Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Megjegyzés:
A Fabric Runtime 2.0 jelenleg kísérleti előzetes verzióban érhető el. További információkért tekintse meg a korlátozásokat és a megjegyzéseket.
A Fabric Runtime zökkenőmentes integrációt biztosít a Microsoft Fabric-ökoszisztémán belül, és robusztus környezetet kínál az Apache Spark által működtetett adatelemzési és adatelemzési projektekhez.
Ez a cikk bemutatja a Fabric Runtime 2.0 Kísérleti (előzetes verzió) verzióját, amely a Microsoft Fabric big data-számításokhoz tervezett legújabb futtatókörnyezete. Kiemeli azokat a főbb funkciókat és összetevőket, amelyek miatt ez a kiadás jelentős előrelépést jelent a méretezhető elemzések és a speciális számítási feladatok számára.
A Fabric Runtime 2.0 az alábbi összetevőket és frissítéseket tartalmazza az adatfeldolgozási képességek javítása érdekében:
- Apache Spark 4.0
- Operációs rendszer: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.12
- Delta Lake: 4.0
Runtime 2.0 engedélyezése
A Futtatókörnyezet 2.0 a munkaterület vagy a környezeti elem szintjén is engedélyezhető. A munkaterület beállításával alapértelmezettként alkalmazza a Runtime 2.0-t a munkaterület összes Spark-számítási feladatára. Másik lehetőségként hozzon létre egy olyan környezeti elemet a Runtime 2.0-val, amely adott jegyzetfüzetekkel vagy Spark-feladatdefiníciókkal használható, amely felülírja a munkaterület alapértelmezett beállítását.
Runtime 2.0 engedélyezése a Munkaterület beállításai között
A Runtime 2.0 beállítása alapértelmezettként a teljes munkaterületen:
Lépjen a Munkaterület beállításai lapra a Háló munkaterületen belül.
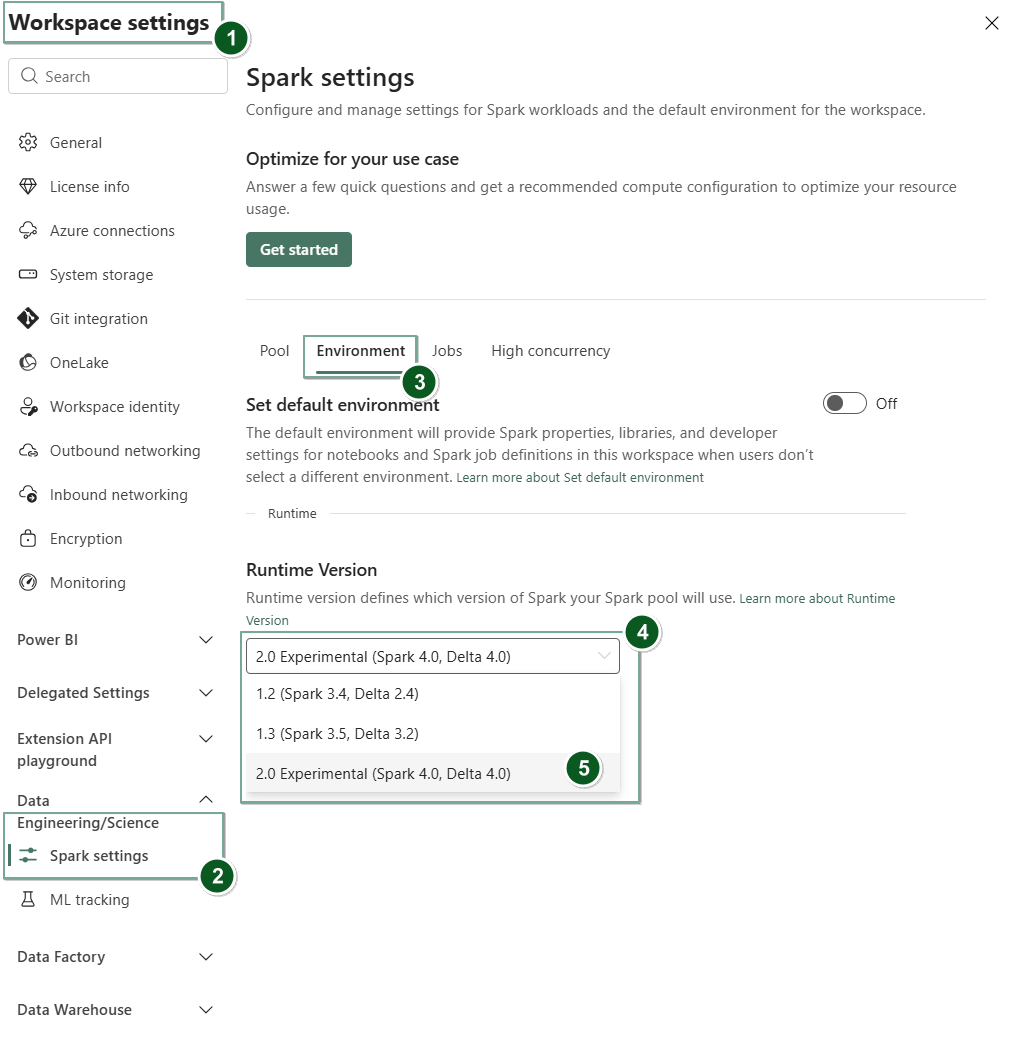
Nyissa meg az Adatelemzés/Tudomány lapot, és válassza a Spark-beállításokat.
Válassza a Környezet lapot.
A Futtatókörnyezet verzió legördülő listájában válassza a 2.0 Kísérleti verziót (Spark 4.0, Delta 4.0), és mentse a módosításokat. Ez a művelet a Runtime 2.0-t állítja be a munkaterület alapértelmezett futtatókörnyezeteként.

A futtatókörnyezet 2.0 engedélyezése egy környezeti elemben
A Runtime 2.0 használata adott jegyzetfüzetekkel vagy Spark-feladatdefiníciókkal:
Hozzon létre egy új környezet elemet, vagy nyisson meg egy meglévőt.
A Futtatókörnyezet legördülő menüben válassza a 2.0 Kísérleti (Spark 4.0, Delta 4.0) lehetőséget, majd
SavealkalmazzaPublisha változtatásokat.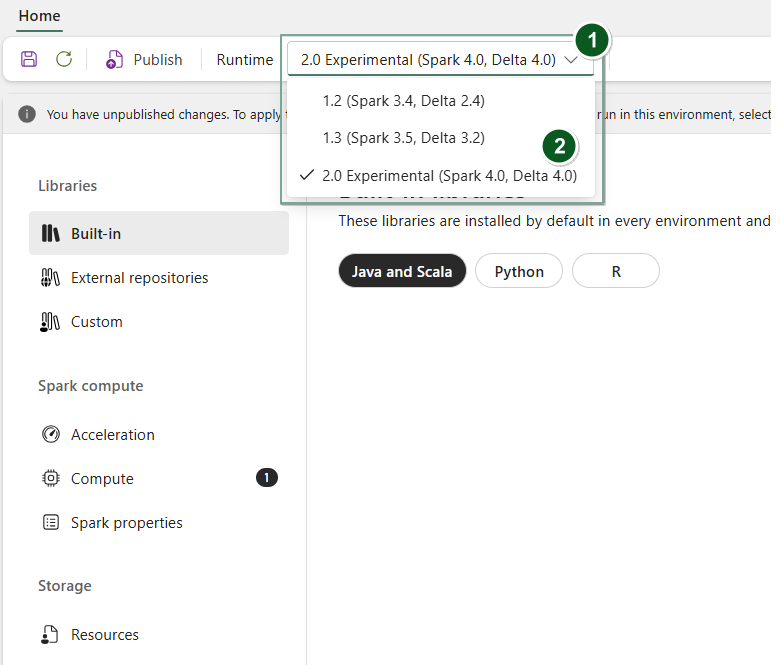
Fontos
A Spark 2.0-munkamenetek indítása körülbelül 2-5 percet vehet igénybe, mivel a kezdőkészletek nem részei a korai kísérleti kiadásnak.
Ezután a környezet elemet használhatja a saját
NotebookvagySpark Job Definitionesetében.

Most már kísérletezhet a Fabric Runtime 2.0-ban (Spark 4.0 és Delta Lake 4.0) bevezetett legújabb fejlesztésekkel és funkciókkal.
Kísérleti nyilvános előzetes verzió
A Fabric runtime 2.0 kísérleti előzetes verziója korai hozzáférést biztosít a Spark 4.0 és a Delta Lake 4.0 új funkcióihoz és API-iihoz. Az előzetes verzióval azonnal használhatja a Spark-alapú legújabb fejlesztéseket, így zökkenőmentes felkészülést és átmenetet biztosít az olyan jövőbeli változásokhoz, mint a Java, a Scala és a Python újabb verziói.
Jótanács
Naprakész információkért, a módosítások részletes listájáért és a Fabric-futtatókörnyezetekhez kapcsolódó konkrét kibocsátási megjegyzésekért tekintse meg és iratkozzon fel a Spark Runtimes kiadásaira és frissítéseire.
Korlátozások és megjegyzések
A Fabric Runtime 2.0 jelenleg egy kísérleti nyilvános előzetes verzióban érhető el, amelynek célja, hogy a felhasználók felfedezzék és kipróbálják a Spark és a Delta Lake legújabb funkcióit és API-jait a fejlesztési vagy tesztelési környezetekben. Bár ez a verzió hozzáférést biztosít az alapvető funkciókhoz, bizonyos korlátozások vannak érvényben:
Spark 4.0-munkameneteket használhat, kódot írhat jegyzetfüzetekbe, ütemezhet Spark-feladatdefiníciókat, és használhatja a PySpark, a Scala és a Spark SQL használatát. Az R nyelv azonban ebben a korai kiadásban nem támogatott.
A kódtárakat közvetlenül a kódban telepítheti pip és conda használatával. A Spark-beállításokat a jegyzetfüzetek %%configure beállításai és a Spark-feladatdefiníciók (SJD-k) segítségével állíthatja be.
A Delta Lake 4.0-val olvashat és írhat a Lakehouse-ban, de a korai kiadás nem tartalmaz olyan speciális funkciókat, mint a V-order, a natív Parquet-írás, az automatikus tömörítés, az írás optimalizálása, az alacsony átrendezésű összevonás, az egyesítés, a sémafejlődés és az időutazás.
A Spark Advisor jelenleg nem érhető el. Ebben a korai kiadásban azonban támogatottak az olyan monitorozási eszközök, mint a Spark felhasználói felülete és a naplók.
Az olyan funkciók, mint a Data Science-integrációk, például a Copilot és az olyan összekötők, mint a Kusto, az SQL Analytics, a Cosmos DB és a MySQL Java Connector, jelenleg nem támogatottak ebben a korai kiadásban. Az adatelemzési kódtárak PySpark-környezetekben nem támogatottak. A PySpark csak alapszintű Conda beállítással működik, amely magában foglalja a PySparkot külön kódtárak nélkül.
A környezetelemekkel és a Visual Studio Code-tal való integráció ebben a korai kiadásban nem támogatott.
Nem támogatja az adatok beolvasását és írását általános célú v2 (GPv2) Azure Storage-fiókokba WASB- vagy ABFS-protokollokkal.
Megjegyzés:
Ossza meg visszajelzését a Fabric Runtime-ról az Ötletek platformon. Mindenképpen említse meg a hivatkozott verziót és kiadási szakaszt. Nagyra értékeljük a közösségi visszajelzéseket, és a szavazatok alapján rangsoroljuk a fejlesztéseket, biztosítva a felhasználói igényeknek való megfelelést.
Főbb kiemelések
Apache Spark 4.0
Az Apache Spark 4.0 jelentős mérföldkövet jelent a 4.x sorozat beiktatási kiadásaként, amely a nyüzsgő nyílt forráskódú közösség kollektív erőfeszítéseit testesíti meg.
Ebben a verzióban a Spark SQL jelentős mértékben bővül az SQL-számítási feladatok expresszivitásának és sokoldalúságának fokozására tervezett hatékony új funkciókkal, például a VARIANT adattípus támogatásával, az SQL felhasználó által definiált függvényeivel, a munkamenet-változókkal, a csőszintaxissal és a sztringek rendezéssel. A PySpark folyamatosan elkötelezett annak érdekében, hogy bővítse a funkciók körét és javítsa a fejlesztői élményt, például natív plotting API-t, új Python-adatforrás API-t, a Python UDTF-k támogatását, a PySpark UDF-ekhez való egységes profilkészítést, és számos egyéb fejlesztést hoz létre. A strukturált streamelés olyan kulcsfontosságú kiegészítésekkel bővül, amelyek nagyobb felügyeletet és egyszerű hibakeresést biztosítanak, nevezetesen az Tetszőleges állapot API v2 bevezetése a rugalmasabb állapotkezeléshez és az állapotadatforráshoz a könnyebb hibakeresés érdekében.
A teljes listát és a részletes módosításokat itt tekintheti meg: https://spark.apache.org/releases/spark-release-4-0-0.html.
Megjegyzés:
A Spark 4.0-ban a SparkR elavult, és lehetséges, hogy egy későbbi verzióban el lesz távolítva.
Delta Lake 4.0
A Delta Lake 4.0 együttes elkötelezettséget jelent, hogy a Delta Lake több formátumban is átjárhatóvá, könnyebben kezelhetővé és teljesíthetőbbé váljon. A Delta 4.0 egy mérföldköves kiadás, amely hatékony új funkciókkal, teljesítményoptimalizálásokkal és a nyitott data lakehouse-k jövőjének alapvető fejlesztéseivel van tele.
A Delta Lake 3.3-ban és 4.0-s verzióban bevezetett teljes listát és részletes módosításokat itt tekintheti meg: https://github.com/delta-io/delta/releases/tag/v3.3.0. https://github.com/delta-io/delta/releases/tag/v4.0.0.
Fontos
A Delta Lake 4.0-specifikus funkciói kísérleti jellegűek, és csak Spark-élményeken működnek, például jegyzetfüzeteken és Spark-feladatdefiníciókon. Ha ugyanazt a Delta Lake-táblát több Microsoft Fabric-számítási feladatban is használnia kell, ne engedélyezze ezeket a funkciókat. Ha többet szeretne megtudni arról, hogy mely protokollverziók és szolgáltatások kompatibilisek az összes Microsoft Fabric-szolgáltatással, olvassa el a Delta Lake táblaformátum együttműködési lehetőségeit.
Kapcsolódó tartalom
- Apache Spark futtatási környezetek a Fabric rendszerben – Áttekintés, verziózás és több futtatáskörnyezet támogatása
- A Spark Core migrálási útmutatója
- SQL, Adathalmazok és DataFrame migrálási útmutatók
- Strukturált streamelési migrálási útmutató
- MLlib (Machine Learning) migrálási útmutató
- A PySpark (Python a Sparkon) migrálási útmutatója
- SparkR (R a Sparkon) migrálási útmutatója