Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk ajánlott eljárásokkal kapcsolatos irányelveket tartalmaz, amelyek segítenek optimalizálni a teljesítményt, csökkenteni a költségeket, és biztonságossá tenni a Data Lake Storage-kompatibilis Azure Storage-fiókot.
A data lake strukturálásával kapcsolatos általános javaslatokért tekintse meg az alábbi cikkeket:
- Az Azure Data Lake Storage áttekintése az adatkezelési és elemzési forgatókönyvhöz
- Három Azure Data Lake Storage-fiók kiépítése minden adat-kezdőzónához
Dokumentáció keresése
Az Azure Data Lake Storage nem dedikált szolgáltatás vagy fióktípus. Ez olyan képességek készlete, amelyek támogatják a nagy átviteli sebességű elemzési számítási feladatokat. A Data Lake Storage dokumentációja ajánlott eljárásokat és útmutatást nyújt ezeknek a képességeknek a használatához. A fiókkezelés minden egyéb aspektusát, például a hálózati biztonság beállítását, a magas rendelkezésre állás kialakítását és a vészhelyreállítást a Blob Storage dokumentációjában találja.
Funkciótámogatás és ismert problémák kiértékelése
Használja az alábbi mintát a fiók Blob Storage-funkciók használatára való konfigurálása során.
Tekintse át a Blob Storage szolgáltatástámogatását az Azure Storage-fiókokról szóló cikkben, és állapítsa meg, hogy egy szolgáltatás teljes mértékben támogatott-e a fiókjában. Egyes funkciók még nem támogatottak, vagy részlegesen támogatottak a Data Lake Storage-kompatibilis fiókokban. A funkciótámogatás folyamatosan bővül, ezért rendszeresen tekintse át ezt a cikket frissítésekért.
Tekintse át az Azure Data Lake Storage ismert problémáit, és ellenőrizze, hogy vannak-e korlátozások vagy speciális útmutatás a használni kívánt funkcióval kapcsolatban.
Áttekintse funkció cikkeit bármely, a Data Lake Storage-kompatibilis fiókokra vonatkozó útmutatásért.
A dokumentációban használt kifejezések ismertetése
A tartalomkészletek közötti mozgás során némi terminológiai különbséget tapasztal. A Blob Storage dokumentációjában szereplő tartalom például a blob kifejezést fogja használni fájl helyett. A tárfiókba betöltött fájlok gyakorlatilag blobokká válnak a fiókjában. Ezért a kifejezés helyes. A "blob" kifejezés azonban zavart okozhat, ha a fájl kifejezéshez van szokva. Ön is látni fogja, hogy a tároló kifejezést a fájlrendszer megnevezésére használják. Ezeket a kifejezéseket szinonimának tekinti.
Fontolja meg a prémium verziót
Ha a számítási feladatok alacsony konzisztens késést igényelnek, és/vagy nagy számú bemeneti kimeneti műveletet igényelnek másodpercenként (IOP), fontolja meg egy prémium szintű blokkblobtároló-fiók használatát. Ez a fióktípus nagy teljesítményű hardveren keresztül teszi elérhetővé az adatokat. Az adatok tárolása olyan SSD-meghajtókon történik, amelyek alacsony késésre vannak optimalizálva. Az SSD-k nagyobb átviteli sebességet biztosítanak a hagyományos merevlemezekhez képest. A prémium teljesítmény tárolási költségei magasabbak, de a tranzakciós költségek alacsonyabbak. Ezért, ha a számítási feladatok nagy számú tranzakciót hajtanak végre, akkor egy prémium teljesítményű blokkblob fiók gazdaságos lehet.
Ha a tárfiókot elemzésre fogja használni, javasoljuk, hogy az Azure Data Lake Storage-t és egy prémium szintű blokkblobtárfiókot használjon. Ezt a prémium szintű blokkblobtároló-fiók és a Data Lake Storage-kompatibilis fiók együttes használatát az Azure Data Lake Storage prémium szintű rétegének nevezzük.
Optimalizálja az adatok beillesztését
A forrásrendszerből való adatbetöltés során szűk keresztmetszetet jelenthet a forráshardver, a forráshálózati hardver vagy a tárfiókhoz való hálózati kapcsolat.
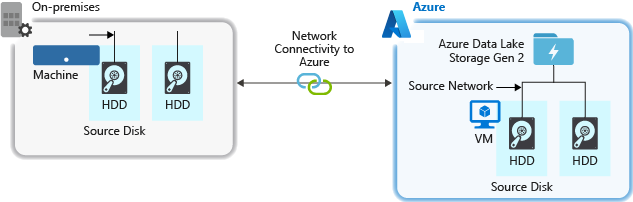
Forráshardver
Függetlenül attól, hogy helyszíni gépeket vagy virtuális gépeket (VM-eket) használ-e az Azure-ban, gondosan válassza ki a megfelelő hardvert. Lemezhardverek esetén fontolja meg a solid state meghajtók (SSD) használatát, és válassza ki a gyorsabb orsókkal rendelkező lemezhardvereket. Hálózati hardver esetén használja a leggyorsabb hálózati adapter-vezérlőket (NIC). Az Azure-ban az Azure D14-beli virtuális gépeket javasoljuk, amelyek megfelelő teljesítményű lemez- és hálózati hardverekkel rendelkeznek.
Hálózati kapcsolat a tárfiókhoz
A forrásadatok és a tárfiók közötti hálózati kapcsolat néha szűk keresztmetszet lehet. Ha a forrásadatok helyszíniek, fontolja meg egy dedikált hivatkozás használatát az Azure ExpressRoute-tal. Ha a forrásadatok az Azure-ban vannak, a teljesítmény akkor a legjobb, ha az adatok ugyanabban az Azure-régióban vannak, mint a Data Lake Storage-kompatibilis fiók.
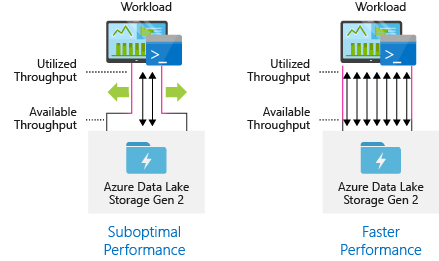
Adatbetöltési eszközök konfigurálása a maximális párhuzamosításhoz
A legjobb teljesítmény eléréséhez használja az összes rendelkezésre álló átviteli sebességet a lehető legtöbb olvasás és írás párhuzamos végrehajtásával.
Az alábbi táblázat számos népszerű betöltési eszköz kulcsbeállításait foglalja össze.
| Eszköz | Beállítások |
|---|---|
| DistCp | -m (leképező) |
| Azure Data Factory | párhuzamos másolatok |
| Sqoop | fs.azure.block.méret, -m (térképező) |
| AzCopy | AZCOPY_CONCURRENCY_VALUE |
Feljegyzés
A betöltési műveletek általános teljesítménye az adatok betöltéséhez használt eszközre jellemző egyéb tényezőktől függ. A legjobb naprakész útmutatásért tekintse meg az egyes használni kívánt eszközök dokumentációját.
A fiók méretezhető, hogy minden elemzési forgatókönyv esetében biztosítsa a szükséges átviteli sebességet. Alapértelmezés szerint egy Data Lake Storage-kompatibilis fiók elegendő átviteli sebességet biztosít az alapértelmezett konfigurációban, hogy megfeleljen a használati esetek széles körének igényeinek. Ha túllépi az alapértelmezett korlátot, a fiók konfigurálható úgy, hogy több átviteli sebességet biztosítson az Azure ügyfélszolgálatához fordulva.
Adathalmazok struktúrája
Fontolja meg az adatok szerkezetének előzetes tervezését. A fájlformátum, a fájlméret és a könyvtárstruktúra mind hatással lehet a teljesítményre és a költségekre.
Fájlformátumok
Az adatok többféle formátumban is betölthetők. Az adatok megjelenhetnek olvasható emberi formátumokban, például JSON, CSV vagy XML formátumban, vagy tömörített bináris formátumokban, például .tar.gz. Az adatok különböző méretűek is lehetnek. Az adatok nagy fájlokból (néhány terabájtból) állhatnak, például egy SQL-tábla helyszíni rendszerekből való exportálásából származó adatokból. Az adatok nagy számú apró fájl (néhány kilobájt) formájában is érkezhetnek, például az ioT-megoldások valós idejű eseményeiből származó adatok. A hatékonyságot és a költségeket a megfelelő fájlformátum és fájlméret kiválasztásával optimalizálhatja.
A Hadoop támogatja a strukturált adatok tárolására és feldolgozására optimalizált fájlformátumokat. Néhány gyakori formátum az Avro, a Parquet és az Optimalizált soroszlopos (ORC) formátum. Ezek a formátumok géppel olvasható bináris fájlformátumok. A tömörített fájlok segítenek a fájlméret kezelésében. Mindegyik fájlba egy séma van beágyazva, ami önleíróvá teszi őket. A formátumok közötti különbség az adatok tárolási módjában van. Az Avro soralapú formátumban tárolja az adatokat, a Parquet és az ORC formátum pedig oszlopos formátumban tárolja az adatokat.
Fontolja meg az Avro fájlformátum használatát olyan esetekben, amikor az I/O-minták írási nehézkesebbek, vagy a lekérdezési minták több rekordsor teljes lekérését részesítik előnyben. Az Avro formátum például jól működik egy olyan üzenetbuszsal, mint az Event Hubs vagy a Kafka, amelyek egymás után több eseményt/üzenetet írnak.
A Parquet- és ORC-fájlformátumokat akkor érdemes megfontolni, ha az I/O-minták nagyobb olvasási igényűek, vagy ha a lekérdezési minták a rekordok oszlopainak egy részhalmazára összpontosítanak. Az olvasási tranzakciók úgy optimalizálhatók, hogy adott oszlopokat kérjenek le a teljes rekord beolvasása helyett.
Az Apache Parquet egy nyílt forráskód fájlformátum, amely olvasási nehéz elemzési folyamatokhoz van optimalizálva. A Parquet oszlopos tárolási struktúrája lehetővé teszi, hogy átugorja a nem releváns adatokat. A lekérdezések sokkal hatékonyabbak, mivel szűk körben hatókörbe helyezhetik a tárolóból az elemzési motorba küldendő adatokat. Mivel a hasonló adattípusok (oszlophoz) együtt vannak tárolva, a Parquet támogatja a hatékony adattömörítési és kódolási sémákat, amelyek csökkenthetik az adattárolás költségeit. Az olyan szolgáltatások, mint az Azure Synapse Analytics, az Azure Databricks és az Azure Data Factory natív funkciókkal rendelkeznek, amelyek kihasználják a Parquet-fájlformátumok előnyeit.
Fájlméret
A nagyobb fájlok jobb teljesítményt és alacsonyabb költségeket eredményeznek.
Az olyan elemzőmotorok, mint a HDInsight, általában fájlonkénti többletterheléssel rendelkeznek, amely olyan feladatokat foglal magában, mint például a listázás, a hozzáférés ellenőrzése és a különböző metaadat-műveletek végrehajtása. Ha az adatokat annyi kis fájlban tárolja, az negatív hatással lehet a teljesítményre. Általában nagyobb méretű fájlokba rendezheti az adatokat a jobb teljesítmény érdekében (256 MB és 100 GB közötti méret). Egyes motoroknak és alkalmazásoknak problémát jelenthet a 100 GB-nál nagyobb méretű fájlok hatékony feldolgozása.
A fájlméret növelése csökkentheti a tranzakciós költségeket is. Az olvasási és írási műveletek számlázása 4 megabájtos növekményben történik, így a műveletért díjat számítunk fel, függetlenül attól, hogy a fájl 4 megabájtot vagy csak néhány kilobájtot tartalmaz-e. A díjszabással kapcsolatos információkért tekintse meg az Azure Data Lake Storage díjszabását.
Néha az adatfolyamok korlátozottan szabályozják a nyers adatokat, amelyek sok kis fájllal rendelkeznek. Általában azt javasoljuk, hogy a rendszer rendelkezik valamilyen folyamattal a kis fájlok nagyobbakba való összesítéséhez az alsóbb rétegbeli alkalmazások számára. Ha valós időben dolgoz fel adatokat, használhat egy valós idejű streamelési motort (például az Azure Stream Analyticset vagy a Spark Streaminget) egy üzenetközvetítővel (például Az Event Hubs vagy az Apache Kafka) az adatok nagyobb fájlokként való tárolásához. A kis méretű fájlok nagyobbakba való összesítésekor érdemes lehet olvasásra optimalizált formátumban menteni őket, például az Apache Parquetet az alsóbb rétegbeli feldolgozáshoz.
Címtárstruktúra
Minden számítási feladat különböző követelményeket támaszt az adatok felhasználásával kapcsolatban, de ezek a gyakori elrendezések a dolgok internetes hálózatának (IoT) használatakor, a kötegforgatókönyvekben vagy az idősoros adatok optimalizálásában.
IoT-struktúra
Az IoT-számítási feladatokban nagy mennyiségű adat lehet betöltve, amelyek számos termékre, eszközre, szervezetre és ügyfélre kiterjednek. Fontos, hogy előre megtervezze a címtár elrendezését a szervezet, a biztonság és az adatok hatékony feldolgozása érdekében a down-stream-felhasználók számára. Egy általánosan megfontolandó sablon az alábbi elrendezés lehet:
- {Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
Az Egyesült Királyságban egy repülőgépmotor leszállási telemetriája például a következő struktúrának megfelelően nézhet ki:
- UK/Planes/BA1293/Engine1/2017/08/11/12/
Ebben a példában, ha a dátumot a címtárstruktúra végére helyezi, az ACL-ek használatával könnyebben biztonságossá teheti a régiókat és a témaköröket meghatározott felhasználókra és csoportokra. Ha a dátumstruktúrát az elején helyezzük el, sokkal nehezebb lenne biztosítani ezeket a régiókat és témákat. Ha például csak az Egyesült Királyság adataihoz vagy bizonyos adatrendezési síkokhoz szeretne hozzáférést biztosítani, akkor külön engedélyt kell alkalmaznia számos könyvtárra minden egyes óránkénti könyvtár esetében. Ez a struktúra exponenciálisan növelné a könyvtárak számát az idő múlásával.
Kötegelt feladatok struktúrája
A kötegelt feldolgozás gyakran használt módszere az adatok "in" mappába való elhelyezése. Az adatok feldolgozása után az új adatokat helyezze el egy "out" könyvtárba, hogy a következő lépések felhasználhassák őket. Ezt a címtárstruktúrát néha olyan feladatokhoz használják, amelyek egyes fájlok feldolgozását igénylik, és nem feltétlenül igényelnek nagy adathalmazokon keresztüli, nagymértékben párhuzamos feldolgozást. A fent javasolt IoT-struktúrához hasonlóan egy jó könyvtárstruktúra szülőszintű könyvtárakkal rendelkezik olyan dolgokhoz, mint például a régió és a tárgy (például szervezet, termék vagy gyártó). Fontolja meg a struktúrában lévő dátumot és időt, hogy jobb szervezést, szűrt kereséseket, biztonságot és automatizálást biztosíthasson a feldolgozásban. A dátumstruktúra részletességét az határozza meg, hogy az adatok feltöltése vagy feldolgozása milyen időközönként történik, például óránként, naponta vagy akár havonta.
Előfordulhat, hogy a fájlfeldolgozás adatsérülés vagy váratlan formátum miatt sikertelen. Ilyen esetekben hasznos lehet, ha a címtárstruktúra tartalmaz egy /rossz mappát, ahová el lehet helyezni a fájlokat további ellenőrzés céljából. Előfordulhat, hogy a csoportosított feladat kezeli a hibás fájlok jelentését vagy értesítését manuális beavatkozás céljából is. Vegye figyelembe a következő sablonstruktúrát:
- {Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Bad/{yyyy}/{mm}/{dd}/{hh}/
Egy marketingcég például napi adatkivonatokat kap ügyfelei frissítéseiről Észak-Amerikából. Lehet, hogy a feldolgozás előtt és után a következőképpen fog kinézni a kódrészlet:
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
Abban az esetben, ha a kötegelt adatokat közvetlenül adatbázisokba, például Hive-be vagy hagyományos SQL-adatbázisokba dolgozzák fel, nincs szükség /in vagy /out könyvtárra, mert a kimenet már egy külön mappába kerül a Hive-tábla vagy a külső adatbázis számára. Az ügyfelek napi kivonatai például a saját címtáraikba kerülnek. Ezután egy olyan szolgáltatás, mint az Azure Data Factory, az Apache Oozie vagy az Apache Airflow , napi Hive- vagy Spark-feladatot indítana el az adatok Hive-táblába való feldolgozásához és írásához.
Idősor adatszerkezete
Hive-számítási feladatok esetén az idősoradatok partícióinak metszése segíthet egyes lekérdezéseknek az adatoknak csak egy részhalmazának olvasásában, ami javítja a teljesítményt.
Azok a folyamatok, amelyek betöltik az idősoros adatokat, gyakran strukturált elnevezéssel helyezik el fájljaikat a fájlok és mappák számára. Az alábbiakban egy gyakori példát láthatunk a dátum szerint strukturált adatokra:
/DataSet/YYYY/MM/DD/datafile_YYYY_MM_DD.tsv
Figyelje meg, hogy a datetime-információk mappákként és fájlnévként is megjelennek.
A dátum és az idő esetében az alábbiak egy gyakori minta
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
A mappa- és fájlszervezési lehetőségnek ismét a nagyobb fájlméretekhez és az egyes mappákban lévő fájlok ésszerű számához kell optimalizálnia.
Biztonság beállítása
Először tekintse át a Blob Storage-ra vonatkozó biztonsági javaslatokban szereplő javaslatokat. Az ajánlott eljárásokkal kapcsolatos útmutatást talál arról, hogyan védheti meg adatait a véletlen vagy rosszindulatú törléstől, hogyan védheti meg az adatokat tűzfal mögött, és hogyan használhatja a Microsoft Entra ID azonosítót az identitáskezelés alapjaként.
Ezután tekintse át az Azure Data Lake Storage hozzáférés-vezérlési modelljét a Data Lake Storage-kompatibilis fiókokra vonatkozó útmutatásért. Ez a cikk segít megérteni, hogyan használhatja az Azure szerepköralapú hozzáférés-vezérlési (Azure RBAC-) szerepköröket a hozzáférés-vezérlési listákkal (ACL-ekkel) együtt a hierarchikus fájlrendszer címtáraira és fájljaira vonatkozó biztonsági engedélyek kikényszerítéséhez.
Betöltés, feldolgozás és elemzés
Számos különböző adatforrás és különböző módokon lehet ezeket az adatokat beszúrni egy Data Lake Storage-kompatibilis fiókba.
Például betölthet nagy adatkészleteket a HDInsight- és Hadoop-fürtökből vagy kisebb, ad hoc adatkészleteket az alkalmazások prototípusainak készítéséhez. Különböző források, például alkalmazások, eszközök és érzékelők által létrehozott streamelt adatokat fogadhat. Az ilyen típusú adatokhoz eszközökkel rögzítheti és feldolgozhatja az adatokat eseményenként, valós időben, majd kötegekbe írhatja az eseményeket a fiókjába. Webkiszolgálói naplókat is betölthet, amelyek olyan információkat tartalmaznak, mint például az oldalkérések előzményei. A naplóadatok esetében érdemes lehet egyéni szkripteket vagy alkalmazásokat írni a feltöltésükhöz, hogy rugalmasan belefoglalhassa az adatfeltöltő összetevőt a nagyobb big data-alkalmazásba.
Miután az adatok elérhetővé válnak a fiókjában, elemzéseket futtathat az adatokon, vizualizációkat hozhat létre, és akár adatokat is letölthet a helyi gépére vagy más adattárakba, például egy Azure SQL-adatbázisba vagy egy SQL Server-példányba.
Az alábbi táblázat olyan eszközöket javasol, amelyekkel adatokat tölthet be, elemezhet, vizualizálhat és tölthet le. A táblázatban található hivatkozások segítségével útmutatást találhat az egyes eszközök konfigurálásához és használatához.
| Cél | Eszközök és eszközök – útmutató |
|---|---|
| Alkalmi adatok betöltése | Azure Portal, Azure PowerShell, Azure CLI, REST, Azure Storage Explorer, Apache DistCp, AzCopy |
| Relációs adatok betöltése | Azure Data Factory |
| Webkiszolgáló naplóinak betöltése | Azure PowerShell, Azure CLI, REST, Azure SDK-k (.NET, Java, Python és Node.js), Azure Data Factory |
| Adatok betöltése HDInsight-fürtökről | Azure Data Factory, Apache DistCp, AzCopy |
| Adatfelvétel Hadoop-fürtökről | Azure Data Factory, Apache DistCp, WANdisco LiveData Migrator for Azure, Azure Data Box |
| Nagy adathalmazok betöltése (több terabájt) | Azure ExpressRoute |
| Adatok feldolgozása és elemzése | Azure Synapse Analytics, Azure HDInsight, Databricks |
| Adatok vizualizációja | Power BI, Azure Data Lake Storage lekérdezések gyorsítása |
| Adatok letöltése | Azure Portal, PowerShell, Azure CLI, REST, Azure SDK-k (.NET, Java, Python és Node.js), Azure Storage Explorer, AzCopy, Azure Data Factory, Apache DistCp |
Feljegyzés
Ez a táblázat nem tükrözi a Data Lake Storage-t támogató Azure-szolgáltatások teljes listáját. A támogatott Azure-szolgáltatások és azok támogatási szintjének megtekintéséhez tekintse meg az Azure Data Lake Storage-t támogató Azure-szolgáltatásokat.
Telemetria monitorozása
A használat és a teljesítmény monitorozása fontos része a szolgáltatás üzembe helyezésének. Ilyenek például a gyakori műveletek, a nagy latenciájú műveletek, vagy a szolgáltatásoldali korlátozást okozó műveletek.
A tárfiók összes telemetria az Azure Storage-naplókon keresztül érhető el az Azure Monitorban. Ez a funkció integrálja a tárfiókot a Log Analytics és az Event Hubs szolgáltatással, ugyanakkor lehetővé teszi a naplók archiválását egy másik tárfiókba. A metrikák és erőforrások naplóinak és a hozzájuk tartozó sémák teljes listájának megtekintéséhez tekintse meg az Azure Storage monitorozási adatreferenciáját.
A naplók tárolásának helye attól függ, hogyan tervezi elérni őket. Ha például közel valós időben szeretné elérni a naplókat, és az Azure Monitor más metrikáival szeretné korrelálni a naplók eseményeit, a naplókat egy Log Analytics-munkaterületen tárolhatja. Ezután kérdezze le a naplókat KQL használatával, és hozza létre a lekérdezéseket, amelyek felsorolják a StorageBlobLogs táblát a munkaterületén.
Ha közel valós idejű lekérdezéshez és hosszú távú megőrzéshez is szeretné tárolni a naplókat, a diagnosztikai beállításokat úgy konfigurálhatja, hogy naplókat küldjön egy Log Analytics-munkaterületre és egy tárfiókba is.
Ha egy másik lekérdezési motoron, például a Splunkon keresztül szeretné elérni a naplókat, beállíthatja a diagnosztikai beállításokat, hogy naplókat küldjön egy eseményközpontba, és a naplókat az eseményközpontból a választott célhelyre betöltse.
Az Azure Storage-naplók az Azure Monitorban az Azure Portalon, a PowerShellben, az Azure CLI-ben és az Azure Resource Manager-sablonokban engedélyezhetők. Nagy léptékű üzemelő példányok esetén az Azure Policy a szervizelési feladatok teljes támogatásával használható. További információ: ciphertxt/AzureStoragePolicy.