Indexelők az Azure AI Searchben
Az Azure AI Search egyik indexelője egy olyan keresőrobot, amely szöveges adatokat nyer ki a felhőbeli adatforrásokból, és a forrásadatok és a keresési indexek közötti mezők közötti leképezések használatával tölti fel a keresési indexet. Ezt a megközelítést néha "lekéréses modellnek" is nevezik, mert a keresési szolgáltatás adatokat kér le anélkül, hogy bármilyen olyan kódot kellene írnia, amely adatokat ad hozzá egy indexhez.
Az indexelők emellett a képességkészletek végrehajtását és az AI-bővítést is fejlesztik, ahol konfigurálhatja a képességeket a tartalom további feldolgozásának integrálásához az indexhez vezető útvonalon. Néhány példa: OCR képfájlokra, szövegfelosztási képesség adattömbökhöz, szövegfordítás több nyelvre.
Az indexelők támogatott adatforrásokat céloznak meg. Az indexelő konfigurációja egy adatforrást (forrást) és egy keresési indexet (célhelyet) határoz meg. Számos forrás, például az Azure Blob Storage több, az adott tartalomtípusra jellemző konfigurációs tulajdonsággal rendelkezik.
Az indexelőket igény szerint vagy ismétlődő adatfrissítési ütemezéssel is futtathatja, amely öt percenként fut. A gyakoribb frissítésekhez leküldéses modellre van szükség, amely egyidejűleg frissíti az adatokat az Azure AI Searchben és a külső adatforrásban is.
A keresési szolgáltatás keresési egységenként egy indexelő feladatot futtat. Ha egyidejű feldolgozásra van szüksége, győződjön meg arról, hogy rendelkezik elegendő replikával. Az indexelők nem futnak a háttérben, ezért a szokásosnál több lekérdezésszabályozást észlelhet, ha a szolgáltatás nyomás alatt áll.
Indexelő forgatókönyvek és használati esetek
Az indexelőt használhatja egyetlen adatbetöltési eszközként, vagy más technikákkal kombinálva. Az alábbi táblázat a fő forgatókönyveket foglalja össze.
| Eset | Stratégia |
|---|---|
| Egyetlen adatforrás | Ez a minta a legegyszerűbb: egy adatforrás a keresési index egyetlen tartalomszolgáltatója. A legtöbb támogatott adatforrás valamilyen változásészlelést biztosít, így az indexelő későbbi futtatásai felveszik a különbséget, amikor tartalmat adnak hozzá vagy frissítenek a forrásban. |
| Több adatforrás | Az indexelők specifikációinak csak egy adatforrása lehet, de maga a keresési index több forrásból származó tartalmat is elfogadhat, ahol az egyes indexelők egy másik adatszolgáltatótól származó új tartalmat hoznak létre. Minden forrás hozzájárulhat a teljes dokumentumok megosztásához, vagy feltöltheti az egyes dokumentumok kijelölt mezőit. A forgatókönyv részletesebb megtekintéséhez tekintse meg az oktatóanyagot: Indexelés több adatforrásból. |
| Több indexelő | A rendszer általában több adatforrást párosít több indexelővel, ha a futtatási idő paramétereit, az ütemezést vagy a mezőleképezéseket módosítania kell. Az Azure AI Search régióközi felskálázása egy másik forgatókönyv. Előfordulhat, hogy ugyanannak a keresési indexnek a másolatai különböző régiókban vannak. A keresési index tartalmának szinkronizálásához több indexelő is lekérte ugyanabból az adatforrásból, ahol minden indexelő egy másik keresési indexet céloz meg az egyes régiókban. A nagyon nagy adathalmazok párhuzamos indexeléséhez több indexelő stratégia is szükséges, ahol minden indexelő az adatok egy részhalmazát célozza meg. |
| Tartalomátalakítás | Az indexelők a képességkészletek végrehajtását és az AI-bővítést hajtják végre. A tartalomátalakítások az indexelőhöz csatolt készségkészletben vannak definiálva. Az adattömb-készítést és a vektorizálást a készségek segítségével is beépítheti. |
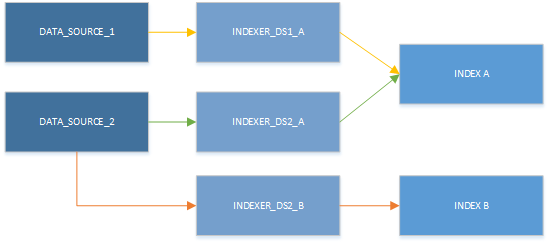
Minden célindexhez és adatforrás-kombinációhoz létre kell hoznia egy indexelőt. Több indexelő is írhat ugyanabba az indexbe, és ugyanazt az adatforrást több indexelőhöz is felhasználhatja. Az indexelők azonban egyszerre csak egy adatforrást használhatnak, és csak egyetlen indexbe írhatnak. Az alábbi ábrán látható, hogy egy adatforrás bemenetet biztosít egy indexelőhöz, amely ezután feltölt egy indexet:

Bár egyszerre csak egy indexelőt használhat, az erőforrások különböző kombinációkban használhatók. A következő ábrán az látható, hogy egy adatforrás több indexelővel is párosítható, és több indexelő is írhat ugyanahhoz az indexhez.
Támogatott adatforrások
Az indexelők az Azure-ban és az Azure-on kívül is bejárják az adattárakat.
- Azure Blob Storage
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Azure SQL Database
- Azure Table Storage
- Felügyelt Azure SQL-példány
- SQL Server az Azure Virtual Machines szolgáltatásban
- Azure Files (előzetes verzióban)
- Azure MySQL (előzetes verzióban)
- SharePoint a Microsoft 365-ben (előzetes verzióban)
- MongoDB-hez készült Azure Cosmos DB (előzetes verzió)
- Azure Cosmos DB for Apache Gremlin (előzetes verzió)
Az Azure Cosmos DB for Cassandra nem támogatott.
Az indexelők elfogadják az egybesimított sorkészleteket, például egy táblázatot vagy nézetet, illetve egy tárolóban vagy mappában lévő elemeket. A legtöbb esetben soronként, rekordonként vagy elemenként egy keresési dokumentumot hoz létre.
A távoli adatforrásokhoz való indexelő kapcsolatok szabványos (nyilvános) vagy titkosított privát kapcsolatok használatával hozhatók létre megosztott privát kapcsolat használata esetén. A kapcsolatok úgy is beállíthatók, hogy felügyelt identitással hitelesítsék magukat. A biztonságos kapcsolatokról további információt az Indexelő az Azure hálózati biztonsági funkciói által védett tartalmakhoz való hozzáférésről és a felügyelt identitással rendelkező adatforráshoz való csatlakozásról talál.
Az indexelés szakaszai
Kezdeti futtatáskor, amikor az index üres, az indexelő beolvassa a táblában vagy tárolóban megadott összes adatot. A későbbi futtatások során az indexelő általában csak a megváltozott adatokat képes észlelni és lekérni. Blobadatok esetén a változásészlelés automatikus. Más adatforrások, például az Azure SQL vagy az Azure Cosmos DB esetében engedélyezni kell a változásészlelést.
Minden kapott dokumentum esetében az indexelő több lépést valósít meg vagy koordinál, a dokumentumlekéréstől kezdve az indexelés végső keresőmotorján át az "átadásig". Opcionálisan az indexelő a képességkészletek végrehajtását és kimeneteit is vezérli, feltéve, hogy egy képességkészlet definiálva van.

1. szakasz: Dokumentumrepedés
A dokumentumok feltörése a fájlok megnyitásának és a tartalom kinyerésének folyamata. A szöveges tartalom kinyerhető egy szolgáltatás fájljaiból, egy tábla soraiból, illetve a tároló vagy gyűjtemény elemeiből. Ha képességkészletet és képi készségeket ad hozzá, a dokumentummegrepedés képeket is kinyerhet, és képfeldolgozás céljából várólistára helyezheti őket.
Az adatforrástól függően az indexelő különböző műveleteket próbál ki a potenciálisan indexelhető tartalom kinyeréséhez:
Ha a dokumentum beágyazott képekkel (például PDF) rendelkező fájl, az indexelő kinyeri a szöveget, a képeket és a metaadatokat. Az indexelők megnyithatnak fájlokat az Azure Blob Storage-ból, az Azure Data Lake Storage Gen2-ből és a SharePointból.
Ha a dokumentum egy rekord az Azure SQL-ben, az indexelő nem bináris tartalmat nyer ki az egyes rekordok egyes mezőiből.
Ha a dokumentum egy rekord az Azure Cosmos DB-ben, az indexelő nem bináris tartalmat nyer ki az Azure Cosmos DB-dokumentum mezőiből és almezőiből.
2. szakasz: Mezőleképezések
Az indexelő kinyeri a szöveget egy forrásmezőből, és elküldi azt egy index vagy tudástár célmezőjére. Ha a mezőnevek és az adattípusok egybeesnek, az elérési út egyértelmű. Előfordulhat azonban, hogy különböző neveket vagy típusokat szeretne a kimenetben, ebben az esetben meg kell mondania az indexelőnek, hogyan képezze le a mezőt.
Mezőleképezések megadásához adja meg a forrás- és célmezőket az indexelő definíciójában.
A mezőleképezés a dokumentumok feltörése után, de az átalakítások előtt történik, amikor az indexelő a forrásdokumentumokból olvas. Mezőleképezés definiálásakor a forrásmező értéke módosítás nélkül lesz elküldve a célmezőbe.
3. szakasz: Készségkészlet végrehajtása
A készségkészlet végrehajtása nem kötelező lépés, amely meghívja a beépített vagy egyéni AI-feldolgozást. A képességkészletek optikai karakterfelismerést (OCR) vagy más képelemzési formákat adhatnak hozzá, ha a tartalom bináris. A készségkészletek természetes nyelvi feldolgozást is hozzáadhatnak. Hozzáadhat például szövegfordítást vagy kulcskifejezés-kinyeréseket.
Bármi legyen is az átalakítás, a képességkészlet-végrehajtás az, ahol a bővítés történik. Ha egy indexelő egy folyamat, akkor a képességkészletet "folyamatként" tekintheti a folyamaton belül.
4. szakasz: Kimeneti mezőleképezések
Ha tartalmaz egy készségkészletet, meg kell adnia a kimeneti mezőleképezéseket az indexelő definíciójában. A készségkészlet kimenete belsőleg egy bővített dokumentumnak nevezett faszerkezetként nyilvánul meg. A kimeneti mezőleképezésekkel kiválaszthatja, hogy a fa mely részeit képezze le az index mezőibe.
A nevek hasonlósága ellenére a kimeneti mezőleképezések és a mezőleképezések társításokat építenek ki különböző forrásokból. A mezőleképezések a forrásmező tartalmát a keresési index célmezőihez társítják. A kimeneti mezőleképezések egy belső bővített dokumentum tartalmát (képességkimeneteket) társítják az index célmezőihez. A nem kötelezőnek ítélt mezőleképezésekkel ellentétben a kimeneti mezőleképezés szükséges minden olyan átalakított tartalomhoz, amelynek az indexben kell lennie.
A következő képen az indexelő szakaszainak hibakeresési munkamenet-ábrázolása látható: dokumentumreplikáció, mezőleképezések, képességkészlet-végrehajtás és kimeneti mezőleképezések.

Alapvető munkafolyamat
Az indexelők az adott adatforrások esetében egyedi funkciókat biztosítanak. Ezért az indexelő- vagy az adatforrás-konfiguráció egyes szempontjai az indexelő típusától függően változnak. Az alapvető felépítés és követelmények azonban minden indexelő esetében azonosak. Az alábbiakban az összes indexelőre érvényes lépések láthatóak.
1. lépés: Adatforrás létrehozása
Az indexelőknek olyan adatforrás-objektumra van szükségük, amely kapcsolati sztring és esetleg hitelesítő adatokat biztosít. Az adatforrások független objektumok. Egyszerre több indexelő is használhatja ugyanazt az adatforrás-objektumot több index betöltéséhez.
Adatforrást az alábbi módszerek bármelyikével hozhat létre:
- Az Azure Portalon a keresési szolgáltatás lapJának Adatforrások lapján válassza az Adatforrás hozzáadása lehetőséget az adatforrás definíciójának megadásához.
- Az Azure Portal használatával az Adatok importálása varázsló egy adatforrást ad ki.
- A REST API-k használatával hívja meg az Adatforrás létrehozása parancsot.
- A .NET-hez készült Azure SDK használatával hívja meg a SearchIndexerDataSourceConnection osztályt
2. lépés: Index létrehozása
Az indexelők automatizálni tudják az adatfeldolgozáshoz kapcsolódó bizonyos feladatokat, de az indexek létrehozása nem tartozik ezek közé. Előfeltételként rendelkeznie kell egy előre definiált indexkel, amely a külső adatforrás bármely forrásmezőjének megfelelő célmezőit tartalmazza. A mezőknek név és adattípus szerint kell egyeznie. Ha nem, mezőleképezéseket határozhat meg a társítás létrehozásához.
További információ: Index létrehozása.
3. lépés: Az indexelő létrehozása és futtatása (vagy ütemezése)
Az indexelő definíciója olyan tulajdonságokból áll, amelyek egyedileg azonosítják az indexelőt, megadják, hogy melyik adatforrást és indexet használják, és egyéb konfigurációs beállításokat biztosítanak, amelyek befolyásolják a futási idő viselkedését, beleértve azt is, hogy az indexelő igény szerint vagy ütemezés szerint fut-e.
Az indexelő végrehajtása során az adathozzáféréssel vagy a képességkészlet ellenőrzésével kapcsolatos hibák vagy figyelmeztetések lépnek fel. Az indexelő végrehajtásának megkezdéséig a függő objektumok, például az adatforrások, az indexek és a képességkészletek passzívak a keresési szolgáltatásban.
További információ: Indexelő létrehozása
Az első indexelő futtatása után igény szerint újrafuttathatja, vagy ütemezést állíthat be.
Az indexelő állapotát a portálon vagy az Indexelő állapotának lekérése API-val figyelheti. Az indexen lekérdezéseket is futtatnia kell, hogy ellenőrizze, hogy az eredmény a várt eredmény-e.
Az indexelők nem rendelkeznek dedikált feldolgozási erőforrásokkal. Ennek alapján előfordulhat, hogy az indexelők állapota inaktívként jelenik meg a futtatás előtt (az üzenetsor más feladataitól függően), és a futtatási idők nem kiszámíthatók. Más tényezők is meghatározzák az indexelő teljesítményét, például a dokumentumméretet, a dokumentum összetettségét, a képelemzést.
Következő lépések
Most, hogy megismerte az indexelőket, a következő lépés az indexelő tulajdonságainak és paramétereinek, ütemezésének és indexelő figyelésének áttekintése. Másik lehetőségként visszatérhet a támogatott adatforrások listájára, ha további információt szeretne egy adott forrásról.