Intelligens gyorsítótár az Azure Synapse Analyticsben
Az Intelligens gyorsítótár zökkenőmentesen működik a színfalak mögött, és gyorsítótárazza az adatokat, hogy felgyorsítsa a Spark végrehajtását az ADLS Gen2 data lake-ből való olvasás során. Emellett automatikusan észleli a mögöttes fájlok módosításait, és automatikusan frissíti a gyorsítótárban lévő fájlokat, biztosítva a legfrissebb adatokat, és amikor a gyorsítótár mérete eléri a korlátot, a gyorsítótár automatikusan felszabadítja a legkevésbé olvasható adatokat, hogy helyet biztosítson a legutóbbi adatok számára. Ez a funkció csökkenti a teljes tulajdonjogi költséget, mivel a parquet-fájlokhoz elérhető gyorsítótárban tárolt fájlok későbbi olvasási teljesítménye akár 65%-kal is csökken, a CSV-fájlok esetében pedig 50%-kal.
Amikor lekérdez egy fájlt vagy táblát a data lake-ből, a Synapse Apache Spark motorja meghívja a távoli ADLS Gen2-tárolót a mögöttes fájlok olvasásához. Minden olyan lekérdezési kérelem esetén, amely ugyanazokat az adatokat szeretné beolvasni, a Spark-motornak hívást kell kezdeményeznie a távoli ADLS Gen2-tárolóhoz. Ez a redundáns folyamat késést ad a teljes feldolgozási időhöz. A Spark egy gyorsítótárazási funkciót biztosít, amelyet manuálisan kell beállítania a gyorsítótárnak, és fel kell szabadítania a gyorsítótárat a késés minimalizálása és az általános teljesítmény javítása érdekében. Ez azonban azt eredményezheti, hogy az eredmények elavult adatokkal rendelkeznek, ha az alapul szolgáló adatok megváltoznak.
A Synapse Intelligent Cache leegyszerűsíti ezt a folyamatot azáltal, hogy automatikusan gyorsítótárazza az egyes olvasásokat az egyes Spark-csomópontok lefoglalt gyorsítótár-tárterületén belül. Minden fájlkérés ellenőrzi, hogy a fájl megtalálható-e a gyorsítótárban, és összehasonlítja a távoli tároló címkéjét annak megállapításához, hogy a fájl elavult-e. Ha a fájl nem létezik, vagy ha a fájl elavult, a Spark felolvassa a fájlt, és a gyorsítótárban tárolja. Amikor a gyorsítótár megtelik, a rendszer kiüríti a legrégebbi utolsó hozzáférési időt tartalmazó fájlt a gyorsítótárból, hogy újabb fájlokat engedélyezhessen.
A Synapse-gyorsítótár csomópontonként egyetlen gyorsítótár. Ha közepes méretű csomópontot használ, és két kis végrehajtóval fut egy közepes méretű csomóponton, ez a két végrehajtó ugyanazt a gyorsítótárat használja.
A gyorsítótár engedélyezése vagy letiltása
A gyorsítótár mérete az egyes Apache Spark-készletekhez elérhető teljes lemezméret százalékos aránya alapján módosítható. Alapértelmezés szerint a gyorsítótár le van tiltva, de a csúszkasáv 0-ról (le van tiltva) a gyorsítótár méretének kívánt százalékára való áthelyezésével. A rendelkezésre álló lemezterület legalább 20%-át lefoglaljuk az adatelkeveréshez. Az igényes számítási feladatok esetében minimalizálhatja a gyorsítótár méretét, vagy letilthatja a gyorsítótárat. Javasoljuk, hogy 50%-os gyorsítótármérettel kezdjen, és szükség szerint módosítsa. Fontos megjegyezni, hogy ha a számítási feladat sok lemezterületet igényel a helyi SSD-n az shuffle vagy AZ RDD gyorsítótárazásához, fontolja meg a gyorsítótár méretének csökkentését, hogy csökkentse a nem megfelelő tárterület miatti meghibásodás esélyét. Az elérhető tárterület tényleges mérete és az egyes csomópontok gyorsítótármérete a csomópontcsaládtól és a csomópont méretétől függ.
Gyorsítótár engedélyezése új Spark-készletekhez
Új Spark-készlet létrehozásakor a további beállítások lapon tallózva keresse meg az intelligens gyorsítótár csúszkát , amellyel a kívánt méretre léphet a funkció engedélyezéséhez.

Meglévő Spark-készletek gyorsítótárának engedélyezése/letiltása
Meglévő Spark-készletek esetén keresse meg a választható Apache Spark-készlet méretezési beállításait úgy, hogy a csúszkát 0-nál nagyobb értékre helyezi, vagy letiltja, ha a csúszkát 0-ra helyezi.
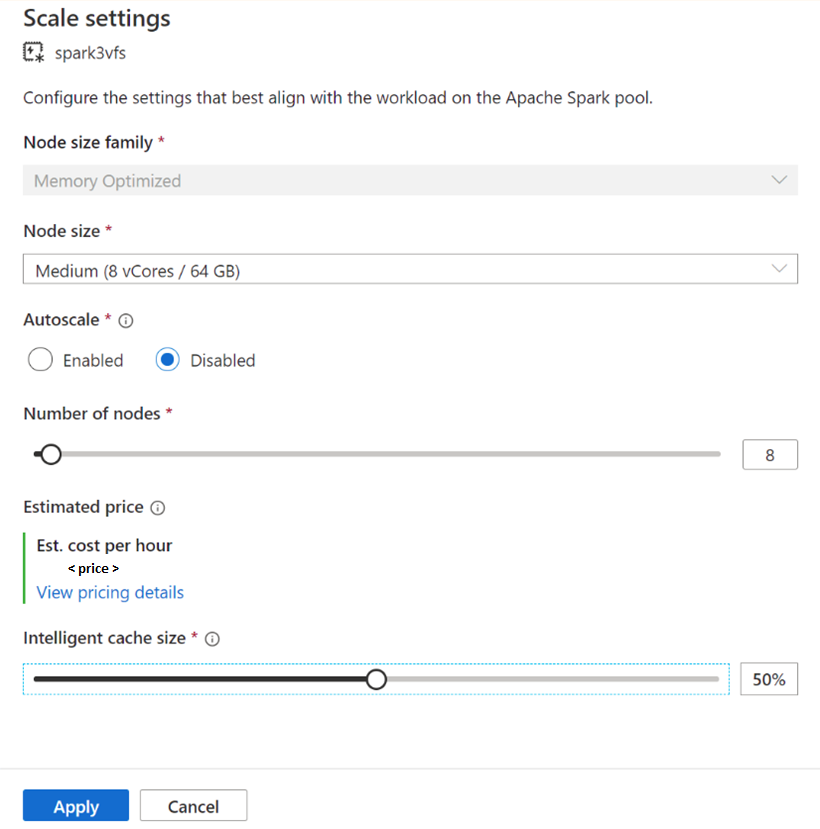
Meglévő Spark-készletek gyorsítótárméretének módosítása
A készlet intelligens gyorsítótárának méretének módosításához újra kell indítania, ha a készlet aktív munkamenetekkel rendelkezik. Ha a Spark-készlet aktív munkamenetet tart, akkor az új beállítások kényszerítése jelenik meg. Kattintson a jelölőnégyzetre, és válassza az Alkalmaz elemet a munkamenet automatikus újraindításához.

A gyorsítótár engedélyezése és letiltása a munkameneten belül
Egyszerűen tiltsa le az intelligens gyorsítótárat egy munkameneten belül a következő kód futtatásával a jegyzetfüzetben:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "false")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'false')
És engedélyezze a következő futtatásával:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "true")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'true')
Mikor érdemes használni az intelligens gyorsítótárat, és mikor ne?
Ez a funkció akkor hasznos, ha:
A számítási feladathoz többször is be kell olvasni ugyanazt a fájlt, és a fájl mérete elfér a gyorsítótárban.
A számítási feladat Delta-táblákat, parquet-fájlformátumokat és CSV-fájlokat használ.
Az Apache Spark 3 vagy újabb verzióját használja az Azure Synapse-ban.
Nem fogja látni ennek a funkciónak az előnyeit, ha:
Olyan fájlt olvas, amely túllépi a gyorsítótár méretét, mert a fájlok elejét kizárhatja, és a későbbi lekérdezések során vissza kell vennie az adatokat a távoli tárolóból. Ebben az esetben nem fog megjelenni az intelligens gyorsítótár előnyei, ezért érdemes lehet növelni a gyorsítótár méretét és/vagy a csomópont méretét.
A számítási feladat nagy mennyiségű shuffle-t igényel, majd az Intelligens gyorsítótár letiltása szabadít fel szabad területet, hogy megakadályozza a feladat meghiúsulását az elégtelen tárterület miatt.
Spark 3.1-készletet használ, a készletet a Spark legújabb verziójára kell frissítenie.
Tudjon meg többet
Az Apache Sparkról az alábbi cikkekben olvashat bővebben:
- Mi az Az Apache Spark?
- Az Apache Spark alapfogalmai
- Azure Synapse Runtime for Apache Spark 3.2
- Apache Spark-készlet méretei és konfigurációi
További információ a Spark-munkamenet beállításainak konfigurálásáról
Következő lépések
Az Apache Spark-készlet nyílt forráskódú big data számítási képességeket biztosít, ahol az adatok betölthetők, modellezhetők, feldolgozhatók és terjeszthetők a gyorsabb elemzés érdekében. Ha többet szeretne megtudni arról, hogyan hozhat létre egyet a Spark-számítási feladatok futtatásához, tekintse meg az alábbi oktatóanyagokat:
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: