Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini berisi informasi tentang cara memecahkan masalah yang paling sering terjadi dengan kumpulan SQL tanpa server di Azure Synapse Analytics.
Untuk mempelajari selengkapnya tentang Azure Synapse Analytics, periksa topik di Gambaran Umum.
Synapse Studio
Synapse Studio adalah alat yang mudah digunakan yang dapat Anda gunakan untuk mengakses data Anda dengan menggunakan browser tanpa perlu menginstal alat akses database. Synapse Studio tidak dirancang untuk membaca himpunan data yang besar atau pengelolaan penuh objek SQL.
Kumpulan SQL tanpa server berwarna abu-abu di Synapse Studio
Jika Synapse Studio tidak dapat terhubung ke kumpulan SQL tanpa server, Anda akan melihat kumpulan SQL tanpa server berwarna abu-abu atau menampilkan status Offline.
Biasanya, masalah ini terjadi karena salah satu dari dua alasan:
- Jaringan Anda mencegah komunikasi ke back-end Azure Synapse Analytics. Kasus yang paling sering adalah port TCP 1443 diblokir. Agar kumpulan SQL tanpa server berfungsi, buka blokir port ini. Masalah lain juga dapat mencegah kumpulan SQL tanpa server berfungsi. Untuk informasi selengkapnya, lihat Panduan pemecahan masalah.
- Anda tidak memiliki izin untuk masuk ke kumpulan SQL tanpa server. Untuk mendapatkan akses, administrator ruang kerja Azure Synapse harus menambahkan Anda ke peran administrator ruang kerja atau peran administrator SQL. Untuk informasi selengkapnya, lihat Kontrol akses Azure Synapse.
Koneksi WebSocket ditutup secara tak terduga
Kueri Anda mungkin gagal dengan pesan Websocket connection was closed unexpectedly. kesalahan Pesan ini berarti bahwa koneksi browser Anda ke Synapse Studio terganggu, misalnya, karena masalah jaringan.
- Untuk mengatasi masalah ini, jalankan ulang kueri Anda.
- Coba ekstensi MSSQL untuk Visual Studio Code atau SQL Server Management Studio untuk kueri yang sama alih-alih Synapse Studio untuk penyelidikan lebih lanjut.
- Jika pesan ini sering muncul di lingkungan Anda, dapatkan bantuan dari administrator jaringan. Anda juga dapat memeriksa pengaturan firewall, dan memeriksa Panduan pemecahan masalah.
- Jika masalah berlanjut, buat tiket dukungan melalui portal Microsoft Azure.
Database tanpa server tidak ditampilkan di Synapse Studio
Jika Anda tidak melihat database yang dibuat di kumpulan SQL tanpa server, periksa untuk melihat apakah kumpulan SQL tanpa server Anda aktif. Jika kumpulan SQL tanpa server dinonaktifkan, database tidak akan ditampilkan. Jalankan kueri apa pun, misalnya, SELECT 1, pada kumpulan SQL tanpa server untuk mengaktifkannya dan membuat database muncul.
Kumpulan SQL tanpa server Synapse ditampilkan sebagai tidak tersedia
Konfigurasi jaringan yang salah sering menjadi penyebab perilaku ini. Pastikan port dikonfigurasi dengan benar. Jika Anda menggunakan firewall atau titik akhir privat, periksa juga pengaturan ini.
Terakhir, pastikan peran yang sesuai diberikan dan belum dicabut.
Tidak dapat membuat database baru karena permintaan akan menggunakan kunci lama/kedaluwarsa
Kesalahan ini disebabkan oleh perubahan kunci yang dikelola pelanggan ruang kerja yang digunakan untuk enkripsi. Anda dapat memilih untuk mengenkripsi ulang semua data di ruang kerja dengan versi terbaru dari kunci aktif. Untuk mengenkripsi ulang, ubah kunci di portal Azure menjadi kunci sementara, lalu alihkan kembali ke kunci yang ingin Anda gunakan untuk enkripsi. Pelajari di sini cara mengelola kunci ruang kerja.
Kumpulan SQL tanpa server Synapse tidak tersedia setelah mentransfer langganan ke penyewa Microsoft Entra yang berbeda
Jika Anda memindahkan langganan ke penyewa Microsoft Entra lain, Anda mungkin mengalami beberapa masalah dengan kumpulan SQL tanpa server. Membuat tiket dukungan dan dukungan Azure akan menghubungi Anda untuk mengatasi masalah tersebut.
Akses penyimpanan
Jika Anda mendapatkan kesalahan saat mencoba mengakses file di penyimpanan Azure, pastikan Anda memiliki izin untuk mengakses data. Anda harus dapat mengakses file yang tersedia untuk umum. Jika Anda mencoba mengakses data tanpa kredensial, pastikan identitas Microsoft Entra Anda dapat langsung mengakses file.
Jika Anda memiliki kunci tanda tangan akses bersama yang harus digunakan untuk mengakses file, pastikan Anda membuat kredensial tingkat server atau cakupan database yang berisi kredensial tersebut. Kredensial diperlukan jika Anda perlu mengakses data dengan menggunakan identitas terkelola ruang kerja dan nama prinsipal layanan (SPN) kustom.
Tidak dapat membaca, membuat daftar, atau mengakses file di Azure Data Lake Storage
Jika Anda menggunakan login Microsoft Entra tanpa kredensial eksplisit, pastikan identitas Microsoft Entra Anda dapat mengakses file di penyimpanan. Untuk mengakses file, identitas Microsoft Entra Anda harus memiliki izin Pembaca Data Blob, atau izin ke Daftar dan Membaca daftar kontrol akses (ACL) di ADLS. Untuk informasi selengkapnya, lihat Kueri gagal karena file tidak dapat dibuka.
Jika Anda mengakses penyimpanan dengan menggunakan kredensial, pastikan identitas terkelola atau SPN Anda memiliki peran Pembaca Data atau Kontributor atau izin ACL tertentu. Jika Anda menggunakan token tanda tangan akses bersama, pastikan token tersebut memiliki rl izin dan belum kedaluwarsa.
Jika Anda menggunakan login SQL dan OPENROWSET fungsi tanpa sumber data, pastikan Anda memiliki kredensial tingkat server yang cocok dengan URI penyimpanan dan memiliki izin untuk mengakses penyimpanan.
Permintaan gagal karena file tidak dapat dibuka
Jika kueri Anda gagal dengan kesalahan File cannot be opened because it does not exist or it is used by another process dan Anda yakin bahwa kedua file ada dan tidak digunakan oleh proses lain, kumpulan SQL tanpa server tidak dapat mengakses file. Masalah ini biasanya terjadi karena identitas Microsoft Entra Anda tidak memiliki hak untuk mengakses file atau karena firewall memblokir akses ke file.
Secara default, kumpulan SQL tanpa server mencoba mengakses file dengan menggunakan identitas Microsoft Entra Anda. Untuk mengatasi masalah ini, Anda harus memiliki hak yang tepat untuk mengakses file. Cara term mudah adalah dengan memberi diri Anda peran Kontributor Data Blob Penyimpanan di akun penyimpanan yang coba Anda kueri.
Untuk informasi selengkapnya, lihat:
- Kontrol akses ID Microsoft Entra untuk penyimpanan
- Mengontrol akses akun penyimpanan untuk kumpulan SQL tanpa server di Synapse Analytics
Alternatif untuk peran Kontributor Data Blob Penyimpanan
Alih-alih memberi diri Anda peran Kontributor Data Blob Penyimpanan, Anda juga dapat memberikan izin yang lebih terperinci pada subset file.
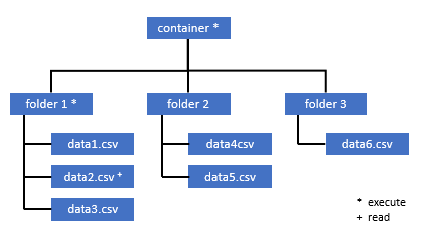
Semua pengguna yang membutuhkan akses ke beberapa data dalam kontainer ini juga harus memiliki izin EXECUTE di semua folder induk hingga ke root (kontainer).
Pelajari selengkapnya tentang cara mengatur ACL di Azure Data Lake Storage Gen2.
Catatan
Izin eksekusi pada tingkat kontainer harus diatur dalam Azure Data Lake Storage Gen2. Izin pada folder dapat diatur dalam Azure Synapse.
Jika Anda ingin membuat kueri data2.csv dalam contoh ini, izin berikut diperlukan:
- Izin eksekusi pada kontainer
- Jalankan izin pada folder1
- Izin baca pada data2.csv
Masuk ke Azure Synapse dengan pengguna admin yang memiliki izin penuh pada data yang ingin Anda akses.
Di panel data, klik kanan file dan pilih Kelola akses.
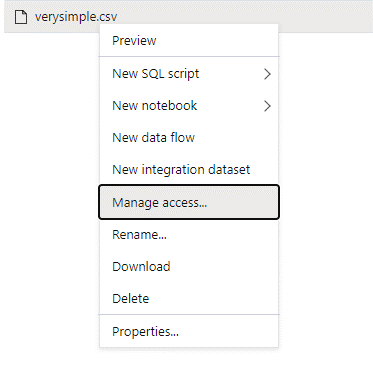
Pilih setidaknya izin Baca. Masukkan UPN atau ID objek pengguna, misalnya,
user@contoso.com. Pilih Tambahkan.Berikan izin baca untuk pengguna ini.

Catatan
Untuk pengguna tamu, langkah ini perlu dilakukan secara langsung dengan Azure Data Lake karena tidak dapat dilakukan secara langsung melalui Azure Synapse.
Konten direktori pada jalur tidak dapat dicantumkan
Kesalahan ini menunjukkan bahwa pengguna yang mengkueri Azure Data Lake tidak dapat mencantumkan file di penyimpanan. Ada beberapa skenario di mana kesalahan ini mungkin terjadi:
- Pengguna Microsoft Entra yang menggunakan autentikasi pass-through Microsoft Entra tidak memiliki izin untuk mendaftarkan file di Data Lake Storage.
- ID Microsoft Entra atau pengguna SQL yang membaca data dengan menggunakan kunci tanda tangan akses bersama (SAS) atau identitas terkelola ruang kerja, di mana kunci atau identitas tersebut tidak memiliki izin untuk mencantumkan file di penyimpanan.
- Pengguna yang mengakses data di Dataverse tetapi tidak memiliki izin untuk melakukan kueri data di Dataverse. Skenario ini mungkin terjadi jika Anda menggunakan pengguna SQL.
- Pengguna yang mengakses Delta Lake mungkin tidak memiliki izin untuk membaca log transaksi Delta Lake.
Cara termudah untuk mengatasi masalah ini adalah dengan memberi diri Anda peran Kontributor Data Blob Penyimpanan di akun penyimpanan yang sedang Anda kueri.
Untuk informasi selengkapnya, lihat:
- Kontrol akses ID Microsoft Entra untuk penyimpanan
- Mengontrol akses akun penyimpanan untuk kumpulan SQL tanpa server di Synapse Analytics
Konten tabel Dataverse tidak dapat dicantumkan
Jika Anda menggunakan Azure Synapse Link for Dataverse untuk membaca tabel DataVerse yang ditautkan, Anda perlu menggunakan akun Microsoft Entra untuk mengakses data yang ditautkan menggunakan kumpulan SQL tanpa server. Untuk informasi selengkapnya, lihat Azure Synapse Link untuk Dataverse dengan Azure Data Lake.
Jika Anda mencoba menggunakan login SQL untuk membaca tabel eksternal yang mereferensikan tabel DataVerse, Anda akan mendapatkan kesalahan berikut: External table '???' is not accessible because content of directory cannot be listed.
Tabel eksternal Dataverse selalu menggunakan autentikasi passthrough Microsoft Entra. Anda tidak dapat mengonfigurasinya untuk menggunakan kunci tanda tangan akses bersama atau identitas terkelola ruang kerja.
Konten log transaksi Delta Lake tidak bisa dicantumkan
Kesalahan berikut ini ditampilkan saat kumpulan SQL tanpa server tidak dapat membaca folder log transaksi Delta Lake:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Pastikan folder _delta_log ada. Mungkin Anda mengkueri file Parquet biasa yang tidak dikonversi ke format Delta Lake. Jika folder _delta_log ada, pastikan Anda memiliki izin Membaca dan Mendaftar pada folder Delta Lake yang bersangkutan. Cobalah untuk membaca file json secara langsung dengan menggunakan FORMAT='csv'. Masukkan URI Anda di parameter BULK:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Jika kueri ini gagal, pemanggil tidak memiliki izin untuk membaca file penyimpanan yang mendasarinya.
Eksekusi kueri
Anda mungkin mendapatkan kesalahan selama eksekusi kueri dalam kasus berikut:
- Pemanggil tidak dapat mengakses beberapa objek.
- Kueri tidak dapat mengakses data eksternal.
