Apache Sparkhoz készült dedikált Azure Synapse SQL-készlet összekötő
Introduction
Az Azure Synapse Analyticsben az Apache Sparkhoz készült Dedikált Azure Synapse SQL-készlet Csatlakozás or lehetővé teszi a nagy adathalmazok hatékony átvitelét az Apache Spark-futtatókörnyezet és a dedikált SQL-készlet között. Az összekötőt az Azure Synapse-munkaterület alapértelmezett kódtárként tartalmazza. Az összekötő implementálása nyelv használatával Scala történik. Az összekötő támogatja a Scalát és a Pythont. Ha a Csatlakozás ort más jegyzetfüzetnyelvi választási lehetőségekkel szeretné használni, használja a Spark magic parancsot – %%spark.
Magas szinten az összekötő a következő képességeket biztosítja:
- Olvasás az Azure Synapse dedikált SQL-készletéből:
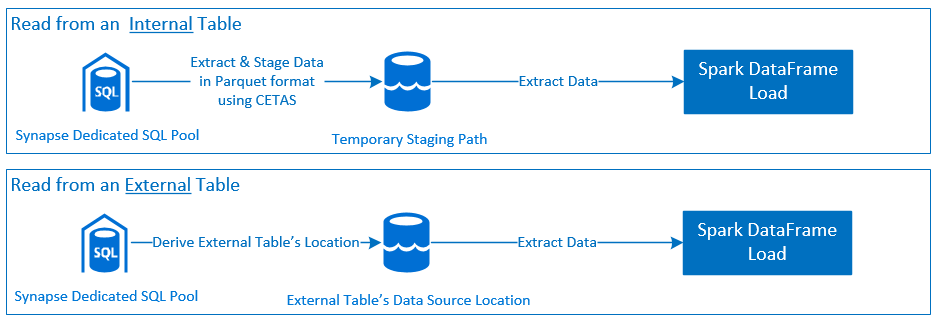
- Nagy adatkészletek olvasása a Synapse dedikált SQL-készlettábláiból (belső és külső) és nézetekből.
- Átfogó predikátumleküldési támogatás, ahol a DataFrame szűrői a megfelelő SQL-predikátum leküldéséhez lesznek leképezve.
- Oszlopmetszet támogatása.
- A lekérdezés leküldésének támogatása.
- Írás dedikált Azure Synapse SQL-készletbe:
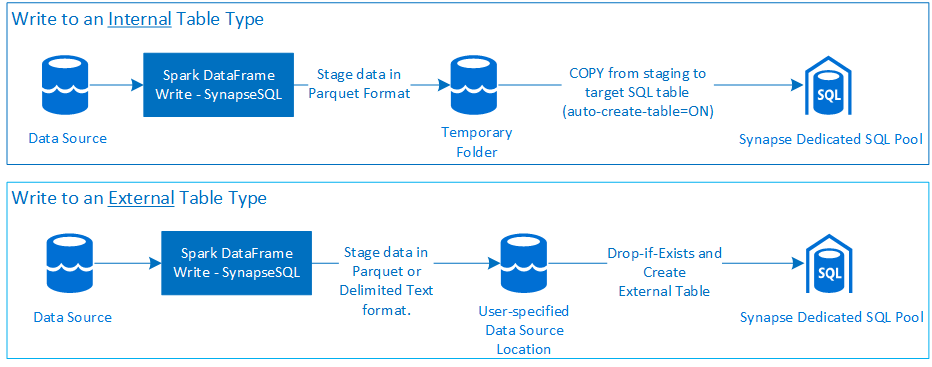
- Nagy mennyiségű adat betöltése belső és külső táblatípusokba.
- A következő DataFrame mentési mód beállításait támogatja:
AppendErrorIfExistsIgnoreOverwrite
- A külső táblázattípusba való írás támogatja a Parquet és a Tagolt szöveg fájlformátumot (például – CSV).
- Ha belső táblákba szeretne adatokat írni, az összekötő mostantól a COPY utasítást használja a CETAS/CTAS megközelítés helyett.
- Fejlesztések a végpontok közötti írási teljesítmény optimalizálásához.
- Bevezet egy opcionális visszahívási leírót (egy Scala-függvény argumentumát), amellyel az ügyfelek írás utáni metrikákat fogadhatnak.
- Néhány példa: rekordok száma, bizonyos műveletek végrehajtásának időtartama és a hiba oka.
Vezénylési megközelítés
Olvasás
Írás
Pre-requisites
Az olyan előfeltételeket, mint a szükséges Azure-erőforrások beállítása és a konfigurálásuk lépései, ebben a szakaszban tárgyaljuk.
Azure resources
Tekintse át és állítsa be a következő függő Azure-erőforrásokat:
- Azure Data Lake Storage – az Azure Synapse-munkaterület elsődleges tárfiókjaként használatos.
- Azure Synapse-munkaterület – jegyzetfüzetek létrehozása, DataFrame-alapú bejövő kimenő munkafolyamatok létrehozása és üzembe helyezése.
- Dedikált SQL-készlet (korábbi nevén SQL DW) – vállalati Adattárolás funkciókat biztosít.
- Azure Synapse kiszolgáló nélküli Spark-készlet – Spark-futtatókörnyezet, ahol a feladatok Spark-alkalmazásokként lesznek végrehajtva.
Az adatbázis előkészítése
Csatlakozás a Synapse dedikált SQL-készlet adatbázisához, és futtassa a következő beállítási utasításokat:
Hozzon létre egy adatbázis-felhasználót, amely megfelel az Azure Synapse-munkaterületre való bejelentkezéshez használt Microsoft Entra felhasználói identitásnak.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Hozzon létre sémát, amelyben táblák lesznek definiálva, hogy a Csatlakozás or sikeresen tudjon írni és olvasni a megfelelő táblákból.
CREATE SCHEMA [<schema_name>];
Authentication
Microsoft Entra ID-alapú hitelesítés
A Microsoft Entra ID-alapú hitelesítés egy integrált hitelesítési módszer. A felhasználónak sikeresen be kell jelentkeznie az Azure Synapse Analytics-munkaterületre.
Alapszintű hitelesítés
Az alapszintű hitelesítési módszer használatához a felhasználónak konfigurálnia kell a beállításokat és password a beállításokatusername. Tekintse meg az Azure Synapse dedikált SQL-készletében lévő táblákból való olvasáshoz és a táblákba való íráshoz szükséges konfigurációs paramétereket ismertető szakaszt.
Authorization
Azure Data Lake Storage Gen2
Kétféleképpen adhat hozzáférési engedélyeket az Azure Data Lake Storage Gen2 – Storage-fiókhoz:
- Szerepköralapú hozzáférés-vezérlési szerepkör – Storage Blob Data Közreműködői szerepkör
- A
Storage Blob Data Contributor Rolehozzárendelés a felhasználónak engedélyt ad az Azure Storage Blob-tárolókból való olvasásra, írásra és törlésre. - Az RBAC durva vezérlési megközelítést kínál a tároló szintjén.
- A
- Hozzáférés-vezérlési listák (ACL)
- Az ACL-megközelítés lehetővé teszi az adott mappában lévő adott elérési utak és/vagy fájlok részletes vezérlését.
- Az ACL-ellenőrzések nem lesznek kényszerítve, ha a felhasználó már kapott engedélyeket RBAC-megközelítéssel.
- Az ACL-engedélyeknek két széles típusa van:
- Hozzáférési engedélyek (adott szinten vagy objektumon alkalmazva).
- Alapértelmezett engedélyek (automatikusan alkalmazva az összes gyermekobjektumra a létrehozásuk időpontjában).
- Az engedélyek típusa:
Executelehetővé teszi a mappahierarchiák közötti váltást vagy navigálást.Readlehetővé teszi az olvasási képességet.Writelehetővé teszi az írási képességet.
- Fontos úgy konfigurálni az ACL-eket, hogy a Csatlakozás or sikeresen tudjon írni és olvasni a tárolóhelyekről.
Megjegyzés:
Ha a Synapse Workspace-folyamatokkal szeretne jegyzetfüzeteket futtatni, akkor a fent felsorolt hozzáférési engedélyeket is meg kell adnia a Synapse-munkaterület alapértelmezett felügyelt identitásához. A munkaterület alapértelmezett felügyelt identitásának neve megegyezik a munkaterület nevével.
Ha biztonságos tárfiókokkal szeretné használni a Synapse-munkaterületet, egy felügyelt privát végpontot kell konfigurálni a jegyzetfüzetből. A felügyelt privát végpontot a panel ADLS Gen2 tárfiókjának
Private endpoint connectionsszakaszábólNetworkingkell jóváhagyni.
Dedikált Azure Synapse SQL-készlet
A dedikált Azure Synapse SQL-készlettel való sikeres interakció engedélyezéséhez az alábbi engedélyezés szükséges, kivéve, ha Ön felhasználóként Active Directory Admin is konfigurálva van a dedikált SQL-végponton:
Olvasási forgatókönyv
Adja meg a felhasználónak
db_exportera rendszer által tárolt eljárástsp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Írási forgatókönyv
- Csatlakozás or a COPY paranccsal adatokat ír az előkészítésről a belső tábla felügyelt helyére.
Konfigurálja az itt ismertetett szükséges engedélyeket.
Az alábbiakban egy gyorselérési kódrészletet tekintünk meg:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- Csatlakozás or a COPY paranccsal adatokat ír az előkészítésről a belső tábla felügyelt helyére.
API-dokumentáció
Dedikált Azure Synapse SQL-készlet Csatlakozás or az Apache Sparkhoz – API-dokumentáció.
Konfigurációs lehetőségek
Az olvasási vagy írási művelet sikeres indítása és vezénylése érdekében a Csatlakozás or bizonyos konfigurációs paramétereket vár. Az objektumdefiníció – com.microsoft.spark.sqlanalytics.utils.Constants az egyes paraméterkulcsok szabványosított állandóinak listáját tartalmazza.
A használati forgatókönyvön alapuló konfigurációs beállítások listája a következő:
- Olvasás a Microsoft Entra ID-alapú hitelesítéssel
- A hitelesítő adatok automatikusan le vannak képezve, és a felhasználónak nem kell megadnia bizonyos konfigurációs beállításokat.
- A metódus háromrészes táblanévargumentumára
synapsesqlvan szükség a megfelelő táblából való olvasáshoz az Azure Synapse Dedikált SQL-készletben.
- Olvasás alapszintű hitelesítéssel
- Dedikált Azure Synapse SQL-végpont
Constants.SERVER- Dedikált Synapse SQL-készlet végpontja (kiszolgáló teljes tartományneve)Constants.USER- SQL-felhasználónév.Constants.PASSWORD- SQL felhasználói jelszó.
- Azure Data Lake Storage (Gen 2) végpont – Átmeneti mappák
Constants.DATA_SOURCE– Az adatforrás helyparaméterén beállított tárolási útvonal az adat-előkészítéshez használatos.
- Dedikált Azure Synapse SQL-végpont
- Írás Microsoft Entra ID-alapú hitelesítéssel
- Dedikált Azure Synapse SQL-végpont
- Alapértelmezés szerint a Csatlakozás or a synapse dedikált SQL-végpontot a metódus háromrészes táblanévparaméterén
synapsesqlbeállított adatbázisnév használatával következteti. - Másik lehetőségként a felhasználók megadhatja az
Constants.SERVERSQL-végpontot. Győződjön meg arról, hogy a végpont a megfelelő adatbázist tárolja a megfelelő sémával.
- Alapértelmezés szerint a Csatlakozás or a synapse dedikált SQL-végpontot a metódus háromrészes táblanévparaméterén
- Azure Data Lake Storage (Gen 2) végpont – Átmeneti mappák
- Belső táblázattípus esetén:
- Konfiguráljon vagy
Constants.TEMP_FOLDERConstants.DATA_SOURCEválasszon. - Ha a felhasználó úgy döntött, hogy megadja
Constants.DATA_SOURCEa lehetőséget, az átmeneti mappa a DataSource-ból származó érték használatávallocationlesz származtatva. - Ha mindkettő meg van adva, a rendszer a
Constants.TEMP_FOLDERbeállítás értékét fogja használni. - Átmeneti mappabeállítás hiányában a Csatlakozás or a futtatókörnyezet konfigurációja alapján fogja levezetni a következőt:
spark.sqlanalyticsconnector.stagingdir.prefix.
- Konfiguráljon vagy
- Külső táblatípus esetén:
Constants.DATA_SOURCEegy szükséges konfigurációs beállítás.- Az összekötő az adatforrás helyparaméterén beállított tárolási útvonalat használja a
locationmetódus argumentumávalsynapsesqlegyütt, és a külső táblaadatok megőrzéséhez az abszolút elérési utat használja. - Ha nincs megadva a
locationmetódus argumentumasynapsesql, akkor az összekötő a helyértéket<base_path>/dbName/schemaName/tableNamea következőképpen fogja kinyerni.
