térnie a következőhöz.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Feljegyzés
Az MLClient létrehozása nem fog csatlakozni a munkaterülethez. Az ügyfél inicializálása lusta, az első alkalommal várakozik, amikor hívást kell kezdeményeznie (ez a következő kódcellában történik).
Adatok feltöltése felhőbeli tárolóba
Az Azure Machine Tanulás egységes erőforrás-azonosítókat (URI-kat) használ, amelyek a felhőbeli tárolóhelyekre mutatnak. Az URI megkönnyíti a jegyzetfüzetek és feladatok adatainak elérését. Az adat URI-formátumok a webböngészőben a weblapok eléréséhez használt webes URL-címekhez hasonlóak. Példa:
- Adatok elérése nyilvános https-kiszolgálóról:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Adatok elérése az Azure Data Lake Gen 2-ből:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Az Azure Machine Tanulás adategység hasonló a webböngésző könyvjelzőihez (kedvencekhez). A leggyakrabban használt adatokra mutató hosszú tárolási útvonalak (URI-k) megjegyzése helyett létrehozhat egy adategységet, majd egy rövid névvel elérheti az objektumot.
Az adategység létrehozása az adatforrás helyére mutató hivatkozást is létrehoz a metaadatok másolatával együtt. Mivel az adatok a meglévő helyen maradnak, nem jár többlet tárolási költséggel, és nem kockáztatja az adatforrás integritását. Adategységeket hozhat létre az Azure Machine Tanulás adattárakból, az Azure Storage-ból, a nyilvános URL-címekből és a helyi fájlokból.
Tipp.
Kisebb méretű adatfeltöltések esetén az Azure Machine Tanulás adategység létrehozása jól működik a helyi gép erőforrásaiból a felhőbeli tárolóba történő adatfeltöltésekhez. Ez a megközelítés elkerüli a további eszközök vagy segédprogramok szükségességét. A nagyobb méretű adatfeltöltéshez azonban szükség lehet egy dedikált eszközre vagy segédprogramra – például az azcopyra. Az azcopy parancssori eszköz áthelyezi az adatokat az Azure Storage-ba és onnan. Az azcopyról itt olvashat bővebben.
A következő jegyzetfüzetcella létrehozza az adategységet. A kódminta feltölti a nyers adatfájlt a kijelölt felhőtárhely-erőforrásba.
Minden alkalommal, amikor létrehoz egy adategységet, egyedi verzióra van szüksége. Ha a verzió már létezik, hibaüzenet jelenik meg. Ebben a kódban az adatok első olvasásához a "kezdeti" értéket használjuk. Ha ez a verzió már létezik, nem fogjuk újból létrehozni.
Kihagyhatja a verzióparamétert is, és a rendszer létrehoz egy verziószámot, amely 1-től kezdődik, majd onnan növekszik.
Ebben az oktatóanyagban a "initial" nevet használjuk első verzióként. Az éles gépi tanulási folyamatok létrehozása oktatóanyag az adatok ezen verzióját is használni fogja, ezért itt egy olyan értéket használunk, amelyet az oktatóanyagban újra látni fog.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
A feltöltött adatokat a bal oldali Adatok gombra kattintva tekintheti meg. Látni fogja, hogy az adatok feltöltődnek, és létrejön egy adategység:
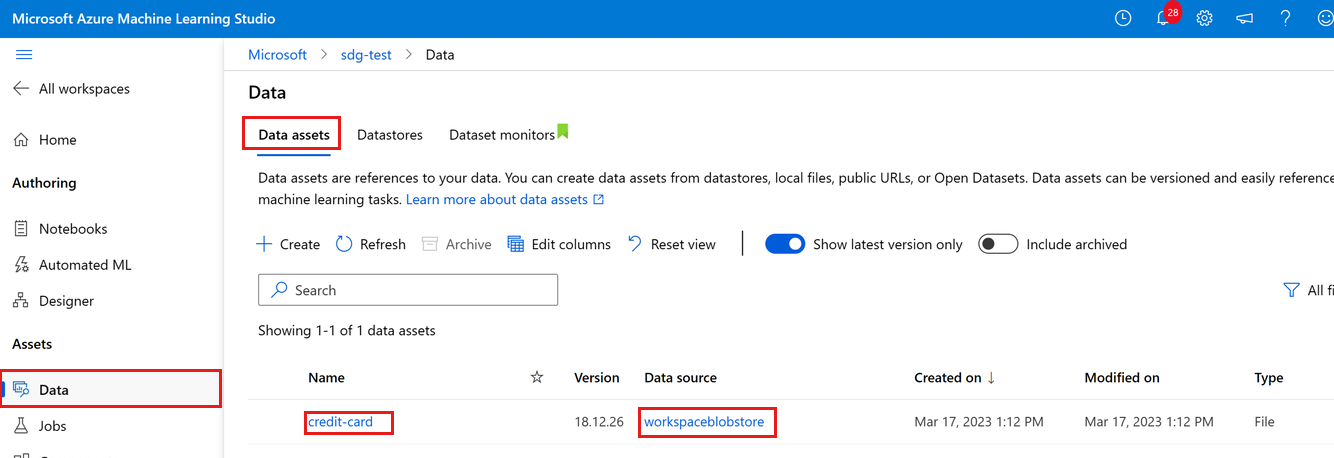
Ezeket az adatokat hitelkártyának nevezik, és az Adategységek lapon a Név oszlopban láthatjuk. Ezek az adatok feltöltve a munkaterület alapértelmezett, workspaceblobstore nevű adattárára, amely az Adatforrás oszlopban látható.
