A OneLake integrálása az Azure Synapse Analyticsszel
Az Azure Synapse egy korlátlan elemzési szolgáltatás, amely egyesíti a nagyvállalati adatraktározást és a Big Data analitikát. Ez az oktatóanyag bemutatja, hogyan csatlakozhat a OneLake-hez az Azure Synapse Analytics használatával.
Adatok írása a Synapse-ból az Apache Spark használatával
Kövesse ezeket a lépéseket az Apache Spark használatával, hogy mintaadatokat írjon a OneLake-be az Azure Synapse Analyticsből.
Nyissa meg a Synapse-munkaterületet, és hozzon létre egy Apache Spark-készletet az előnyben részesített paraméterekkel.
Hozzon létre egy új Apache Spark-jegyzetfüzetet.
Nyissa meg a jegyzetfüzetet, állítsa a nyelvet a PySpark (Python) értékre, és csatlakoztassa az újonnan létrehozott Spark-készlethez.
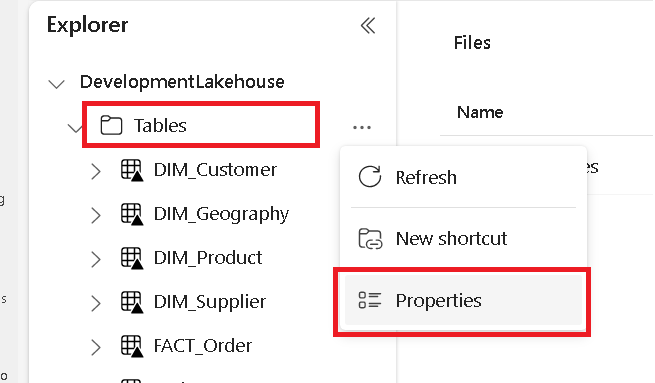
Egy külön lapon keresse meg a Microsoft Fabric lakehouse-t, és keresse meg a legfelső szintű Táblák mappát.
Kattintson a jobb gombbal a Táblák mappára, és válassza a Tulajdonságok lehetőséget.
Másolja az ABFS-elérési utat a tulajdonságok panelről.
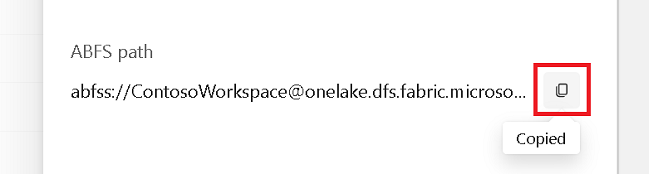
Az Azure Synapse-jegyzetfüzetben, az első új kódcellában adja meg a lakehouse elérési útját. Ez a lakehouse az, ahol az adatok később meg lesznek írva. Futtassa a cellát.
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'Egy új kódcellában töltsön be adatokat egy Azure-beli nyitott adathalmazból egy adatkeretbe. Ezt az adatkészletet tölti be a tóházába. Futtassa a cellát.
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))Egy új kódcellában szűrje, alakítsa át vagy készítse elő az adatokat. Ebben a forgatókönyvben levághatja az adathalmazt a gyorsabb betöltéshez, más adatkészletekhez való csatlakozáshoz vagy adott eredményekre való szűréshez. Futtassa a cellát.
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))Egy új kódcellában, a OneLake-elérési út használatával írja a szűrt adatkeretet egy új Delta-Parquet táblába a Fabric lakehouse-ban. Futtassa a cellát.
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')Végül egy új kódcellában tesztelje, hogy az adatok sikeresen meg vannak-e írva, ha beolvassa az újonnan betöltött fájlt a OneLake-ből. Futtassa a cellát.
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
Gratulálunk! Az Azure Synapse Analyticsben az Apache Spark használatával most már olvashat és írhat adatokat a OneLake-ben.
Adatok olvasása a Synapse-ból az SQL használatával
Az alábbi lépéseket követve az SQL kiszolgáló nélküli használatával olvashat adatokat a OneLake-ből az Azure Synapse Analyticsből.
Nyisson meg egy Fabric lakehouse-t, és azonosítsa a Synapse-ból lekérdezni kívánt táblát.
Kattintson a jobb gombbal a táblára, és válassza a Tulajdonságok lehetőséget.
Másolja ki a táblázat ABFS-elérési útját .
Hozzon létre egy új SQL-szkriptet.
Az SQL-lekérdezésszerkesztőben írja be a következő lekérdezést, és cserélje le
ABFS_PATH_HEREa korábban másolt elérési útra.SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;Futtassa a lekérdezést a tábla 10 első sorának megtekintéséhez.
Gratulálunk! Mostantól a OneLake-ből is olvashat adatokat kiszolgáló nélküli SQL használatával az Azure Synapse Analyticsben.