Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Data Box-eszköz használatával adatokat migrálhat a Hadoop-fürt helyszíni HDFS-tárolójából az Azure Storage-ba (blobtárolóba vagy Data Lake Storage-ba). A Data Box Disk, a 80, 120 vagy 525 TiB kapacitású Data Box, illetve a 770 TiB Data Box Heavy közül választhat.
Ez a cikk a következő feladatok elvégzésében nyújt segítséget:
- Felkészülés az adatok migrálására
- Adatok másolása Data Box Diskre, Data Box-ra vagy Data Box Heavy-eszközre
- Az eszköz visszaküldése a Microsoftnak
- Hozzáférési engedélyek alkalmazása fájlokra és könyvtárakra (csak Data Lake Storage esetén)
Előfeltételek
Ezekre a dolgokra van szüksége a migrálás befejezéséhez.
Egy Azure Storage-fiókot.
A forrásadatokat tartalmazó helyszíni Hadoop-fürt.
-
Csatlakoztassa a Data Boxot vagy a Data Box Heavyt egy helyszíni hálózathoz.
Ha készen áll, kezdjük.
Adatok másolása Data Box-eszközre
Ha az adatok egyetlen Data Box-eszközbe illeszkednek, akkor az adatokat a Data Box-eszközre másolja.
Ha az adatméret meghaladja a Data Box-eszköz kapacitását, az opcionális eljárással ossza fel az adatokat több Data Box-eszközre , majd hajtsa végre ezt a lépést.
Ha a helyszíni HDFS-tárolóból egy Data Box-eszközre szeretné másolni az adatokat, állítson be néhány dolgot, majd használja a DistCp eszközt.
Az alábbi lépéseket követve adatokat másolhat a Blob/Object Storage REST API-kkal a Data Box-eszközre. A REST API felülettel az eszköz HDFS-tárolóként jelenik meg a fürtön.
Az adatok REST-en keresztüli másolása előtt azonosítsa a biztonsági és kapcsolati primitíveket a Data Box vagy a Data Box Heavy REST-felületéhez való csatlakozáshoz. Jelentkezzen be a Data Box helyi webes felületére, és lépjen a Csatlakozás és másolás lapra. Az eszköz azure-tárfiókjain az Access beállításai alatt keresse meg és válassza a REST elemet.
Az Access tárolófiók és adatok feltöltése párbeszédpanelen másolja ki a Blob szolgáltatásvégpontot és a tárolófiók-kulcsot. A blobszolgáltatás végpontjáról hagyja ki a
https://záró perjelet.Ebben az esetben a végpont a következő:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. A használt URI gazdagéprésze:mystorageaccount.blob.mydataboxno.microsoftdatabox.com. Megtudhatja például, hogyan csatlakozhat a REST-hez http-en keresztül.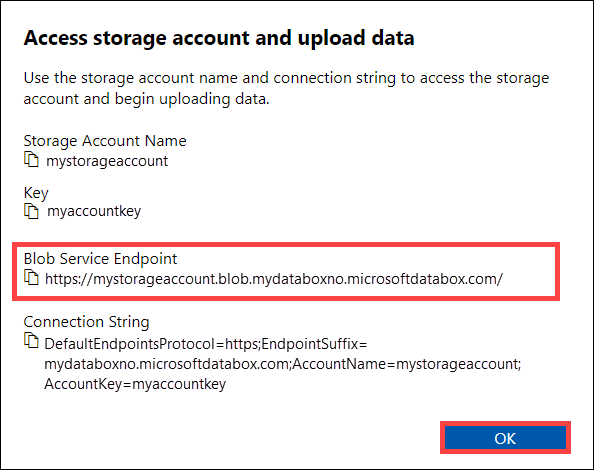
Adja hozzá a végpontot és a Data Box vagy a Data Box Heavy csomópont IP-címét minden csomóponthoz
/etc/hosts.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comHa más mechanizmust használ a DNS-hez, győződjön meg arról, hogy a Data Box-végpont feloldható.
Állítsa a rendszerhéjváltozót
azjarsa jar-fájlokhadoop-azurehelyéreazure-storage. Ezeket a fájlokat a Hadoop telepítési könyvtárában találja.Ha meg szeretné állapítani, hogy léteznek-e ilyen fájlok, használja a következő parancsot:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure. Cserélje le a<hadoop_install_dir>helyőrzőt arra a könyvtárra, ahová a Hadoopot telepítette. Ügyeljen arra, hogy teljesen minősített elérési utakat használjon.Példák:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarHozza létre az adatmásoláshoz használni kívánt tárolót. A parancs részeként meg kell adnia egy célkönyvtárat is. Ez lehet egy ál célkönyvtár ezen a ponton.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Cserélje le a
<blob_service_endpoint>helyőrzőt a blobszolgáltatás végpontjának nevére.Cserélje le a
<account_key>helyőrzőt a fiók hozzáférési kulcsára.Cserélje le a
<container-name>helyőrzőt a tároló nevére.Cserélje le a
<destination_directory>helyőrzőt annak a könyvtárnak a nevére, amelybe az adatokat át szeretné másolni.
Futtasson egy listaparancsot a tároló és a könyvtár létrehozásának ellenőrzéséhez.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/Cserélje le a
<blob_service_endpoint>helyőrzőt a blobszolgáltatás végpontjának nevére.Cserélje le a
<account_key>helyőrzőt a fiók hozzáférési kulcsára.Cserélje le a
<container-name>helyőrzőt a tároló nevére.
Másolja az adatokat a Hadoop HDFS-ből a Data Box Blob Storage-ba a korábban létrehozott tárolóba. Ha a másolandó könyvtár nem található, a parancs automatikusan létrehozza azt.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Cserélje le a
<blob_service_endpoint>helyőrzőt a blobszolgáltatás végpontjának nevére.Cserélje le a
<account_key>helyőrzőt a fiók hozzáférési kulcsára.Cserélje le a
<container-name>helyőrzőt a tároló nevére.Cserélje le a
<exclusion_filelist_file>helyőrzőt annak a fájlnak a nevére, amely tartalmazza a fájlkizárások listáját.Cserélje le a
<source_directory>helyőrzőt a másolni kívánt adatokat tartalmazó könyvtár nevére.Cserélje le a
<destination_directory>helyőrzőt annak a könyvtárnak a nevére, amelybe az adatokat át szeretné másolni.
Ezzel
-libjarsa beállítással elérhetővéhadoop-azure*.jarteheti aazure-storage*.jarfüggődistcpfájlokat. Ez egyes fürtök esetében már előfordulhat.Az alábbi példa bemutatja, hogyan használja a parancs az
distcpadatok másolását.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataA másolási sebesség javítása:
Próbálja meg módosítani a leképezők számát. (A leképezők alapértelmezett száma 20. A fenti példa = 4 mappert használ
m.)Próbálja ki
-D fs.azure.concurrentRequestCount.out=<thread_number>. Cserélje le<thread_number>a leképezőnkénti szálak számát. A leképezők számának és a menetek per mapperenkéntim*<thread_number>számának szorzata nem haladhatja meg a 32-t.Próbálkozzon több
distcppárhuzamos futtatásával.Ne feledje, hogy a nagy fájlok jobban teljesítenek, mint a kis fájlok.
Ha 200 GB-nál nagyobb fájlokkal rendelkezik, javasoljuk, hogy módosítsa a blokkméretet 100 MB-ra a következő paraméterekkel:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
A Data Box elküldése a Microsoftnak
Az alábbi lépéseket követve előkészíti és elküldi a Data Box-eszközt a Microsoftnak.
Először készítse elő a Data Box vagy a Data Box Heavy készüléket szállításra.
Az eszköz előkészítése után töltse le a BOM-fájlokat. Ezeket a BOM-fájlokat vagy jegyzékfájlokat később használhatja az Azure-ba feltöltött adatok ellenőrzéséhez.
Állítsa le az eszközt, és távolítsa el a kábeleket.
Egyeztessen egy csomagfelvételi időpontot a UPS-szel.
A Data Box-eszközökkel kapcsolatban lásd a Data Box szállítását.
A Data Box Heavy-eszközökkel kapcsolatban lásd a Data Box Heavy szállítását ismertető témakört.
Miután a Microsoft megkapta az eszközt, az az adatközpont hálózatához csatlakozik, és az adatok fel lesznek töltve az eszközrendelés leadásakor megadott tárfiókba. Ellenőrizze a BOM-fájlokon, hogy az összes adat feltöltve van-e az Azure-ba.
Hozzáférési engedélyek alkalmazása fájlokra és könyvtárakra (csak Data Lake Storage esetén)
Már rendelkezik az adatokkal az Azure Storage-fiókjában. Most hozzáférési engedélyeket alkalmaz a fájlokra és könyvtárakra.
Feljegyzés
Erre a lépésre csak akkor van szükség, ha az Azure Data Lake Storage-t használja adattárként. Ha csak egy blobtároló fiókot használ hierarchikus névtér nélkül adattárként, kihagyhatja ezt a szakaszt.
Szolgáltatásnév létrehozása az Azure Data Lake Storage-kompatibilis fiókhoz
Szolgáltatásnév létrehozásához lásd : Útmutató: A portál használatával létrehozhat egy Olyan Microsoft Entra-alkalmazást és szolgáltatásnevet, amely hozzáfér az erőforrásokhoz.
