Mi az Az Apache Spark az Azure Synapse Analyticsben?
Az Apache Spark egy párhuzamos feldolgozást végző keretrendszer, amely támogatja a memóriabeli feldolgozást a big data-elemző alkalmazások teljesítményének növelése érdekében. Az Azure Synapse Analyticsben üzemelő Apache Spark az Apache Spark egyik felhőbeli megvalósítása a Microsofttól. Az Azure Synapse segítségével leegyszerűsíthető a kiszolgáló nélküli Apache Spark-készletek létrehozása és konfigurálása az Azure-ban. Az Azure Storage és a 2. generációs Azure Data Lake Storage kompatibilis az Azure Synapse Spark-készleteivel. Így a Spark-készleteket az Azure-ban tárolt adatok feldolgozására használhatja.
Mi az Az Apache Spark?
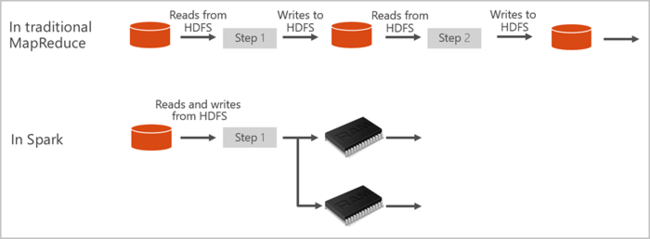
Az Apache Spark primitíveket biztosít a memórián belüli fürtszámításhoz. A Spark-feladatokkal az adatok betölthetők és gyorsítótárazhatók a memóriába, majd ismétlődő jelleggel lekérdezhetők. A memóriabeli számítástechnika gyorsabb, mint a lemezalapú alkalmazások. A Spark több programozási nyelvvel is integrálható, így az elosztott adatkészleteket, például a helyi gyűjteményeket is kezelheti. Nem kell mindent térképként rendszerezni és csökkenteni a műveletek számát. További információt az Apache Spark for Synapse videóból tudhat meg.
Az Azure Synapse Spark-készletei teljes körűen felügyelt Spark-szolgáltatást kínálnak. A Spark-készlet Azure Synapse Analyticsben való létrehozásának előnyei itt találhatók.
| Szolgáltatás | Leírás |
|---|---|
| Sebesség és hatékonyság | A Spark-példányok körülbelül 2 perc alatt kezdődnek kevesebb, mint 60 csomópont esetén, és körülbelül 5 perc alatt több mint 60 csomópont esetén. A példány alapértelmezés szerint 5 perccel az utolsó feladat futtatása után leáll, kivéve, ha egy jegyzetfüzet-kapcsolat tartja életben. |
| Könnyű létrehozás | Az Azure Synapse-ban percek alatt létrehozhat egy új Spark-készletet az Azure Portal, az Azure PowerShell vagy a Synapse Analytics .NET SDK használatával. Tekintse meg a Spark-készletek használatának első lépéseit az Azure Synapse Analyticsben. |
| Egyszerű használat | A Synapse Analytics egy nteractból származó egyéni jegyzetfüzetet tartalmaz. Ezeket a notebookokat interaktív adatfeldolgozásra és -vizualizációra használhatja. |
| REST API-k | Az Azure Synapse Analyticsben a Spark tartalmazza az Apache Livyt, egy REST API-alapú Spark-feladatkiszolgálót, amely távolról küldi el és figyeli a feladatokat. |
| Az Azure Data Lake Storage 2. generációjának támogatása | Az Azure Synapse Spark-készletei használhatják a 2. generációs Azure Data Lake Storage-t és a BLOB Storage-t. További információ a Data Lake Storage-ról: Az Azure Data Lake Storage áttekintése |
| Integráció külső integrált fejlesztői környezetekkel (IDE) | Az Azure Synapse egy IDE beépülő modult biztosít a JetBrains IntelliJ IDEA-hoz , amely hasznos alkalmazások létrehozásához és Spark-készletbe való beküldéséhez. |
| Előre betöltött Anaconda-kódtárak | Az Azure Synapse Spark-készleteiben előre telepített Anaconda-kódtárak találhatók. Az Anaconda közel 200 kódtárat biztosít gépi tanuláshoz, adatelemzéshez, vizualizációhoz és egyéb technológiákhoz. |
| Méretezhetőség | Az Azure Synapse-készletekben az Apache Spark automatikus méretezést engedélyezhet, így a készletek szükség szerint csomópontok hozzáadásával vagy eltávolításával méretezhetők. A Spark-készletek emellett adatvesztés nélkül leállíthatók, mivel minden adatot az Azure Storage vagy a Data Lake Storage tárol. |
Az Azure Synapse Spark-készletei alapértelmezés szerint a következő összetevőket tartalmazzák a készleteken:
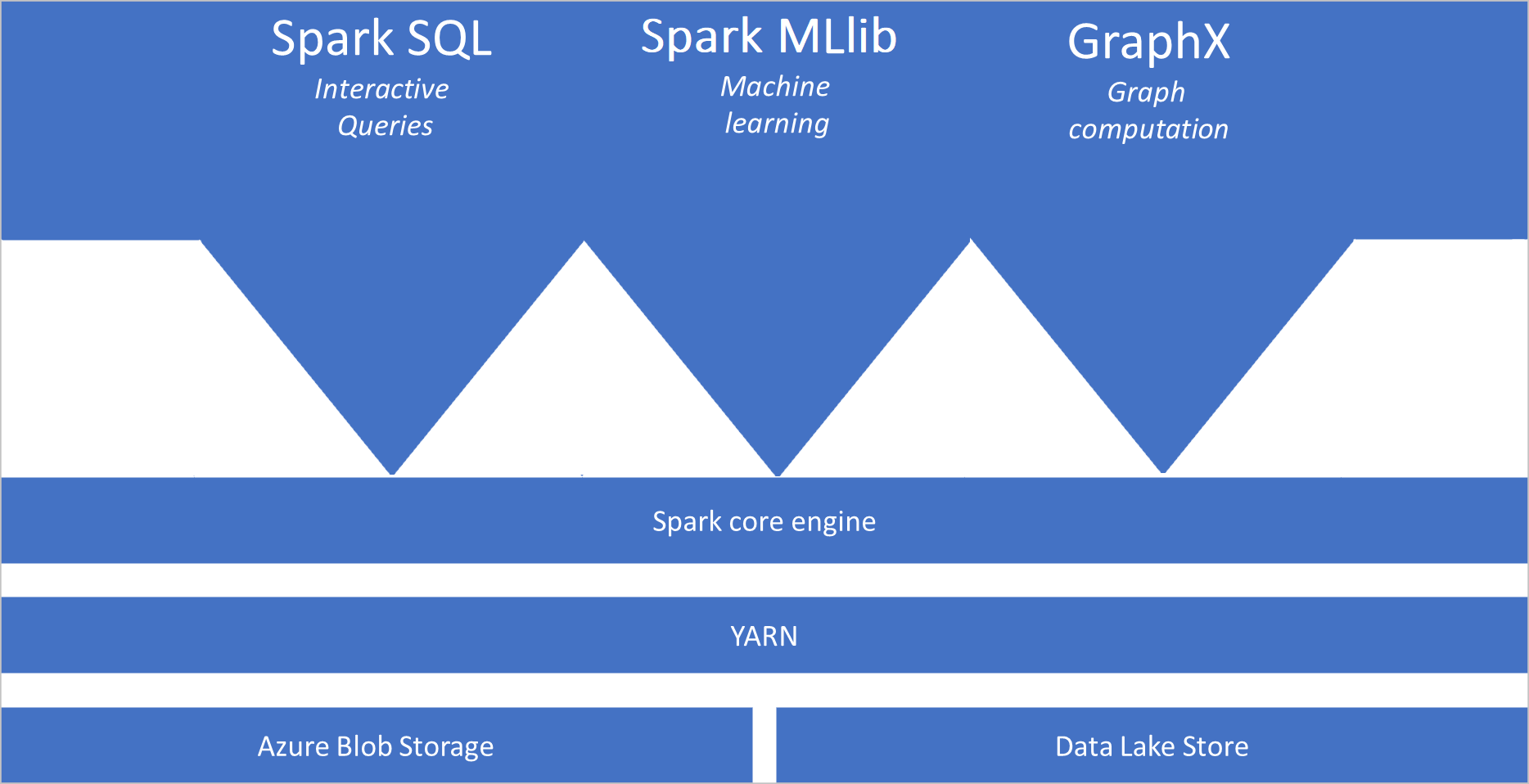
- Spark mag. A következőket tartalmazza: Spark mag, Spark SQL, GraphX és MLlib.
- Anaconda
- Apache Livy
- nteract notebook
Spark-készlet architektúrája
A Spark-alkalmazások önálló folyamatkészletként futnak egy készleten, amelyet a SparkContext fő program objektuma, az úgynevezett illesztőprogram-program koordinál.
A SparkContext fürtkezelőhöz csatlakozhat, amely erőforrásokat foglal le az alkalmazások között. A fürtkezelő az Apache Hadoop YARN. Miután csatlakozott, a Spark a készlet csomópontjaihoz szerzi be a végrehajtókat, amelyek olyan folyamatok, amelyek számításokat futtatnak, és adatokat tárolnak az alkalmazás számára. Ezután elküldi a jar- vagy Python-fájlok SparkContextáltal definiált alkalmazáskódot a végrehajtóknak. SparkContext Végül feladatokat küld a végrehajtóknak a futtatáshoz.
A SparkContext felhasználó fő függvényét futtatja, és végrehajtja a csomópontokon a különböző párhuzamos műveleteket. Ezután a SparkContext művelet eredményeit gyűjti össze. A csomópontok adatokat olvasnak és írnak a fájlrendszerből és a fájlrendszerbe. A csomópontok rugalmas elosztott adatkészletekként (RDD-kként) gyorsítótárazják az átalakított adatokat a memóriában.
A SparkContext Spark-készlethez csatlakozik, és az alkalmazás irányított aciklikus gráfmá (DAG) való konvertálásáért felelős. A gráf olyan egyedi feladatokból áll, amelyek a csomópontokon futó végrehajtói folyamaton belül futnak. Minden alkalmazás saját végrehajtói folyamatokat kap, amelyek az egész alkalmazás során fenn maradnak, és több szálon futtatják a feladatokat.
Apache Spark az Azure Synapse Analyticsben használati esetek
Az Azure Synapse Analytics Spark-készletei a következő kulcsfontosságú forgatókönyveket teszik lehetővé:
- adatmérnök-/adat-előkészítés
Az Apache Spark számos nyelvi funkciót tartalmaz a nagy mennyiségű adat előkészítésének és feldolgozásának támogatására, hogy azok értékesebbé tehetők, majd az Azure Synapse Analytics más szolgáltatásai is felhasználhassák. Ez több nyelven (C#, Scala, PySpark, Spark SQL) és a megadott kódtárakon keresztül engedélyezve van a feldolgozáshoz és a kapcsolódáshoz.
- Machine Learning
Az Apache Spark a Sparkra épülő MLlib gépi tanulási kódtárat tartalmaz, amelyet az Azure Synapse Analytics Spark-készletéből használhat. Az Azure Synapse Analytics Spark-készletei közé tartozik az Anaconda is, amely egy Python-disztribúció, amely különböző adatelemzési csomagokat tartalmaz, beleértve a gépi tanulást is. A jegyzetfüzetek beépített támogatásával ötvözve ez egy gépi tanulási alkalmazások létrehozásához ideális környezetet teremt.
- Streamelési adatok
A Synapse Spark mindaddig támogatja a Spark strukturált streamelését, amíg az Azure Synapse Spark futtatókörnyezeti kiadás támogatott verzióját futtatja. Minden feladat hét napig támogatott. Ez a kötegelt és streamelési feladatokra is vonatkozik, és általában az ügyfelek automatizálják az újraindítási folyamatot az Azure Functions használatával.
Kapcsolódó tartalom
A következő cikkekben további információt talál az Apache Sparkról az Azure Synapse Analyticsben:
- Rövid útmutató: Spark-készlet létrehozása az Azure Synapse-ban
- Rövid útmutató: Apache Spark-jegyzetfüzet létrehozása
- Oktatóanyag: Gépi tanulás az Apache Spark használatával
Feljegyzés
Néhány hivatalos Apache Spark-dokumentáció a Spark-konzol használatára támaszkodik, amely nem érhető el az Azure Synapse Sparkban. Használja inkább a jegyzetfüzetet vagy az IntelliJ-szolgáltatásokat.