Az Azure Machine Tanulás-adattár az Azure-ban meglévő tárfiókra mutató hivatkozás. Az adattárak az alábbi előnyöket kínálják:
- Gyakori és könnyen használható API, amely különböző tárolási típusokkal (Blob/Files/Azure Data Lake Storage) és hitelesítési módszerekkel használható.
- A hasznos adattárak könnyebb felderítése csapatmunka közben.
- A szkriptekben elrejtheti a hitelesítő adatokhoz való hozzáférés kapcsolati adatait (szolgáltatásnév/SAS/kulcs).
Adatok elérése jegyzetfüzetben
A Pandas közvetlenül támogatja az URI-kat – ez a példa bemutatja, hogyan olvasható be CSV-fájl egy Azure Machine Tanulás Datastore-ból:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Azonban, ahogy korábban említettük, nehéz lehet megjegyezni ezeket az URI-kat. Emellett manuálisan kell helyettesítenie az pd.read_csv parancs összes <részszúrási> értékét az erőforrások valós értékeivel.
Adategységeket szeretne létrehozni a gyakran használt adatokhoz. Az alábbiakban egyszerűbben érheti el a CSV-fájlt a Pandasban:
Fontos
Egy jegyzetfüzetcellában hajtsa végre ezt a kódot a azureml-fsspec Python-kódtár Jupyter-kernelben való telepítéséhez:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Az Access-adatok azure cloud storage-ból való interaktív fejlesztése során történő olvasása további információt a jegyzetfüzetek adathozzáféréséről.
Az adategység új verziójának létrehozása
Lehet, hogy észrevette, hogy az adatok egy kis könnyű tisztítást igényelnek, hogy alkalmassá tegyék egy gépi tanulási modell betanítására. A következőt teszi:
- két fejléc
- ügyfél-azonosító oszlop; Ezt a funkciót nem használnánk a Machine Tanulás
- szóközök a válaszváltozó nevében
A CSV formátumhoz képest a Parquet fájlformátum is jobb módszer az adatok tárolására. A Parquet tömörítést biztosít, és séma fenntartására is használható. Ezért az adatok parquetben való tárolásához és tisztításához használja a következőt:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
Ez a táblázat az eredeti default_of_credit_card_clients.csv fájlban lévő adatok szerkezetét mutatja. Egy korábbi lépésben letöltött CSV-fájl. A feltöltött adatok 23 magyarázó változót és 1 válaszváltozót tartalmaznak, az itt látható módon:
| Oszlopnév(ek) | Változó típusa | Leírás |
|---|---|---|
| X1 | Magyarázó | Az adott hitel összege (NT dollár): magában foglalja mind az egyéni fogyasztói hitelt, mind a családi (kiegészítő) jóváírást. |
| X2 | Magyarázó | Nem (1 = férfi; 2 = nő). |
| X3 | Magyarázó | Oktatás (1 = végzős iskola; 2 = egyetem; 3 = gimnázium; 4 = egyéb). |
| X4 | Magyarázó | Családi állapot (1 = házas; 2 = egyedülálló; 3 = mások). |
| X5 | Magyarázó | Életkor (évek). |
| X6-X11 | Magyarázó | Korábbi fizetések előzményei. Nyomon követtük az elmúlt havi fizetési rekordokat (2005 áprilisától szeptemberig). -1 = megfelelő fizetés; 1 = fizetési késedelem egy hónapra; 2 = két hónapos fizetési késedelem; . . .; 8 = nyolc hónapos fizetési késedelem; 9 = 9 hónapos vagy újabb fizetési késedelem. |
| X12-17 | Magyarázó | A számlakivonat (NT-dollár) összege 2005 áprilisától szeptemberig. |
| X18-23 | Magyarázó | Az előző kifizetés (NT-dollár) összege 2005 áprilisától szeptemberig. |
| I | Válasz | Alapértelmezett fizetés (Igen = 1, Nem = 0) |
Ezután hozza létre az adategység új verzióját (az adatok automatikusan feltöltődnek a felhőbeli tárolóba). Ebben a verzióban egy időértéket adunk hozzá, így a kód minden futtatásakor egy másik verziószám jön létre.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
A megtisztított parkettafájl a legújabb verziójú adatforrás. Ez a kód először a CSV-verzió eredménykészletét, majd a Parquet-verziót jeleníti meg:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Az erőforrások eltávolítása
Ha most más oktatóanyagokra szeretne továbblépni, ugorjon a Következő lépésekre.
Számítási példány leállítása
Ha most nem fogja használni, állítsa le a számítási példányt:
- A stúdió bal oldali navigációs területén válassza a Számítás lehetőséget.
- A felső lapokban válassza a Számítási példányok lehetőséget
- Válassza ki a számítási példányt a listában.
- A felső eszköztáron válassza a Leállítás lehetőséget.
Az összes erőforrás törlése
Fontos
A létrehozott erőforrások előfeltételként használhatók más Azure Machine-Tanulás oktatóanyagokhoz és útmutatókhoz.
Ha nem tervezi használni a létrehozott erőforrások egyikét sem, törölje őket, hogy ne járjon költséggel:
Az Azure Portalon válassza az Erőforráscsoportok lehetőséget a bal szélen.
A listából válassza ki a létrehozott erőforráscsoportot.
Válassza az Erőforráscsoport törlése elemet.
Adja meg az erőforráscsoport nevét. Ezután válassza a Törlés elemet.
Következő lépések
Az adategységekkel kapcsolatos további információkért olvassa el az Adategységek létrehozása című cikket.
Az adattárak létrehozásával kapcsolatos további információkért olvassa el a Create datastores (Adattárak létrehozása) című cikket.
Folytassa az oktatóanyagokkal, és ismerje meg, hogyan fejleszthet betanítási szkriptet.