Amikor végrehajtja az Alkalmazás hozzárendelése egy szerepkörhöz című résznek a lépéseit a cikkben, győződjön meg arról, hogy a Storage Blob Data Contributor szerepkört a szolgáltatási példányhoz rendeli.
Amikor végrehajtja a cikkben található Bejelentkezési értékek lekérése szakasz lépéseit, mentse az alkalmazásazonosítót és az ügyféltitok értékeket egy szövegfájlba. Ezekre hamarosan szüksége lesz.
Másolt fájlok listájának létrehozása az engedélyekkel
A helyszíni Hadoop-fürtben futtassa a következő parancsot:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
Ez a parancs létrehozza az engedélyekkel rendelkező másolt fájlok listáját.
Feljegyzés
A HDFS-fájlok számától függően ez a parancs hosszú ideig tarthat.
Identitások listájának létrehozása és a Microsoft Entra-identitások leképezése
Töltse le a
copy-acls.pyszkriptet. Tekintse meg a Letöltési segédszkriptek telepítése és az élcsomópont beállítása azok futtatására című részt ebben a cikkben.Futtassa ezt a parancsot az egyedi identitások listájának létrehozásához.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gEz a szkript létrehoz egy fájlt
id_map.json, amely tartalmazza azokat az identitásokat, amelyeket az ADD-alapú identitásokhoz kell leképeznie.Nyissa meg a
id_map.jsonfájlt egy szövegszerkesztőben.A fájlban megjelenő minden egyes JSON-objektum esetében frissítse a
targetMicrosoft Entra felhasználónév (UPN) vagy az ObjectId (OID) attribútumát a megfelelő leképezett identitással. Miután végzett, mentse a fájlt. A következő lépésben szüksége lesz erre a fájlra.
Engedélyek alkalmazása másolt fájlokra és identitásleképezések alkalmazása
Futtassa ezt a parancsot a Data Lake Storage-kompatibilis fiókba másolt adatokra vonatkozó engedélyek alkalmazásához:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
Cserélje le a
<storage-account-name>helyőrzőt a tárfiók nevére.Cserélje le a
<container-name>helyőrzőt a tároló nevére.Cserélje le a
<application-id>helyőrzőket<client-secret>az alkalmazásazonosítóra és az ügyfél titkos kódjára, amelyet a szolgáltatásnév létrehozásakor gyűjtött.
Függelék: Adatok felosztása több Data Box-eszközön
Mielőtt áthelyezi az adatokat egy Data Box-eszközre, le kell töltenie néhány segédszkriptet, gondoskodnia kell arról, hogy az adatok úgy legyenek rendszerezve, hogy illeszkedjenek a Data Box-eszközre, és kizárja a szükségtelen fájlokat.
Segédszkriptek letöltése és a peremhálózati csomópont beállítása a futtatásukhoz
A helyszíni Hadoop-fürt peremhálózati vagy fő csomópontján futtassa a következő parancsot:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderEz a parancs klónozza a segédszkripteket tartalmazó GitHub-adattárat.
Győződjön meg arról, hogy a helyi számítógépen legyen telepítve a jq csomag.
sudo apt-get install jqTelepítse a Requests Python-csomagot.
pip install requestsVégrehajtási engedélyek beállítása a szükséges szkripteken.
chmod +x *.py *.sh
Győződjön meg arról, hogy az adatok rendszerezése úgy van rendezve, hogy egy Data Box-eszközhöz illeszkedjen
Ha az adatok mérete meghaladja az egyetlen Data Box-eszköz méretét, feloszthatja a fájlokat olyan csoportokra, amelyeket több Data Box-eszközre is tárolhat.
Ha az adatok nem lépik túl egyetlen Data Box-eszköz méretét, folytassa a következő szakaszsal.
Emelt szintű engedélyekkel futtassa a
generate-file-listletöltött szkriptet az előző szakaszban található útmutatást követve.Íme a parancsparaméterek leírása:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Másolja a létrehozott fájllistákat a HDFS-be, hogy azok elérhetők legyenek a DistCp-feladat számára.
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Felesleges fájlok kizárása
Ki kell zárnia néhány könyvtárat a DisCp-feladatból. Zárja ki például a fürtöt futtató állapotinformációkat tartalmazó könyvtárakat.
Azon a helyszíni Hadoop-fürtön, ahol a DistCp-feladat elindítását tervezi, hozzon létre egy fájlt, amely megadja a kizárni kívánt könyvtárak listáját.
Példa:
.*ranger/audit.*
.*/hbase/data/WALs.*
Következő lépések
Megtudhatja, hogyan működik a Data Lake Storage a HDInsight-fürtökkel. További információ: Az Azure Data Lake Storage használata Azure HDInsight-fürtökkel.