Az Azure Service Fabric monitorozása
Ez a cikk a következőket ismerteti:
- A szolgáltatáshoz gyűjthető monitorozási adatok típusai.
- Az adatok elemzésének módjai.
Feljegyzés
Ha már ismeri ezt a szolgáltatást és/vagy az Azure Monitort, és csak tudni szeretné, hogyan elemezheti a figyelési adatokat, tekintse meg a cikk végén található Elemzés szakaszt.
Ha olyan kritikus alkalmazásokkal és üzleti folyamatokkal rendelkezik, amelyek Az Azure-erőforrásokra támaszkodnak, figyelnie kell és riasztásokat kell kapnia a rendszeréről. Az Azure Monitor szolgáltatás a rendszer minden összetevőjéből gyűjti és összesíti a metrikákat és naplókat. Az Azure Monitor áttekintést nyújt a rendelkezésre állásról, a teljesítményről és a rugalmasságról, és értesíti Önt a problémákról. A monitorozási adatok beállításához és megtekintéséhez használhatja az Azure Portalt, a PowerShellt, az Azure CLI-t, a REST API-t vagy az ügyfélkódtárakat.
- Az Azure Monitorral kapcsolatos további információkért tekintse meg az Azure Monitor áttekintését.
- Az Azure-erőforrások általános monitorozásával kapcsolatos további információkért lásd : Azure-erőforrások monitorozása az Azure Monitorral.
Azure Service Fabric monitorozása
Az Azure Service Fabric a következő, monitorozásra használható rétegeket tartalmazza:
- Alkalmazásfigyelés: A csomópontokon futó alkalmazások . Az alkalmazásokat application Insights-kulccsal, SDK-val, EventStore-nal vagy ASP.NET Core-naplózással figyelheti.
- Platform (fürt) monitorozása: Ügyfélmetrikák, naplók és események a platform- vagy fürtcsomópontokhoz, beleértve a tárolómetrikát is. A metrikák és a naplók linuxos vagy Windows-csomópontok esetén eltérőek.
- Infrastruktúra (teljesítmény) monitorozása: a szolgáltatásinfrastruktúra Szolgáltatásállapot és teljesítményszámlálói.
Megfigyelheti az alkalmazások használatát, a Service Fabric platform által végrehajtott műveleteket, az erőforrás-kihasználtságot teljesítményszámlálókkal, valamint a fürt általános állapotát. Az Azure Monitor naplói és az Application Insights beépített integrációt kínálnak a Service Fabrictel.
- Az ajánlott eljárásokról az Azure Service Fabric monitorozási és diagnosztikai ajánlott eljárásai című témakörben olvashat.
- A Service Fabric-események és állapotjelentések megtekintését, az EventStore API-k lekérdezését és a teljesítményszámlálók monitorozását bemutató oktatóanyagért lásd : Service Fabric-fürt monitorozása az Azure-ban.
- Ha tudni szeretné, hogyan konfigurálhatja az Azure Monitor-naplókat a Service Fabricen vezénylő Windows-tárolók figyelésére, tekintse meg az oktatóanyagot: Windows-tárolók monitorozása a Service Fabricen Azure Monitor-naplók használatával.
Service Fabric Explorer
A Service Fabric Explorer egy windowsos, macOS és Linux rendszerű asztali alkalmazás, amely nyílt forráskódú eszköz az Azure Service Fabric-fürtök vizsgálatára és kezelésére. Az automatizálás engedélyezéséhez a Service Fabric Exploreren keresztül elvégezhető összes művelet elvégezhető PowerShell-lel vagy REST API-val is.
Alkalmazásmonitorozás
Az alkalmazásfigyelés nyomon követi az alkalmazás funkcióinak és összetevőinek használatát. Figyelnie kell az alkalmazásokat, hogy a felhasználókat érintő problémákat is megfigyelje. Az alkalmazásfigyelés felelőssége az alkalmazás és szolgáltatásai fejlesztésének felhasználóira hárul, mivel ez egyedi az alkalmazás üzleti logikája szerint. Az alkalmazások monitorozása az alábbi esetekben lehet hasznos:
- Mekkora forgalmat tapasztal az alkalmazásom? – Skáláznia kell a szolgáltatásokat a felhasználói igényeknek megfelelően, vagy kezelnie kell az alkalmazás esetleges szűk keresztmetszeteit?
- Sikeresek és nyomon követhetők a szolgáltatásközi hívások?
- Milyen műveleteket hajtanak végre az alkalmazás felhasználói? – A telemetriai adatok gyűjtése segíthet a jövőbeli funkciók fejlesztésében és az alkalmazáshibák jobb diagnosztikában
- Az alkalmazás nem kezelt kivételeket ad ki?
- Mi történik a tárolókon belül futó szolgáltatásokban?
Az alkalmazásfigyelésben az a nagyszerű, hogy a fejlesztők bármilyen eszközt és keretrendszert használhatnak, mivel az az alkalmazás környezetében található! Az Azure Monitor Application Insights alkalmazásmonitorozási megoldásával kapcsolatos további információk az Application Insights eseményelemzésében.
A .NET-alkalmazásokhoz is van egy oktatóanyag, amely bemutatja, hogyan állíthatja be ezt a beállítást. Ez az oktatóanyag bemutatja, hogyan telepítheti a megfelelő eszközöket, hogyan írhat egyéni telemetriát az alkalmazásba, és hogyan tekintheti meg az alkalmazásdiagnosztikát és a telemetriát az Azure Portalon.
Alkalmazásnaplózás
A kód rendszerezésével nemcsak a felhasználókra vonatkozó megállapításokat nyerhet, hanem az egyetlen módja annak is, hogy megtudja, van-e hiba az alkalmazásban, és diagnosztizálhatja, hogy mit kell kijavítani. Bár technikailag lehetséges egy hibakeresőt egy éles szolgáltatáshoz csatlakoztatni, ez nem gyakori eljárás. Ezért fontos a részletes rendszerállapot-adatok megadása.
Egyes termékek automatikusan elvégzik a kódot. Bár ezek a megoldások jól működnek, a manuális kialakítás szinte mindig az üzleti logikára jellemző. Végül elegendő információval kell rendelkeznie az alkalmazás kriminalisztikai hibakereséséhez. A Service Fabric-alkalmazások bármilyen naplózási keretrendszerrel rendszerezhetők. Ez a szakasz a kód rendszerezésének néhány különböző megközelítését ismerteti, és azt, hogy mikor érdemes egyik megközelítést választani a másikhoz.
Application Insights SDK: Az Application Insights gazdag integrációval rendelkezik a Service Fabrictel. A felhasználók hozzáadhatják az AI Service Fabric nuget-csomagokat, és fogadhatják az Azure Portalon létrehozott és összegyűjtött adatokat és naplókat. Emellett a felhasználókat arra is ösztönzik, hogy saját telemetriát adjanak hozzá az alkalmazásuk diagnosztizálásához és hibakereséséhez, és nyomon követhessék, hogy az alkalmazás mely szolgáltatásait és részeit használják a leggyakrabban. Az SDK TelemetryClient osztálya számos lehetőséget kínál az alkalmazások telemetriájának nyomon követésére. További információ: Eseményelemzés és vizualizáció az Application Insights használatával.
A .NET-alkalmazások monitorozására és diagnosztizálására vonatkozó oktatóanyagunkból megtudhatja, hogyan hozhat létre és adhat hozzá alkalmazáselemzéseket az alkalmazáshoz.
EventSource: Amikor Service Fabric-megoldást hoz létre egy sablonból a Visual Studióban, létrejön egy EventSource-származtatott osztály (ServiceEventSource vagy ActorEventSource). Létrejön egy sablon, amelyben eseményeket adhat hozzá az alkalmazáshoz vagy szolgáltatáshoz. Az EventSource nevének egyedinek kell lennie, és át kell neveznie a MyCompany-solution-project<><> alapértelmezett sablonsztringből. Ha több EventSource-definíció ugyanazt a nevet használja, futásidőben problémát okoz. Minden definiált eseménynek egyedi azonosítóval kell rendelkeznie. Ha egy azonosító nem egyedi, futásidejű hiba történik. Egyes szervezetek előre hozzárendelnek értéktartományokat az azonosítókhoz, hogy elkerüljék a különálló fejlesztői csapatok közötti ütközéseket. További információ : Vance blogja vagy az MSDN dokumentációja.
ASP.NET Alapszintű naplózás: Fontos, hogy gondosan megtervezze a kód kialakításának módját. A megfelelő kialakítási terv segítségével elkerülheti a kódbázis esetleges destabilizálását, majd újra kell alakítania a kódot. A kockázat csökkentése érdekében választhat olyan eszközkódtárat, mint a Microsoft.Extensions.Logging, amely a Microsoft ASP.NET Core része. ASP.NET Core rendelkezik egy ILogger-felülettel , amelyet a választott szolgáltatóval használhat, miközben minimalizálja a meglévő kódra gyakorolt hatást. A kódot windowsos és linuxos ASP.NET Core-ban, valamint a teljes .NET-keretrendszer használhatja, így a rendszerállapot-kód szabványosított.
A javaslatok használatára vonatkozó példákért lásd a Naplózás hozzáadása a Service Fabric-alkalmazáshoz című témakört.
Platform (fürt) monitorozása
A felhasználó szabályozza, hogy milyen telemetriai adatok származnak az alkalmazásból, mivel egy felhasználó maga írja a kódot, de mi a helyzet a Service Fabric platform diagnosztikai adataival? A Service Fabric egyik célja, hogy az alkalmazásokat ellenállóvá tegye a hardverhibákkal szemben. Ez a cél úgy érhető el, hogy a platform rendszerszolgáltatásai képesek észlelni az infrastruktúrával kapcsolatos problémákat és gyorsan feladatátvételi számítási feladatokat a fürt más csomópontjaira. De ebben a konkrét esetben mi történik, ha maguk a rendszerszolgáltatások problémákat tapasztalnak? Vagy ha számítási feladat üzembe helyezésére vagy áthelyezésére próbál meg kísérletet tenni, a szolgáltatások elhelyezésére vonatkozó szabályok sérülnek? A Service Fabric diagnosztikát biztosít ezekhez és egyebekhez, hogy biztosan értesüljön a fürtben zajló tevékenységekről. A fürtfigyelés néhány példaforgatókönyve:
A platform (fürt) monitorozásával kapcsolatos további információkért lásd : A fürt figyelése.
Service Fabric-események
A Service Fabric átfogó diagnosztikai eseményeket biztosít a dobozból, amelyeket az EventStore-on vagy a platform által elérhető operatív eseménycsatornán keresztül érhet el. Ezek a Service Fabric-események a platform által különböző entitásokon, például csomópontokon, alkalmazásokon, szolgáltatásokon és partíciókon végzett műveleteket szemléltetik. Ugyanezek az események windowsos és linuxos fürtökön is elérhetők.
Service Fabric-eseménycsatornák: Windows rendszeren a Service Fabric-események egyetlen ETW-szolgáltatótól érhetők el, és az operatív és az adat- és üzenetkezelési csatornák közötti választáshoz szükséges releváns
logLevelKeywordFiltershalmazt használják. Így választjuk el a kimenő Service Fabric-eseményeket, amelyekre szükség esetén szűrni kell. Linux rendszeren a Service Fabric-események ltTngen keresztül érkeznek, és egy Storage-táblába kerülnek, ahonnan szükség szerint szűrhetők. Ezek a csatornák válogatott, strukturált eseményeket tartalmaznak, amelyek a fürt állapotának jobb megértésére használhatók. A diagnosztika alapértelmezés szerint engedélyezve van a fürtlétrehozáskor, amely létrehoz egy Azure Storage-táblát, amelyben a csatornák eseményei a jövőben lekérdezésre kerülnek.Az EventStore egy olyan funkció, amely a Service Fabric-platform eseményeit jeleníti meg a Service Fabric Explorerben, és programozott módon a Service Fabric ügyféloldali kódtár REST API-jával. Pillanatképet láthat arról, hogy mi történik a fürtben az egyes csomópontok, szolgáltatások és alkalmazások és lekérdezések esetében az esemény időpontja alapján. Az EventStore API-k csak az Azure-ban futó Windows-fürtökhöz érhetők el. Windows rendszerű gépeken ezek az események be vannak osztva az eseménynaplóba, így láthatja a Service Fabric-eseményeket a Eseménynapló.
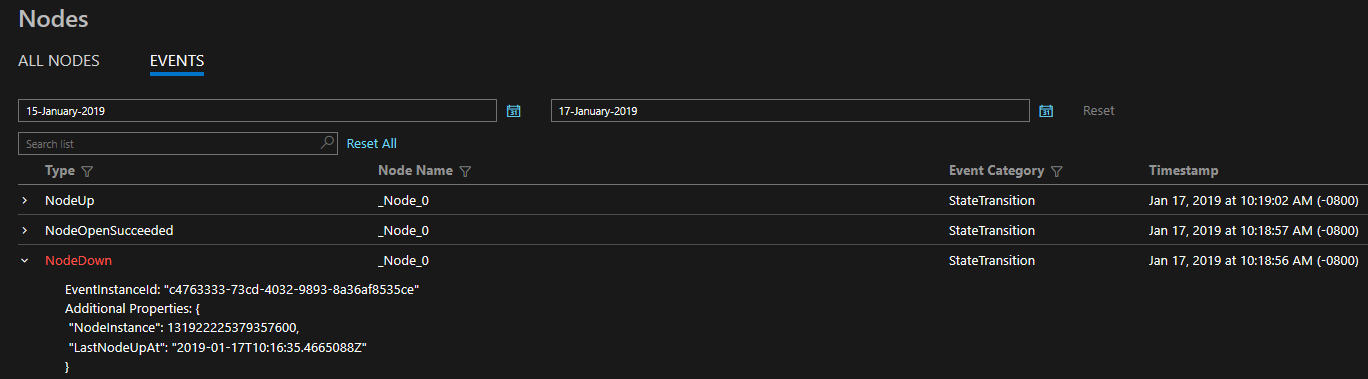
A megadott diagnosztikák a dobozon kívüli események átfogó készlete formájában vannak megadva. Ezek a Service Fabric-események a platform által különböző entitásokon, például csomópontokon, alkalmazásokon, szolgáltatásokon, partíciókon végzett műveleteket szemléltetik. A fenti utolsó forgatókönyvben, ha egy csomópont leállna, a platform eseményt NodeDown bocsátana ki, és a választott monitorozási eszköz azonnal értesítené Önt. Egyéb gyakori példák lehetnek például ApplicationUpgradeRollbackStarted a feladatátvétel során vagy PartitionReconfigured közben. Ugyanezek az események windowsos és linuxos fürtökön is elérhetők.
Az eseményeket windowsos és linuxos standard csatornákon keresztül küldi el a rendszer, és bármely olyan monitorozási eszköz képes olvasni, amely támogatja ezeket. Az Azure Monitor-megoldás az Azure Monitor-naplók. Nyugodtan olvassa el az Azure Monitor-naplók integrációját, amely tartalmaz egy egyéni működési irányítópultot a fürthöz, valamint néhány minta lekérdezést, amelyekből riasztásokat hozhat létre. További fürtfigyelési fogalmak érhetők el platformszintű esemény- és naplógeneráláskor.
Állapotfigyelés
A Service Fabric platform tartalmaz egy állapotmodellt, amely bővíthető állapotjelentést biztosít egy fürt entitásainak állapotáról. Minden csomópont, alkalmazás, szolgáltatás, partíció, replika vagy példány folyamatosan frissíthető állapottal rendelkezik. Az állapot lehet "OK", "Figyelmeztetés" vagy "Hiba". A Service Fabric-eseményeket úgy tekintheti, mint a fürt által a különböző entitásokra és az állapotra vonatkozó igéket, mint az egyes entitások melléknevét. Minden alkalommal, amikor egy adott entitás állapota áttűn, egy esemény is ki lesz bocsátva. Így lekérdezéseket és riasztásokat állíthat be az állapoteseményekhez a választott monitorozási eszközben, ugyanúgy, mint bármely más esemény esetében.
Emellett lehetővé tesszük, hogy a felhasználók felülbírálják az entitások állapotát. Ha az alkalmazás frissítésen megy keresztül, és az érvényesítési tesztek sikertelenek, az Állapot API-val írhat a Service Fabric Health szolgáltatásba, hogy jelezze, hogy az alkalmazás már nem megfelelő, és a Service Fabric automatikusan visszaállítja a frissítést! Az állapotmodellről bővebben a Service Fabric állapotmonitorozásának bemutatása
Watchdogs
A watchdog általában egy különálló szolgáltatás, amely figyeli az állapotot és a terhelést a szolgáltatások között, pingeli a végpontokat, és váratlan állapoteseményeket jelent a fürtben. Ez segíthet megelőzni azokat a hibákat, amelyek nem csak egyetlen szolgáltatás teljesítménye alapján észlelhetők. A watchdogok olyan kódot is üzemeltetnek, amely olyan javító műveleteket hajt végre, amelyek nem igényelnek felhasználói beavatkozást, például a naplófájlok bizonyos időközönként történő megtisztítása a tárolóban. Ha teljesen implementált, nyílt forráskód SF watchdog szolgáltatást, amely egy könnyen használható watchdog bővíthetőségi modellt tartalmaz, és amely Windows és Linux fürtökön is fut, tekintse meg a FabricObserver projektet. A FabricObserver éles üzemre kész szoftver. Javasoljuk, hogy telepítse a FabricObservert a teszt- és éles fürtökre, és bővítse ki az igényeinek megfelelően a beépülő modulmodellen keresztül, vagy elágaztatással és saját beépített megfigyelők írásával. Az előbbi (beépülő modulok) az ajánlott megközelítés.
Infrastruktúra (teljesítmény) monitorozása
Most, hogy áttekintettük az alkalmazás és a platform diagnosztikáit, honnan tudjuk, hogy a hardver a várt módon működik? A mögöttes infrastruktúra monitorozása kulcsfontosságú része a fürt állapotának és az erőforrás-kihasználtságnak. A rendszer teljesítményének mérése számos tényezőtől függ, amelyek a számítási feladatoktól függően szubjektívek lehetnek. Ezeket a tényezőket általában teljesítményszámlálókkal mérik. Ezek a teljesítményszámlálók számos forrásból származhatnak, beleértve az operációs rendszert, a .NET-keretrendszert vagy magát a Service Fabric-platformot. Egyes forgatókönyvek, amelyekben hasznosak lennének,
- Hatékonyan használom a hardveremet? Szeretné használni a hardvert 90%-os processzor- vagy 10%-os cpu-n. Ez hasznos lehet a fürt skálázása vagy az alkalmazás folyamatainak optimalizálása során.
- Előre jelezhetem az infrastruktúra problémáit proaktív módon? - számos problémát megelőz a teljesítmény hirtelen változása (csökkenése), így a teljesítményszámlálók, például a hálózati I/O és a CPU-kihasználtság használatával proaktív módon jelezheti előre és diagnosztizálhatja a problémákat.
Az infrastruktúra szintjén összegyűjtendő teljesítményszámlálók listája a Teljesítménymetrikákban található.
Az Azure Monitor-naplók a fürtszintű események monitorozásához ajánlottak. Miután konfigurálta a Log Analytics-ügynököt a munkaterülettel, a következőket gyűjtheti:
- Teljesítménymetrikák, például processzorkihasználtság.
- .NET-teljesítményszámlálók, például folyamatszintű processzorkihasználtság.
- Service Fabric-teljesítményszámlálók, például egy megbízható szolgáltatás kivételeinek száma.
- Tárolómetrikák, például processzorkihasználtság.
Erőforrástípusok
Az Azure az erőforrástípusok és azonosítók fogalmát használja az előfizetések minden elemének azonosítására. Az erőforrástípusok az Azure-ban futó összes erőforrás erőforrásazonosítóinak is részét képezik. A virtuális gépek egyik erőforrástípusa például az Microsoft.Compute/virtualMachines. A szolgáltatások és a hozzájuk kapcsolódó erőforrástípusok listáját az Erőforrás-szolgáltatók című témakörben találja.
Az Azure Monitor hasonlóan rendszerezi az alapvető monitorozási adatokat metrikákba és naplókba az erőforrástípusok, más néven névterek alapján. Különböző metrikák és naplók érhetők el a különböző erőforrástípusokhoz. Előfordulhat, hogy a szolgáltatás több erőforrástípushoz is társítva van.
Az Azure Service Fabric erőforrástípusairól további információt a Service Fabric monitorozási adatreferenciájában talál.
Adattárolás
Azure Monitor esetén:
- A metrikák adatait az Azure Monitor metrikák adatbázisa tárolja.
- A naplóadatok tárolása az Azure Monitor naplók tárolójában történik. A Log Analytics egy eszköz az Azure Portalon, amely le tudja kérdezni ezt az áruházat.
- Az Azure-tevékenységnapló egy külön tároló, amelynek saját felülete van az Azure Portalon.
A metrikák és a tevékenységnaplók adatait igény szerint átirányíthatja az Azure Monitor-naplók tárolójába. Ezután a Log Analytics használatával lekérdezheti az adatokat, és összehasonlíthatja azokat más naplóadatokkal.
Számos szolgáltatás diagnosztikai beállításokkal küldhet metrikákat és naplóadatokat az Azure Monitoron kívüli más tárolóhelyekre. Ilyenek például az Azure Storage, a üzemeltetett partnerrendszerek és a nem Azure-beli partnerrendszerek az Event Hubs használatával.
Az Azure Monitor adatainak tárolásáról az Azure Monitor adatplatformja nyújt részletes tájékoztatást.
Az Azure Monitor platformmetrikái
Az Azure Monitor számos szolgáltatáshoz biztosít platformmetrikát. Az Azure Monitor összes erőforrásához gyűjthető metrikák listájáért tekintse meg az Azure Monitor támogatott metrikáit.
Ez a szolgáltatás nem gyűjt platformmetrikát.
Nem Azure Monitor-alapú metrikák
Ez a szolgáltatás más metrikákat is biztosít, amelyek nem szerepelnek az Azure Monitor metrikák adatbázisában.
Vendég operációsrendszer-metrikák
A Service Fabric-fürtcsomópontokon futó vendég operációs rendszer (OS) metrikáit egy vagy több, a vendég operációs rendszeren futó ügynökön keresztül kell gyűjteni. A vendég operációs rendszer metrikái olyan teljesítményszámlálókat tartalmaznak, amelyek nyomon követik a vendég CPU-százalékos vagy memóriahasználatát, és mindkettőt gyakran használják automatikus skálázáshoz vagy riasztáshoz.
Ajánlott eljárás az Azure Monitor-ügynök használata és konfigurálása a vendég operációs rendszer teljesítménymetrikáinak az egyéni metrikák API-jának az Azure Monitor metrikák adatbázisába való küldéséhez. A vendég operációsrendszer-metrikákat ugyanazzal az ügynökkel küldheti el az Azure Monitor-naplókba. Ezután a Log Analytics használatával lekérdezheti ezeket a metrikákat és naplókat.
Feljegyzés
Az Azure Monitor-ügynök lecseréli az Azure Diagnostics-bővítményt és a Log Analytics-ügynököt a vendég operációs rendszer útválasztásához. További információ: Az Azure Monitor-ügynökök áttekintése.
Azure Monitor-erőforrásnaplók
Az erőforrásnaplók betekintést nyújtanak az Azure-erőforrások által végrehajtott műveletekbe. A naplók automatikusan jönnek létre, de a mentésükhöz vagy lekérdezésükhöz az Azure Monitor-naplókba kell őket irányítani. A naplók kategóriákba vannak rendezve. Egy adott névtér több erőforrásnapló-kategóriával is rendelkezhet, amelyeket összegyűjthet.
Ez a szolgáltatás nem gyűjt erőforrásnaplókat, de az Azure-erőforrások adatainak monitorozása során információkat találhat róluk.
Service Fabric-naplók és események
A Service Fabric a következő naplókat gyűjtheti:
- Windows-fürtök esetén beállíthatja a fürtfigyelést a Diagnostics Agent és az Azure Monitor naplóival.
- Linux-fürtök esetén az Azure Monitor Logs az Azure platform- és infrastruktúra-monitorozáshoz is ajánlott eszköz. A Linux-platform diagnosztikához eltérő konfiguráció szükséges. További információ: Service Fabric Linux-fürtesemények a Syslogban.
- Az Azure Monitor-ügynök konfigurálható úgy, hogy vendég operációsrendszer-naplókat küldjön az Azure Monitor-naplókba, ahol a Log Analytics használatával lekérdezheti őket.
- A Service Fabric-tárolónaplókat stdout vagy stderr fájlba is írhatja, hogy azok elérhetők legyenek az Azure Monitor-naplókban.
- Beállíthatja az Azure Monitor-naplók tárolómonitorozási megoldását a tárolóesemények megtekintéséhez.
Egyéb naplózási megoldások
Bár az általunk javasolt két megoldás, az Azure Monitor-naplók és az Application Insights beépített integrációval rendelkeznek a Service Fabrictel, számos eseményt ETW-szolgáltatók írnak ki, és bővíthetők más naplózási megoldásokkal. Az Elastic Stacket is meg kell vizsgálnia (különösen akkor, ha egy fürtöt offline környezetben szeretne futtatni), a Dynatrace-et vagy bármely más, ön által előnyben részesített platformot. Az integrált partnerek listáját az Azure Service Fabric monitorozási partnerei című témakörben találja.
A választott platformok legfontosabb pontjai közé tartozik a felhasználói felület, a lekérdezési képességek, az elérhető egyéni vizualizációk és irányítópultok, valamint a monitorozási élmény fokozása érdekében biztosított további eszközök.
Azure-tevékenységnapló
A tevékenységnapló előfizetésszintű eseményeket tartalmaz, amelyek nyomon követik az egyes Azure-erőforrások műveleteit az adott erőforráson kívülről látható módon; például új erőforrás létrehozása vagy virtuális gép indítása.
Gyűjtemény: A tevékenységnapló-események automatikusan létrejönnek, és egy külön tárolóban lesznek összegyűjtve az Azure Portalon való megtekintéshez.
Útválasztás: Tevékenységnapló-adatokat küldhet az Azure Monitor-naplókba, hogy más naplóadatokkal együtt elemezhesse azokat. Más helyek is elérhetők, például az Azure Storage, az Azure Event Hubs és bizonyos Microsoft monitorozási partnerek. A tevékenységnapló irányításával kapcsolatos további információkért tekintse meg az Azure-tevékenységnapló áttekintését.
Monitorozási adatok elemzése
A monitorozási adatok elemzésére számos eszköz áll rendelkezésre.
Azure Monitor-eszközök
Az Azure Monitor a következő alapvető eszközöket támogatja:
A Metrics Explorer egy eszköz az Azure Portalon, amely lehetővé teszi az Azure-erőforrások mérőszámainak megtekintését és elemzését. További információ: Metrikák elemzése az Azure Monitor metrikakezelőjével.
A Log Analytics egy eszköz az Azure Portalon, amely lehetővé teszi a naplóadatok lekérdezését és elemzését a Kusto lekérdezési nyelv (KQL) használatával. További információ: A napló lekérdezéseinek első lépései az Azure Monitorban.
A tevékenységnapló, amely egy felhasználói felülettel rendelkezik az Azure Portalon a megtekintéshez és az alapszintű keresésekhez. A részletesebb elemzéshez át kell irányítania az adatokat az Azure Monitor-naplókba, és összetettebb lekérdezéseket kell futtatnia a Log Analyticsben.
Az összetettebb vizualizációt lehetővé tevő eszközök a következők:
- Irányítópultok , amelyek lehetővé teszik, hogy különböző típusú adatokat egyesítsen egyetlen panelen az Azure Portalon.
- Az Azure Portalon létrehozható munkafüzetek, testreszabható jelentések. A munkafüzetek tartalmazhatnak szöveget, metrikákat és napló lekérdezéseket.
- Grafana, egy nyíltplatformos eszköz, amely kiválóan működik az irányítópultokon. A Grafana használatával olyan irányítópultokat hozhat létre, amelyek az Azure Monitoron kívül több forrásból származó adatokat is tartalmaznak.
- A Power BI egy üzleti elemzési szolgáltatás, amely interaktív vizualizációkat biztosít különböző adatforrásokban. A Power BI-t úgy konfigurálhatja, hogy automatikusan importálja a naplóadatokat az Azure Monitorból a vizualizációk előnyeinek kihasználásához.
A Service Fabric gyakori monitorozási elemzési forgatókönyveinek áttekintéséhez tekintse meg a Service Fabric gyakori forgatókönyveinek diagnosztizálását ismertető témakört.
Az Azure Monitor exportálási eszközei
Az Azure Monitorból más eszközökre is lekérheti az adatokat az alábbi módszerekkel:
Metrikák: Metrikákhoz használja a REST API-t metrikaadatok kinyeréséhez az Azure Monitor metrika-adatbázisából. Az API támogatja a szűrőkifejezéseket a lekért adatok finomításához. További információ: Azure Monitor REST API-referencia.
Naplók: Használja a REST API-t vagy a kapcsolódó ügyfélkódtárakat.
Egy másik lehetőség a munkaterület adatexportálása.
Az Azure MonitorHOZ készült REST API használatának megkezdéséhez tekintse meg az Azure monitoring REST API-útmutatót.
Kusto-lekérdezések
A monitorozási adatokat az Azure Monitor Naplók/ Log Analytics-tárolóban a Kusto lekérdezési nyelv (KQL) használatával elemezheti.
Fontos
Amikor a portálon a szolgáltatás menüjében a Naplók lehetőséget választja, megnyílik a Log Analytics, és a lekérdezés hatóköre az aktuális szolgáltatásra van állítva. Ez a hatókör azt jelenti, hogy a napló lekérdezései csak az adott típusú erőforrásból származó adatokat tartalmazzák. Ha más Azure-szolgáltatásokból származó adatokat tartalmazó lekérdezést szeretne futtatni, válassza a Naplók lehetőséget az Azure Monitor menüjében. A részletekért tekintse meg az Azure Monitor Log Analytics napló lekérdezési hatókörét és időtartományát.
A szolgáltatások gyakori lekérdezéseinek listáját a Log Analytics lekérdezési felületén találja.
Minta lekérdezések
Az alábbi lekérdezések Service Fabric-eseményeket ad vissza, beleértve a csomópontokon végzett műveleteket is. További hasznos lekérdezésekért tekintse meg a Service Fabric-eseményeket.
Az elmúlt órában rögzített működési események visszaadása:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Állapotjelentéseket ad vissza a HealthState == 3 (Hiba) értékével, és nyerjen ki további tulajdonságokat a EventMessage mezőből:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
A Service Fabric működési eseményeinek összesítése az adott szolgáltatással és csomóponttal:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Riasztások
Az Azure Monitor-riasztások proaktív módon értesítik, ha adott feltételek találhatók a monitorozási adatokban. A riasztások lehetővé teszik a rendszer problémáinak azonosítását és kezelését, mielőtt az ügyfelek észrevennénk őket. További információ: Azure Monitor-riasztások.
Az Azure-erőforrásokra vonatkozó gyakori riasztások számos forrásból állnak. Az Azure-erőforrásokra vonatkozó gyakori riasztások példáiért lásd a naplóriasztási lekérdezéseket. Az Azure Monitor Alapszintű riasztások (AMBA) webhelye félautomata módszert biztosít a fontos platformmetrika-riasztások, irányítópultok és irányelvek implementálására. A webhely az Azure-szolgáltatások folyamatosan bővülő részhalmazára vonatkozik, beleértve az Azure Landing Zone (ALZ) részét képező összes szolgáltatást is.
A gyakori riasztási séma szabványosítja az Azure Monitor riasztási értesítéseinek használatát. További információ: Gyakori riasztási séma.
Riasztások típusai
Az Azure Monitor adatplatformon bármilyen metrika- vagy naplóadatforrásról riasztást készíthet. A figyelt szolgáltatásoktól és a gyűjtött monitorozási adatoktól függően számos különböző típusú riasztás létezik. A különböző típusú riasztások különböző előnyökkel és hátrányokkal rendelkeznek. További információ: A megfelelő figyelési riasztástípus kiválasztása.
Az alábbi lista a létrehozható Azure Monitor-riasztások típusait ismerteti:
- A metrikariasztások rendszeres időközönként értékelik ki az erőforrásmetrikákat. A metrikák lehetnek platformmetrikák, egyéni metrikák, az Azure Monitorból metrikákká konvertált naplók vagy Application Insights-metrikák. A metrikariasztások több feltételt és dinamikus küszöbértéket is alkalmazhatnak.
- A naplóriasztások lehetővé teszik, hogy a felhasználók Log Analytics-lekérdezéssel kiértékeljék az erőforrásnaplókat egy előre meghatározott gyakorisággal.
- A tevékenységnapló-riasztások akkor aktiválnak, ha egy új tevékenységnapló-esemény következik be, amely megfelel a megadott feltételeknek. A Resource Health-riasztások és a Service Health-riasztások olyan tevékenységnapló-riasztások, amelyek jelentést jelentenek a szolgáltatásról és az erőforrás állapotáról.
Egyes Azure-szolgáltatások intelligens észlelési riasztásokat, Prometheus-riasztásokat vagy ajánlott riasztási szabályokat is támogatnak.
Egyes szolgáltatások esetében nagy léptékben monitorozhat, ha ugyanazt a metrikariasztási szabályt több, azonos típusú erőforrásra alkalmazza, amelyek ugyanabban az Azure-régióban léteznek. Minden figyelt erőforráshoz külön értesítéseket küld a rendszer. A támogatott Azure-szolgáltatásokról és felhőkről lásd : Több erőforrás monitorozása egyetlen riasztási szabmánnyal.
Service Fabric-riasztási szabályok
Az alábbi táblázat felsorol néhány riasztási szabályt a Service Fabrichez. Ezek a riasztások csak példák. Riasztásokat állíthat be a Service Fabric monitorozási adatreferenciájában vagy a Service Fabric-események listájában felsorolt metrikákhoz, naplóbejegyzésekhez vagy tevékenységnapló-bejegyzésekhez.
| Riasztástípus | Feltétel | Leírás |
|---|---|---|
| Csomópontesemény | A csomópont leáll | ServiceFabricOperationalEvent, ahol eventID >= 25622 és EventID <= 25626. Ezek az eseményazonosítók a Node-események referenciájában találhatók. |
| Alkalmazásesemény | Alkalmazásfrissítés visszaállítása | ServiceFabricOperationalEvent, ahol eventID == 29623 vagy EventID == 29624. Ezek az eseményazonosítók az alkalmazásesemények hivatkozásában találhatók. |
| Erőforrás állapota | A szolgáltatás frissítése nem érhető el/nem érhető el | A fürt az UpgradeServiceUnreachable állapotba kerül. |
Az Advisor javaslatai
Egyes szolgáltatások esetében, ha az erőforrás-műveletek során kritikus feltételek vagy közelgő változások lépnek fel, riasztás jelenik meg a portál szolgáltatásáttekintő lapján. A riasztással kapcsolatos további információkat és javasolt javításokat a bal oldali menü Figyelés területén található Advisor-javaslatok között találja. Normál műveletek során nem jelennek meg tanácsadói javaslatok.
Az Azure Advisorról további információt az Azure Advisor áttekintésében talál.
Ajánlott beállítás
Most, hogy áttekintettük a figyelési és példaforgatókönyvek egyes területeit, íme az Azure monitorozási eszközeinek összegzése, és a fenti területek monitorozásához szükséges beállítás.
- Alkalmazásfigyelés az Application Insights használatával
- Fürtfigyelés diagnosztikai ügynökkel és Azure Monitor-naplókkal
- Infrastruktúra monitorozása Azure Monitor-naplókkal
A minta ARM-sablon használatával és módosításával automatizálhatja az összes szükséges erőforrás és ügynök üzembe helyezését.
Kapcsolódó tartalom
- A Service Fabrichez létrehozott metrikák, naplók és egyéb fontos értékek hivatkozását a Service Fabric monitorozási adathivatkozásában talál.
- Az Azure-erőforrások monitorozásával kapcsolatos általános részletekért tekintse meg az Azure-erőforrások Monitorozása az Azure Monitorral című témakört.
- Tekintse meg a Service Fabric-események listáját.