Medallion lakehouse architektúra implementálása a Microsoft Fabricben
Ez a cikk bemutatja a medallion lake architektúrát, és ismerteti, hogyan implementálhat egy tóházat a Microsoft Fabricben. Több célközönséget céloz meg:
- Adatmérnökök: Olyan infrastruktúrákat és rendszereket tervező, fejlesztő és karbantartó műszaki személyzet, amelyek lehetővé teszik a szervezet számára a nagy mennyiségű adat gyűjtését, tárolását, feldolgozását és elemzését.
- Kiválósági központ, informatikai és BI-csapat: Azok a csapatok, amelyek az elemzések felügyeletéért felelősek a szervezetben.
- Hálógazdák: Azok a rendszergazdák, akik a Fabric felügyeletéért felelősek a szervezetben.
A medallion lakehouse architektúra, más néven medallion architektúra olyan tervezési minta, amelyet a szervezetek használnak az adatok logikai rendszerezésére egy tóházban. Ez a Fabric ajánlott tervezési megközelítése.
A medallion architektúra három különböző rétegből vagy zónából áll. Az egyes rétegek a tóházban tárolt adatok minőségét jelzik, magasabb szintűek pedig magasabb minőséget képviselnek. Ezzel a többrétegű megközelítéssel egyetlen igazságforrást hozhat létre a vállalati adattermékekhez.
Fontos, hogy a medallion architektúra garantálja az ACID tulajdonságkészletet (atomiság, konzisztencia, elkülönítés és tartósság), ahogy az adatok haladnak végig a rétegeken. A nyers adatoktól kezdve az érvényesítések és átalakítások sorozata előkészíti a hatékony elemzésre optimalizált adatokat. Három medálszakasz létezik: bronz (nyers), ezüst (ellenőrzött) és arany (dúsított).
További információ: Mi a medallion lakehouse architektúra?
OneLake és lakehouse a Fabricben
A modern adattárház alapja egy adattó. Microsoft OneLake, amely egyetlen, egységes, logikai adattó a teljes szervezet számára. Automatikusan ki van építve minden Fabric-bérlővel, és úgy lett kialakítva, hogy az összes elemzési adat egyetlen helye legyen.
A OneLake-et a következőre használhatja:
- Távolítsa el a silókat, és csökkentse a felügyeleti erőfeszítéseket. Minden szervezeti adat egy data lake-erőforráson belül van tárolva, felügyelve és védve . Mivel a OneLake ki van építve a Fabric-bérlővel, nincs több kiépítésre vagy kezelésre szolgáló erőforrás.
- Csökkentse az adatáthelyezést és a duplikációt. A OneLake célja, hogy csak egy adatmásolatot tároljon. Az adatok kevesebb példánya kevesebb adatáthelyezési folyamatot eredményez, ami a hatékonyság növeléséhez és az összetettség csökkenéséhez vezet. Szükség esetén létrehozhat egy parancsikont, amellyel más helyeken tárolt adatokra hivatkozhat ahelyett, hogy a OneLake-be másolta volna őket.
- Több elemzési motorral használható. A OneLake-ben tárolt adatok nyílt formátumban lesznek tárolva. Így az adatokat különböző elemzési motorok kérdezhetik le, beleértve az Analysis Servicest (a Power BI által használt), a T-SQL-t és az Apache Sparkot. Más nem hálós alkalmazások api-kat és SDK-kat is használhatnak a OneLake eléréséhez.
További információ: OneLake, a OneDrive for data.
Az adatok OneLake-ben való tárolásához létre kell hoznia egy tóházat a Fabricben. A lakehouse egy adatarchitektúra-platform a strukturált és strukturálatlan adatok egyetlen helyen történő tárolására, kezelésére és elemzésére. Egyszerűen méretezhető nagy méretű adatkötetekre minden fájltípusból és méretből, és mivel egyetlen helyen van tárolva, könnyen megosztható és újra felhasználható a szervezeten belül.
Minden lakehouse rendelkezik egy beépített SQL Analytics-végpontkal, amely az adatok áthelyezése nélkül oldja fel az adattárház képességeit. Ez azt jelenti, hogy sql-lekérdezésekkel és speciális beállítások nélkül lekérdezheti az adatokat a lakehouse-ban.
További információ: Mi az a lakehouse a Microsoft Fabricben?
Táblák és fájlok
Amikor létrehoz egy tóházat a Fabricben, a rendszer automatikusan két fizikai tárolóhelyet épít ki táblákhoz és fájlokhoz.
