Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ebben az oktatóanyagban megtudhatja, hogyan végezhet feltáró adatelemzést (EDA) az adatok vizsgálatához és vizsgálatához, miközben az adatvizualizációs technikák használatával összegzi annak főbb jellemzőit.
A seaborn, egy Python-adatvizualizációs kódtárat fog használni, amely magas szintű felületet biztosít a vizualizációk adatkereteken és tömbökön való létrehozásához. További információkért a seaborn-ról lásd: Seaborn: Statistical Data Visualization.
A Data Wrangleris használható, amely egy jegyzetfüzet-alapú eszköz, amely magával ragadó élményt nyújt a feltáró adatok elemzéséhez és tisztításához.
Az oktatóanyag fő lépései a következők:
- Olvassa el a lakehouse-beli delta táblából tárolt adatokat.
- Spark DataFrame konvertálása Pandas DataFrame-gé, amelyet a Python-vizualizációs kódtárak támogatnak.
- A Data Wrangler használatával elvégezheti a kezdeti adattisztítást és -átalakítást.
- Feltáró adatelemzés végrehajtása
seabornhasználatával.
Előfeltételek
Szerezz egy Microsoft Fabric-előfizetést. Vagy regisztráljon egy ingyenes Microsoft Fabric próbaverzióra.
Jelentkezzen be a Microsoft Fabric.
A kezdőlap bal alsó részén található élménykapcsolóval válthat Fabricre.

Ez az oktatóanyag-sorozat 5. része. Az oktatóanyag elvégzéséhez először végezze el a következőket:
Követés a jegyzetfüzetben
2-explore-cleanse-data.ipynb az oktatóanyagot kísérő jegyzetfüzet.
Az oktatóanyaghoz mellékelt jegyzetfüzet megnyitásához kövesse az A rendszer előkészítése adatelemzési oktatóanyagokhoz utasításait, hogy a jegyzetfüzetet importálja a munkaterületére.
Ha inkább erről a lapról másolja és illessze be a kódot, létrehozhat egy új jegyzetfüzetet.
A kód futtatása előtt mindenképpen csatoljon egy lakehouse-t a jegyzetfüzethez.
Fontos
Csatolja ugyanazt a tóházat, amelyet az 1. részben használt.
Nyers adatok olvasása a lakehouse rendszerből
Nyers adatok olvasása a tóház Fájlok szakaszából. Ezeket az adatokat az előző jegyzetfüzetbe töltötte fel. A kód futtatása előtt győződjön meg arról, hogy az 1. részben használt tóházat csatolta ehhez a jegyzetfüzethez.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Pandas DataFrame létrehozása az adatkészletből
Konvertálja a spark DataFrame-et pandas DataFrame-gé a könnyebb feldolgozás és vizualizáció érdekében.
df = df.toPandas()
Nyers adatok megjelenítése
Ismerkedjen meg a nyers adatokkal display, végezze el az alapvető statisztikákat, és jelenítsen meg diagramnézeteket. Vegye figyelembe, hogy először importálnia kell a szükséges kódtárakat, például Numpy, Pnadas, Seabornés Matplotlib adatelemzéshez és vizualizációhoz.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
A Data Wrangler használata kezdeti adattisztításhoz
A pandas Dataframe-ek felfedezéséhez és átalakításához indítsa el közvetlenül a jegyzetfüzetből a Data Wranglert.
jegyzet
Nem nyitható meg a Data Wrangler, amíg a jegyzetfüzet kernele foglalt. A cellavégrehajtásnak a Data Wrangler elindítása előtt le kell fejeződnie.
- A jegyzetfüzet menüszalagján Adatok lapon válassza a Data Wrangler megnyitásalehetőséget. Megjelenik a szerkesztésre elérhető aktivált pandas DataFrame-ek listája.
- Válassza ki a Data Wranglerben megnyitni kívánt DataFrame-et. Mivel ez a jegyzetfüzet csak egy DataFrame-et tartalmaz,
df, válassza adflehetőséget.
A Data Wrangler elindítja és leíró áttekintést készít az adatokról. A középen lévő táblázat az egyes adatoszlopokat jeleníti meg. A táblázat melletti Összegzés panel a DataFrame-ről jelenít meg információkat. Amikor kijelöl egy oszlopot a táblában, az összefoglaló a kijelölt oszlopra vonatkozó információkkal frissül. Bizonyos esetekben a megjelenített és összegzett adatok a DataFrame csonkolt nézete lesznek. Ha ez történik, figyelmeztető kép jelenik meg az összefoglaló panelen. Vigye az egérmutatót erre a figyelmeztetésre ahhoz, hogy megtekintse a helyzetet magyarázó szöveget.

Minden műveletet kattintással alkalmazhat, valós időben frissítheti az adatmegjelenítést, és olyan kódot hozhat létre, amelyet újrahasználható függvényként menthet vissza a jegyzetfüzetbe.
A szakasz további része végigvezeti a Data Wrangler adattisztításának lépésein.
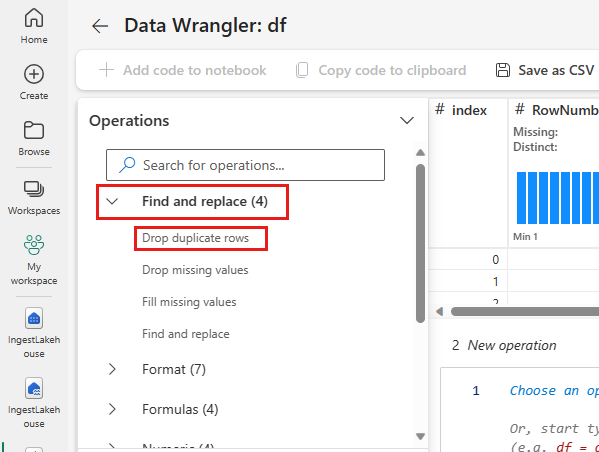
Ismétlődő sorok elvetése
A bal oldali panelen az adathalmazon végrehajtható műveletek listája (például keresése és cseréje, Formátum, Képletek, Numerikus) listája látható.
Bontsa ki keresése és cseréje, majd válassza Ismétlődő sorok elvetéselehetőséget.
Megjelenik egy panel, amelyen kiválaszthatja azoknak az oszlopoknak a listáját, amelyeket össze szeretne hasonlítani egy ismétlődő sor definiálásához. Válassza RowNumber és CustomerIdlehetőséget.
A középső panelen a művelet eredményeinek előnézete látható. Az előnézet alatt található a művelet végrehajtásához szükséges kód. Ebben az esetben az adatok változatlannak tűnnek. Mivel azonban rövidített nézetet lát, továbbra is érdemes alkalmazni a műveletet.
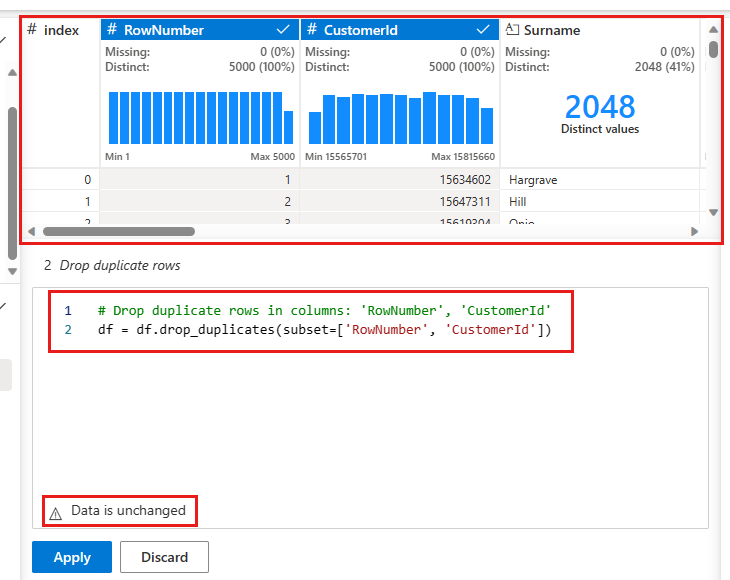
Válassza ki a(z) elemet, majd alkalmazza a(z) elemet (az oldalon vagy az alján) a következő lépéshez.

Hiányzó adatokkal rendelkező sorok elvetése
A Data Wrangler használatával a hiányzó adatokat tartalmazó sorokat az összes oszlopba elvetheti.
Válassza Hiányzó értékek elvetéseKeresés és csereelemet.
Válassza a Az összes kijelölése a Céloszlopok.
A következő lépéshez válassza az alkalmazása lehetőséget.

Oszlopok eltávolítása
A Data Wrangler használatával elvetheti a szükségtelen oszlopokat.
Bontsa ki séma, és válassza Oszlopok elvetéselehetőséget.
Válassza ki a RowNumber, CustomerId, Vezetéknévelemeket. Ezek az oszlopok piros színben jelennek meg az előnézetben, hogy jelezzék: a kód módosította őket (ebben az esetben eltávolítva).
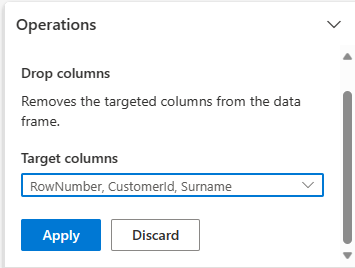
Válassza ki az -t, majd a továbbhaladáshoz kattintson a alkalmazása gombra.

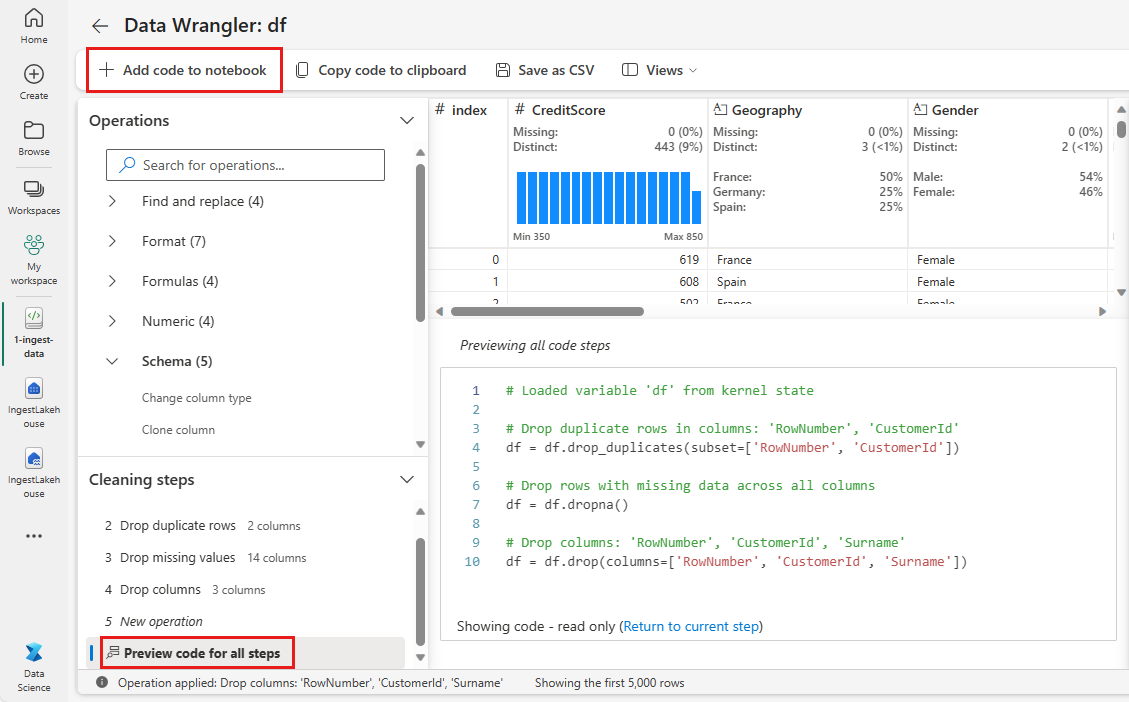
Kód hozzáadása jegyzetfüzethez
Minden alkalommal, amikor a Alkalmazlehetőséget választja, egy új lépés jön létre a bal alsó Tisztítási lépések panelen. A panel alján válassza előnézeti kódot az összes lépéshez, az összes külön lépés kombinációjának megtekintéséhez.
Válassza a Kód hozzáadása jegyzetfüzethez a bal felső sarokban a Data Wrangler bezárásához és a kód automatikus hozzáadásához. A Kód hozzáadása a jegyzetfüzethez becsomagolja a kódot egy függvénybe, majd meghívja a függvényt.
Borravaló
A Data Wrangler által létrehozott kód csak akkor lesz alkalmazva, ha manuálisan futtatja az új cellát.
Ha nem a Data Wranglert használta, használhatja ezt a következő kódcellát.
Ez a kód hasonló a Data Wrangler által létrehozott kódhoz, de minden létrehozott lépéshez hozzáadja az argumentum inplace=True-t. A inplace=Truebeállításával a pandas felülírja az eredeti DataFrame-et ahelyett, hogy egy új DataFrame-et állít elő kimenetként.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Az adatok megismerése
A megtisztított adatok összegzéseinek és vizualizációinak megjelenítése.
Kategorikus, numerikus és célattribútumok meghatározása
Ezzel a kóddal kategorikus, numerikus és célattribútumokat határozhat meg.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Az öt szám összegzése
A numerikus attribútumok ötszámos összegzésének (a minimális pontszám, az első kvartilis, a medián, a harmadik kvartilis, a maximális pontszám) megjelenítése dobozdiagramok használatával.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
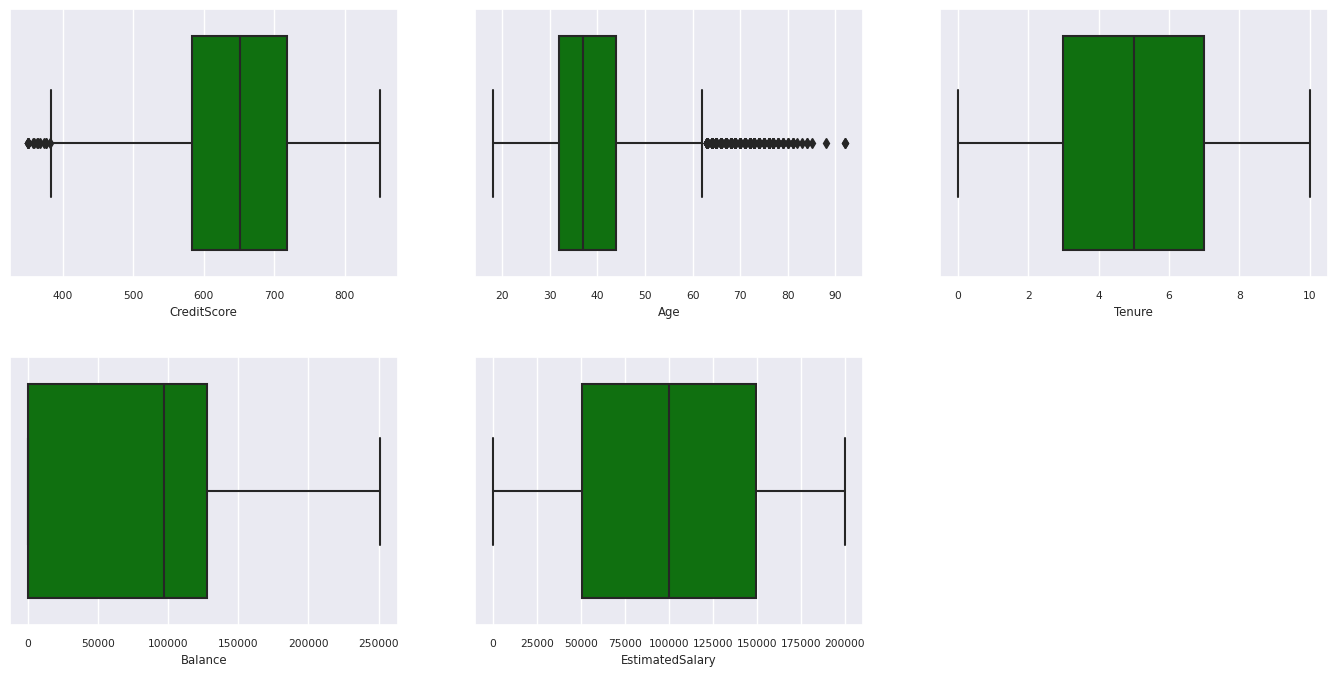
Kilépett és nem kilépett ügyfelek elosztása
Mutasd a kilépett és a megmaradt ügyfelek eloszlását a kategórikus attribútumok szerint.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
df_clean['Exited'] = df_clean['Exited'].astype(str)
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

Numerikus attribútumok eloszlása
Numerikus attribútumok gyakoriságeloszlásának megjelenítése hisztogram használatával.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Funkciófejlesztés végrehajtása
Szolgáltatásfejlesztés elvégzése új attribútumok létrehozásához az aktuális attribútumok alapján:
df_clean['Tenure'] = df_clean['Tenure'].astype(int)
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
A Data Wrangler használata egy gyakori kódolás végrehajtásához
A "Data Wrangler" one-hot kódolás végrehajtására is használható. Ehhez nyissa meg újra a Data Wranglert. Ezúttal válassza ki a df_clean adatokat.
- Bontsa ki képletek, és válassza Egy gyakori elérésű kódolásúlehetőséget.
- Megjelenik egy panel, amelyen kiválaszthatja azokat az oszlopokat, amelyeken one-hot kódolást szeretne végrehajtani. Válassza Földrajzi és Nemeklehetőséget.
Másolhatja a létrehozott kódot, bezárhatja az Data Wranglert a jegyzetfüzetbe való visszatéréshez, majd beillesztheti egy új cellába. Vagy válassza a Kód hozzáadása a(z) jegyzetfüzethez lehetőséget a bal felső sarokban a Data Wrangler bezárásához és a kód automatikus hozzáadásához.
Ha nem a Data Wranglert használta, használhatja ezt a következő kódcellát:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
A feltáró adatelemzés megfigyeléseinek összegzése
- A legtöbb ügyfél Franciaországból származik, Spanyolországhoz és Németországhoz képest, míg Spanyolországban a legalacsonyabb a forgalom aránya Franciaországhoz és Németországhoz képest.
- A legtöbb ügyfél hitelkártyával rendelkezik.
- Vannak olyan ügyfelek, akiknek az életkora és a hitelképessége 60 év feletti, illetve 400 év alatti, de nem tekinthetők kiugró értéknek.
- Nagyon kevés ügyfélnek van több mint két bank terméke.
- A nem aktív ügyfelek nagyobb valószínűséggel felmondják a szolgáltatást.
- Úgy tűnik, hogy a nem és a munkaviszony hossza nem befolyásolja az ügyfél döntését a bankszámlája bezárásáról.
Delta-tábla létrehozása a megtisztított adatokhoz
Ezeket az adatokat a sorozat következő jegyzetfüzetében fogja használni.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Következő lépés
Gépi tanulási modellek betanítása és regisztrálása az alábbi adatokkal: