Azure Machine Learning-adatkészletek létrehozása Az Azure Open Datasetsből
Ebben a cikkben megtudhatja, hogyan hozhat létre válogatott bővítési adatokat a helyi vagy távoli gépi tanulási kísérletekbe az Azure Machine Learning-adatkészletekkel és az Azure Open Datasets szolgáltatással.
Egy Azure Machine Learning-adatkészlettel létrehozhat egy hivatkozást az adatforrás helyére, valamint a metaadatok másolatát. Mivel az adathalmazok lazán vannak kiértékelve, és mivel az adatok a meglévő helyen maradnak,
- Ne kockáztasson véletlenül módosításokat az eredeti adatforrások esetében
- Nincs extra tárolási költség
- Az ml-munkafolyamat teljesítményének javítása
Ha többet is tudnia kell arról, hogy az adathalmazok hol férnek el az Azure Machine Learning teljes adatelérési munkafolyamatában, tekintse meg a biztonságosan elérhető adatokról szóló cikket.
Az Azure Open Datasets olyan válogatott nyilvános adathalmazok, amelyek forgatókönyvspecifikus funkciókat adnak hozzá a prediktív megoldások gazdagítása és a megoldások pontosságának javítása érdekében. Keresse fel a nyilvános tartomány adatainak Open Datasets katalógus-erőforrását , amely segíthet a gépi tanulási modellek betanítása során– például:
- Egészség és genomika
- Munka és közgazdaságtan
- Népesség és biztonság
- Kiegészítő és gyakori adatkészletek
- Szállítás
A nyílt adathalmazokat a felhőben üzemeltetik a Microsoft Azure-ban. Az Azure Machine Learning Python SDK és az Azure Machine Learning Studio is tartalmazza őket.
Előfeltételek
A következők szükségesek:
Azure-előfizetés. Ha még nincs előfizetése, hozzon létre egy ingyenes fiókot, mielőtt hozzákezd. Próbálja ki az Azure Machine Learning ingyenes vagy fizetős verzióját.
Telepítette a Pythonhoz készült Azure Machine Learning SDK-t, amely tartalmazza a
azureml-datasetscsomagot.- Hozzon létre egy Azure Machine Learning számítási példányt – egy teljes körűen konfigurált és felügyelt fejlesztési környezetet, amely integrált jegyzetfüzeteket és már telepített SDK-t tartalmaz.
VAGY
Feljegyzés
Egyes adathalmazosztályok függőségekkel rendelkeznek az azureml-dataprep csomaghoz. Ez a csomag csak a 64 bites Pythonnal kompatibilis. Linux-felhasználók esetén ezek az osztályok csak az alábbi Linux-disztribúciókban támogatottak:
- Debian (8, 9)
- Fedora (27, 28)
- Red Hat Enterprise Linux (7, 8)
- Ubuntu (14.04, 16.04, 18.04)
Adatkészletek létrehozása az SDK-val
Azure Machine Learning-adathalmazok Azure Open Datasets-osztályokon keresztül történő létrehozásához a Python SDK-ban győződjön meg arról, hogy telepítette a csomagot pip install azureml-opendatasets. Az SDK-ban az egyes különálló adathalmazok osztálya ezt az osztályt jelöli, és egyes osztályok Azure Machine Learning-adattípusként FileDataset , Azure Machine Learning-adattípusként TabularDataset vagy mindkettőként érhetők el. Az osztályok teljes listáját a referenciadokumentációban opendatasets találja.
Bizonyos opendatasets osztályokat lekérhet erőforrásként vagy FileDataset erőforrásként.TabularDataset Ezután közvetlenül módosíthatja és/vagy letöltheti a fájlokat. Más osztályok csak a get_tabular_dataset() get_file_dataset() Python SDK osztályának vagy függvényeinek használatával tudják lekérni az Datasetadathalmazt.
Ez a kód azt mutatja, hogy az MNIST-osztály opendatasets egy TabularDataset vagy FileDataset:
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
Ebben a példában a Diabétesz opendatasets osztály csak TabularDataseta . Ehhez a következőt kell használni: get_tabular_dataset().
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
Adathalmazok regisztrálása
Regisztráljon egy Azure Machine Learning-adathalmazt a munkaterületén, így megoszthatja az adathalmazt másokkal, és újra felhasználhatja a munkaterületen végzett kísérletek során. Az Open Datasets szolgáltatásból létrehozott Azure Machine Learning-adatkészlet regisztrálásakor a rendszer nem tölt le azonnal adatokat, de az adatok később (például a betanítás során) elérhetővé válnak, amikor egy központi tárolóhelyről kérik őket.
Ha egy munkaterületen szeretné regisztrálni az adathalmazokat, használja a metódust register() .
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
Adathalmazok létrehozása a studióval
Azure Machine Learning-adatkészleteket is létrehozhat az Azure Open Datasetsből az Azure Machine Learning Studióval. Ez az összevont webes felület olyan gépi tanulási eszközöket tartalmaz, amelyek adatelemzési forgatókönyveket hajtanak végre az adatelemzési szakemberek számára minden készségszinten.
Feljegyzés
Az Azure Machine Learning Studióban létrehozott adathalmazok automatikusan regisztrálva lesznek a munkaterületen.
A munkaterületen válassza ki az Adatokat a bal oldali navigációs sávon. Az Adategységek lapon válassza a Létrehozás lehetőséget, ahogyan a képernyőképen látható:

A következő képernyőn adjon hozzá egy nevet és egy opcionális leírást az új adategységhez. Ezután válassza a Táblázat lehetőséget a Típus legördülő listában, ahogyan az a képernyőképen látható:

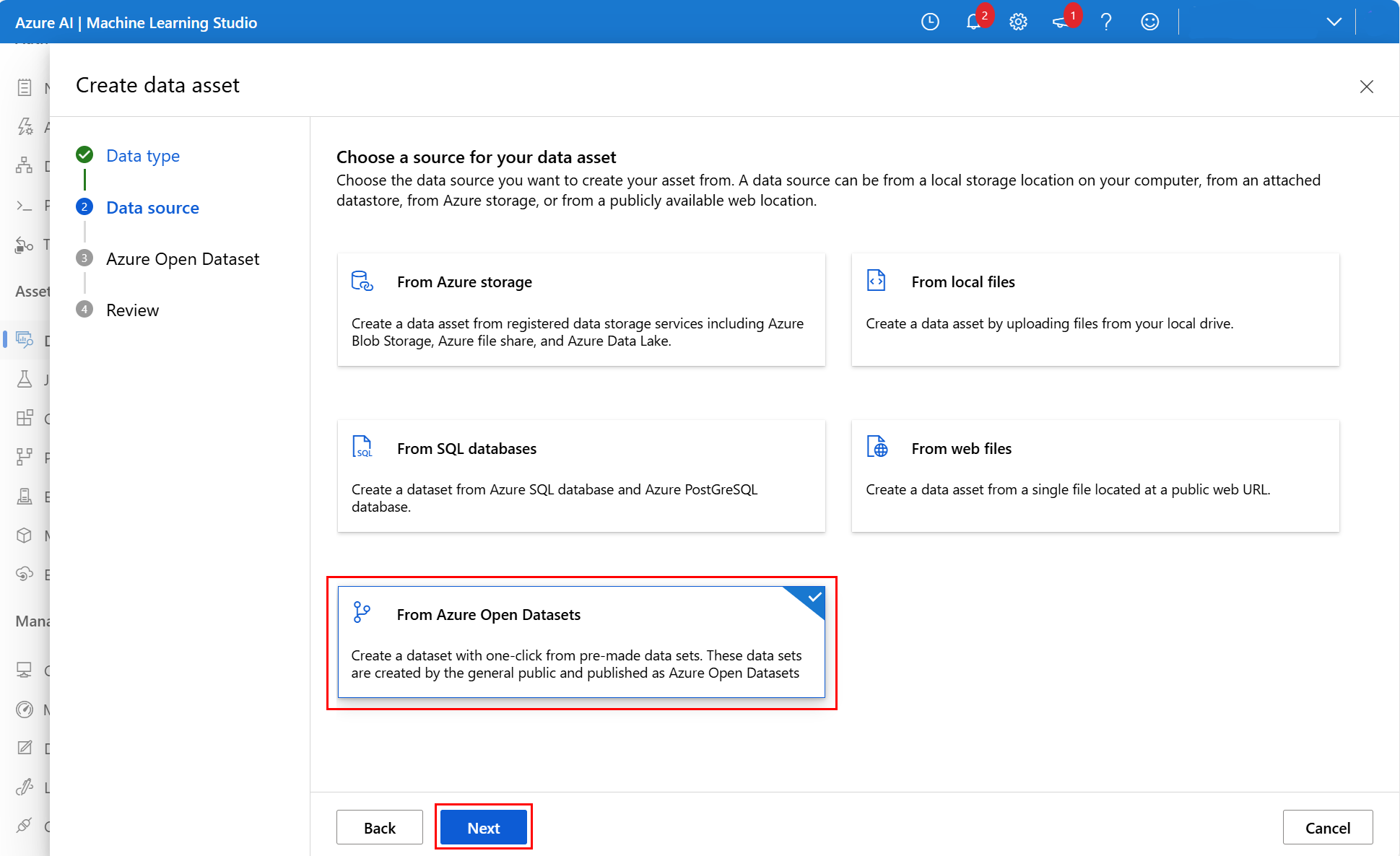
A következő képernyőn válassza az Azure Open Datasets lehetőséget, majd válassza a Tovább gombot, ahogyan az a képernyőképen látható:
A következő képernyőn válasszon ki egy elérhető Azure Open Datasetet. Ebben a képernyőképen a San Francisco Safety Datasetet választottuk ki:

Ha szükséges, görgessen lefelé, és válassza a Tovább gombot, ahogy a képernyőképen látható:

Ha szeretné, szűrje az adatokat a kiválasztott adatkészletnek megfelelő elérhető szűrőkkel. A San Francisco Safety Dataset esetében a szűrt dátumtartományt 2024. július 1. és 2024. július 17. közötti kezdő dátum között állítjuk be. Válassza a Tovább lehetőséget a képernyőképen látható módon:

A következő képernyőn tekintse át az új adategység beállításait, és végezze el a szükséges módosításokat. Ha jónak tűnik, válassza a Létrehozás lehetőséget a képernyőképen látható módon:

A San Francisco Safety Dataset mezőleírásairól és dátumtartományairól a San Francisco Safety Data erőforrásban talál további információt. A többi adatkészletről további információt az Azure Open Datasets Catalog erőforrásában talál.







Az adatkészlet mostantól elérhető a munkaterületen az Adathalmazok területen. Ugyanúgy használhatja, mint a többi létrehozott adathalmazt.
Adathalmazok elérése a kísérletekhez
Az adathalmazokat gépi tanulási kísérletekben használhatja az ML-modellek betanításához. További információt az adatkészletek betanítása című témakörben talál.
Példajegyzetfüzetek
Az Open Datasets funkcióinak példáihoz és bemutatóihoz tekintse át ezeket a mintajegyzetfüzeteket.
Következő lépések
- Az első ml-modell betanítása.
- Betanítása adatkészletekkel.
- Azure Machine Learning-adatkészlet létrehozása.