- A táblák az Apache Spark (CSV, Parquet vagy Delta) összes formátumát tartalmazó táblák üzemeltetésére szolgáló felügyelt terület. Az automatikusan vagy explicit módon létrehozott táblákat a rendszer táblákként ismeri fel a lakehouse-ban. Emellett a Delta-táblák, amelyek fájlalapú tranzakciónaplóval rendelkező Parquet-adatfájlok, szintén táblákként lesznek felismerve.
- A fájlok egy nem felügyelt terület, ahol bármilyen fájlformátumban tárolhatja az adatokat. Az ezen a területen tárolt Delta-fájlok nem lesznek automatikusan táblákként felismerve. Ha egy táblát szeretne létrehozni egy Delta Lake-mappán keresztül a nem felügyelt területen, explicit módon létre kell hoznia egy parancsikont vagy egy külső táblát, amely az Apache Spark Delta Lake-fájljait tartalmazó nem felügyelt mappára mutat.
A felügyelt terület (táblák) és a nem felügyelt terület (fájlok) közötti fő különbség az automatikus táblafelderítési és regisztrációs folyamat. Ez a folyamat csak a felügyelt területen létrehozott mappákon fut, a nem felügyelt területen nem.
A Microsoft Fabricben a Lakehouse Explorer egységes grafikus ábrázolást biztosít a teljes Lakehouse-ról, hogy a felhasználók navigálhassanak, hozzáférjenek és frissíthessék az adataikat.
Az automatikus táblafelderítésről további információt az Automatikus táblafelderítés és -regisztráció című témakörben talál.
Delta Lake Storage
A Delta Lake egy optimalizált tárolási réteg, amely biztosítja az adatok és táblák tárolásának alapjait. Támogatja az ACID-tranzakciókat a big data számítási feladatokhoz, ezért ez a Fabric lakehouse alapértelmezett tárolási formátuma.
Fontos, hogy a Delta Lake megbízhatóságot, biztonságot és teljesítményt nyújt a lakehouse-ban a streamelési és kötegelt műveletekhez is. Belsőleg Parquet-fájlformátumban tárolja az adatokat, de olyan tranzakciónaplókat és statisztikákat is tart fenn, amelyek a standard Parquet formátumhoz hasonló funkciókat és teljesítménybeli javulást biztosítanak.
A Delta Lake-formátum általános fájlformátumokkal a következő fő előnyöket nyújtja.
- Támogatja az ACID-tulajdonságokat, és különösen a tartósságot az adatsérülések megelőzése érdekében.
- Gyorsabb olvasási lekérdezések.
- Az adatok frissessége.
- A kötegelt és a streamelési számítási feladatok támogatása.
- Az adat-visszaállítás támogatása a Delta Lake időutazásával.
- Továbbfejlesztett jogszabályi megfelelőség és auditálás a Delta Lake táblaelőzményeinek használatával.
A Fabric szabványosítja a tárolási fájlformátumot a Delta Lake-zel, és alapértelmezés szerint a Fabric minden számítási feladatmotorja Delta-táblákat hoz létre, amikor adatokat ír egy új táblába. További információ: Lakehouse és Delta Lake táblák.
Medallion architektúra a Fabricben
A medallion architektúra célja az adatok struktúrájának és minőségének fokozatos és fokozatos javítása az egyes fázisok során.
A medallion architektúra három különböző rétegből (vagy zónából) áll.
- Bronz: A nyers zónaként is ismert első réteg a forrásadatokat eredeti formájában tárolja. Az ebben a rétegben lévő adatok általában csak hozzáfűzhetők és nem módosíthatók.
- Ezüst: Más néven gazdagított zóna, ez a réteg a bronz rétegből származó adatokat tárolja. A nyers adatok megtisztítva és szabványosítva lettek, és táblákként (sorokként és oszlopokként) vannak strukturálva. Emellett más adatokkal is integrálható, így vállalati nézetet biztosíthat az összes üzleti entitásról, például az ügyfélről, a termékről és másokról.
- Arany: Más néven a válogatott zóna, ez az utolsó réteg az ezüst rétegből származó adatokat tárolja. Az adatok finomítása az adott alsóbb rétegbeli üzleti és elemzési követelményeknek való megfelelés érdekében történik. A táblák általában megfelelnek a csillagséma kialakításának, amely támogatja a teljesítményre és a használhatóságra optimalizált adatmodellek fejlesztését.
Fontos
Mivel a Fabric lakehouse egyetlen zónát jelöl, a három zóna mindegyikéhez létre kell hoznia egy-egy tóházat.
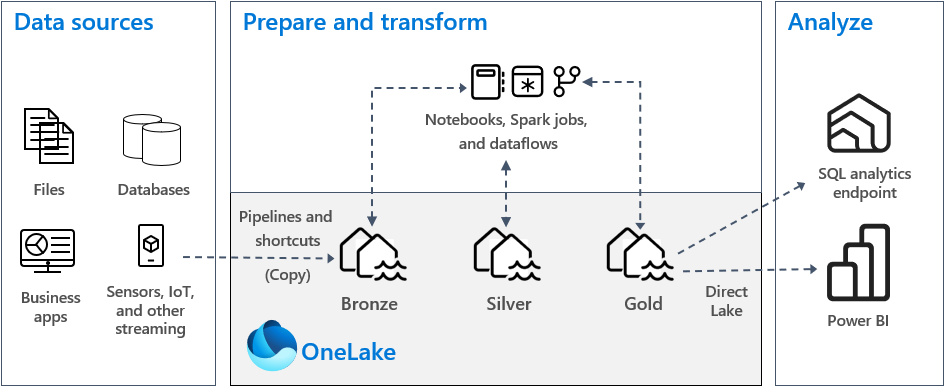
A Fabricben egy tipikus medallion architektúra-implementációban a bronz zóna az adatforrással megegyező formátumban tárolja az adatokat. Ha az adatforrás relációs adatbázis, a Delta-táblák jó választásnak számítanak. Az ezüst és arany zónák deltatáblákat tartalmaznak.
Tipp.
Ha meg szeretné tudni, hogyan hozhat létre egy tóházat, a Lakehouse végpontok közötti forgatókönyv-oktatóanyagában dolgozhat.
Fabric lakehouse útmutató
Ez a szakasz útmutatást nyújt a Fabric lakehouse medál architektúra használatával történő implementálásához.
Üzembehelyezési modell
A Medallion architektúra Fabricben való implementálásához használhatja a lakehouse-t (minden zónához egyet), egy adattárházat vagy mindkettő kombinációját. A döntésnek az Ön preferenciáján és a csapat szakértelmén kell alapulnia. Ne feledje, hogy a Fabric rugalmasságot biztosít: Különböző elemzési motorokat használhat, amelyek az adatok egy példányán működnek a OneLake-ben.
Az alábbiakban két mintát kell figyelembe venni.
- 1. minta: Hozzon létre minden zónát tóházként. Ebben az esetben az üzleti felhasználók az SQL Analytics-végpont használatával férnek hozzá az adatokhoz.
- 2. minta: Hozza létre a bronz és ezüst zónákat tóházakként, az aranyzónát pedig adattárházként. Ebben az esetben az üzleti felhasználók az adattárház végpontjának használatával férnek hozzá az adatokhoz.
Bár az összes tóházat egyetlen Fabric-munkaterületen hozhatja létre, javasoljuk, hogy mindegyik tóházat saját, különálló Fabric-munkaterületen hozza létre. Ez a megközelítés több ellenőrzést és jobb szabályozást biztosít a zónaszinten.
A bronz zónához javasoljuk, hogy az adatokat az eredeti formátumban tárolja, vagy használja a Parquet vagy a Delta Lake-t. Amikor csak lehetséges, tartsa meg az adatokat az eredeti formátumban. Ha a forrásadatok a OneLake-ből, az Azure Data Lake Store Gen2-ből (ADLS Gen2), az Amazon S3-ból vagy a Google-ból származnak, az adatok átmásolása helyett hozzon létre egy parancsikont a bronz zónában.
Az ezüst és arany zónák esetében javasoljuk, hogy a Delta-táblákat az általuk biztosított további képességek és teljesítménybeli fejlesztések miatt használja. A Fabric a Delta Lake formátumot szabványosítja, és alapértelmezés szerint a Fabric minden motorja ilyen formátumban ír adatokat. Ezen túlmenően ezek a motorok V-Order írási időt optimalizálnak a Parquet fájlformátumra. Ez az optimalizálás rendkívül gyors olvasást tesz lehetővé a Fabric számítási motorjai, például a Power BI, az SQL, az Apache Spark és mások számára. További információ: Delta Lake table optimization and V-Order.
Végül, ma számos szervezet szembesül az adatmennyiségek jelentős növekedésével, és egyre nagyobb szükség van az adatok logikus rendszerezésére és kezelésére, miközben elősegíti a célzottabb és hatékonyabb használatot és szabályozást. Így decentralizált vagy összevont adatszervezetet hozhat létre és kezelhet irányítással.
Ennek a célkitűzésnek a teljesítése érdekében fontolja meg egy adathálós architektúra implementálását. Az adatháló egy architektúraminta, amely az adatokat termékként kínáló adattartományok létrehozására összpontosít.
Adattartományok létrehozásával data mesh-architektúrát hozhat létre az adattulajdonhoz a Fabricben. Létrehozhat olyan tartományokat, amelyek megfeleltetik az üzleti tartományokat, például marketinget, értékesítést, leltárt, emberi erőforrásokat és másokat. Ezután a medallion architektúrát úgy implementálhatja, hogy minden tartományon belül beállítja az adatzónákat.
A tartományokról további információt a Tartományok című témakörben talál.
A Delta-tábla adattárolásának ismertetése
Ez a szakasz a medallion lakehouse architektúra Fabricben való implementálásával kapcsolatos egyéb útmutató témaköröket ismerteti.
Fájlméret
A big data platform általában akkor teljesít jobban, ha kis számú nagy fájllal rendelkezik, nem pedig nagy számú kis fájllal. Ennek az az oka, hogy a teljesítménycsökkenés akkor fordul elő, ha a számítási motornak számos metaadatot és fájlműveletet kell kezelnie. A jobb lekérdezési teljesítmény érdekében javasoljuk, hogy körülbelül 1 GB méretű adatfájlokat keressen.
A Delta Lake rendelkezik egy prediktív optimalizálás nevű funkcióval. A prediktív optimalizálás nem igényli manuálisan a Karbantartási műveletek kezelését a Delta-táblákhoz. Ha ez a funkció engedélyezve van, a Delta Lake automatikusan azonosítja a karbantartási műveletek előnyeit élvező táblákat, majd optimalizálja a tárolást. Sok kisebb fájlt transzparensen nagy fájlokká alakítja, és nem befolyásolja az adatok más olvasóit és íróit. Bár ennek a funkciónak a működési kiválóság és az adat-előkészítési munka részét kell képeznie, a Fabric képes optimalizálni ezeket az adatfájlokat az adatírás során is. További információ: A Delta Lake prediktív optimalizálása.
Előzménymegőrzés
Alapértelmezés szerint a Delta Lake fenntartja az összes módosítás előzményeit, ami azt jelenti, hogy a korábbi metaadatok mérete idővel növekszik. Az üzleti követelményeknek megfelelően érdemes az előzményadatokat csak bizonyos ideig megőrizni a tárolási költségek csökkentése érdekében. Fontolja meg az előzményadatok megőrzését csak az elmúlt hónapra vagy más megfelelő időszakra vonatkozóan.
A korábbi előzményadatokat a VACUUM paranccsal távolíthatja el a Delta-táblákból. Vegye figyelembe azonban, hogy alapértelmezés szerint nem törölhet előzményadatokat az elmúlt hét napban – ez az adatok konzisztenciájának fenntartása. Az alapértelmezett napok számát a táblatulajdonság delta.deletedFileRetentionDuration = "interval <interval>"szabályozza. Meghatározza azt az időtartamot, amikor egy fájlt törölni kell ahhoz, hogy vákuumműveletre jelöltnek lehessen tekinteni.
Táblapartíciók
Amikor minden zónában tárol adatokat, ajánlott particionált mappastruktúrát használni, ahol csak lehetséges. Ez a technika segít javítani az adatok kezelhetőségét és a lekérdezési teljesítményt. A mappastruktúrában lévő particionált adatok általában gyorsabban keresnek bizonyos adatbejegyzéseket a partíciók metszésének/eltávolításának köszönhetően.
Általában az új adatok érkezésekor hozzáfűzi az adatokat a céltáblához. Bizonyos esetekben azonban egyesítheti az adatokat, mert egyszerre kell frissítenie a meglévő adatokat. Ebben az esetben a MERGE paranccsal végrehajthat egy upsert műveletet. A céltábla particionálásakor mindenképpen használjon partíciószűrőt a művelet felgyorsításához. Így a motor kiküszöbölheti azokat a partíciókat, amelyek nem igényelnek frissítést.
Az adatok elérése
Végül meg kell terveznie és szabályoznia kell, hogy kinek van szüksége hozzáférésre a tóházban lévő adott adatokhoz. Emellett ismernie kell a különböző tranzakciós mintákat is, amelyet az adatok elérésekor használni fognak. Ezután meghatározhatja a megfelelő táblaparticionálási sémát és az adatelrendezést a Delta Lake Z-order indexekkel.
Kapcsolódó tartalom
A Fabric Lakehouse implementálásával kapcsolatos további információkért tekintse meg az alábbi forrásokat.
- Oktatóanyag: A Lakehouse végpontok közötti forgatókönyve
- Lakehouse és Delta Lake táblák
- A Microsoft Fabric döntési útmutatója: válasszon egy adattárat
- Delta Lake-táblaoptimalizálás és V-Order
- Az Apache Sparkon való írás optimalizálásának szükségessége
- Kérdése van? Kérdezd meg a Háló közösségét.
- Javaslatok? Ötleteket ad a Háló fejlesztéséhez.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: