REST-oktatóanyag: Kereshető tartalom létrehozása az Azure AI Searchben képességkészletek használatával
Ebben az oktatóanyagban megtudhatja, hogyan hívhatja meg azokat a REST API-kat, amelyek tartalomkinyeréshez és átalakításokhoz létrehoznak egy MI-bővítési folyamatot az indexelés során.
A képességkészletek AI-feldolgozást adnak a nyers tartalomhoz, így egységesebbé és kereshetőbbé teszik a tartalmat. Ha már tudja, hogyan működnek a készségkészletek, számos átalakítást támogathat: a képelemzéstől a természetes nyelvi feldolgozáson át a külsőleg biztosított testre szabott feldolgozásig.
Ez az oktatóanyag a következőket ismerteti:
- Objektumok definiálása bővítési folyamatban.
- Képességkészlet létrehozása. OcR meghívása, nyelvfelismerés, entitásfelismerés és kulcskifejezés-kinyerés.
- Hajtsa végre a folyamatot. Keresési index létrehozása és betöltése.
- Ellenőrizze az eredményeket teljes szöveges kereséssel.
Ha nem rendelkezik Azure-előfizetéssel, a kezdés előtt nyisson meg egy ingyenes fiókot .
Áttekintés
Ez az oktatóanyag egy REST-ügyfelet és az Azure AI Search REST API-kat használ egy adatforrás, indexelő, indexelő és képességkészlet létrehozásához.
Az indexelő a folyamat minden lépését vezérli, kezdve a mintaadatok (strukturálatlan szöveg és képek) tartalomkinyerésével egy Azure Storage-blobtárolóban.
A tartalom kinyerése után a képességkészlet beépített képességeket hajt végre a Microsofttól az információk megkereséséhez és kinyeréséhez. Ezek a képességek közé tartozik a képek optikai karakterfelismerése (OCR), a szöveg nyelvfelismerése, a kulcskifejezések kinyerése és az entitásfelismerés (szervezetek). A képességkészlet által létrehozott új információk egy index mezőibe kerülnek. Az index feltöltése után használhatja a lekérdezések, aspektusok és szűrők mezőit.
Előfeltételek
Visual Studio Code REST-ügyféllel
Feljegyzés
Ehhez az oktatóanyaghoz ingyenes keresési szolgáltatást használhat. Az ingyenes szint három indexre, három indexelőre és három adatforrásra korlátozza. Az oktatóanyagban mindegyikből egyet hozhat majd létre. Mielőtt hozzákezdene, győződjön meg arról, hogy van helye a szolgáltatásban az új erőforrások elfogadásához.
Fájlok letöltése
Töltse le a mintaadattár zip-fájlját, és bontsa ki a tartalmat. További tudnivalókat itt talál.
Mintaadatok feltöltése az Azure Storage-ba
Az Azure Storage-ban hozzon létre egy új tárolót, és nevezze el cog-search-demo néven.
Szerezze be a tárolási kapcsolati sztring, hogy kapcsolatot alakíthass ki az Azure AI Searchben.
A bal oldalon válassza az Access-kulcsokat.
Másolja a kapcsolati sztring az első vagy a második kulcshoz. A kapcsolati sztring a következő példához hasonló:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure AI services
A beépített AI-bővítést az Azure AI-szolgáltatások támogatják, beleértve a language szolgáltatást és az Azure AI Visionet a természetes nyelv és a képfeldolgozás érdekében. Az oktatóanyaghoz hasonló kis számítási feladatok esetében indexelőnként húsz tranzakció ingyenes lefoglalását használhatja. Nagyobb számítási feladatok esetén csatoljon egy Többrégiós Azure AI Services-erőforrást egy használatalapú fizetéses díjszabást nyújtó készségkészlethez .
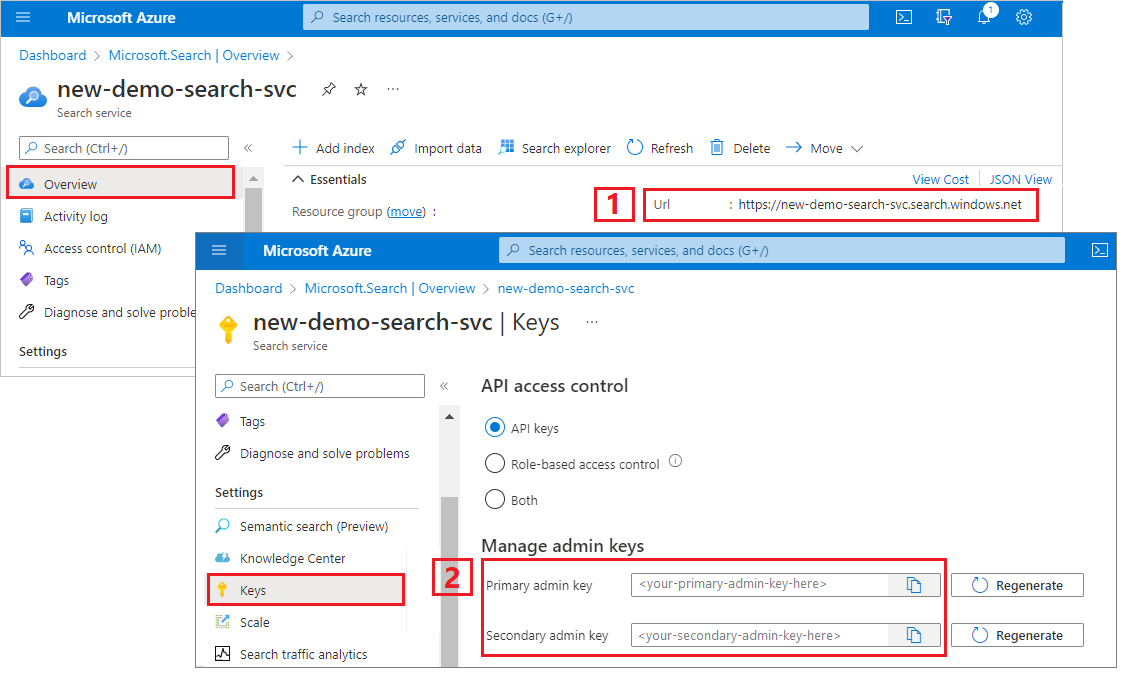
Keresési szolgáltatás URL-címének és API-kulcsának másolása
Ebben az oktatóanyagban az Azure AI Searchhez való csatlakozáshoz végpontra és API-kulcsra van szükség. Ezeket az értékeket az Azure Portalon szerezheti be.
Jelentkezzen be az Azure Portalra, lépjen a keresési szolgáltatás áttekintési oldalára, és másolja az URL-címet. A végpontok például a következőképpen nézhetnek ki:
https://mydemo.search.windows.net.A Beállítások>kulcsok területen másolja ki a rendszergazdai kulcsot. A rendszergazdai kulcsok objektumok hozzáadására, módosítására és törlésére szolgálnak. Két felcserélhető rendszergazdai kulcs van. Másolja valamelyiket.
A REST-fájl beállítása
Indítsa el a Visual Studio Code-ot, és nyissa meg a skillset-tutorial.rest fájlt. Lásd : Rövid útmutató: Szövegkeresés REST használatával, ha segítségre van szüksége a REST-ügyféllel kapcsolatban.
Adja meg a változók értékeit: keresési szolgáltatásvégpont, keresési szolgáltatás rendszergazdai API-kulcsa, indexnév, az Azure Storage-fiókhoz kapcsolati sztring és a blobtároló neve.
A folyamat létrehozása
Az AI-bővítés indexelőalapú. Az útmutató ezen része négy objektumot hoz létre: adatforrást, indexdefiníciót, képességkészletet, indexelőt.
1. lépés: Adatforrás létrehozása
Az adatforrás létrehozása meghívásával állítsa a kapcsolati sztring a mintaadatfájlokat tartalmazó Blob-tárolóra.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
2. lépés: Képességkészlet létrehozása
Hívja meg a Képességcsoport létrehozása elemet , és adja meg, hogy mely bővítési lépéseket alkalmazza a rendszer a tartalomra. A készségek párhuzamosan futnak, hacsak nincs függőség.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Főbb pontok:
A kérelem törzse a következő beépített képességeket határozza meg:
Készség Leírás Optikai karakterfelismerés Felismeri a képfájlokban lévő szöveget és számokat. Szövegegyesítés Olyan "egyesített tartalmat" hoz létre, amely újrakombinálja a korábban elválasztott tartalmakat, amely beágyazott képekkel (PDF, DOCX stb.) rendelkező dokumentumokhoz használható. A képeket és a szöveget a dokumentumtörési fázis során választja el egymástól. Az egyesítési képesség újrakombinálja őket úgy, hogy beszúr minden felismert szöveget, képfeliratot vagy címkét, amelyet a bővítés során hoztak létre abba a helyre, ahonnan a képet kinyerték a dokumentumban. Ha egyesített tartalommal dolgozik egy készségkészletben, ez a csomópont magában foglalja a dokumentum összes szövegét, beleértve azokat a csak szöveges dokumentumokat is, amelyek soha nem vesznek részt ocR-on vagy képelemzésen. Nyelvfelismerés Felismeri a nyelvet, és nyelvi nevet vagy kódot ad ki. A többnyelvű adathalmazokban a nyelvi mezők hasznosak lehetnek a szűrőkhöz. Entitásfelismerés Kinyeri a személyek, szervezetek és helyek nevét az egyesített tartalmakból. Szöveg felosztása A kulcskifejezés-kinyerési képesség meghívása előtt a nagy egyesített tartalmat kisebb adattömbökre bontja. A kulcskifejezések kinyerése legfeljebb 50 000 karakter méterű bemeneteket fogad el. A mintafájlok közül néhányat fel kell osztani ahhoz, hogy beleférjen a korlátozásba. Kulcskifejezések kinyerése Lekéri a legfontosabb kulcskifejezéseket. Minden képesség a dokumentum tartalmán fut le. A feldolgozás során az Azure AI Search feltöri az egyes dokumentumokat a különböző fájlformátumokból származó tartalmak olvasásához. A forrásfájlban talált szöveg a létrehozott
contentmezőbe kerül, amelyből dokumentumonként egy jön létre. Így a bemenet a következő lesz"/document/content": .A kulcskifejezések kinyeréséhez, mivel a szövegfelosztó képesség használatával nagyobb fájlokat bontunk oldalakra, a kulcskifejezés-kinyerési képesség
"document/pages/*"környezete (a dokumentum minden oldalához) ahelyett"/document/content", hogy a szövegfelbontást használnánk.
Feljegyzés
A kimenetek hozzárendelhetők egy indexhez, bemenetként használhatók egy alsóbb rétegbeli képességhez, vagy a fentiek mindegyike lehetséges, akárcsak a nyelvkód esetében. Az indexben a nyelvkód a szűréskor lehet hasznos. A képességcsoportok alapvető tudnivalóval kapcsolatos bővebb információkért lásd: Képességcsoport megadása.
3. lépés: Index létrehozása
Hívja meg az Index létrehozása parancsot az invertált indexek és egyéb szerkezetek Azure AI Searchben való létrehozásához használt séma megadásához.
Az index legnagyobb összetevője a mezők gyűjteménye, ahol az adattípus és az attribútumok határozzák meg a tartalmat és a viselkedést az Azure AI Searchben. Győződjön meg arról, hogy rendelkezik mezőkkel az újonnan létrehozott kimenethez.
### Create an index
POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
4. lépés: Indexelő létrehozása és futtatása
Hívja meg az Indexelő létrehozása parancsot a folyamat vezetéséhez. Az eddig létrehozott három összetevő (adatforrás, képességkészlet, index) egy indexelő bemenete. Az indexelő létrehozása az Azure AI Searchben az az esemény, amely a teljes folyamatot mozgásba hozza.
A lépés utasításainak végrehajtása több percig is eltarthat. Annak ellenére, hogy az adatkészlet kis méretű, az analitikai képességek számítási igénye nagy.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Főbb pontok:
A kérelem törzse az előző objektumokra mutató hivatkozásokat, a képfeldolgozáshoz szükséges konfigurációs tulajdonságokat és két típusú mezőleképezést tartalmaz.
"fieldMappings"a képességkészlet előtt feldolgozzák, és tartalmat küldenek az adatforrásból az index célmezőinek. A mezőleképezésekkel meglévő, nem módosított tartalmat küldhet az indexnek. Ha a mezőnevek és a típusok mindkét végén megegyeznek, nincs szükség leképezésre."outputFieldMappings"a készségek által létrehozott mezőkre, a képességkészlet végrehajtása után. A hivatkozásoksourceFieldNamenem léteznek,outputFieldMappingsamíg a dokumentumok feltörése vagy bővítése nem hozza létre őket. AztargetFieldNameindex egy olyan mezője, amely az indexsémában van definiálva.A
"maxFailedItems"paraméter -1 értékre van állítva, amely arra utasítja az indexelő motort, hogy hagyja figyelmen kívül az adatimportálás során előforduló hibákat. Ez elfogadható, mert olyan kevés dokumentum található a bemutató adatforrásban. Nagyobb méretű adatforrás esetén 0-nál nagyobb értéket kell megadnia.Az
"dataToExtract":"contentAndMetadata"utasítás arra utasítja az indexelőt, hogy automatikusan kinyerje az értékeket a blob tartalomtulajdonságából és az egyes objektumok metaadataiból.A
imageActionparaméter arra utasítja az indexelőt, hogy az adatforrásban található képekből nyerjen ki szöveget. A"imageAction":"generateNormalizedImages"konfiguráció az OCR-képesség és a szövegegyesítési képesség együttes használatával arra utasítja az indexelőt, hogy bontsa ki a képekből a szöveget (például a "stop" szót egy forgalmi stop jelből), és ágyazza be a tartalommezőbe. Ez a viselkedés a beágyazott képekre (a PDF-fájlban lévő képre) és az önálló képfájlokra, például egy JPG-fájlra is vonatkozik.
Feljegyzés
Az indexelő létrehozása elindítja a folyamatot. Ha probléma lép fel az adatok elérésével, a bemenetek és kimenetek leképezésével vagy a műveletek sorrendjével kapcsolatban, az ebben a szakaszban jelenik meg. Ha kód- vagy szkriptmódosításokkal szeretné újra futtatni a folyamatot, lehetséges, hogy először el kell távolítania az objektumokat. További információk: Alaphelyzetbe állítás és ismételt futtatás.
Indexelés figyelése
Az indexelés és a bővítés az Indexelő létrehozása kérelem elküldése után azonnal megkezdődik. A képességkészlet összetettségétől és műveleteitől függően az indexelés eltarthat egy ideig.
Annak megállapításához, hogy az indexelő továbbra is fut-e, hívja meg az Indexelő állapotának lekérését az indexelő állapotának ellenőrzéséhez.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Főbb pontok:
Egyes helyzetekben gyakoriak a figyelmeztetések, és nem mindig jeleznek problémát. Ha például egy blobtároló képfájlokat tartalmaz, és a folyamat nem kezeli a képeket, figyelmeztetés jelenik meg arról, hogy a rendszerképek nem lettek feldolgozva.
Ebben a mintában van egy PNG-fájl, amely nem tartalmaz szöveget. A szövegalapú készségek (nyelvfelismerés, helyek, szervezetek, személyek és kulcskifejezések kinyerése) mind az öt művelete nem fut ezen a fájlon. Az eredményként kapott értesítés megjelenik a végrehajtási előzményekben.
Eredmények ellenőrzése
Most, hogy létrehozott egy AI által létrehozott tartalmat tartalmazó indexet, hívja meg a keresési dokumentumokat , hogy futtasson néhány lekérdezést az eredmények megtekintéséhez.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
A szűrők segíthetnek a találatok érdekes elemekre való szűkítésében:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Ezek a lekérdezések az Azure AI Search által létrehozott új mezők lekérdezési szintaxisának és szűrőinek néhány módját szemléltetik. További lekérdezési példákért lásd : Példák a Keresési dokumentumok REST API-ban, egyszerű szintaxisú lekérdezési példák és teljes Lucene-lekérdezési példák.
Alaphelyzetbe állítás és ismételt futtatás
A fejlesztés korai szakaszaiban gyakori az iteráció a tervezés során. Az alaphelyzetbe állítás és az újrafuttatás segít az iterációban.
Legfontosabb ismeretek
Ez az oktatóanyag bemutatja azokat az alapvető lépéseket, amelyek alapján a REST API-k segítségével migrálási folyamatot hozhat létre: adatforrást, képességkészletet, indexet és indexelőt.
Bevezették a beépített készségeket , valamint a készségek definícióját, amely bemutatja a készségek összeláncolásának mechanikát bemeneteken és kimeneteken keresztül. Azt is megtudhatta, hogy az indexelő definíciója szükséges ahhoz, hogy outputFieldMappings a gazdagított értékeket a folyamatból egy kereshető indexbe irányítsa egy Azure AI-Search szolgáltatás.
Végül megismerte, hogyan tesztelheti az eredményeket, és hogyan állíthatja alaphelyzetbe a rendszert a későbbi futtatásokhoz. Megtanulta, hogy ha lekérdezéseket futtat az indexen, az a bővített indexelési folyamat által létrehozott kimenetet adja vissza.
Az erőforrások eltávolítása
Ha a saját előfizetésében dolgozik, a projekt végén célszerű eltávolítania a már nem szükséges erőforrásokat. A továbbra is futó erőforrások költségekkel járhatnak. Az erőforrásokat törölheti egyesével, vagy az erőforráscsoport törlésével eltávolíthatja a benne lévő összes erőforrást is.
A portálon a bal oldali navigációs panel Minden erőforrás vagy Erőforráscsoport hivatkozásával kereshet és kezelhet erőforrásokat.
Következő lépések
Most, hogy már ismeri az AI-bővítési folyamat összes objektumát, tekintse meg közelebbről a képességkészlet-definíciókat és az egyéni képességeket.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: