C# oktatóanyag: Kereshető tartalom létrehozása az Azure AI Searchben képességkészletek használatával
Ebben az oktatóanyagban megtudhatja, hogyan hozhat létre AI-bővítési folyamatot tartalomkinyeréshez és átalakításokhoz az indexelés során az Azure SDK for .NET használatával.
A képességkészletek AI-feldolgozást adnak a nyers tartalomhoz, így egységesebbé és kereshetőbbé teszik a tartalmat. Ha már tudja, hogyan működnek a készségkészletek, számos átalakítást támogathat: a képelemzéstől a természetes nyelvi feldolgozáson át a külsőleg biztosított testre szabott feldolgozásig.
Ez az oktatóanyag a következőket ismerteti:
- Objektumok definiálása bővítési folyamatban.
- Képességkészlet létrehozása. OcR meghívása, nyelvfelismerés, entitásfelismerés és kulcskifejezés-kinyerés.
- Hajtsa végre a folyamatot. Keresési index létrehozása és betöltése.
- Ellenőrizze az eredményeket teljes szöveges kereséssel.
Ha nem rendelkezik Azure-előfizetéssel, a kezdés előtt nyisson meg egy ingyenes fiókot .
Áttekintés
Ez az oktatóanyag a C# és az Azure.Search.Documents ügyfélkódtár használatával hoz létre adatforrást, indexelőt, indexelőt és készségkészletet.
Az indexelő a folyamat minden lépését vezérli, kezdve a mintaadatok (strukturálatlan szöveg és képek) tartalomkinyerésével egy Azure Storage-blobtárolóban.
A tartalom kinyerése után a képességkészlet beépített képességeket hajt végre a Microsofttól az információk megkereséséhez és kinyeréséhez. Ezek a képességek közé tartozik a képek optikai karakterfelismerése (OCR), a szöveg nyelvfelismerése, a kulcskifejezések kinyerése és az entitásfelismerés (szervezetek). A képességkészlet által létrehozott új információk egy index mezőibe kerülnek. Az index feltöltése után használhatja a lekérdezések, aspektusok és szűrők mezőit.
Előfeltételek
Feljegyzés
Ehhez az oktatóanyaghoz ingyenes keresési szolgáltatást használhat. Az ingyenes szint három indexre, három indexelőre és három adatforrásra korlátozza. Az oktatóanyagban mindegyikből egyet hozhat majd létre. Mielőtt hozzákezdene, győződjön meg arról, hogy van helye a szolgáltatásban az új erőforrások elfogadásához.
Fájlok letöltése
Töltse le a mintaadattár zip-fájlját, és bontsa ki a tartalmat. További tudnivalókat itt talál.
Mintaadatok feltöltése az Azure Storage-ba
Az Azure Storage-ban hozzon létre egy új tárolót, és nevezze el cog-search-demo néven.
Szerezze be a tárolási kapcsolati sztring, hogy kapcsolatot alakíthass ki az Azure AI Searchben.
A bal oldalon válassza az Access-kulcsokat.
Másolja a kapcsolati sztring az első vagy a második kulcshoz. A kapcsolati sztring a következő példához hasonló:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure AI services
A beépített AI-bővítést az Azure AI-szolgáltatások támogatják, beleértve a language szolgáltatást és az Azure AI Visionet a természetes nyelv és a képfeldolgozás érdekében. Az oktatóanyaghoz hasonló kis számítási feladatok esetében indexelőnként 20 tranzakció ingyenes lefoglalását használhatja. Nagyobb számítási feladatok esetén csatoljon egy Többrégiós Azure AI Services-erőforrást egy használatalapú fizetéses díjszabást nyújtó készségkészlethez .
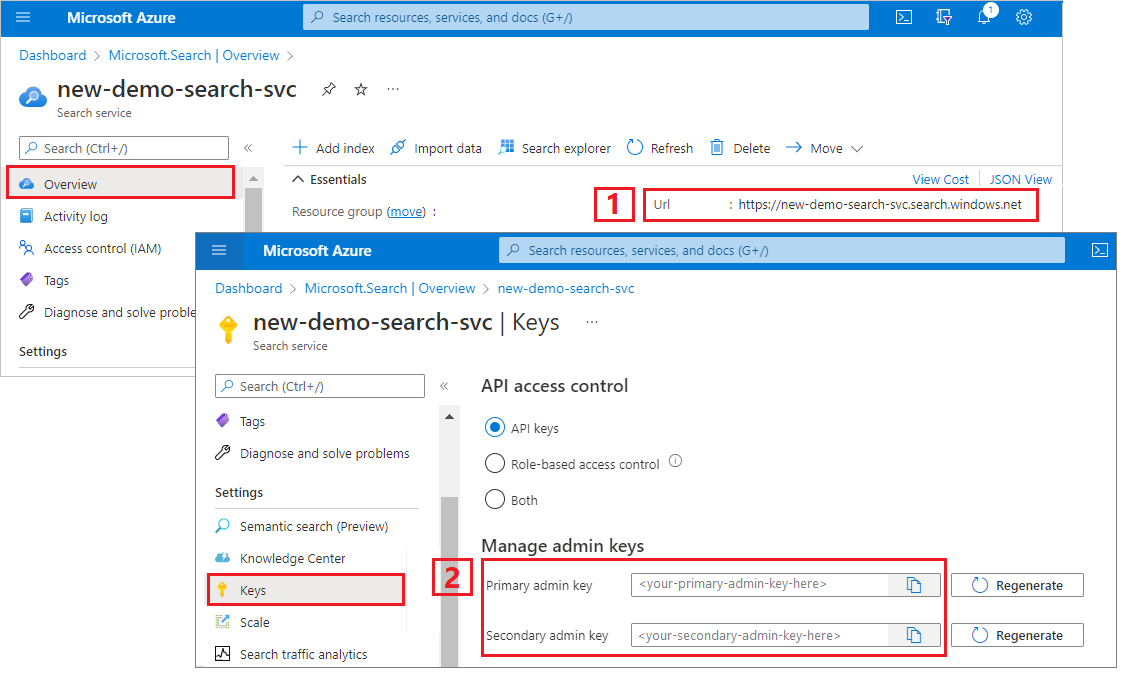
Keresési szolgáltatás URL-címének és API-kulcsának másolása
Ebben az oktatóanyagban az Azure AI Searchhez való csatlakozáshoz végpontra és API-kulcsra van szükség. Ezeket az értékeket az Azure Portalon szerezheti be.
Jelentkezzen be az Azure Portalra, lépjen a keresési szolgáltatás áttekintési oldalára, és másolja az URL-címet. A végpontok például a következőképpen nézhetnek ki:
https://mydemo.search.windows.net.A Beállítások>kulcsok területen másolja ki a rendszergazdai kulcsot. A rendszergazdai kulcsok objektumok hozzáadására, módosítására és törlésére szolgálnak. Két felcserélhető rendszergazdai kulcs van. Másolja valamelyiket.
Saját környezet beállítása
Először nyissa meg a Visual Studio-t, és hozzon létre egy új konzolalkalmazás-projektet, amely a .NET Core-on futtatható.
Az Azure.Search.Documents telepítése
Az Azure AI Search .NET SDK egy ügyfélkódtárból áll, amely lehetővé teszi az indexek, adatforrások, indexelők és képességkészletek kezelését, valamint a dokumentumok feltöltését és kezelését, valamint a lekérdezések végrehajtását anélkül, hogy a HTTP és a JSON részleteivel kellene foglalkoznia. Ez az ügyfélkódtár NuGet-csomagként van elosztva.
Ehhez a projekthez telepítse a 11-es vagy újabb verziót, Azure.Search.Documents valamint a legújabb verziót Microsoft.Extensions.Configuration.
A Visual Studióban válassza az Tools>NuGet Csomagkezelő> Manage NuGet Packages for Solution...
Keresse meg az Azure.Search.Document fájlt.
Válassza ki a legújabb verziót, majd válassza a Telepítés lehetőséget.
Ismételje meg az előző lépéseket a Microsoft.Extensions.Configuration és a Microsoft.Extensions.Configuration.Json telepítéséhez.
Szolgáltatáskapcsolati adatok hozzáadása
Kattintson a jobb gombbal a projektre a Megoldáskezelő, és válassza az Új elem hozzáadása>... lehetőséget.
Nevezze el a fájlt
appsettings.json, és válassza a Hozzáadás lehetőséget.Adja meg ezt a fájlt a kimeneti könyvtárban.
- Kattintson a jobb gombbal, és válassza a
appsettings.jsonTulajdonságok lehetőséget. - Módosítsa a másolás értékét a Kimeneti könyvtárra , ha újabb.
- Kattintson a jobb gombbal, és válassza a
Másolja az alábbi JSON-fájlt az új JSON-fájlba.
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
Adja hozzá a keresési szolgáltatást és a Blob Storage-fiók adatait. Ne feledje, hogy ezeket az információkat az előző szakaszban ismertetett szolgáltatáskiépítési lépésekből szerezheti be.
SearchServiceUri esetén adja meg a teljes URL-címet.
Névterek hozzáadása
Adja Program.cshozzá a következő névtereket.
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
Ügyfél létrehozása
Hozzon létre egy példányt SearchIndexClient egy és egy SearchIndexerClient alatt Main.
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
Feljegyzés
Az ügyfelek a keresési szolgáltatáshoz csatlakoznak. A túl sok kapcsolat megnyitásának elkerülése érdekében próbálja meg megosztani egyetlen példányt az alkalmazásban, ha lehetséges. A metódusok szálbiztosak az ilyen megosztás engedélyezéséhez.
Függvény hozzáadása a programból való kilépéshez hiba esetén
Ez az oktatóanyag segít megérteni az indexelési folyamat minden lépését. Ha van egy kritikus probléma, amely megakadályozza, hogy a program létrehozza az adatforrást, a képességkészletet, az indexet vagy az indexelőt, a program megjeleníti a hibaüzenetet, és kilép a problémából, hogy megérthető és kezelhető legyen.
Adja hozzá ExitProgram azokat a Main forgatókönyveket, amelyekhez a programnak ki kell lépnie.
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
A folyamat létrehozása
Az Azure AI Searchben az AI-feldolgozás az indexelés (vagy adatbetöltés) során történik. Az útmutató ezen része négy objektumot hoz létre: adatforrást, indexdefiníciót, képességkészletet, indexelőt.
1. lépés: Adatforrás létrehozása
SearchIndexerClient van egy DataSourceName tulajdonsága, amelyet egy objektumra SearchIndexerDataSourceConnection állíthat be. Ez az objektum biztosítja az Azure AI Search-adatforrások létrehozásához, listázásához, frissítéséhez vagy törléséhez szükséges összes módszert.
Hozzon létre egy új SearchIndexerDataSourceConnection példányt hívással indexerClient.CreateOrUpdateDataSourceConnection(dataSource). Az alábbi kód létrehoz egy típusú AzureBlobadatforrást.
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("cog-search-demo"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
Sikeres kérés esetén a metódus a létrehozott adatforrást adja vissza. Ha probléma merül fel a kéréssel, például egy érvénytelen paraméterrel, a metódus kivételt okoz.
Most vegyen fel egy sort Main az CreateOrUpdateDataSource imént hozzáadott függvény meghívásához.
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
Fordítsa le és futtassa a megoldást. Mivel ez az első kérése, ellenőrizze az Azure Portalon, hogy az adatforrás létrejött-e az Azure AI Searchben. A keresési szolgáltatás áttekintési lapján ellenőrizze, hogy az Adatforrások lista tartalmaz-e új elemet. Lehet, hogy várnia kell néhány percet, amíg a portáloldal frissül.

2. lépés: Képességkészlet létrehozása
Ebben a szakaszban megadhatja az adatokra alkalmazni kívánt bővítési lépéseket. Minden egyes bővítési lépést készségnek és a bővítési lépések készletének, egy készségkészletnek nevezünk. Ez az oktatóanyag beépített készségeket használ a készségkészlethez:
Optikai karakterfelismerés a képfájlokban lévő nyomtatott és kézzel írt szövegek felismeréséhez.
Szövegegyesítés egy mezőgyűjtemény szövegének egyetlen "egyesített tartalom" mezőbe való összevonásához.
Nyelvfelismeréssel azonosítja a tartalom nyelvét.
Entitásfelismerés a szervezetek nevének a blobtárolóban lévő tartalomból való kinyeréséhez.
A szöveg felosztásával nagyobb tartalmakat bonthat kisebb darabokra, mielőtt meghívja a kulcskifejezés-kinyerési képességet és az entitásfelismerési képességet. A kulcskifejezések kinyerése és az entitásfelismerés legfeljebb 50 000 karakteres bemeneteket fogad el. A mintafájlok közül néhányat fel kell osztani ahhoz, hogy beleférjen a korlátozásba.
A Kulcskifejezések kinyerése lehívja a leggyakoribb kulcskifejezéseket.
A kezdeti feldolgozás során az Azure AI Search minden dokumentumot feltör, hogy tartalmat nyerjen ki a különböző fájlformátumokból. A forrásfájlból származó szöveg egy létrehozott content mezőbe kerül, minden dokumentumhoz egyet. Ennek megfelelően állítsa be a bemenetet "/document/content" a szöveg használatára. A rendszer a képtartalmat egy létrehozott normalized_images mezőbe helyezi, amely egy készségkészletben a következőként /document/normalized_images/*van megadva: .
A kimenetek hozzárendelhetők egy indexhez, bemenetként használhatók egy alsóbb rétegbeli képességhez, vagy a fentiek mindegyike lehetséges, akárcsak a nyelvkód esetében. Az indexben a nyelvkód a szűréskor lehet hasznos. A nyelvkódot bemenetként a szövegelemzési képességek használják, a szótördeléssel kapcsolatos nyelvi szabályok megadásához.
A képességcsoportok alapvető tudnivalóval kapcsolatos bővebb információkért lásd: Képességcsoport megadása.
OCR-képesség
A OcrSkill rendszer képekből nyer ki szöveget. Ez a képesség feltételezi, hogy létezik egy normalized_images mező. A mező létrehozásához az oktatóanyag későbbi részében az "imageAction" indexelő definíciójának konfigurációját a következőre "generateNormalizedImages"állítottuk be: .
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
Egyesítési képesség
Ebben a szakaszban egy MergeSkill olyan mezőt hoz létre, amely egyesíti a dokumentumtartalom-mezőt az OCR-képesség által létrehozott szöveggel.
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
Nyelvfelismerési képesség
A LanguageDetectionSkill program észleli a bemeneti szöveg nyelvét, és egyetlen nyelvi kódot jelent a kérelemben beküldött minden dokumentumhoz. A Language Detection skill kimenetét a Szöveg felosztása képesség bemeneteként használjuk.
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
Szövegfelosztási képesség
Az alábbiakban SplitSkill oldalak szerint osztja fel a szöveget, és az oldal hosszát 4000 karakterre korlátozza a mérték szerint String.Length. Az algoritmus a szöveget legfeljebb maximumPageLength méretben lévő adattömbökre próbálja felosztani. Ebben az esetben az algoritmus a lehető legjobban meg tudja törni a mondatot egy mondathatáron, így az adattömb mérete valamivel kisebb lehet, mint maximumPageLengtha .
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
Entitásfelismerési képesség
Ez EntityRecognitionSkill a példány a kategóriatípus organizationfelismerésére van beállítva. A EntityRecognitionSkill kategóriatípusok person és locationa .
Figyelje meg, hogy a "context" mező csillaggal van beállítva "/document/pages/*" , ami azt jelenti, hogy a dúsítási lépés az egyes lapokhoz lesz meghívva a következő alatt "/document/pages".
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
EntityRecognitionSkill entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
Kulcskifejezés-kinyerési képesség
EntityRecognitionSkill Az imént létrehozott példányhoz hasonlóan a KeyPhraseExtractionSkill dokumentum minden oldalára meghívja a dokumentumot.
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
A készségkészlet létrehozása és létrehozása
Hozza létre a SearchIndexerSkillset létrehozott készségeket.
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Azure AI services was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
Adja hozzá a következő sorokat a következőhöz Main:
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
3. lépés: Index létrehozása
Ebben a szakaszban egy indexsémát határoz meg a kereshető indexben szereplő mezők és az egyes mezők keresési attribútumainak megadásával. A mezők típussal is rendelkeznek, emellett olyan attribútumokat tartalmazhatnak, amelyek meghatározzák a mező használatának módját (kereshető, rendezhető stb.). Az indexben lévő mezőneveknek nem kell egyezniük a forrás mezőnevével. Egy későbbi lépésben mezőleképezéseket fog hozzáadni egy indexelőhöz a forrás-cél mezőkhöz való csatlakozás céljából. Ebben a lépésben a keresőalkalmazásra vonatkozó mezőelnevezési konvenciók használatával határozza meg az indexet.
A gyakorlat során az alábbi mezőket és mezőtípusokat használjuk:
| Mezőnevek | Mezőtípusok |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
Edm.String listázása<> |
organizations |
Edm.String listázása<> |
DemoIndex-osztály létrehozása
Az index mezői modellosztály használatával vannak definiálva. A modellosztály minden tulajdonsága olyan attribútumokkal rendelkezik, amelyek meghatározzák a megfelelő indexmező keresési viselkedését.
A modellosztályt hozzáadjuk egy új C#-fájlhoz. Kattintson a jobb gombbal a projektre, és válassza az Új elem hozzáadása>... lehetőséget, válassza az "Osztály" lehetőséget, és adja meg a fájl DemoIndex.csnevét, majd válassza a Hozzáadás lehetőséget.
Ügyeljen arra, hogy jelezze, hogy típusokat szeretne használni a névterekből és System.Text.Json.Serialization a Azure.Search.Documents.Indexes névterekből.
Adja hozzá az alábbi modellosztály-definíciót DemoIndex.cs , és adja hozzá ugyanabba a névtérbe, ahol az indexet létrehozza.
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
Most, hogy definiált egy modellosztályt, elég Program.cs könnyen létrehozhat egy indexdefiníciót. Az index neve a következő lesz demoindex: . Ha egy index már létezik ezzel a névvel, az törlődik.
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
A tesztelés során előfordulhat, hogy többször is megpróbálja létrehozni az indexet. Emiatt ellenőrizze, hogy a létrehozni kívánt index már létezik-e, mielőtt megkísérli létrehozni.
Adja hozzá a következő sorokat a következőhöz Main:
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
A egyértelmű hivatkozás feloldásához adja hozzá az alábbi utasítást.
using Index = Azure.Search.Documents.Indexes.Models;
Az indexfogalmakkal kapcsolatos további információkért lásd az Index létrehozása (REST API) című témakört.
4. lépés: Indexelő létrehozása és futtatása
Eddig létrehozott egy adatforrást, egy képességcsoportot és egy indexet. Ez a három összetevő egy olyan indexelő része lesz, amely az egyes részeket egyetlen többszakaszos műveletben egyesíti. A három rész egy indexelőben való egyesítéséhez mezőleképezéseket kell meghatároznia.
A fieldMappings a képességkészlet előtt lesz feldolgozva, a forrásmezők az adatforrásból az index célmezőibe lesznek megfeleltetve. Ha a mezőnevek és a típusok mindkét végén megegyeznek, nincs szükség leképezésre.
Az outputFieldMappings a képességkészlet után lesz feldolgozva, és a forrásmezőnevekre hivatkozik, amelyek nem léteznek, amíg a dokumentum feltörése vagy bővítése létre nem hozza őket. A targetFieldName egy index mezője.
A bemenetek kimenetekhez való csatlakoztatása mellett mezőleképezésekkel is összesimíthatja az adatstruktúrákat. További információ: Bővített mezők leképezése kereshető indexre.
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
Adja hozzá a következő sorokat a következőhöz Main:
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
Várhatja, hogy az indexelő feldolgozása eltarthat egy ideig. Annak ellenére, hogy az adatkészlet kis méretű, az analitikai képességek számítási igénye nagy. Néhány képesség, például a képelemzés futásideje hosszú.
Tipp.
Az indexelő létrehozása elindítja a folyamatot. Ha probléma lép fel az adatok elérésével, a bemenetek és kimenetek leképezésével vagy a műveletek sorrendjével kapcsolatban, az ebben a szakaszban jelenik meg.
Az indexelő létrehozásának megismerése
A kód -1 értékre van halmazva "maxFailedItems" , amely arra utasítja az indexelő motort, hogy hagyja figyelmen kívül az adatimportálás során előforduló hibákat. Ez azért hasznos, mert az adatforrás kevés dokumentumot tartalmaz. Nagyobb méretű adatforrás esetén 0-nál nagyobb értéket kell megadnia.
Azt is figyelje meg, hogy a "dataToExtract" beállítás értéke ."contentAndMetadata" Ez az utasítást meghatározza, hogy az indexelő automatikusan kinyerje a tartalmat a különböző fájlformátumokból, beleértve az egyes fájlokra vonatkozó metaadatokat is.
Tartalom kinyerésekor az imageAction beállításával kinyerheti a szöveget az adatforrásban talált képekből. A "imageAction" konfigurációs "generateNormalizedImages" beállítás az OCR-képesség és a szövegegyesítési képesség együttes használatával arra utasítja az indexelőt, hogy bontsa ki a képekből a szöveget (például a "stop" szót egy forgalmi stop jelből), és ágyazza be a tartalommezőbe. Ez a működés mind a dokumentumokban beágyazott képekre (például egy PDF-fájlban található képre), mind az adatforrásban talált képekre (például egy JPG-fájlra) vonatkozik.
Indexelés figyelése
Az indexelő meghatározását követően az indexelő a kérés elküldésekor automatikusan lefut. Attól függően, hogy milyen készségeket definiált, az indexelés a vártnál tovább tarthat. Annak megállapításához, hogy az indexelő továbbra is fut-e, használja a metódust GetStatus .
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure Portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo az indexelőzmények aktuális állapotát és végrehajtási előzményeit jelöli.
A figyelmeztetések gyakran előfordulnak a forrásfájlok és a képességek egyes kombinációiban, és nem mindig jeleznek problémát. Ebben az oktatóanyagban a figyelmeztetések jóindulatúak (például nincs szöveges bemenet a JPEG-fájlokból).
Adja hozzá a következő sorokat a következőhöz Main:
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
Keresés
Az Azure AI Search oktatóanyag konzolalkalmazásaiban általában 2 másodperces késést adunk hozzá, mielőtt eredményeket eredményező lekérdezéseket futtatnánk, de mivel a bővítés több percet vesz igénybe, bezárjuk a konzolalkalmazást, és helyette egy másik megközelítést használunk.
A legegyszerűbb megoldás a Kereséskezelő a portálon. Először futtathat egy üres lekérdezést, amely az összes dokumentumot visszaadja, vagy egy célzottabb keresést, amely a folyamat által létrehozott új mezőtartalmakat adja vissza.
Az Azure Portal keresési áttekintési lapján válassza az Indexek lehetőséget.
Keresse meg
demoindexa listában. 14 dokumentumnak kell lennie. Ha a dokumentumszám nulla, akkor az indexelő továbbra is fut, vagy a lap még nem frissült.Válassza ki
demoindex. A Kereséskezelő az első lap.A tartalom az első dokumentum betöltése után azonnal kereshető. A tartalom meglétének ellenőrzéséhez futtasson egy meghatározatlan lekérdezést a Keresés gombra kattintva. Ez a lekérdezés az összes jelenleg indexelt dokumentumot visszaadja, így képet kap arról, hogy mit tartalmaz az index.
Ezután illessze be a következő sztringet a kezelhetőbb eredmények érdekében:
search=*&$select=id, languageCode, organizations
Alaphelyzetbe állítás és ismételt futtatás
A fejlesztés korai kísérleti fázisaiban a tervezési iteráció legpraktikusabb módszere az objektumok törlése az Azure AI Searchből, és a kód újraépítésének engedélyezése. Az erőforrásnevek egyediek. Egy objektum törlése révén újból létrehozhatja azt ugyanazzal a névvel.
Az oktatóanyag mintakódja ellenőrzi a meglévő objektumokat, és törli őket, hogy újrafuttassa a kódot. A portálon indexeket, indexelőket, adatforrásokat és képességkészleteket is törölhet.
Legfontosabb ismeretek
Ez az oktatóanyag bemutatja a bővített indexelési folyamat létrehozásának alapvető lépéseit az összetevők – adatforrás, képességkészlet, indexelő és indexelő – létrehozásával.
Bevezették a beépített készségeket , valamint a készségek definícióját és a készségek összeláncolásának mechanikát bemeneteken és kimeneteken keresztül. Azt is megtudhatta, hogy az indexelő definíciója szükséges ahhoz, hogy outputFieldMappings a gazdagított értékeket a folyamatból egy kereshető indexbe irányítsa egy Azure AI-Search szolgáltatás.
Végül megismerte, hogyan tesztelheti az eredményeket, és hogyan állíthatja alaphelyzetbe a rendszert a későbbi futtatásokhoz. Megtanulta, hogy ha lekérdezéseket futtat az indexen, az a bővített indexelési folyamat által létrehozott kimenetet adja vissza. Emellett azt is megtanulta, hogyan ellenőrizheti az indexelő állapotát, illetve hogy melyik objektumokat kell törölnie a folyamat újrafuttatása előtt.
Az erőforrások eltávolítása
Ha a saját előfizetésében dolgozik, a projekt végén célszerű eltávolítania a már nem szükséges erőforrásokat. A továbbra is futó erőforrások költségekkel járhatnak. Az erőforrásokat törölheti egyesével, vagy az erőforráscsoport törlésével eltávolíthatja a benne lévő összes erőforrást is.
A portálon a bal oldali navigációs panel Minden erőforrás vagy Erőforráscsoport hivatkozásával kereshet és kezelhet erőforrásokat.
Következő lépések
Most, hogy megismerkedett az AI-bővítési folyamat összes objektumával, tekintsük át közelebbről a képességkészlet-definíciókat és az egyéni képességeket.