Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ebben az oktatóanyagban megtanulhatja, hogyan taníthat be több gépi tanulási modellt, hogy kiválaszthassa a legjobbat annak érdekében, hogy előre jelezze, mely banki ügyfelek fognak távozni.
Ebben az oktatóanyagban a következőket fogja elkönyvelni:
- Random Forest- és LightGBM-modellek betanítása.
- A Microsoft Fabric Natív integrációja az MLflow-keretrendszerrel a betanított gépi tanulási modellek, a használt hiperparaméterek és a kiértékelési metrikák naplózásához.
- Regisztrálja a betanított gépi tanulási modellt.
- Értékelje a betanított gépi tanulási modellek teljesítményét az érvényesítési adathalmazon.
Az MLflow egy nyílt forráskód platform a gépi tanulási életciklus kezeléséhez olyan funkciókkal, mint a Tracking, a Models és a Model Registry. Az MLflow natív módon integrálva van a Fabric Adattudomány felülettel.
Előfeltételek
Microsoft Fabric-előfizetés lekérése. Vagy regisztráljon egy ingyenes Microsoft Fabric-próbaverzióra.
Váltson Fabricre a kezdőlap bal alsó részén található élménykapcsolóval.

Ez az oktatóanyag-sorozat 5. része. Az oktatóanyag elvégzéséhez először végezze el a következőket:
- 1. rész: Adatok betöltése Egy Microsoft Fabric lakehouse-ba az Apache Spark használatával.
- 2. rész: Adatok feltárása és vizualizációja a Microsoft Fabric-jegyzetfüzetek használatával, hogy többet tudjon meg az adatokról.
Követés a jegyzetfüzetben
A 3-train-evaluate.ipynb az oktatóanyagot kísérő jegyzetfüzet.
A jelen oktatóanyaghoz mellékelt jegyzetfüzet megnyitásához kövesse a Rendszer előkészítése az adattudományi oktatóanyagokhoz utasításait, hogy a jegyzetfüzetet importálhassa a munkaterületére.
Ha inkább erről a lapról másolja és illessze be a kódot, létrehozhat egy új jegyzetfüzetet.
A kód futtatása előtt mindenképpen csatoljon egy lakehouse-t a jegyzetfüzethez .
Fontos
Csatolja ugyanazt a tóházat, amelyet az 1. és a 2. részben használt.
Egyéni kódtárak telepítése
Ebben a jegyzetfüzetben a kiegyensúlyozatlan tanulást (importálva imblearn) fogja telepíteni a következővel %pip install: . A kiegyensúlyozatlan tanulás a szintetikus kisebbségi túlhasználati technika (SMOTE) könyvtára, amelyet a kiegyensúlyozatlan adathalmazok kezelésekor használnak. A PySpark-kernel ezután újraindul %pip install, ezért telepítenie kell a kódtárat, mielőtt bármilyen más cellát futtatna.
Az SMOTE-t a kódtár használatával érheti imblearn el. Telepítse most a helyszíni telepítési képességekkel (pl. %pip, ). %conda
# Install imblearn for SMOTE using pip
%pip install imblearn
%pip install scikit-learn==1.6.1
%pip install "mlflow==2.12.2"
Fontos
Futtassa ezt a telepítést minden alkalommal, amikor újraindítja a jegyzetfüzetet.
Ha egy jegyzetfüzetbe telepít egy tárat, az csak a jegyzetfüzet munkamenetének időtartamára érhető el, a munkaterületen nem. Ha újraindítja a jegyzetfüzetet, újra kell telepítenie a tárat.
Ha rendelkezik egy gyakran használt tárval, és elérhetővé szeretné tenni a munkaterület összes jegyzetfüzete számára, erre a célra használhat hálókörnyezetet. Létrehozhat egy környezetet, telepítheti benne a tárat, majd a munkaterület rendszergazdája alapértelmezett környezetként csatolhatja a környezetet a munkaterülethez. A környezet alapértelmezettként való beállításáról további információt a munkaterület alapértelmezett kódtárainak rendszergazdai beállítása című témakörben talál.
A meglévő munkaterületi kódtárak és Spark-tulajdonságok környezetbe való migrálásával kapcsolatos információkért lásd : Munkaterülettárak és Spark-tulajdonságok áttelepítése alapértelmezett környezetbe.
Az adatok betöltése
A gépi tanulási modellek betanítása előtt be kell töltenie a delta táblát a lakehouse-ból az előző jegyzetfüzetben létrehozott megtisztított adatok olvasásához.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Kísérlet létrehozása a modell nyomon követésére és naplózására az MLflow használatával
Ez a szakasz bemutatja, hogyan hozhat létre kísérletet, hogyan adhatja meg a gépi tanulási modellt és a betanítási paramétereket, valamint a metrikákat, betaníthatja a gépi tanulási modelleket, naplózhatja őket, és mentheti a betanított modelleket későbbi használatra.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment-SBM" # MLflow experiment name
Az MLflow autologging képességeinek kibővítésével az automatikus naplózás úgy működik, hogy automatikusan rögzíti a gépi tanulási modell bemeneti paramétereinek és kimeneti metrikáinak értékeit a betanítás során. Ezt az információt ezután a rendszer naplózza a munkaterületre, ahol az MLflow API-kkal vagy a munkaterület megfelelő kísérletével érhető el és jeleníthető meg.
A rendszer naplózza a megfelelő nevű kísérleteket, és nyomon követheti a paramétereket és a teljesítménymetrikákat. Az automatikus kereséssel kapcsolatos további információkért tekintse meg az Automatikus keresés a Microsoft Fabricben című témakört.
Kísérlet és automatikus címkézési specifikációk beállítása
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Scikit-learn és LightGBM importálása
A gépi tanulási modellek most már meghatározhatók, ha az adatok a helyükön lesznek. Ebben a jegyzetfüzetben véletlenszerű erdő- és LightGBM-modelleket fog alkalmazni. A modelleket scikit-learn néhány kódsoron belül használhatja és lightgbm implementálhatja.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Betanítási, érvényesítési és tesztelési adathalmazok előkészítése
A függvény train_test_split használatával scikit-learn feloszthatja az adatokat betanítási, érvényesítési és tesztelési csoportokra.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Tesztadatok mentése deltatáblába
Mentse a tesztadatokat a delta táblába a következő jegyzetfüzetben való használatra.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
SMOTE alkalmazása a betanítási adatokra a kisebbségi osztály új mintáinak szintetizálásához
A 2. részben végzett adatfeltárás azt mutatta, hogy a 10 000 ügyfélnek megfelelő 10 000 adatpont közül csak 2037 ügyfél (körülbelül 20%) hagyta el a bankot. Ez azt jelzi, hogy az adathalmaz nagymértékben kiegyensúlyozatlan. A kiegyensúlyozatlan besorolással az a probléma, hogy túl kevés példa van a kisebbségi osztályra ahhoz, hogy egy modell hatékonyan megtanulja a döntési határt. Az SMOTE a legelszántabb módszer a kisebbségi osztály új mintáinak szintetizálására. További információ az SMOTE-ról itt és itt.
Tipp.
Vegye figyelembe, hogy az SMOTE csak a betanítási adathalmazra alkalmazható. A tesztadatkészletet az eredeti kiegyensúlyozatlan eloszlásában kell hagynia, hogy érvényes közelítést kapjon a gépi tanulási modell teljesítményéről az eredeti adatokon, ami az éles helyzetnek megfelelő.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Tipp.
Nyugodtan figyelmen kívül hagyhatja a cella futtatásakor megjelenő MLflow figyelmeztető üzenetet.
Ha egy ModuleNotFoundError üzenet jelenik meg, nem futtatta a jegyzetfüzet első celláját, amely telepíti a imblearn tárat. Ezt a tárat minden alkalommal telepítenie kell, amikor újraindítja a jegyzetfüzetet. Térjen vissza, és futtassa újra az összes cellát a jegyzetfüzet első cellájával kezdve.
A modell betanítása
- A modell betanítása Random Forest használatával, legfeljebb 4 és 4 funkcióval
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- A modell betanítása Random Forest használatával, legfeljebb 8 és 6 funkcióval
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- A modell betanítása a LightGBM használatával
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
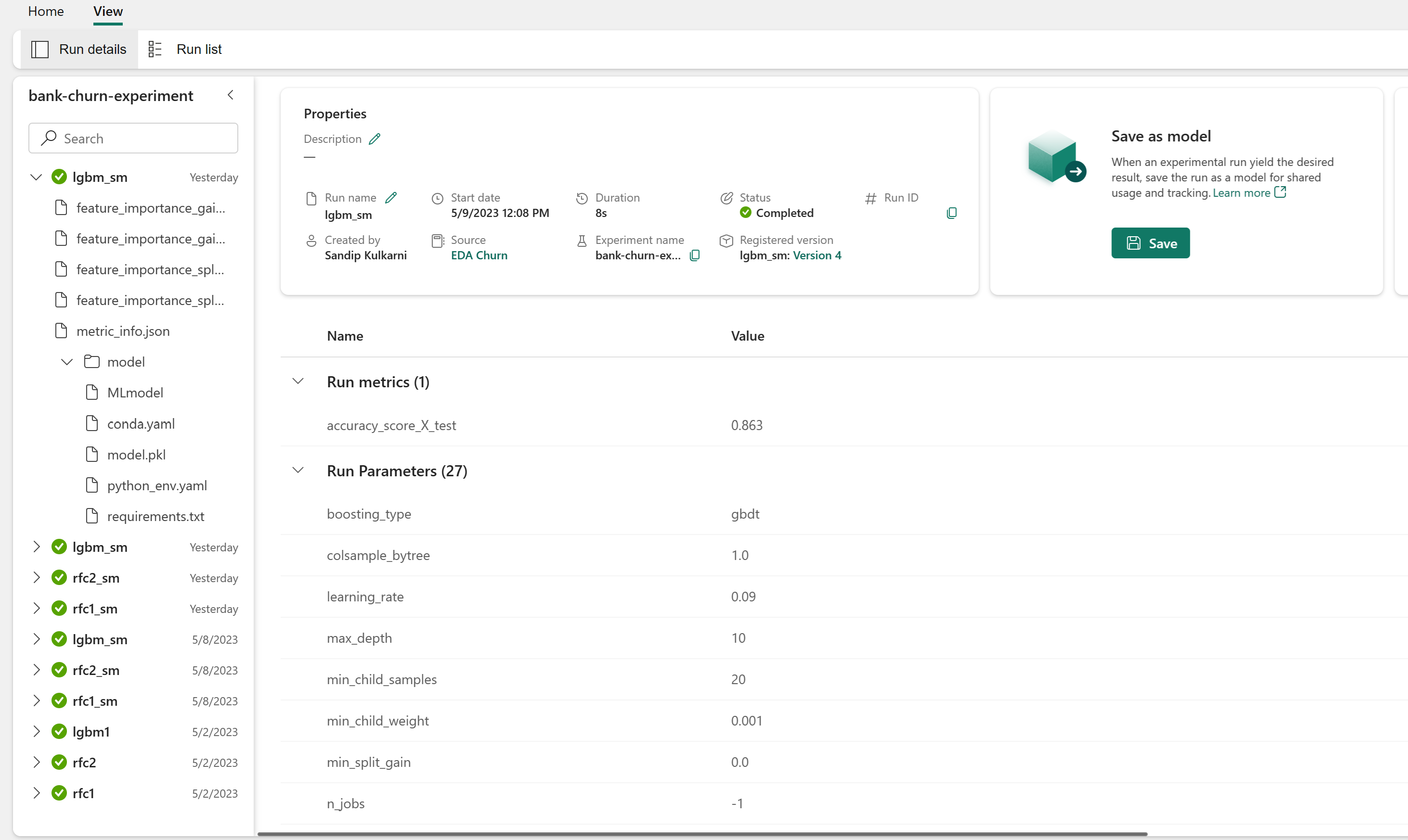
Kísérletösszetevő a modell teljesítményének nyomon követéséhez
A kísérletfuttatások automatikusan a munkaterületről található kísérletösszetevőbe kerülnek. A név a kísérlet beállításához használt név alapján van elnevezve. A rendszer naplózza az összes betanított gépi tanulási modellt, azok futását, teljesítménymetrikáit és modellparamétereit.
A kísérletek megtekintése:
A bal oldali panelen válassza ki a munkaterületet.
A jobb felső sarokban szűrjön, hogy csak kísérleteket jelenítsen meg, hogy könnyebben megtalálja a keresett kísérletet.
Keresse meg és válassza ki a kísérlet nevét, ebben az esetben a bank-churn-experiment nevet. Ha nem látja a kísérletet a munkaterületen, frissítse a böngészőt.


A betanított modellek teljesítményének értékelése az érvényesítési adathalmazon
Miután végzett a gépi tanulási modell betanításával, kétféleképpen értékelheti a betanított modellek teljesítményét.
Nyissa meg a munkaterületről mentett kísérletet, töltse be a gépi tanulási modelleket, majd mérje fel a betöltött modellek teljesítményét az érvényesítési adatkészleten.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMKözvetlenül felmérheti a betanított gépi tanulási modellek teljesítményét az érvényesítési adathalmazon.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
A beállításoktól függően bármelyik megközelítés rendben van, és azonos teljesítményt kell nyújtania. Ebben a jegyzetfüzetben az első módszert választja, hogy jobban bemuhassa a Microsoft Fabric MLflow automatikusan megjelenő funkcióit.
Igaz/hamis pozitív/negatív értékek megjelenítése a keveredési mátrix használatával
Ezután egy szkriptet fog kidolgozni a keveredési mátrix ábrázolásához, hogy kiértékelje a besorolás pontosságát az érvényesítési adathalmaz használatával. A keveredési mátrix a SynapseML-eszközökkel is ábrázolható, amely az itt elérhető csalásészlelési mintában látható.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- Keveredési mátrix véletlenszerű erdőosztályozóhoz legfeljebb 4 és 4 funkcióval
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
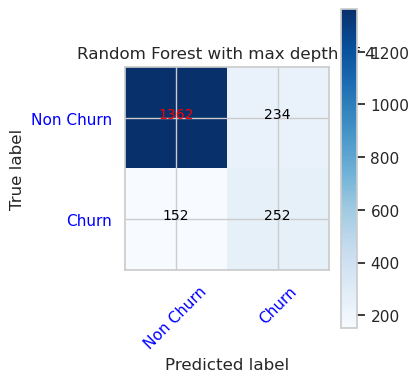
- Keveredési mátrix véletlenszerű erdőosztályozóhoz legfeljebb 8 és 6 funkcióval
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()

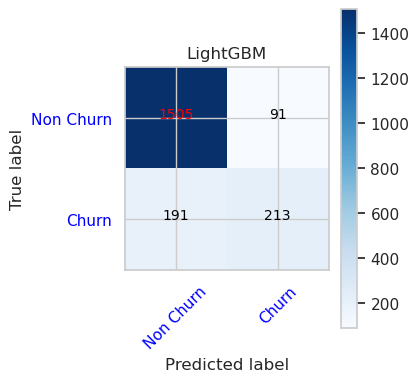
- Keveredési mátrix a LightGBM-hez
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()