Megbízhatóság az Azure AI Searchben
Az Azure-ban a megbízhatóság rugalmasságot és rendelkezésre állást jelent, ha szolgáltatáskimaradás vagy -leállás áll fenn. Az Azure AI Searchben a megbízhatóság egyetlen szolgáltatáson belül vagy több keresési szolgáltatáson keresztül érhető el külön régiókban.
Egyetlen keresési szolgáltatás üzembe helyezése és vertikális felskálázás a magas rendelkezésre állás érdekében. Több replikát is hozzáadhat a magasabb indexelési és lekérdezési számítási feladatok kezeléséhez. Ha a keresési szolgáltatás támogatja a rendelkezésre állási zónákat, a replikák automatikusan ki lesznek építve különböző fizikai adatközpontokban a további rugalmasság érdekében.
Több keresési szolgáltatás üzembe helyezése különböző földrajzi régiókban. Az összes keresési számítási feladat teljes mértékben egyetlen, egyetlen földrajzi régióban futó szolgáltatásban található, de többszolgáltatásos forgatókönyv esetén lehetősége van a tartalom szinkronizálására, hogy az minden szolgáltatásban ugyanaz legyen. Terheléselosztási megoldást is beállíthat a kérések újraelosztására, vagy szolgáltatáskimaradás esetén a feladatátvételre.
Az üzletmenet folytonossága és a katasztrófákból való regionális szintű helyreállítás érdekében tervezze meg a régiók közötti topológiát, amely több azonos konfigurációval és tartalommal rendelkező keresési szolgáltatásból áll. Az egyéni szkript vagy kód biztosítja a "feladatátvételi" mechanizmust egy alternatív keresési szolgáltatásnak, ha hirtelen elérhetetlenné válik.
Magas szintű rendelkezésre állás
Az Azure AI Searchben a replikák az index másolatai. A keresési szolgáltatás legalább egy replikával van megbízva, és legfeljebb 12 replikával rendelkezhet. A replikák hozzáadása lehetővé teszi az Azure AI Search számára a gép újraindítását és karbantartását egy replikán, míg a lekérdezések végrehajtása más replikákon folytatódik.
A Microsoft legalább 99,9%-os rendelkezésre állást garantál az egyes keresési szolgáltatásokra, amennyiben a konfigurációk megfelelnek az alábbi feltételeknek:
Két replika a csak olvasható számítási feladatok (lekérdezések) magas rendelkezésre állása érdekében
Három vagy több replika az írható-olvasható számítási feladatok (lekérdezések és indexelés) magas rendelkezésre állása érdekében
A rendszer belső mechanizmusokkal rendelkezik a replika állapotának és partícióintegritásának monitorozására. Ha replikák és partíciók meghatározott kombinációját építi ki, a rendszer biztosítja a szolgáltatás kapacitásának szintjét.
Az ingyenes szinthez nem biztosítunk SLA-t. További információt az Azure AI Search SLA-jában talál.
Rendelkezésre állási zóna támogatása
A rendelkezésre állási zónák olyan Azure-platformképességek, amelyek egy régió adatközpontjait különböző fizikai helycsoportokra osztja, hogy magas rendelkezésre állást biztosítsanak ugyanazon a régión belül. Az Azure AI Searchben az egyes replikák a zónahozzárendelés egységei. A keresési szolgáltatás egy régión belül fut; replikái az adott régió különböző fizikai adatközpontjaiban (vagy zónáiban) futnak.
A rendelkezésre állási zónák akkor használatosak, ha két vagy több replikát ad hozzá a keresési szolgáltatáshoz. Minden replika egy másik rendelkezésre állási zónába kerül a régión belül. Ha több replika van, mint a keresési szolgáltatási régióban elérhető zónák, a replikák a lehető leg egyenletesebben vannak elosztva a zónák között. Nincs konkrét művelet az Ön részéről, kivéve, ha létrehoz egy keresési szolgáltatást egy olyan régióban, amely rendelkezésre állási zónákat biztosít, majd konfigurálja a szolgáltatást több replika használatára.
Előfeltételek
- A szolgáltatási szintnek standardnak vagy magasabbnak kell lennie.
- A szolgáltatásrégiónak olyan régióban kell lennie, amely rendelkezik elérhető zónákkal (a következő szakaszban).
- A konfigurációnak több replikát kell tartalmaznia: kettőt az írásvédett lekérdezési számítási feladatokhoz, hármat az indexelést tartalmazó írásvédett számítási feladatokhoz.
Supported regions
A rendelkezésre állási zónák támogatása az infrastruktúrától és a tárolástól függ. Jelenleg két, 2023 októberében bejelentett zóna rendelkezik elegendő tárterülettel, és nem biztosít rendelkezésre állási zónát az Azure AI Search számára:
- Izrael középső régiója
- Észak-Olaszország
Ellenkező esetben az Azure AI Search rendelkezésre állási zónái a következő régiókban támogatottak:
| Region | Bevezetés |
|---|---|
| Kelet-Ausztrália | 2021. január 30-i vagy újabb |
| Dél-Brazília | 2021. május 2- vagy újabb |
| Kanada középső régiója | 2021. január 30-i vagy újabb |
| Central India | 2022. január 20-i vagy újabb |
| Usa középső régiója | 2020. december 4-e vagy újabb |
| China North 3 | 2022. szeptember 7-e vagy újabb |
| East Asia | 2022. január 13-i vagy újabb |
| East US | 2021. január 27-i vagy újabb |
| USA 2. keleti régiója | 2021. január 30-i vagy újabb |
| France Central | 2020. október 23-i vagy újabb |
| Germany West Central | 2021. május 3- vagy újabb |
| Kelet-Japán | 2021. január 30-i vagy újabb |
| Korea Central | 2022. január 20-i vagy újabb |
| Észak-Európa | 2021. január 28-i vagy újabb |
| Norway East | 2022. január 20-i vagy újabb |
| Qatar Central | 2022. augusztus 25-i vagy újabb |
| South Africa North | 2022. szeptember 7-e vagy újabb |
| South Central US | 2021. április 30-i vagy újabb |
| Délkelet-Ázsia | 2021. január 31-i vagy újabb |
| Sweden Central | 2022. január 21-e vagy újabb |
| Switzerland North | 2022. szeptember 7-e vagy újabb |
| UAE North | 2022. szeptember 9-e vagy újabb |
| Egyesült Királyság déli régiója | 2021. január 30-i vagy újabb |
| USA-beli államigazgatás – Virginia | 2021. április 30-i vagy újabb |
| Nyugat-Európa | 2021. január 29-i vagy újabb |
| USA 2. nyugati régiója | 2021. január 30-i vagy újabb |
| USA 3. nyugati régiója | 2021. június 02- vagy újabb |
Megjegyzés:
A rendelkezésre állási zónák nem módosítják az Azure AI Search szolgáltatásiszint-szerződés feltételeit. A lekérdezés magas rendelkezésre állásához továbbra is három vagy több replikára van szükség.
Több szolgáltatás külön földrajzi régióban
A szolgáltatás redundanciára akkor van szükség, ha az üzemeltetési követelmények a következők:
Üzletmenet-folytonossági és vészhelyreállítási (BCDR) követelmények (az Azure AI Search nem biztosít azonnali feladatátvételt, ha kimaradás történik).
Gyors teljesítmény globálisan elosztott alkalmazásokhoz. Ha a lekérdezési és indexelési kérések a világ minden tájáról érkeznek, a gazdagép adatközpontjához legközelebb álló felhasználók gyorsabban teljesítenek. Ha több szolgáltatást hoz létre a felhasználók közvetlen közelében lévő régiókban, az az összes felhasználó teljesítményét kiegyenlítheti.
Ha két vagy több keresési szolgáltatásra van szüksége, a különböző régiókban való létrehozásuk megfelelhet a folytonosságra és helyreállításra vonatkozó alkalmazáskövetelményeknek, és gyorsabb válaszidőt biztosít a globális felhasználói bázis számára.
Az Azure AI Search nem biztosít automatizált módszert a keresési indexek földrajzi régiók közötti replikálására, de vannak olyan technikák, amelyekkel a folyamat egyszerűen implementálható és kezelhető. Ezeket a technikákat a következő néhány szakaszban ismertetjük.
A földrajzilag elosztott keresési szolgáltatások célja, hogy két vagy több index legyen elérhető két vagy több régióban, ahol a felhasználót az Azure AI-Search szolgáltatás irányítják, amely a legalacsonyabb késést biztosítja:
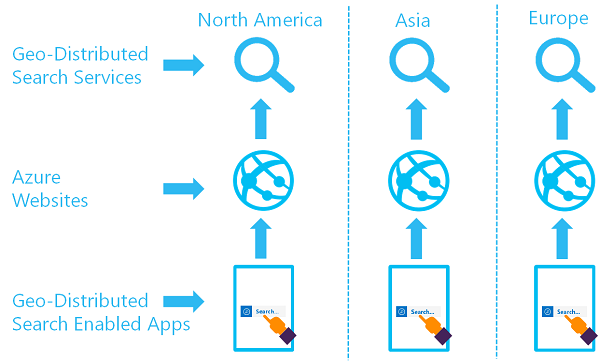
Ezt az architektúrát több szolgáltatás létrehozásával és egy adatszinkronizálási stratégia kialakításával valósíthatja meg. Opcionálisan egy olyan erőforrást is megadhat, mint az Azure Traffic Manager az útválasztási kérelmekhez.
Tipp.
Ha segítségre van szüksége több keresési szolgáltatás több régióban történő üzembe helyezéséhez, tekintse meg ezt a Bicep-mintát a GitHubon , amely egy teljes körűen konfigurált, többrégiós keresési megoldást helyez üzembe. A minta két lehetőséget kínál az indexszinkronizálásra, és a Traffic Manager használatával kérheti az átirányítást.
Adatok szinkronizálása több szolgáltatás között
Két lehetőség van két vagy több különböző keresési szolgáltatás szinkronban tartására:
- Tartalomfrissítések lekérése keresési indexbe indexelő használatával.
- Tartalom leküldése indexbe a Dokumentumok hozzáadása vagy frissítése (REST) API vagy az Azure SDK-val egyenértékű API használatával.
Bármelyik beállítás konfigurálásához javasoljuk, hogy használja a minta Bicep-szkriptet az azure-search-multiple-region adattárban, amely a régiókhoz és az indexelési stratégiákhoz van módosítva.
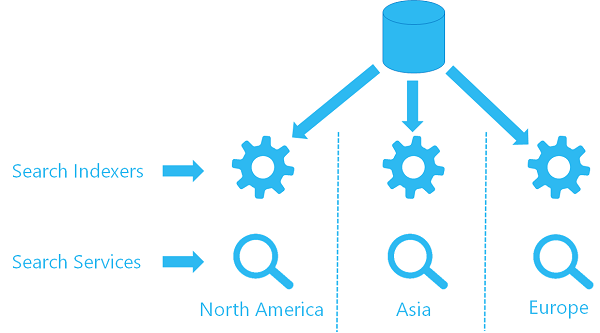
1. lehetőség: Indexelők használata több szolgáltatás tartalmának frissítéséhez
Ha már használ indexelőt egy szolgáltatásban, konfigurálhat egy második indexelőt egy második szolgáltatásban ugyanarra az adatforrás-objektumra, amely ugyanabból a helyről kéri le az adatokat. Az egyes régiókban minden szolgáltatás saját indexelővel és célindexkel rendelkezik (a keresési index nincs megosztva, ami azt jelenti, hogy minden index saját másolatot készít az adatokról), de mindegyik indexelő ugyanarra az adatforrásra hivatkozik.
Íme egy magas szintű vizualizáció az architektúra megjelenéséről.
2. lehetőség: REST API-k használata több szolgáltatás tartalomfrissítéseinek leküldéséhez
Ha az Azure AI Search REST API-t használja tartalom leküldésére a keresési indexbe, a különböző keresési szolgáltatásokat szinkronban tarthatja, ha módosításokat küld az összes keresési szolgáltatásnak, amikor frissítésre van szükség. A kódban ügyeljen arra, hogy kezelje azokat az eseteket, amikor egy keresési szolgáltatás frissítése sikertelen, de más keresési szolgáltatások esetében sikeres.
Lekérdezési kérelmek feladatátvétele vagy átirányítása
Ha a kérés szintjén redundanciára van szüksége, az Azure számos terheléselosztási lehetőséget kínál:
- Az Azure Traffic Managerrel a kéréseket több földrajzi helyen található webhelyre irányíthatja, amelyeket aztán több keresési szolgáltatás is támogatott.
- Application Gateway, amely az alkalmazásréteg egy régiójában lévő kiszolgálók közötti terheléselosztásra szolgál.
- Az Azure Front Door a webes forgalom globális útválasztásának optimalizálására és a globális feladatátvétel biztosítására szolgál.
Néhány szempont, amit szem előtt kell tartani a terheléselosztási lehetőségek kiértékelésekor:
A keresés egy háttérszolgáltatás, amely fogadja az ügyféltől érkező lekérdezési és indexelési kéréseket.
Az ügyféltől a keresési szolgáltatáshoz érkező kéréseket hitelesíteni kell. A keresési műveletekhez való hozzáféréshez a hívónak szerepköralapú engedélyekkel kell rendelkeznie, vagy meg kell adnia egy API-kulcsot a kéréshez.
A szolgáltatásvégpontok alapértelmezés szerint nyilvános internetkapcsolaton keresztül érhetők el. Ha privát végpontot állít be egy virtuális hálózaton belülről származó ügyfélkapcsolatokhoz, használja az Application Gatewayt.
Az Azure AI Search fogadja a
<your-search-service-name>.search.windows.netvégpontnak címzett kéréseket. Ha ugyanazt a végpontot egy másik DNS-névvel éri el a gazdagép fejlécében, például egy CNAME-t, a rendszer elutasítja a kérést.
Az Azure AI Search többrégiós üzembe helyezési mintát biztosít, amely az Azure Traffic Managert használja a kérés átirányításához, ha az elsődleges végpont meghiúsul. Ez a megoldás akkor hasznos, ha olyan keresőbarát ügyfélhez irányít, amely csak ugyanabban a régióban hívja meg a keresési szolgáltatást.
Az Azure Traffic Managert elsősorban a különböző végpontok közötti hálózati forgalom adott útválasztási módszerek (például prioritás, teljesítmény vagy földrajzi hely) alapján történő útválasztására használják. A DNS szintjén működik, hogy a bejövő kéréseket a megfelelő végpontra irányítsa. Ha a Traffic Manager által karbantartott végpont elkezdi elutasítani a kéréseket, a forgalom egy másik végpontra lesz irányítva.
A Traffic Manager nem biztosít végpontot az Azure AI Search közvetlen kapcsolatához, ami azt jelenti, hogy nem helyezhet közvetlenül a Traffic Manager mögé keresőszolgáltatást. Ehelyett a feltételezés az, hogy a kérések a Traffic Managerbe, majd egy kereséssel kompatibilis webes ügyfélbe, végül pedig a háttérrendszeren található keresési szolgáltatásba kerülnek. Az ügyfél és a szolgáltatás ugyanabban a régióban található. Ha egy keresési szolgáltatás leáll, a keresési ügyfél meghibásodik, és a Traffic Manager átirányítja a fennmaradó ügyfélhez.
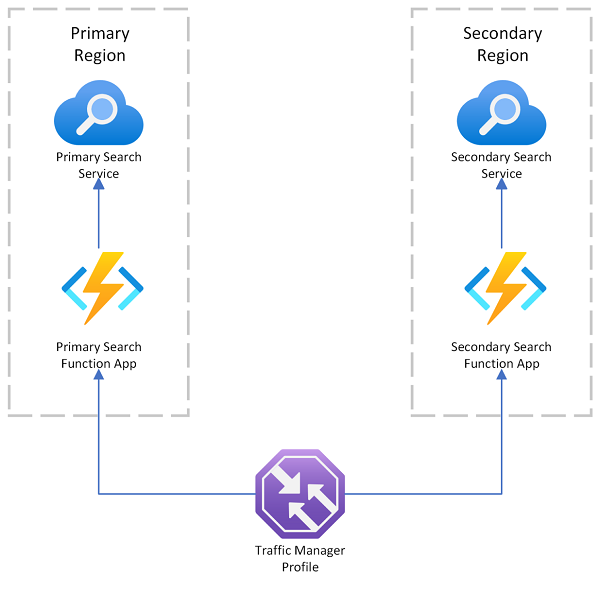
Tudnivalók a többrégiós üzemelő példányok adattárolásáról
Ha több keresési szolgáltatást helyez üzembe különböző földrajzi régiókban, a tartalom abban a régióban lesz tárolva, amelyet az egyes keresési szolgáltatásokhoz választott.
Az Azure AI Search nem tárol adatokat a megadott régión kívül az Ön engedélye nélkül. Az engedélyezés implicit, ha Azure Storage-erőforrásba írt funkciókat használ: bővítési gyorsítótár, hibakeresési munkamenet, tudástár. A tárfiók minden esetben az Ön által megadott tárfiók, a választott régióban.
Megjegyzés:
Ha a tárfiók és a keresési szolgáltatás ugyanabban a régióban található, a keresés és a tárolás közötti hálózati forgalom egy privát IP-címet használ, és a Microsoft gerinchálózatán keresztül történik. Mivel magánhálózati IP-címeket használ, nem konfigurálhat IP-tűzfalakat vagy privát végpontokat a hálózati biztonság érdekében. Ehelyett használja a megbízható szolgáltatáskivételt alternatívaként, ha mindkét szolgáltatás ugyanabban a régióban található.
Tudnivalók a szolgáltatáskimaradásokról és a katasztrofális eseményekről
A szolgáltatásiszint-szerződésben (SLA) leírtaknak megfelelően a Microsoft garantálja az index-lekérdezési kérelmek magas rendelkezésre állását, ha egy Azure AI-Search szolgáltatás-példány két vagy több replikával van konfigurálva, és indexfrissítési kéréseket, ha egy Azure AI-Search szolgáltatás-példány három vagy több replikával van konfigurálva. A vészhelyreállításhoz azonban nincs beépített mechanizmus. Ha a Microsoft irányításán kívüli katasztrofális hiba esetén folyamatos szolgáltatásra van szükség, javasoljuk, hogy egy másik régióban építsen ki egy második szolgáltatást, és implementáljon egy georeplikációs stratégiát annak érdekében, hogy az indexek teljes mértékben redundánsak legyenek az összes szolgáltatásban.
Azok az ügyfelek, akik indexelőket használnak az indexek feltöltésére és frissítésére, geospecifikus indexelőkkel kezelhetik a vészhelyreállítást, amelyek ugyanabból az adatforrásból kérnek le adatokat. A georedundancia eléréséhez a különböző régiókban két szolgáltatás, amelyek mindegyike egy indexelőt futtat, indexelheti ugyanazt az adatforrást. Ha georedundáns adatforrásokból indexel, ne feledje, hogy az Azure AI Search-indexelők csak növekményes indexelést végezhetnek (új, módosított vagy törölt dokumentumok frissítéseinek egyesítése) az elsődleges replikákból. Feladatátvételi esemény esetén mindenképpen átirányítsa az indexelőt az új elsődleges replikára.
Ha nem használ indexelőket, az alkalmazás kódját használva küldhet le objektumokat és adatokat különböző keresési szolgáltatásokba párhuzamosan. További információ: Adatok szinkronizálása több szolgáltatás között.
Alternatív megoldások biztonsági mentése és visszaállítása
Az adatréteg üzletmenet-folytonossági stratégiája általában tartalmaz egy visszaállítási biztonsági mentési lépést. Mivel az Azure AI Search nem elsődleges adattárolási megoldás, a Microsoft nem biztosít formális mechanizmust az önkiszolgáló biztonsági mentéshez és visszaállításhoz. Ebben az Azure AI Search .NET-mintaadattárban azonban használhatja az index-biztonsági mentési-visszaállítási mintakódot az indexdefiníció és a pillanatkép JSON-fájlok sorozatára való biztonsági mentéséhez, majd ezeket a fájlokat használva szükség esetén visszaállíthatja az indexet. Ez az eszköz az indexeket a szolgáltatási szintek között is áthelyezheti.
Ellenkező esetben az index létrehozásához és feltöltéséhez használt alkalmazáskód a de facto visszaállítási lehetőség, ha véletlenül töröl egy indexet. Az index újraépítéséhez törölnie kell (feltéve, hogy létezik), újra létre kell hoznia az indexet a szolgáltatásban, és újra kell betöltenie az adatokat az elsődleges adattárból.
További lépések
- Tekintse át a szolgáltatási korlátokat , és tudjon meg többet az egyes tarifacsomagokról és szolgáltatási korlátokról.
- Tekintse át a kapacitás tervét, hogy többet tudjon meg a partíció- és replikakombinációkról.
- Esettanulmány áttekintése : Összetett AI-forgatókönyvek támogatása a Cognitive Search használatával további konfigurációs útmutatásért.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: