Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A bemeneti ellenőrzés a fő lekérdezési logikának a helytelen vagy váratlan események elleni védelmére szolgáló technika. A lekérdezést explicit módon feldolgozzák és ellenőrzik a rekordokat, hogy ne szeghetik meg a fő logikát.
A bemeneti ellenőrzés implementálásához két kezdeti lépést adunk hozzá egy lekérdezéshez. Először győződjön meg arról, hogy az alapvető üzleti logikának küldött séma megfelel az elvárásainak. Ezután a kivételeket osztályozzuk, és opcionálisan átirányítjuk az érvénytelen rekordokat egy másodlagos kimenetbe.
A bemeneti ellenőrzéssel rendelkező lekérdezések a következőképpen lesznek strukturálva:
WITH preProcessingStage AS (
SELECT
-- Rename incoming fields, used for audit and debugging
field1 AS in_field1,
field2 AS in_field2,
...
-- Try casting fields in their expected type
TRY_CAST(field1 AS bigint) as field1,
TRY_CAST(field2 AS array) as field2,
...
FROM myInput TIMESTAMP BY myTimestamp
),
triagedOK AS (
SELECT -- Only fields in their new expected type
field1,
field2,
...
FROM preProcessingStage
WHERE ( ... ) -- Clauses make sure that the core business logic expectations are satisfied
),
triagedOut AS (
SELECT -- All fields to ease diagnostic
*
FROM preProcessingStage
WHERE NOT (...) -- Same clauses as triagedOK, opposed with NOT
)
-- Core business logic
SELECT
...
INTO myOutput
FROM triagedOK
...
-- Audit output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- To a storage adapter that doesn't require strong typing, here blob/adls
FROM triagedOut
Ha átfogó példát szeretne látni a bemeneti ellenőrzéssel beállított lekérdezésre, tekintse meg a következő szakaszt: Példa a bemeneti ellenőrzéssel rendelkező lekérdezésre.
Ez a cikk bemutatja, hogyan valósíthatja meg ezt a technikát.
Környezet
Az Azure Stream Analytics (ASA) feladatai streamekből származó adatokat dolgoznak fel. adatfolyamok a szerializált nyers adatok sorozatai (CSV, JSON, AVRO...). A streamből való olvasáshoz az alkalmazásnak ismernie kell a használt szerializálási formátumot. Az ASA-ban az esemény szerializálási formátumát meg kell határozni a streambemenet konfigurálásakor.
Az adatok deszerializálása után egy sémát kell alkalmazni annak jelentésére. Séma alatt a streamben lévő mezők listáját és azok adattípusait értjük. Az ASA esetén a bejövő adatok sémáját nem kell a bemeneti szinten beállítani. Az ASA ehelyett natív módon támogatja a dinamikus bemeneti sémákat . Azt várja , hogy a mezők (oszlopok) és típusuk listája megváltozzon az események (sorok) között. Az ASA akkor is adattípusokat fog kikövetkeztetni, ha nincs explicit módon megadva, és szükség esetén megpróbálja implicit módon leadni a típusokat.
A dinamikus sémakezelés hatékony funkció, a streamfeldolgozás kulcsa. Az adatfolyamok gyakran több forrásból származó adatokat tartalmaznak, több eseménytípussal, amelyek mindegyike egyedi sémával rendelkezik. Az ilyen streameken lévő események irányításához, szűréséhez és feldolgozásához az ASA-nak minden sémát be kell használnia.
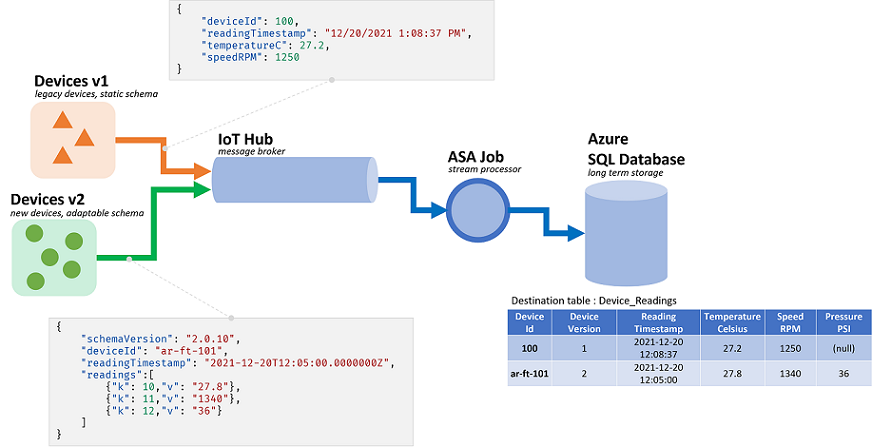
A dinamikus sémakezelés által kínált képességek azonban potenciális hátrányai lehetnek. A váratlan események átfolyhatnak a fő lekérdezési logikán, és megszakíthatják azt. Példaként használhatjuk a ROUND függvényt egy típusmezőn NVARCHAR(MAX). Az ASA implicit módon lebegteti, hogy megfeleljen a következő aláírásának ROUND: . Itt azt várjuk, vagy reméljük, hogy ez a mező mindig numerikus értékeket fog tartalmazni. Ha azonban olyan eseményt kapunk, amelynek a mezője be van állítva "NaN", vagy ha a mező teljesen hiányzik, akkor a feladat meghiúsulhat.
A bemeneti ellenőrzéssel előzetes lépéseket adunk a lekérdezéshez az ilyen hibásan formázott események kezeléséhez. Elsősorban a WITH és a TRY_CAST fogjuk használni a implementáláshoz.
Forgatókönyv: bemeneti ellenőrzés megbízhatatlan eseménykészítők számára
Létrehozunk egy új ASA-feladatot, amely egyetlen eseményközpontból betölti az adatokat. Ahogy a leggyakrabban is előfordul, nem mi vagyunk a felelősek az adattermelőkért. Itt a gyártók olyan IoT-eszközök, amelyeket több hardvergyártó értékesített.
Az érdekelt felekkel való találkozás során egyetértünk a szerializálási formátummal és a sémával. Minden eszköz leküldi az ilyen üzeneteket egy gyakori eseményközpontba, az ASA-feladat bemenetére.
A sémaszerződés a következőképpen van definiálva:
| Mezőnév | Mezőtípus | Mező leírása |
|---|---|---|
deviceId |
Egész | Egyedi eszközazonosító |
readingTimestamp |
Datetime | Egy központi átjáró által generált üzenetidő |
readingStr |
Sztring | |
readingNum |
Numerikus | |
readingArray |
Sztringtömb |
Ez a JSON-szerializálás alatt a következő mintaüzenetet adja nekünk:
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7,
"readingArray" : ["A","B"]
}
Már láthatunk eltérést a sémaszerződés és annak megvalósítása között. JSON formátumban nincs adattípus a datetime-hez. Sztringként lesz továbbítva (lásd readingTimestamp fent). Az ASA könnyen meg tudja kezelni a problémát, de azt mutatja, hogy szükség van a típusok ellenőrzésére és explicit módon történő leadására. Annál is inkább a CSV-ben szerializált adatok esetében, mivel az összes érték sztringként lesz továbbítva.
Van egy másik eltérés. Az ASA saját típusrendszert használ, amely nem felel meg a bejövő rendszernek. Ha az ASA beépített típusokkal rendelkezik egész számokhoz (bigint), datetime-hez, sztringhez (nvarchar(max)) és tömbökhöz, akkor csak a lebegőpontos számokat támogatja. Ez az eltérés a legtöbb alkalmazás esetében nem jelent problémát. Bizonyos peremhálózati esetekben azonban kis pontosságú sodródást okozhat. Ebben az esetben a numerikus értéket sztringként konvertáljuk egy új mezőben. Ezután lefelé egy olyan rendszert használnánk, amely támogatja a rögzített tizedesjegyeket a lehetséges eltérések észleléséhez és javításához.
Térjen vissza a lekérdezéshez, itt a következőt tervezzük:
- Továbbítás
readingStrJavaScript UDF-hez - A tömbben lévő rekordok számának megszámlálása
- Kerekítés
readingNuma második tizedesjegyre - Adatok beszúrása SQL-táblába
A cél SQL-tábla a következő sémával rendelkezik:
CREATE TABLE [dbo].[readings](
[Device_Id] int NULL,
[Reading_Timestamp] datetime2(7) NULL,
[Reading_String] nvarchar(200) NULL,
[Reading_Num] decimal(18,2) NULL,
[Array_Count] int NULL
) ON [PRIMARY]
Érdemes feltérképezni, hogy mi történik az egyes mezőkben a feladat során:
| Mező | Bemenet (JSON) | Örökölt típus (ASA) | Kimenet (Azure SQL) | Megjegyzés |
|---|---|---|---|---|
deviceId |
szám | bigint | egész szám | |
readingTimestamp |
húr | nvarchar(MAX) | datetime2 | |
readingStr |
húr | nvarchar(MAX) | nvarchar(200) | az UDF által használt |
readingNum |
szám | float | decimális(18,2) | lekerekíteni |
readingArray |
tömb(sztring) | nvarchar(MAX) tömbje | egész szám | megszámlálandó |
Előfeltételek
A lekérdezést a Visual Studio Code-ban fejlesztjük az ASA Tools bővítmény használatával. Az oktatóanyag első lépései végigvezetik a szükséges összetevők telepítésén.
A VS Code-ban helyi futtatásokat használunk helyi bemenettel/kimenettel, hogy ne járjon költséggel, és felgyorsítsuk a hibakeresési ciklust. Nem kell eseményközpontot vagy Azure SQL Database-t beállítani.
Alap lekérdezés
Kezdjük egy alapszintű implementációval , bemeneti ellenőrzés nélkül. A következő szakaszban fogjuk hozzáadni.
A VS Code-ban létrehozunk egy új ASA-projektet
input A mappában létrehozunk egy új JSON-fájlt, amelyet meghívunkdata_readings.json, és hozzáadjuk a következő rekordokat:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingStr" : "Another String",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : -4.85436,
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : ["G","G"]
}
]
Ezután meghatározunk egy helyi bemenetet, az úgynevezett readingsJSON-fájlt, amely a fent létrehozott JSON-fájlra hivatkozik.
A konfigurálás után a következőhöz hasonlóan kell kinéznie:
{
"InputAlias": "readings",
"Type": "Data Stream",
"Format": "Json",
"FilePath": "data_readings.json",
"ScriptType": "InputMock"
}
Előzetes adatokkal megfigyelhetjük, hogy a rekordok megfelelően vannak betöltve.
Létrehozunk egy új JavaScript UDF-t , amelyet úgy hívunk udfLen meg, hogy a jobb gombbal a mappára kattintunk, és kiválasztjuk a Functions lehetőséget ASA: Add Function. A használni kívánt kód a következő:
// Sample UDF that returns the length of a string for demonstration only: LEN will return the same thing in ASAQL
function main(arg1) {
return arg1.length;
}
Helyi futtatások esetén nem kell kimeneteket definiálnunk. Nem is kell használnunk INTO , hacsak nem több kimenet van. A fájlban lecserélhetjük .asaql a meglévő lekérdezést a következőre:
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
FROM readings AS r TIMESTAMP BY r.readingTimestamp
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
Tekintsük át gyorsan a beküldött lekérdezést:
- Az egyes tömbök rekordjainak megszámlálásához először ki kell csomagolnunk őket. A CROSS APPLY és a GetArrayElements() függvényt fogjuk használni (további minták itt)
- Ezzel két adathalmazt fogunk felszínre tenni a lekérdezésben: az eredeti bemenetet és a tömbértékeket. Annak érdekében, hogy ne keverjük össze a mezőket, aliasokat (
AS r) határozunk meg, és mindenhol használjuk őket - Ezután a tömbértékek tényleges
COUNTösszegzéséhez a GROUP BY függvényt kell összesíteni - Ehhez meg kell határoznunk egy időablakot. Mivel itt nincs szükségünk a logikánkhoz, a pillanatképablak a megfelelő választás
- Ezzel két adathalmazt fogunk felszínre tenni a lekérdezésben: az eredeti bemenetet és a tömbértékeket. Annak érdekében, hogy ne keverjük össze a mezőket, aliasokat (
- Az összes mezőre
GROUP BYis szükségünk van, és mindet ki kell vetíteni aSELECT. A mezők explicit kivetítése ajánlott eljárás, mivelSELECT *a hibák átfolynak a bemenettől a kimenetig - Az UDF használatával szűrjük azokat az értékeket, ahol
readingStrkét karakternél kevesebb karakter van. Itt kellett volna használnunk a LEN-t . Csak bemutató célú UDF-et használunk
Elindíthatjuk a futtatásokat, és megfigyelhetjük a feldolgozott adatokat:
| deviceId | readingTimestamp | readingStr | readingNum | arrayCount |
|---|---|---|---|---|
| 0 | 2021-12-10T10:00:00 | Sztring | 1,71 | 2 |
| 2 | 2021-12-10T10:01:00 | Másik sztring | 2.38 | 0 |
| 3 | 2021-12-10T10:01:20 | Harmadik sztring | -4.85 | 3 |
| 0 | 2021-12-10T10:02:10 | A Forth sztring | 1.21 | 2 |
Most, hogy már tudjuk, hogy a lekérdezés működik, teszteljük több adaton. Cserélje le a következő rekordok tartalmát data_readings.json :
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : "NaN",
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : {}
}
]
Az alábbiakban a következő problémákat láthatjuk:
- Az 1. eszköz mindent rendben csinált
- A 2. eszköz elfelejtette tartalmazni a következőt:
readingStr - Számként küldött
NaN3. eszköz - A 4. eszköz tömb helyett üres rekordot küldött
A feladat futtatása nem fog jól végződni. A következő hibaüzenetek egyikét kapjuk:
A 2. eszköz a következőt adja nekünk:
[Error] 12/22/2021 10:05:59 PM : **System Exception** Function 'udflen' resulted in an error: 'TypeError: Unable to get property 'length' of undefined or null reference' Stack: TypeError: Unable to get property 'length' of undefined or null reference at main (Unknown script code:3:5)
[Error] 12/22/2021 10:05:59 PM : at Microsoft.EventProcessing.HostedRuntimes.JavaScript.JavaScriptHostedFunctionsRuntime.
A 3. eszköz a következőt adja nekünk:
[Error] 12/22/2021 9:52:32 PM : **System Exception** The 1st argument of function round has invalid type 'nvarchar(max)'. Only 'bigint', 'float' is allowed.
[Error] 12/22/2021 9:52:32 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Arithmetics.Round(CompilerPosition pos, Object value, Object length)
A 4. eszköz a következőt adja nekünk:
[Error] 12/22/2021 9:50:41 PM : **System Exception** Cannot cast value of type 'record' to type 'array' in expression 'r . readingArray'. At line '9' and column '30'. TRY_CAST function can be used to handle values with unexpected type.
[Error] 12/22/2021 9:50:41 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Cast.ToArray(CompilerPosition pos, Object value, Boolean isUserCast)
Minden alkalommal, amikor a hibásan formázott rekordok a bemenetből a fő lekérdezési logikába áramolhattak ellenőrzés nélkül. Most már felismerjük a bemeneti ellenőrzés értékét.
Bemeneti ellenőrzés implementálása
Bővítsük ki a lekérdezést a bemenet ellenőrzéséhez.
A bemeneti ellenőrzés első lépése az alapvető üzleti logika sémával kapcsolatos elvárásainak meghatározása. Az eredeti követelményre visszatekintve a fő logikánk a következő:
- Továbbítás
readingStrJavaScript UDF-nek a hosszának méréséhez - A tömbben lévő rekordok számának megszámlálása
- Kerekítés
readingNuma második tizedesjegyre - Adatok beszúrása SQL-táblába
Minden egyes ponton felsorolhatjuk az elvárásokat:
- Az UDF-hez olyan karakterlánc típusú argumentum szükséges (itt nvarchar(max), amely nem lehet null értékű
GetArrayElements()típusú tömb argumentumot vagy null értéket igényelRoundegy bigint vagy float típusú argumentumot vagy null értéket igényel- Ahelyett, hogy az ASA implicit castingjára támaszkodnánk, saját magunk kell tennünk, és kezelni a lekérdezésben lévő típusütközéseket
Ennek egyik módja, ha a fő logikát a kivételek kezeléséhez igazítja. De ebben az esetben úgy gondoljuk, hogy a fő logikánk tökéletes. Ezért vizsgáljuk meg inkább a bejövő adatokat.
Először is a WITH használatával adjunk hozzá egy bemeneti érvényesítési réteget a lekérdezés első lépéseként. A TRY_CAST használatával konvertáljuk a mezőket a várt típusra, és beállíthatjuk őketNULL, ha az átalakítás sikertelen:
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
)
-- For debugging only
SELECT * FROM readingsValidated
A legutóbb használt bemeneti fájllal (a hibát tartalmazó fájllal) ez a lekérdezés a következő készletet adja vissza:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2021-12-10T10:00:00 | Sztring | 1.7145 | ["A";"B"] | 0 | 2021-12-10T10:00:00.0000000Z | Sztring | 1.7145 | ["A";"B"] |
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2.378 | ["C"] |
| 3 | 2021-12-10T10:01:20 | Harmadik sztring | Nan | ["D","E";"F"] | 3 | 2021-12-10T10:01:20.0000000Z | Harmadik sztring | NULL | ["D","E";"F"] |
| 4 | 2021-12-10T10:02:10 | A Forth sztring | 1.2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | A Forth sztring | 1.2126 | NULL |
Már láthatjuk, hogy két hiba van megoldva. Átalakítottuk és átalakítottuk NaN NULL.{} Most már biztosak vagyunk benne, hogy ezek a rekordok megfelelően lesznek beszúrva a cél SQL-táblába.
Most el kell döntenünk, hogyan kell kezelni a hiányzó vagy érvénytelen értékeket tartalmazó rekordokat. Némi vita után úgy döntünk, hogy elutasítjuk az üres/érvénytelen readingArray vagy hiányzó readingStrrekordokat.
Ezért hozzáadunk egy második réteget, amely a rekordokat az ellenőrzés és a fő logika között fogja összefűzni:
WITH readingsValidated AS (
...
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- For debugging only
SELECT * INTO Debug1 FROM readingsToBeProcessed
SELECT * INTO Debug2 FROM readingsToBeRejected
Ajánlott egyetlen WHERE záradékot írni mindkét kimenethez, és a másodikban használni NOT (...) . Így egyetlen rekord sem zárható ki a kimenetből és az elveszettből sem.
Most két kimenetet kapunk. A Debug1 a fő logikába küldendő rekordokkal rendelkezik:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 0 | 2021-12-10T10:00:00.0000000Z | Sztring | 1.7145 | ["A";"B"] |
| 3 | 2021-12-10T10:01:20.0000000Z | Harmadik sztring | NULL | ["D","E";"F"] |
A Debug2 a következő rekordokat fogja elutasítani:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2.378 | ["C"] |
| 4 | 2021-12-10T10:02:10 | A Forth sztring | 1.2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | A Forth sztring | 1.2126 | NULL |
Az utolsó lépés a fő logika visszaadása. Hozzáadjuk az elvetett kimenetet is. Itt a legjobb, ha olyan kimeneti adaptert használ, amely nem kényszeríti ki az erős gépelést, például egy tárfiókot.
A teljes lekérdezés az utolsó szakaszban található.
WITH
readingsValidated AS (...),
readingsToBeProcessed AS (...),
readingsToBeRejected AS (...)
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
SELECT
*
INTO BlobOutput
FROM readingsToBeRejected
Ez az SQLOutput következő készletét adja meg, lehetséges hiba nélkül:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 0 | 2021-12-10T10:00:00.0000000Z | Sztring | 1.7145 | 2 |
| 3 | 2021-12-10T10:01:20.0000000Z | Harmadik sztring | NULL | 3 |
A másik két rekordot egy BlobOutput küldi el az emberi felülvizsgálat és a feldolgozás utáni feldolgozás céljából. A lekérdezés biztonságos.
Példa a bemeneti ellenőrzéssel rendelkező lekérdezésre
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- Core business logic
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
-- Rejected output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- to a storage adapter that doesn't require strong typing, here blob/adls
FROM readingsToBeRejected
Bemeneti ellenőrzés kiterjesztése
A GetType használatával explicit módon ellenőrizheti a típust. Jól működik a CA Standard kiadás a kivetítésben, vagy a WHERE a beállított szinten. GetType A bejövő séma metaadattárakon való dinamikus ellenőrzésére is használható. Az adattár egy referenciaadatkészleten keresztül tölthető be.
Az egységtesztelés jó gyakorlat a lekérdezés rugalmasságának biztosításához. Olyan tesztsorozatot fogunk készíteni, amely bemeneti fájlokból és azok várható kimenetéből áll. A lekérdezésnek meg kell egyeznie az átadáshoz létrehozott kimenettel. Az ASA-ban az egységtesztelés az asa-streamanalytics-cicd npm modulon keresztül történik. A különböző hibásan formázott eseményekkel rendelkező teszteseteket az üzembehelyezési folyamatban kell létrehozni és tesztelni.
Végül elvégezhetünk néhány könnyű integrációs tesztet a VS Code-ban. Rekordokat szúrhatunk be az SQL-táblába egy helyi futtatáson keresztül egy élő kimenetre.
Támogatás kérése
További segítségért próbálja ki a Microsoft Q&A kérdésoldalát az Azure Stream Analyticshez.
Következő lépések
- CI/CD-folyamatok és egységtesztelés beállítása az npm-csomag használatával
- A Helyi Stream Analytics-futtatások áttekintése a Visual Studio Code-ban az ASA-eszközökkel
- Stream Analytics-lekérdezések helyi tesztelése mintaadatokkal a Visual Studio Code használatával
- Stream Analytics-lekérdezések helyi tesztelése élő streambemenettel a Visual Studio Code használatával
- Azure Stream Analytics-feladatok felfedezése a Visual Studio Code-tal (előzetes verzió)