A OneLake integrálása az Azure Databricks szolgáltatással
Ez a forgatókönyv bemutatja, hogyan csatlakozhat a OneLake-hez az Azure Databricksen keresztül. Az oktatóanyag elvégzése után az Azure Databricks-munkaterületről olvashat és írhat egy Microsoft Fabric lakehouse-ba.
Előfeltételek
A csatlakozás előtt a következő eszközökre van szüksége:
- Háló munkaterület és tóház.
- Prémium Szintű Azure Databricks-munkaterület. Csak a prémium Szintű Azure Databricks-munkaterületek támogatják a Microsoft Entra hitelesítő adatok átadását, amelyre ebben a forgatókönyvben szüksége van.
A Databricks-munkaterület beállítása
Nyissa meg az Azure Databricks-munkaterületet, és válassza a Fürt létrehozása lehetőséget>.
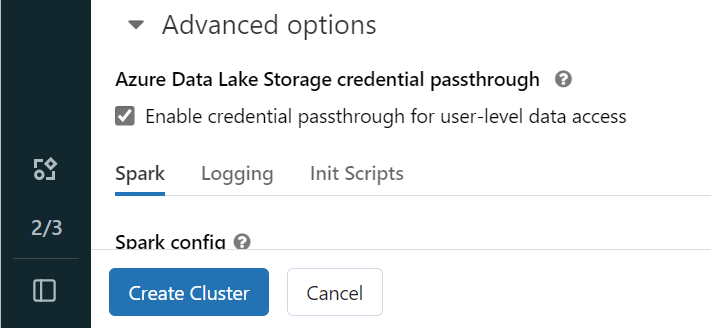
A OneLake-ben a Microsoft Entra-identitással való hitelesítéshez engedélyeznie kell az Azure Data Lake Storage (ADLS) hitelesítő adatok átadását a fürtön a Speciális beállítások területen.
Feljegyzés
A Databrickset egy szolgáltatásnévvel is csatlakoztathatja a OneLake-hez. További információ az Azure Databricks szolgáltatásnévvel történő hitelesítéséről: Szolgáltatásnevek kezelése.
Hozza létre a fürtöt az előnyben részesített paraméterekkel. A Databricks-fürtök létrehozásáról további információt a Fürtök konfigurálása – Azure Databricks című témakörben talál.
Nyisson meg egy jegyzetfüzetet, és csatlakoztassa az újonnan létrehozott fürthöz.
Jegyzetfüzet létrehozása
Lépjen a Fabric lakehouse-hoz, és másolja az Azure Blob Filesystem (ABFS) elérési útját a tóházba. A Tulajdonságok panelen található.
Feljegyzés
Az Azure Databricks csak az Azure Blob Filesystem (ABFS) illesztőprogramot támogatja az ADLS Gen2 és a OneLake felé történő olvasáskor és íráskor:
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/.Mentse a lakehouse elérési útját a Databricks-jegyzetfüzetben. Ebben a lakehouse-ben írhatja meg a feldolgozott adatokat később:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Adatok betöltése a Databricks nyilvános adatkészletéből egy adatkeretbe. A Fabric más részein is elolvashat egy fájlt, vagy kiválaszthat egy fájlt egy másik, már meglévő ADLS Gen2-fiókból.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")Szűrheti, átalakíthatja vagy előkészítheti az adatokat. Ebben a forgatókönyvben levághatja az adathalmazt a gyorsabb betöltéshez, más adatkészletekhez való csatlakozáshoz vagy adott eredményekre való szűréshez.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)Írja be a szűrt adatkeretet a Fabric lakehouse-ba a OneLake elérési útján.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)Tesztelje, hogy az adatok sikeresen meg vannak-e írva az újonnan betöltött fájl olvasásával.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
Gratulálunk! Mostantól az Azure Databricks használatával is olvashat és írhat adatokat a Fabricben.