Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk bemutatja, hogyan lehet hibakeresést végezni egy olyan alkalmazáson, amely c++ gyorsított masszív párhuzamosságot (C++ AMP) használ a grafikus feldolgozó egység (GPU) előnyeinek kihasználásához. Egy párhuzamos csökkentési programot használ, amely egész számok nagy tömbét összegzi. Ez az útmutató a következő feladatokat mutatja be:
- Indítsa el a GPU-hibakeresőt.
- GPU-szálak vizsgálata a GPU-szálak ablakban.
- A Párhuzamos halmok ablak használata több GPU-szál hívásveremeinek egyidejű megfigyeléséhez.
- A Párhuzamos figyelő ablak használatával egyszerre több szálon is megvizsgálhatja egyetlen kifejezés értékeit.
- GPU-szálak megjelölése, fagyasztása, felolvasztása és csoportosítása.
- Egy csempe összes szálának végrehajtása egy adott helyre a kódban.
Előfeltételek
Mielőtt elkezdené ezt az útmutatót:
Megjegyzés:
A C++ AMP fejlécek elavultak a Visual Studio 2022 17.0-s verziójától kezdve.
Az AMP-fejlécek beépítése építési hibákat fog okozni. A figyelmeztetések elnémításához a _SILENCE_AMP_DEPRECATION_WARNINGS definiálása előtt az AMP-fejléceket be kell vonni.
- Olvassa el a C++ AMP áttekintését.
- Győződjön meg arról, hogy a sorszámok megjelennek a szövegszerkesztőben. További információért lásd: A vonalszámok megjelenítése a szerkesztőben.
- Győződjön meg arról, hogy legalább Windows 8 vagy Windows Server 2012 rendszert futtat a szoftveremulátor hibakeresésének támogatásához.
Megjegyzés:
Előfordulhat, hogy a számítógép különböző neveket vagy helyeket jelenít meg a Visual Studio felhasználói felületének egyes elemeihez az alábbi utasításokban. Ezeket az elemeket a Visual Studio-kiadás és a használt beállítások határozzák meg. További információért lásd: A fejlesztői környezet személyre szabása.
A mintaprojekt létrehozása
A projekt létrehozásának utasításai a Visual Studio használt verziójától függően eltérőek lehetnek. Győződjön meg arról, hogy a megfelelő dokumentációs verzió van kiválasztva a lap tartalomjegyzéke felett.
Mintaprojekt létrehozása a Visual Studióban
A menüsávOn válassza azÚj>projekt> lehetőséget az Új projekt létrehozása párbeszédpanel megnyitásához.
A párbeszédpanel tetején állítsa a Nyelvbeállítást C++-ra, állítsa a PlatformotWindowsra, és állítsa a Projekt típusátkonzolra.
A projekttípusok szűrt listájában válassza a Konzolalkalmazás lehetőséget, majd a Tovább gombot. A következő lapon írja be
AMPMapReducea Név mezőbe a projekt nevét, és adja meg a projekt helyét, ha másikat szeretne.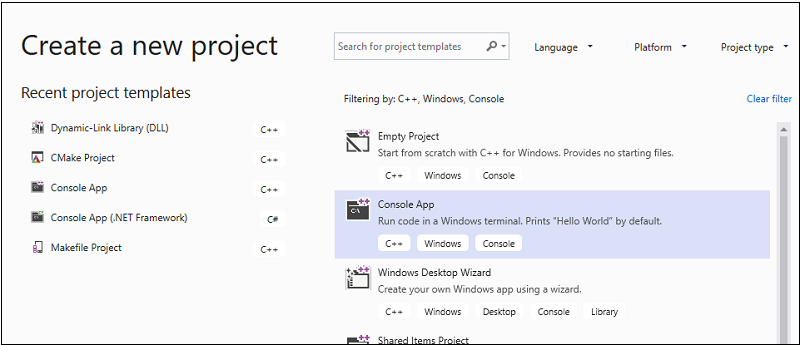
Válassza a Létrehozás gombot az ügyfélprojekt létrehozásához.
Következő:
Nyissa meg AMPMapReduce.cpp, és cserélje le a tartalmát a következő kódra.
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }A menüsávon válassza az Összes fájl>mentése lehetőséget.
A Megoldáskezelőben nyissa meg az AMPMapReduce helyi menüjét, majd válassza a Tulajdonságok lehetőséget.
A Tulajdonságlapok párbeszédpanel Konfigurációs tulajdonságok csoportjában válassza a C/C++>Előre összeállított fejlécek lehetőséget.
Az Előre összeállított fejléc tulajdonságnál válassza a Nem előre összeállított fejlécek lehetőséget, majd kattintson az OK gombra.
A menüsávon válassza a Build>Build Solution lehetőséget.
A CPU-kód hibakeresése
Ebben az eljárásban a Helyi Windows hibakereső használatával győződjön meg arról, hogy az alkalmazás CPU-kódja helyes. Az alkalmazás CPU-kódjának különösen érdekes szegmense a for ciklus a reduction_sum_gpu_kernel függvényben. Ez szabályozza a GPU-n futó faalapú párhuzamos csökkentést.
A CPU-kód hibakeresése
A Megoldáskezelőben nyissa meg az AMPMapReduce helyi menüjét, majd válassza a Tulajdonságok lehetőséget.
A Tulajdonságlapok párbeszédpanel Konfigurációs tulajdonságok csoportjában válassza a Hibakeresés lehetőséget. Ellenőrizze, hogy a Helyi Windows hibakereső van-e kiválasztva a elindítandó hibakereső listájában.
Térjen vissza a Kódszerkesztőbe.
Állítson be töréspontokat az alábbi ábrán látható kódsorokon (körülbelül 67. sor 70. sor).

CPU-töréspontokA menüsávon válassza a Hibakeresés>Hibakeresés indítása lehetőséget.
A Helyiek ablakban figyelje meg az értéket
stride_size, amíg el nem éri a töréspontot a 70. sorban.A menüsávon válassza a Hibakeresés>Hibakeresés leállítása lehetőséget.
A GPU-kód hibakeresése
Ez a szakasz bemutatja, hogyan lehet elvégezni a GPU-kód hibakeresését, amely a sum_kernel_tiled függvényben található. A GPU-kód az egyes "blokkok" egész számainak összegét számítja ki párhuzamosan.
A GPU-kód hibakeresése
A Megoldáskezelőben nyissa meg az AMPMapReduce helyi menüjét, majd válassza a Tulajdonságok lehetőséget.
A Tulajdonságlapok párbeszédpanel Konfigurációs tulajdonságok csoportjában válassza a Hibakeresés lehetőséget.
Az Hibakereső indításhoz listában válassza a Helyi Windows Hibakereső lehetőséget.
A Hibakereső típusa listában ellenőrizze, hogy az Automatikus beállítás van-e kiválasztva.
Az automatikus érték az alapértelmezett érték. A Windows 10 előtti verziókban a GPU Csak a szükséges érték az Automatikus helyett.
Válassza az OK gombot.
Állítson be egy töréspontot a 30. sorban az alábbi ábrán látható módon.

GPU-töréspontA menüsávon válassza a Hibakeresés>Hibakeresés indítása lehetőséget. A CPU-kód 67- és 70-es soraiban lévő töréspontok nem lesznek végrehajtva a GPU-hibakeresés során, mert ezek a kódsorok a processzoron futnak.
A GPU-szálak ablakának használata
A GPU-szálak ablak megnyitásához a menüsávon válassza aWindows>GPU-szálak> lehetőséget.
A MEGJELENŐ GPU-szálak ablakban ellenőrizheti a GPU-szálak állapotát.
Rögzítse a GPU Threads ablakot a Visual Studio alján. Válassza a Szálkapcsoló kibontása gombot a csempe és a szál szövegmezőinek megjelenítéséhez. A GPU-szálak ablak az aktív és letiltott GPU-szálak teljes számát jeleníti meg, ahogyan az alábbi ábrán is látható.

GPU-szálak ablakEhhez a számításhoz 313 csempe lesz lefoglalva. Minden csempe 32 szálat tartalmaz. Mivel a helyi GPU-hibakeresés szoftveremulátoron történik, négy aktív GPU-szál létezik. A négy szál egyszerre hajtja végre az utasításokat, majd továbblép a következő utasításra.
A GPU Threads ablakban négy GPU-szál aktív, és 28 GPU-szál blokkolva van a tile_barrier::wait utasításnál, amely kb. a 21. sorban van definiálva (
t_idx.barrier.wait();). Mind a 32 GPU-szál az első csempéhez tartozik.tile[0]Egy nyíl az aktuális szálat tartalmazó sorra mutat. Ha másik szálra szeretne váltani, használja az alábbi módszerek egyikét:A GPU-szálak ablakban a váltani kívánt szál sorában nyissa meg a helyi menüt, és válassza a Váltás szálra parancsot. Ha a sor egynél több szálat jelöl, a szálkoordináta alapján válthat az első szálra.
Írja be a szál csempéjének és szálértékeinek értékét a megfelelő szövegmezőkbe, majd válassza a Szálváltás gombot.
A Hívásverem ablak az aktuális GPU-szál hívásveremét jeleníti meg.
A Párhuzamos halmok ablak használata
A Párhuzamos halmok ablak megnyitásához a menüsávon válassza aWindows>Párhuzamos halmok> lehetőséget.
A Párhuzamos verem ablak használatával egyszerre több GPU-szál veremkereteit is megvizsgálhatja.
Rögzítse a Párhuzamos halmok ablakot a Visual Studio alján.
Győződjön meg arról, hogy a Threads ki legyen jelölve a bal felső sarokban lévő listában. Az alábbi ábrán a Párhuzamos verem ablakban látható a GPU-szálak ablakban bemutatott GPU-szálak hívásveremre fókuszáló nézete.

Párhuzamos halmok ablak32 szál ment
_kernel_stuba lambda kifejezéshez aparallel_for_eachfüggvényhívásban, majd asum_kernel_tiledfüggvényhez, ahol a párhuzamos csökkentés valósul meg. A 32 szálból 28 jutott el aztile_barrier::waitutasításig, és a 22. sorban továbbra is blokkolva marad, míg a másik négy szál aktív marad a függvényben asum_kernel_tiled30. sorban.Megvizsgálhatja a GPU-szál tulajdonságait. Ezek a GPU-szálak ablakban érhetők el a párhuzamos veremek ablak gazdag adattippjében. Ha látni szeretné őket, vigye az egérmutatót a veremkeretre
sum_kernel_tiled. Az alábbi ábrán az adatleírás látható.
GPU-szál adatleírásaA Párhuzamos halmok ablakról további információt a Párhuzamos halmok ablak használata című témakörben talál.
A Párhuzamos figyelő ablak használata
A Párhuzamos figyelő ablak megnyitásához a menüsávon válassza a Hibakeresés>Windows>Párhuzamos figyelő>Párhuzamos figyelő 1 lehetőséget.
A Párhuzamos figyelő ablak segítségével több szálon is megvizsgálhatja egy kifejezés értékeit.
A Párhuzamos figyelő 1 ablak lehorgonyzása a Visual Studio aljára. A Párhuzamos figyelő ablak táblázatában 32 sor található. Mindegyik egy GPU-szálnak felel meg, amely a GPU Threads ablakban és a Párhuzamos verem ablakban is megjelent. Most megadhatja azokat a kifejezéseket, amelyek értékeit meg szeretné vizsgálni mind a 32 GPU-szálon.
Válassza a Figyelő hozzáadása oszlopfejlécet, írja be
localIdx, majd válassza az Enter billentyűt.Jelölje ki ismét a Add Watch oszlopfejlécet, írja be
globalIdx, majd nyomja meg az Enter billentyűt.Jelölje ki ismét a Add Watch oszlopfejlécet, írja be
localA[localIdx[0]], majd nyomja meg az Enter billentyűt.Egy adott kifejezés szerint rendezhet, ha kiválasztja a megfelelő oszlopfejlécet.
Válassza ki a localA[localIdx[0]] oszlopfejlécet az oszlop rendezéséhez. Az alábbi ábrán a localA[localIdx[0]] szerinti rendezés eredményei láthatók.

Rendezési eredményekA Párhuzamos figyelő ablakban lévő tartalmat exportálhatja az Excelbe az Excel gombra kattintva, majd a Megnyitás az Excelben parancsra kattintva. Ha telepítve van az Excel a fejlesztői számítógépen, a gomb megnyitja a tartalmat tartalmazó Excel-munkalapot.
A Párhuzamos figyelő ablak jobb felső sarkában található egy szűrővezérlő, amellyel logikai kifejezések használatával szűrheti a tartalmat. Írja be
localA[localIdx[0]] > 20000a szűrővezérlő szövegmezőbe, majd válassza az Enter billentyűt.Az ablak mostantól csak olyan szálakat tartalmaz, amelyeken az
localA[localIdx[0]]érték nagyobb, mint 20000. A tartalmat továbbra is azlocalA[localIdx[0]]oszlop rendezi, amely a korábban kiválasztott rendezési művelet.
GPU-szálak megjelölése
Meghatározott GPU-szálak megjelölésével megjelölheti őket a GPU-szálak ablakában, a Párhuzamos figyelő ablakban vagy a Párhuzamos verem ablak adatleírásában . Ha a GPU-szálak ablak egy sora több szálat tartalmaz, a sor megjelölése a sorban található összes szálat jelöli.
GPU-szálak megjelölése
Jelölje ki a [Szál] oszlopfejlécet a Párhuzamos figyelő 1 ablakban a csempeindex és a szálindex szerinti rendezéshez.
A menüsávon válassza a hibakeresés és a > lehetőséget, amely miatt az a négy aktív szál a következő akadályhoz lép, amely az AMPMapReduce.cpp 32. sorában van definiálva.
Válassza ki a jelölő szimbólumot a sor bal oldalán, amely az aktív négy szálat tartalmazza.
Az alábbi ábrán a GPU Threads ablak négy aktív megjelölt szála látható.

Aktív szálak a GPU-szálak ablakbanA Párhuzamos figyelő ablak és a Párhuzamos verem ablak adattippje egyaránt jelzi a megjelölt szálakat.
Ha a megjelölt négy szálra szeretne összpontosítani, kiválaszthatja, hogy csak a megjelölt szálak jelenjenek meg. Ez korlátozza a GPU-szálak, a Párhuzamos figyelő és a Párhuzamos verem ablakokban megjelenő elemet.
Válassza a Megjelölt csak megjelenítése gombot bármelyik ablakban vagy a Hibakeresési hely eszköztáron. Az alábbi ábrán a Csak megjelölt elemek gomb látható a Hibakeresési eszköztáron.

Csak megjelölt gomb megjelenítéseMost a GPU-szálak, a Parallel Watch és a Párhuzamos verem ablakok csak a megjelölt szálakat jelenítik meg.
GPU-szálak fagyasztása és felolvasztása
A GPU Threads ablakból vagy a Párhuzamos figyelő ablakból lefagyaszthatja (felfüggesztheti) és felolvassa (folytathatja) a GPU-szálakat. A CPU-szálakat ugyanúgy fagyaszthatja és felolvaszthatja; további információ : Útmutató: A Szálak ablak használata.
GPU-szálak befagyasztása és felolvasztása
Az összes szál megjelenítéséhez válassza a Megjelölt csak megjelenítése gombot.
A menüsávon válassza aFolytatás> lehetőséget.
Nyissa meg az aktív sor helyi menüjét, majd válassza a Rögzítés lehetőséget.
A GPU-szálak ablakának alábbi ábrája azt mutatja, hogy mind a négy szál le van fagyasztva.

Fagyasztott szálak a GPU-szálak ablakábanHasonlóképpen, a Párhuzamos figyelő ablak azt mutatja, hogy mind a négy szál le van fagyasztva.
A menüsávOn válassza a Folytatás hibakeresése> lehetőséget, hogy a következő négy GPU-szál a 22. sorban haladjon át az akadályon, és elérje a töréspontot a 30. sorban. A GPU Threads ablak azt mutatja, hogy a négy korábban fagyott szál fagyasztva marad, és aktív állapotban marad.
A menüsávon válassza a Hibakeresés, Folytatás lehetőséget.
A Parallel Watch ablakból önálló vagy több GPU-szálat is feloldhat.
GPU-szálak csoportosítása
A GPU-szálak ablak egyik szálának helyi menüjében válassza a Csoportosítás lehetőséget Cím szerint.
A GPU-szálak ablakban lévő szálak cím szerint vannak csoportosítva. A cím megfelel annak az utasításnak, amely szétszereli a szálak minden csoportját. 24 szál a 22. sorban található, ahol a tile_barrier::wait metódus végrehajtása történik. A 32. sorban 12 szál van a sorompóra vonatkozó utasításban. Négy szál van megjelölve. Nyolc szál van a töréspontnál a 30- as sorban. Ezek közül négy szál le van fagyasztva. Az alábbi ábrán a GPU Threads ablak csoportosított szálai láthatók.

Csoportosított szálak a GPU-szálak ablakbanA Csoportosítás műveletet a Párhuzamos figyelő ablak adatmátrixának helyi menüje megnyitásával is elvégezheti. Válassza a Csoportosítás szempontja lehetőséget, majd válassza ki a szálak csoportosítási módjának megfelelő menüelemet.
Az összes szál futtatása egy adott helyre a Kódban
Egy adott csempe összes szálát a kurzort tartalmazó vonalra futtatja az Aktuális csempe futtatása kurzorhoz paranccsal.
Az összes szál a kurzor által megjelölt helyre való futtatásához
A fagyasztott szálak shortcut menüjében válassza a Felolvasztás lehetőséget.
A Kódszerkesztőben helyezze a kurzort a 30. sorba.
A Kódszerkesztő helyi menüjében válassza az Aktuális csempe futtatása kurzorhoz lehetőséget.
A 21. sorban lévő sorompónál korábban blokkolt 24 szál továbbhaladt a 32. sorba. Ez a GPU Threads ablakban jelenik meg.
Lásd még
A C++ AMP áttekintése
GPU-kód hibakeresése
Útmutató: A GPU-szálak ablak használata
Útmutató: A Párhuzamos figyelő ablak használata
C++ AMP-kód elemzése az egyidejűségi vizualizációval