- Belső táblázattípus esetén:
- Dedikált Azure Synapse SQL-végpont
- Írás alapszintű hitelesítéssel
- Dedikált Azure Synapse SQL-végpont
Constants.SERVER- - Synapse Dedikált SQL-készlet végpontja (kiszolgáló teljes tartományneve).Constants.USER- SQL-felhasználónév.Constants.PASSWORD- SQL felhasználói jelszó.Constants.STAGING_STORAGE_ACCOUNT_KEYtársított tárfiók, amely (Constants.TEMP_FOLDERScsak belső táblatípusok) vagyConstants.DATA_SOURCE.
- Azure Data Lake Storage (Gen 2) végpont – Átmeneti mappák
- Az SQL alapszintű hitelesítési hitelesítő adatai nem vonatkoznak a tárolási végpontok elérésére.
- Ezért győződjön meg arról, hogy az Azure Data Lake Storage Gen2 című szakaszban leírtak szerint hozzárendeli a megfelelő tárhozzáférési engedélyeket.
- Dedikált Azure Synapse SQL-végpont
Kódsablonok
Ez a szakasz referenciakódsablonokat mutat be az Apache Sparkhoz készült Azure Synapse dedikált SQL-készlet Csatlakozás or használatához és meghívásához.
Megjegyzés:
A Csatlakozás or használata a Pythonban
- Az összekötő csak a Spark 3-hoz készült Pythonban támogatott. A Spark 2.4 (nem támogatott) esetében a Scala-összekötő API-val a DataFrame.createOrReplaceTempView vagy a DataFrame.createOrReplaceGlobalTempView használatával kommunikálhatunk egy DataFrame.createOrReplaceGlobalTempView használatával. Lásd: Szakasz – Materializált adatok használata cellák között.
- A visszahívási leíró nem érhető el a Pythonban.
Olvasás dedikált Azure Synapse SQL-készletből
Olvasási kérelem – synapsesql metódus aláírása
Olvasás egy táblából Microsoft Entra ID-alapú hitelesítéssel
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Olvasás egy lekérdezésből a Microsoft Entra ID-alapú hitelesítéssel
Megjegyzés:
Korlátozások a lekérdezésből való olvasás során:
- A tábla neve és lekérdezése nem adható meg egyszerre.
- Csak a kiválasztott lekérdezések engedélyezettek. A DDL- és DML-SQL-ek nem engedélyezettek.
- Az adatkeret kiválasztási és szűrési beállításait a rendszer nem küldi le a dedikált SQL-készletbe lekérdezés megadásakor.
- A lekérdezésből való olvasás csak a Spark 3.1-ben és a 3.2-ben érhető el.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Olvasás egy táblából alapszintű hitelesítéssel
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Olvasás lekérdezésből alapszintű hitelesítéssel
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Írás dedikált Azure Synapse SQL-készletbe
Írási kérelem – synapsesql metódus aláírása
A Spark 2.4.8-hoz készült Csatlakozás or verzió metódusa egy kisebb argumentumot használ, mint a Spark 3.1.2-es verziójára alkalmazva. Az alábbiakban a két metódus-aláírást követjük:
- Spark-készlet 2.4.8-es verziója
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None):Unit
- Spark-készlet 3.1.2-es verziója
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Írás Microsoft Entra ID-alapú hitelesítéssel
Az alábbiakban egy átfogó kódsablont mutatunk be, amely leírja, hogyan használható a Csatlakozás or írási forgatókönyvekhez:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Írás alapszintű hitelesítéssel
Az alábbi kódrészlet felülírja az Írás a Microsoft Entra ID-alapú hitelesítéssel című szakaszban leírt írási definíciót az írási kérelem sql alapszintű hitelesítési megközelítéssel történő elküldéséhez:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
Az alapszintű hitelesítési megközelítésben az adatok forrástárolási útvonalból való beolvasásához más konfigurációs beállításokra van szükség. Az alábbi kódrészlet egy példa az Azure Data Lake Storage Gen2-adatforrásból való olvasásra a szolgáltatásnév hitelesítő adataival:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Támogatott DataFrame mentési módok
A következő mentési módok támogatottak, ha forrásadatokat ír egy céltáblába az Azure Synapse Dedikált SQL-készletben:
- ErrorIfExists (alapértelmezett mentési mód)
- Ha a céltábla létezik, akkor a rendszer megszakítja az írást a híváskezelőnek visszaadott kivétellel. Máskülönben egy új tábla jön létre az előkészítési mappákból származó adatokkal.
- Figyelmen kívül hagyja
- Ha a céltábla létezik, akkor az írás hiba nélkül figyelmen kívül hagyja az írási kérelmet. Máskülönben egy új tábla jön létre az előkészítési mappákból származó adatokkal.
- Felülírja
- Ha a céltábla létezik, akkor a célhelyen lévő meglévő adatok helyébe az előkészítési mappákból származó adatok kerülnek. Máskülönben egy új tábla jön létre az előkészítési mappákból származó adatokkal.
- Hozzáfűzés
- Ha a céltábla létezik, az új adatok hozzá lesznek fűzve. Máskülönben egy új tábla jön létre az előkészítési mappákból származó adatokkal.
Visszahívási leíró írása
Az új írási útvonal API-módosításai egy kísérleti funkciót vezettek be, amely lehetővé teszi az ügyfél számára az írás utáni metrikák kulcs-érték> térképét. A metrikák kulcsai az új objektumdefinícióban vannak definiálva – Constants.FeedbackConstants. A metrikák JSON-sztringként kérhetők le a visszahívási leíró ( Scala Functiona). A függvény aláírása a következő:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
Az alábbiakban néhány figyelemre méltó metrikát mutatunk be (teve esetében):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Az alábbiakban egy írás utáni metrikákat tartalmazó JSON-sztringet láthat:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
További kódminták
Materializált adatok használata cellák között
A Spark DataFrame-ek createOrReplaceTempView egy másik cellában beolvasott adatok elérésére használhatók ideiglenes nézet regisztrálásával.
- Cella, ahol az adatok lekérése történik (például a Jegyzetfüzet nyelvének beállításával
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Most módosítsa a jegyzetfüzet
PySpark (Python)nyelvbeállítását, és kérje le az adatokat a regisztrált nézetből<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Válaszkezelés
Az invokálásnak synapsesql két lehetséges záróállapota van: a sikeres vagy a sikertelen állapot. Ez a szakasz azt ismerteti, hogyan kezelhetők az egyes forgatókönyvekre vonatkozó kérésválaszok.
Kérés válaszának olvasása
A befejezés után az olvasási válasz kódrészlete megjelenik a cella kimenetében. Az aktuális cellában a hiba a későbbi cellavégrehajtásokat is megszakítja. Részletes hibainformációk érhetők el a Spark-alkalmazásnaplókban.
Kérésre adott válasz írása
Alapértelmezés szerint a rendszer írási választ nyomtat a cella kimenetére. Hiba esetén az aktuális cella sikertelenként van megjelölve, és a rendszer megszakítja a későbbi cellavégrehajtásokat. A másik módszer a visszahívási leíró lehetőség átadása a synapsesql metódusnak. A visszahívási leíró programozott hozzáférést biztosít az írási válaszhoz.
Other considerations
- Ha az Azure Synapse dedikált SQL-készlettábláiból olvas:
- Fontolja meg a szükséges szűrők alkalmazását a DataFrame-en, hogy kihasználhassa a Csatlakozás or oszlopmetsző funkcióját.
- Az olvasási forgatókönyv nem támogatja a
TOP(n-rows)záradékot aSELECTlekérdezési utasítások keretezésekor. Az adatok korlátozásának lehetősége a DataFrame korlát(.) záradékának használata.- Tekintse meg a példát – Materializált adatok használata a cellák szakaszában.
- Dedikált Azure Synapse SQL-készlettáblákba való íráskor:
- Belső táblázattípusok esetén:
- A táblák ROUND_ROBIN adateloszlással jönnek létre.
- Az oszloptípusok abból a DataFrame-ből következtetnek, amely adatokat olvas be a forrásból. A sztringoszlopok a következőre vannak megfeleltetve
NVARCHAR(4000): .
- Külső táblatípusok esetén:
- A DataFrame kezdeti párhuzamossága vezérli a külső tábla adatszervezetét.
- Az oszloptípusok abból a DataFrame-ből következtetnek, amely adatokat olvas be a forrásból.
- A végrehajtók közötti jobb adateloszlás a DataFrame
repartitionparaméterének finomhangolásávalspark.sql.files.maxPartitionBytesérhető el. - Nagy adathalmazok írásakor fontos figyelembe venni a DWU teljesítményszint-beállításának hatását, amely korlátozza a tranzakció méretét.
- Belső táblázattípusok esetén:
- Az Azure Data Lake Storage Gen2 kihasználtsági trendjeinek figyelése az olvasási és írási teljesítményt befolyásoló szabályozási viselkedések észleléséhez.