Varázslók importálása az Azure AI Searchben
Az Azure AI Search két importálási varázslóval rendelkezik, amelyek automatizálják az indexelést és az objektumdefiníciókat, hogy azonnal megkezdhesse a lekérdezést. Ha még csak most ismerkedik az Azure AI Search szolgáltatással, ezek a varázslók a rendelkezésére álló leghatékonyabb funkciók egyike. Minimális erőfeszítéssel létrehozhat egy indexelési vagy bővítési folyamatot, amely az Azure AI Search legtöbb funkcióját gyakorolja.
Az Adatok importálása varázsló támogatja a nem közreműködő munkafolyamatokat. Nyers dokumentumokból alfanumerikus szöveget is kinyerhet. Az alkalmazott AI-t és beépített képességeket is konfigurálhatja, amelyek strukturált és kereshető tartalmat hoznak létre képfájlokból és strukturálatlan adatokból.
Az Adatok importálása és vektorizálása varázsló támogatja a vektorizálást. Meg kell adnia egy beágyazási modell meglévő üzembe helyezését, de a varázsló elvégzi a kapcsolatot, összeállítja a kérést, és kezeli a választ. Vektortartalmat hoz létre szöveg- vagy képtartalmakból.
Ha a varázslót használja a megvalósíthatósági vizsgálathoz, ez a cikk ismerteti a varázslók belső működését, hogy hatékonyabban tudja használni őket.
Ez a cikk nem lépésről lépésre. A varázsló beépített mintaadatokkal való használatával kapcsolatos segítségért lásd:
- Rövid útmutató: Keresési index létrehozása
- Rövid útmutató: Szövegfordítási és entitás-készségkészlet létrehozása
- Rövid útmutató: Vektorindex létrehozása
- Rövid útmutató: képkeresés (vektorok)
A varázslók indítása
Az Azure Portalon nyissa meg a keresési szolgáltatás lapját az irányítópulton, vagy keresse meg a szolgáltatást a szolgáltatáslistában.
A felül található Szolgáltatás áttekintése lapon válassza az Adatok importálása vagy Az adatok importálása és vektorizálása lehetőséget.
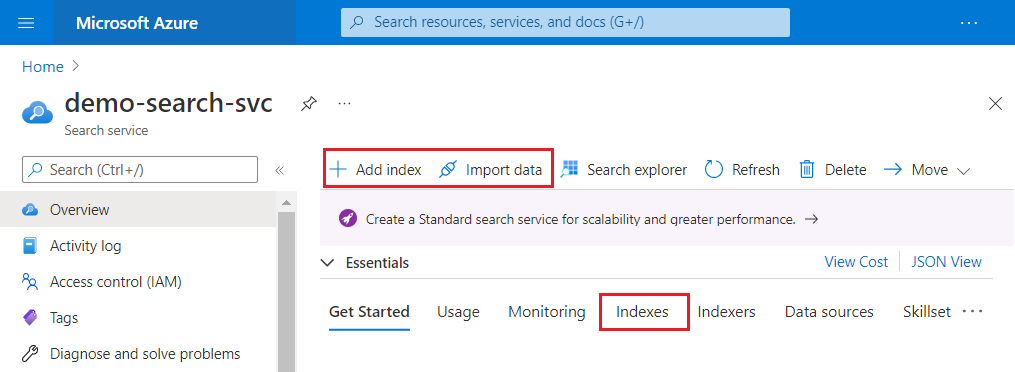
A varázslók teljesen ki vannak bontva a böngészőablakban, hogy több hely legyen a munkához.
Ha az Adatok importálása lehetőséget választotta, a Minták lehetőséget választva egy előre összeállított, támogatott adatforrásból származó adatmintát használhat.

Az index és az indexelő létrehozásához kövesse a varázsló további lépéseit.
Az Importálási adatokat más Azure-szolgáltatásokból is elindíthatja, például az Azure Cosmos DB-ből, az Azure SQL Database-ből, a felügyelt SQL-példányból és az Azure Blob Storage-ból. Keresse meg az Azure AI Search hozzáadása lehetőséget a szolgáltatás áttekintési oldalán, a bal oldali navigációs panelen.
A varázsló által létrehozott objektumok
A varázsló az alábbi táblázatban adja ki az objektumokat. Az objektumok létrehozása után áttekintheti a JSON-definíciókat a portálon, vagy meghívhatja őket kódból.
| Objektum | Leírás |
|---|---|
| Indexelő | Egy konfigurációs objektum, amely megadja az adatforrást, a célindexet, az opcionális képességkészletet, az opcionális ütemezést, valamint a hibaátadáshoz és a base-64 kódoláshoz szükséges opcionális konfigurációs beállításokat. |
| Adatforrás | Megőrzi a kapcsolati adatokat egy támogatott adatforráshoz az Azure-ban. Az adatforrás-objektumokat kizárólag indexelők használják. |
| Index | A teljes szöveges kereséshez és más lekérdezésekhez használt fizikai adatstruktúra. |
| Készségkészlet | Opcionális. A tartalom manipulálására, átalakítására és alakítására vonatkozó utasítások teljes készlete, beleértve a képfájlokból származó információk elemzését és kinyerését. Az integrált vektorizáláshoz készségkészleteket is használnak. Hacsak a munka mennyisége nem esik az indexelőnkénti napi 20 tranzakciós korlát alá, a képességkészletnek tartalmaznia kell egy, a bővítést biztosító Többszolgáltatásos Azure AI-erőforrásra mutató hivatkozást. Az integrált vektorizáláshoz használhatja az Azure AI Visiont vagy egy beágyazási modellt az Azure AI Studio modellkatalógusában. |
| Tudástár | Opcionális. A kimeneteket táblákban és blobokban tárolja az Azure Storage-ban független elemzéshez vagy alsóbb rétegbeli feldolgozáshoz nemarchia forgatókönyvekben. |
Juttatások
A kód írása előtt használhatja a varázslókat a prototípus- és a megvalósíthatósági vizsgálathoz. A varázslók külső adatforrásokhoz csatlakoznak, mintát vesz az adatokból egy kezdeti index létrehozásához, majd JSON-dokumentumként importálják és igény szerint vektorizálják az adatokat egy Indexbe az Azure AI Searchben.
A képességkészletek kiértékelése esetén a varázsló kezeli a kimeneti mezők leképezését, és segédfüggvényeket ad hozzá használható objektumok létrehozásához. Ha elemzési módot ad meg, szövegfelosztás lesz hozzáadva. A szövegegyesítés akkor lesz hozzáadva, ha képelemzést választott, hogy a varázsló újra egyesítse a szövegleírásokat képtartalommal. Ha a tudástár lehetőséget választja, az alakzatkezelő készségek hozzáadva az érvényes előrejelzések támogatásához. A fenti feladatok mindegyike tanulási görbével rendelkezik. Ha még csak most ismerkedik a bővítéssel, a lépések végrehajtásának lehetősége lehetővé teszi a képesség értékének mérését anélkül, hogy sok időt és energiát kellene fektetnie.
A mintavételezés az a folyamat, amellyel az indexséma kikövetkeztetett, és bizonyos korlátozásokkal rendelkezik. Az adatforrás létrehozásakor a varázsló kiválaszt egy véletlenszerű dokumentummintát, hogy eldöntse, mely oszlopok tartoznak az adatforráshoz. Nem minden fájl van beolvasva, mivel ez akár órákat is igénybe vehet a nagyon nagy méretű adatforrások esetében. A dokumentumok kiválasztásával a forrás metaadatai, például a mezőnév vagy a típus mezőgyűjtemények létrehozására szolgálnak egy indexsémában. A forrásadatok összetettségétől függően előfordulhat, hogy módosítania kell a kezdeti sémát a pontosság érdekében, vagy ki kell terjesztenie a teljesség érdekében. A módosításokat beágyazottan is elvégezheti az indexdefiníció oldalán.
Összességében a varázsló használatának előnyei egyértelműek: amíg a követelmények teljesülnek, percek alatt létrehozhat egy lekérdezhető indexet. Az indexelés néhány összetettségét, például az adatok JSON-dokumentumokként való szerializálását a varázsló kezeli.
Korlátozások
A varázsló nem korlátozás nélkül működik. A korlátozások a következőképpen vannak összegezve:
A varázsló nem támogatja az iterációt vagy az újrafelhasználást. A varázsló minden áthaladása új index-, képességkészlet- és indexelőkonfigurációt hoz létre. A varázslóban csak adatforrások tárolhatók és használhatók fel újra. Más objektumok szerkesztéséhez vagy finomításához törölje az objektumokat, és kezdje újra, vagy használja a REST API-kat vagy a .NET SDK-t a struktúrák módosításához.
A forrástartalomnak támogatott adatforrásban kell lennie.
A mintavételezés a forrásadatok egy részhalmazán keresztül történik. Nagy adatforrások esetén előfordulhat, hogy a varázsló kihagyja a mezőket. Előfordulhat, hogy ki kell terjesztenie a sémát, vagy ki kell javítania a kikövetkeztetett adattípusokat, ha a mintavételezés nem elegendő.
A portálon közzétett AI-bővítés a beépített képességek egy részhalmazára korlátozódik.
A varázsló által létrehozható tudástárak csak néhány alapértelmezett előrejelzésre korlátozódnak, és egy alapértelmezett elnevezési konvenciót használnak. Ha testre szeretné szabni a neveket vagy az előrejelzéseket, létre kell hoznia a tudástárat a REST API-val vagy az SDK-kkal.
Biztonságos kapcsolatok
Az importálási varázslók kimenő kapcsolatokat hoznak létre a portálvezérlő és a nyilvános végpontok használatával. Nem használhatja a varázslókat, ha az Azure-erőforrások privát kapcsolaton vagy megosztott privát kapcsolaton keresztül érhetők el.
A varázslók korlátozott nyilvános kapcsolatokon keresztül is használhatók, de nem minden funkció érhető el.
A keresési szolgáltatásban a beépített mintaadatok importálásához nyilvános végpontra és tűzfalszabályokra van szükség.
A mintaadatokat a Microsoft üzemelteti adott Azure-erőforrásokon. A portálvezérlő nyilvános végponton keresztül csatlakozik ezekhez az erőforrásokhoz. Ha tűzfal mögé helyezi a keresési szolgáltatást, a következő hibaüzenet jelenik meg a beépített mintaadatok lekérésekor:
Import configuration failed, error creating Data Sourcemajd a"An error has occured."következő.A tűzfalak által védett támogatott Azure-adatforrások esetében lekérheti az adatokat, ha a megfelelő tűzfalszabályok vannak érvényben.
Az Azure-erőforrásnak el kell fogadnia a kapcsolaton használt eszköz IP-címéről érkező hálózati kéréseket. Az Azure AI Searcht megbízható szolgáltatásként is fel kell sorolnia az erőforrás hálózati konfigurációjában. Az Azure Storage-ban például megbízható szolgáltatásként listázhatja
Microsoft.Search/searchServices.Az Ön által megadott Többszolgáltatásos Azure AI-fiókhoz való kapcsolatokon vagy az Azure AI Studióban vagy az Azure OpenAI-ban üzembe helyezett modellek beágyazási modelljeihez való kapcsolatokon engedélyezni kell a nyilvános internetkapcsolatot. Ezek az Azure-erőforrások akkor lesznek meghívva, ha beépített készségeket használ az Adatok importálása varázslóban, vagy integrált vektorizációt az Adatok importálása és vektorizálása varázslóban.
Az Adatok importálása és vektorizálása varázslóban a hiba a következő:
"Access denied due to Virtual Network/Firewall rules."Az Adatok importálása varázslóban nincs hiba, de a készségkészlet nem jön létre.
Ha a tűzfalbeállítások megakadályozzák a varázsló munkafolyamatainak sikerességét, fontolja meg inkább a szkriptes vagy programozott megközelítéseket.
Munkafolyamat
A varázsló négy fő lépésből áll:
Csatlakozzon egy támogatott Azure-adatforráshoz.
Hozzon létre egy indexsémát a forrásadatok mintavételezésével.
Igény szerint hozzáadhat alkalmazott AI-t a tartalom és a struktúra kinyeréséhez vagy létrehozásához. Ebben a lépésben gyűjtjük össze a tudástár létrehozásához szükséges bemeneteket.
Futtassa a varázslót objektumok létrehozásához, opcionálisan adatok vektorizálásához, adatok indexbe való betöltéséhez, ütemezés és egyéb konfigurációs beállítások beállításához.
A munkafolyamat egy folyamat, így ez az egyik módja. A varázslóval nem szerkesztheti a létrehozott objektumokat, de más portáleszközöket, például az indexelőt vagy az indexelő tervezőt vagy a JSON-szerkesztőket is használhatja az engedélyezett frissítésekhez.
Adatforrás-konfiguráció a varázslóban
A varázslók egy külső támogatott adatforráshoz csatlakoznak az Azure AI Search indexelői által biztosított belső logikával, amely alkalmas a forrás mintájára, metaadatok olvasására, dokumentumok feltörésére a tartalom és a struktúra olvasásához, valamint a tartalom JSON-ként való szerializálására az Azure AI Searchbe való későbbi importáláshoz.
Beilleszthet egy kapcsolatot egy másik előfizetésben vagy régióban lévő támogatott adatforráshoz, de a Meglévő kapcsolatválasztó kiválasztása lehetőség az aktív előfizetésre van korlátozva.
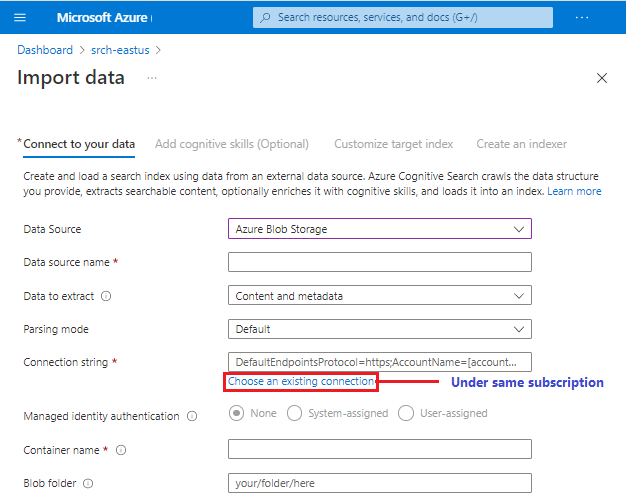
Nem minden előzetes verziójú adatforrás érhető el a varázslóban. Mivel az egyes adatforrások más módosításokat is bevezethetnek az alsóbb rétegben, az előzetes verziójú adatforrás csak akkor lesz hozzáadva az adatforrások listájához, ha teljes mértékben támogatja a varázsló összes funkcióját, például a képességkészlet definícióját és az indexséma következtetését.
Csak egyetlen táblából, adatbázisnézetből vagy azzal egyenértékű adatstruktúrából importálhat, de a struktúra hierarchikus vagy beágyazott alstruktúrákat is tartalmazhat. További információ: Összetett típusok modellezése.
Képességkészlet konfigurálása a varázslóban
A képességkészlet konfigurálása az adatforrás definíciója után történik, mivel az adatforrás típusa bizonyos beépített képességek rendelkezésre állását jelzi. Különösen, ha blobtárolóból indexel fájlokat, a fájlok elemzési módjának kiválasztása határozza meg, hogy elérhető-e a hangulatelemzés.
A varázsló hozzáadja a választott készségeket. Emellett további készségeket is hozzáad, amelyek szükségesek a sikeres eredmény eléréséhez. Ha például egy tudástárat ad meg, a varázsló hozzáad egy Shaper-képességet a kivetítések (vagy fizikai adatstruktúrák) támogatásához.
A készségkészletek nem kötelezőek, és az oldal alján található gomb segítségével továbbléphet, ha nem szeretné az AI-bővítést.
Indexséma konfigurálása a varázslóban
A varázslók mintát adnak az adatforrásból a mezők és a mezőtípus észleléséhez. Az adatforrástól függően a metaadatok indexelését szolgáló mezőket is kínálhat.
Mivel a mintavételezés pontatlan gyakorlat, tekintse át az indexet az alábbi szempontok alapján:
Pontos a mezőlista? Ha az adatforrás olyan mezőket tartalmaz, amelyeket nem vett fel a mintavételezés során, manuálisan hozzáadhat minden olyan új mezőt, amelyet a mintavételezés kihagyott, és eltávolíthat minden olyan mezőt, amely nem ad értéket a keresési élményhez, vagy amelyeket nem használ a szűrőkifejezésekben vagy a pontozási profilban.
Megfelelő az adattípus a bejövő adatokhoz? Az Azure AI Search támogatja az entitás adatmodell (EDM) adattípusokat. Az Azure SQL-adatok esetében van egy leképezési diagram , amely egyenértékű értékeket határoz meg. További háttér : Mezőleképezések és -átalakítások.
Van egy mezője, amely kulcsként szolgálhat? Ennek a mezőnek Edm.sztringnek kell lennie, és egyedileg kell azonosítania egy dokumentumot. A relációs adatok esetében előfordulhat, hogy az elsődleges kulcsra van leképezve. Blobok esetén ez lehet a
metadata-storage-path. Ha a mezőértékek szóközöket vagy szaggatott kötőjeleket tartalmaznak, az Indexelő létrehozása lépésben a Base-64 Kódolási kulcs beállítást be kell állítania a Speciális beállítások területen, hogy ne lehessen ellenőrizni ezeket a karaktereket.Attribútumok beállítása annak meghatározásához, hogy a mező hogyan legyen használva egy indexben.
Szánjon időt erre a lépésre, mert az attribútumok határozzák meg az index mezőinek fizikai kifejezését. Ha később, akár programozott módon is módosítani szeretné az attribútumokat, szinte mindig le kell dobnia és újra kell építenie az indexet. Az olyan alapvető attribútumok, mint a Kereshető és a Lekérdezhető , elhanyagolható hatással vannak a tárolásra. A szűrők engedélyezése és a javaslattevők használata növeli a tárolási követelményeket.
A kereshető funkció lehetővé teszi a teljes szöveges keresést. Minden szabad formátumú lekérdezésben vagy lekérdezési kifejezésben használt mezőnek rendelkeznie kell ezzel az attribútummal. A program invertált indexeket hoz létre minden olyan mezőhöz, amelyet kereshetőként jelöl meg.
A beolvasható a keresési eredményekben szereplő mezőt adja vissza. Minden olyan mezőnek, amely tartalmat biztosít a keresési eredményekhez, rendelkeznie kell ezzel az attribútummal. A mező beállítása nem befolyásolja jelentősen az index méretét.
A szűrhető lehetővé teszi a mező szűrési kifejezésekben való hivatkozását. A $filter kifejezésben használt összes mezőnek rendelkeznie kell ezzel az attribútummal. A szűrőkifejezések pontos egyezéseket jelentenek. Mivel a szöveges sztringek érintetlenek maradnak, több tárhelyre van szükség a szó szerinti tartalom tárolásához.
A facetable lehetővé teszi a mezőt a faceted navigációhoz. Csak a szűrhetőként megjelölt mezők jelölhetők facetableként.
A rendezhető mező lehetővé teszi a mező rendezését. Az $Orderby kifejezésben használt összes mezőnek rendelkeznie kell ezzel az attribútummal.
Szüksége van lexikális elemzésre? A kereshető Edm.string mezők esetében beállíthatja az elemzőt, ha nyelvvel bővített indexelést és lekérdezést szeretne.
Az alapértelmezett a Standard Lucene , de választhatja a Microsoft Angol nyelvet , ha a Microsoft elemzőjét szeretné használni a speciális lexikális feldolgozáshoz, például a szabálytalan főnév és az igealakok feloldásához. A portálon csak nyelvelemzők adhatók meg. Ha egyéni elemzőt vagy nem nyelvi elemzőt használ, például kulcsszót, mintát stb., akkor azt programozott módon kell létrehoznia. Az elemzőkről további információt a Nyelvelemzők hozzáadása című témakörben talál.
Szükség van a typeahead funkcióra automatikus kiegészítés vagy javasolt eredmények formájában? Jelölje be a Javaslattevő jelölőnégyzetet a típusfejléces lekérdezési javaslatok engedélyezéséhez és a kijelölt mezők automatikus kiegészítéséhez . A javaslattevők hozzáadják az indexben lévő tokenizált kifejezések számát, és így több tárhelyet használnak fel.
Indexelő konfigurálása a varázslóban
A varázsló utolsó oldala összegyűjti az indexelő konfigurációjának felhasználói bemeneteit. Megadhat ütemezést, és egyéb beállításokat is megadhat, amelyek az adatforrás típusától függően változnak.
A varázsló belsőleg a következő definíciókat is beállítja, amelyek csak a létrehozás után láthatók az indexelőben:
- mezőleképezések az adatforrás és az index között
- kimeneti mező leképezése a képességkimenet és az index között
Következő lépések
A varázsló előnyeinek és korlátainak megértéséhez a legjobb módszer, ha végiglépked rajta. Íme egy rövid útmutató, amely ismerteti az egyes lépéseket.