- Kueri berisi beberapa fungsi yang tidak didukung di kumpulan SQL tanpa server.
Kueri gagal sebab tidak dapat dijalankan karena kendala sumber daya saat ini
Kueri Anda mungkin gagal dengan pesan This query cannot be executed due to current resource constraints. kesalahan Pesan ini berarti kumpulan SQL tanpa server tidak dapat dijalankan saat ini. Berikut adalah beberapa opsi pemecahan masalah:
- Pastikan bahwa tipe data yang digunakan berukuran wajar.
- Jika kueri Anda menargetkan file Parquet, sebaiknya tentukan jenis eksplisit untuk kolom string karena akan menjadi VARCHAR (8000) secara default. Memeriksa jenis data yang disimpulkan.
- Jika kueri Anda menargetkan file .CSV, pertimbangkan untuk membuat statistik.
- Untuk mengoptimalkan kueri Anda, lihat Praktik terbaik performa untuk kumpulan SQL tanpa server.
Batas waktu kueri kedaluwarsa
Kesalahan Query timeout expired dikembalikan jika kueri dijalankan lebih dari 30 menit pada kumpulan SQL tanpa server. Batas untuk kumpulan SQL tanpa server ini tidak dapat diubah.
- Coba optimalkan kueri Anda dengan menerapkan praktik terbaik.
- Cobalah untuk mewujudkan bagian kueri Anda dengan menggunakan buat tabel eksternal sebagai pilih (CETAS).
- Periksa apakah ada beban kerja bersamaan yang berjalan di kumpulan SQL tanpa server karena kueri lain mungkin mengambil sumber daya. Dalam hal ini, Anda mungkin membagi beban kerja di beberapa ruang kerja.
Nama objek tidak valid
Kesalahan Invalid object name 'table name' menunjukkan bahwa Anda menggunakan objek, seperti tabel atau tampilan, yang tidak ada di database kumpulan SQL tanpa server. Coba opsi ini:
Buat daftar tabel atau tampilan dan periksa apakah objek itu ada. Gunakan SQL Server Management Studio atau Visual Studio Code, karena Synapse Studio mungkin menampilkan beberapa tabel yang tidak tersedia di kumpulan SQL tanpa server.
Jika Anda melihat objek, periksa apakah Anda menggunakan beberapa kolate database peka huruf besar/kecil/biner. Mungkin nama objek tidak cocok dengan nama yang Anda gunakan dalam kueri. Dengan kolase database biner,
Employeedanemployeeadalah dua objek yang berbeda.Jika Anda tidak melihat objek, mungkin Anda mencoba mengkueri tabel dari database lake atau Spark. Tabel mungkin tidak tersedia di kumpulan SQL tanpa server karena:
- Tabel memiliki beberapa jenis kolom yang tidak dapat direpresentasikan dalam kumpulan SQL tanpa server.
- Tabel memiliki format yang tidak didukung di kumpulan SQL tanpa server. Contohnya adalah Avro atau ORC.
String atau data biner akan dipotong
Kesalahan ini terjadi jika panjang string atau jenis kolom biner Anda (misalnya VARCHAR, , VARBINARYatau NVARCHAR) lebih pendek dari ukuran data aktual yang Anda baca. Anda dapat memperbaiki kesalahan ini dengan meningkatkan panjang jenis kolom:
- Jika kolom string Anda didefinisikan sebagai
VARCHAR(32)jenis dan teks adalah 60 karakter, gunakanVARCHAR(60)jenis (atau lebih lama) dalam skema kolom Anda. - Jika Anda menggunakan inferensi skema (tanpa
WITHskema), semua kolom string secara otomatis didefinisikan sebagai jenisnyaVARCHAR(8000). Jika Anda mendapatkan kesalahan ini, tentukan skema secara eksplisit dalam klausul dengan jenis kolom yangWITHlebih besarVARCHAR(MAX)untuk mengatasi kesalahan ini. - Jika tabel Anda berada di database Lake, coba tingkatkan ukuran kolom string di kumpulan Spark.
- Cobalah untuk
SET ANSI_WARNINGS OFFmengaktifkan kumpulan SQL tanpa server untuk secara otomatis memotong nilai VARCHAR, jika ini tidak akan memengaruhi fungsionalitas Anda.
Tanda kutip yang tidak diklasifikasikan setelah string karakter
Dalam kasus yang jarang terjadi, ketika Anda menggunakan operator LIKE pada kolom string atau melakukan beberapa perbandingan dengan string literal, Anda mungkin mendapatkan kesalahan berikut:
Unclosed quotation mark after the character string
Kesalahan ini mungkin terjadi jika Anda menggunakan kolase Latin1_General_100_BIN2_UTF8 pada kolom. Cobalah untuk mengatur kolase Latin1_General_100_CI_AS_SC_UTF8 pada kolom alih-alih kolase Latin1_General_100_BIN2_UTF8 untuk menyelesaikan masalah. Jika kesalahan masih dikembalikan, ajukan permintaan dukungan melalui portal Azure.
Tidak dapat mengalokasikan ruang tempdb saat mentransfer data dari satu distribusi ke distribusi lainnya
Kesalahan Could not allocate tempdb space while transferring data from one distribution to another dikembalikan ketika mesin eksekusi kueri tidak dapat memproses data dan mentransfernya di antara simpul yang menjalankan kueri. Ini adalah kasus khusus dari kueri generik gagal karena tidak dapat dijalankan karena kesalahan batasan sumber daya saat ini . Kesalahan ini dikembalikan ketika sumber daya yang dialokasikan ke database tempdb tidak mencukupi untuk menjalankan kueri.
Terapkan praktik terbaik sebelum Anda mengirimkan tiket dukungan.
Kueri gagal dengan kesalahan saat menangani file eksternal (jumlah kesalahan maksimum tercapai)
Jika kueri Anda gagal dengan pesan kesalahan error handling external file: Max errors count reached, itu berarti ada ketidaksesuaian antara jenis kolom tertentu dan data yang perlu dimuat.
Untuk mendapatkan informasi selengkapnya tentang kesalahan dan baris serta kolom mana yang harus dilihat, ubah versi pengurai dari 2.0 ke 1.0.
Contoh
Jika Anda ingin mengkueri file names.csv dengan Kueri 1 ini, kumpulan SQL tanpa server Azure Synapse akan kembali dengan kesalahan berikut: Error handling external file: 'Max error count reached'. File/External table name: [filepath]. Misalnya:
File names.csv berisi:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Kueri 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Penyebab
Segera setelah versi pengurai diubah dari versi 2.0 ke 1.0, pesan kesalahan membantu mengidentifikasi masalah. Pesan kesalahan baru sekarang Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
Pemotongan memberi tahu Anda bahwa jenis kolom Anda terlalu kecil agar pas dengan data Anda. Nama depan terpanjang dalam file ini names.csv memiliki tujuh karakter. Jenis data yang sesuai yang akan digunakan harus setidaknya VARCHAR(7). Kesalahan disebabkan oleh baris kode ini:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Mengubah kueri yang sesuai akan menyelesaikan kesalahan. Setelah penelusuran kesalahan, ubah versi parser menjadi 2.0 lagi untuk mencapai performa maksimum.
Untuk informasi selengkapnya tentang kapan harus menggunakan versi pengurai mana, lihat Menggunakan OPENROWSET menggunakan kumpulan SQL tanpa server di Synapse Analytics.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Tidak dapat memuat secara massal karena file tidak dapat dibuka
Kesalahan Cannot bulk load because the file could not be opened dikembalikan jika file dimodifikasi selama eksekusi kueri. Biasanya, Anda mungkin mendapatkan kesalahan seperti Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
Kumpulan SQL tanpa server tidak dapat membaca file yang sedang diubah saat kueri sedang berjalan. Kueri tidak dapat mengunci file. Jika Anda tahu bahwa operasi modifikasi adalah tambahkan, Anda dapat mencoba mengatur opsi berikut: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
Untuk informasi selengkapnya, lihat cara mengkueri file append-only atau membuat tabel pada file append-only.
Kueri gagal dengan kesalahan konversi data
Kueri Anda mungkin gagal dengan pesan Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. kesalahan Pesan ini berarti tipe data Anda tidak cocok dengan data aktual untuk nomor baris n dan kolom m.
Misalnya, jika Anda hanya mengharapkan bilangan bulat dalam data Anda, tetapi di baris n ada string, ini adalah pesan kesalahan yang akan Anda dapatkan.
Untuk mengatasi masalah ini, periksa file dan jenis data yang Anda pilih. Periksa juga apakah pemisah baris dan pengaturan terminator bidang Anda sudah benar. Contoh berikut menunjukkan bagaimana pemeriksaan dapat dilakukan dengan menggunakan VARCHAR sebagai jenis kolom.
Untuk informasi selengkapnya tentang terminator bidang, pemisah baris, dan karakter kutipan escape, lihat Kueri file CSV.
Contoh
Jika Anda ingin mengkueri file names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
Dengan kueri berikut:
Kueri 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Kumpulan SQL tanpa server Azure Synapse mengembalikan kesalahan Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
Penting untuk menelusuri data dan membuat keputusan yang tepat dalam menangani masalah ini. Untuk melihat data yang menyebabkan masalah ini, jenis data perlu diubah terlebih dahulu. Sebagai ganti mengkueri kolom ID dengan jenis data SMALLINT, VARCHAR(100) sekarang digunakan untuk menganalisis masalah ini.
Dengan Query 2 yang sedikit berubah ini, data sekarang dapat diproses untuk menampilkan daftar nama.
Kueri 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Anda mungkin mengamati bahwa data memiliki nilai tak terduga untuk ID di baris kelima. Dalam keadaan seperti tersebut, penting untuk menyelaraskan dengan pemilik bisnis data untuk menyetujui bagaimana data korup seperti contoh ini dapat dihindari. Jika pencegahan tidak memungkinkan di tingkat aplikasi, VARCHAR berukuran wajar mungkin menjadi satu-satunya pilihan di sini.
Tip
Coba untuk membuat VARCHAR() sesingkat mungkin. Hindari VARCHAR(MAX) jika memungkinkan karena dapat mengganggu performa.
Hasil kueri tidak terlihat seperti yang diharapkan
Kueri Anda mungkin tidak gagal, tetapi Anda mungkin melihat bahwa kumpulan hasil Anda tidak seperti yang diharapkan. Kolom yang dihasilkan mungkin kosong atau data yang tidak diharapkan mungkin ditampilkan. Dalam skenario ini, kemungkinan pembatas baris atau terminator bidang salah dipilih.
Untuk mengatasi masalah ini, lihat lagi data dan ubah pengaturan tersebut. Memperbaiki kesalahan kueri ini mudah, seperti yang ditunjukkan pada contoh berikut.
Contoh
Jika Anda ingin mengkueri file names.csv dengan kueri di Kueri 1, kumpulan SQL tanpa server Azure Synapse akan kembali dengan hasil yang terlihat aneh:
Dalam names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Sepertinya tidak ada nilai di kolom Firstname. Sebagai gantinya, semua nilai akhirnya berada di kolom ID. Nilai-nilai tersebut dipisahkan dengan koma. Masalahnya disebabkan oleh baris kode ini karena perlu memilih koma, bukan simbol titik koma sebagai pemisah bidang.
FIELDTERMINATOR =';',
Mengubah karakter tunggal ini memecahkan masalah:
FIELDTERMINATOR =',',
Kumpulan hasil yang dibuat oleh Kueri 2 sekarang terlihat seperti yang diharapkan:
Kueri 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Returns:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
Kolom jenis tidak kompatibel dengan jenis data eksternal
Jika kueri Anda gagal dengan pesan Column [column-name] of type [type-name] is not compatible with external data type […], kesalahan, kemungkinan jenis data PARQUET dipetakan ke jenis data SQL yang salah.
Misalnya, jika file Parquet Anda memiliki kolom harga dengan angka float (seperti 12,89) dan Anda mencoba memetakannya ke INT, ini adalah pesan kesalahan yang akan Anda dapatkan.
Untuk mengatasi masalah ini, periksa file dan jenis data yang Anda pilih. Tabel pemetaan ini membantu memilih jenis data SQL yang benar. Sebagai praktik terbaik, tentukan pemetaan hanya untuk kolom yang akan diselesaikan ke dalam jenis data VARCHAR. Menghindari VARCHAR sebisa mungkin dapat memberikan performa kueri yang lebih baik.
Contoh
Jika Anda ingin mengkueri file taxi-data.parquet dengan Kueri 1 ini, kumpulan SQL tanpa server Azure Synapse mengembalikan kesalahan berikut:
File taxi-data.parquet berisi:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Kueri 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Pesan kesalahan ini memberi tahu Anda bahwa jenis data tidak kompatibel dan disertai dengan saran untuk menggunakan FLOAT, bukan INT. Kesalahan disebabkan oleh baris kode ini:
SumTripDistance INT,
Dengan Kueri 2 yang sedikit berubah ini, data sekarang dapat diproses dan menampilkan ketiga kolom:
Kueri 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
Kueri mereferensikan objek yang tidak didukung dalam mode pemrosesan terdistribusi
Kesalahan The query references an object that is not supported in distributed processing mode menunjukkan bahwa Anda telah menggunakan objek atau fungsi yang tidak dapat digunakan saat Anda mengkueri data di penyimpanan analitik Azure Storage atau Azure Cosmos DB.
Beberapa objek, seperti tampilan sistem, dan fungsi tidak dapat digunakan saat Anda membuat kueri data yang disimpan di Azure Data Lake atau penyimpanan analitik Azure Cosmos DB. Hindari menggunakan kueri yang menggabungkan data eksternal dengan tampilan sistem, memuat data eksternal dalam tabel sementara, atau menggunakan beberapa fungsi keamanan atau metadata untuk memfilter data eksternal.
Panggilan WaitIOCompletion gagal
Pesan kesalahan WaitIOCompletion call failed menunjukkan bahwa kueri gagal saat menunggu untuk menyelesaikan operasi I/O yang membaca data dari penyimpanan Azure Data Lake yang merupakan penyimpanan jarak jauh.
Pesan kesalahan memiliki pola berikut: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Pastikan bahwa penyimpanan Anda berada di wilayah yang sama dengan kumpulan SQL tanpa server. Periksa metrik penyimpanan dan pastikan tidak ada beban kerja lain di lapisan penyimpanan, seperti mengunggah file baru, yang dapat memenuhi permintaan I/O.
Bidang HRESULT berisi kode hasil. Kode kesalahan berikut adalah yang paling umum bersama dengan solusi potensialnya.
Kode kesalahan ini berarti file sumber tidak ada dalam penyimpanan.
Ada beberapa alasan mengapa kode galat ini dapat terjadi:
- File tersebut telah dihapus oleh aplikasi lain.
- Dalam skenario umum ini, eksekusi kueri dimulai, menghitung file, dan file ditemukan. Kemudian, selama eksekusi kueri, file dihapus. Misalnya, ini bisa dihapus oleh Databricks, Spark, atau Azure Data Factory. Kueri gagal karena file tidak ditemukan.
- Masalah ini juga dapat terjadi dengan format Delta. Kueri mungkin berhasil saat dicoba lagi karena ada versi baru dari tabel dan file yang dihapus tidak dikuerikan lagi.
- Rencana eksekusi yang tidak valid di-cache.
- Sebagai mitigasi sementara, jalankan perintah
DBCC FREEPROCCACHE. Jika masalah berlanjut, buat tiket dukungan.
- Sebagai mitigasi sementara, jalankan perintah
Sintaksis salah di dekat NOT
Kesalahan Incorrect syntax near 'NOT' menunjukkan ada beberapa tabel eksternal dengan kolom yang berisi batasan NOT NULL dalam definisi kolom.
- Perbarui tabel untuk menghapus NOT NULL dari definisi kolom.
- Kesalahan ini terkadang juga dapat terjadi secara sementara dengan tabel yang dibuat dari pernyataan CETAS. Jika masalah tidak teratasi, Anda dapat mencoba menghapus dan membuat kembali tabel eksternal.
Kolom partisi mengembalikan nilai NULL
Jika kueri Anda menampilkan nilai NULL, bukan mempartisi kolom atau tidak dapat menemukan kolom partisi, ada beberapa langkah pemecahan masalah yang dapat Anda dilakukan:
- Jika Anda menggunakan tabel untuk mengkueri himpunan data yang dipartisi, tabel tidak mendukung pemartisian. Ganti tabel dengan tampilan yang dipartisi.
- Jika Anda menggunakan tampilan yang dipartisi dengan OPENROWSET yang mengkueri file yang dipartisi dengan menggunakan fungsi FILEPATH(), pastikan Anda menentukan dengan benar pola wildcard di lokasi dan menggunakan indeks yang tepat untuk referensi wildcard.
- Jika Anda mengkueri file secara langsung di folder yang dipartisi, kolom partisi bukan bagian dari kolom file. Nilai partisi ditempatkan di jalur folder dan bukan file. Karena alasan ini, file tidak berisi nilai partisi.
Menyisipkan nilai ke batch untuk tipe kolom DATETIME2 gagal
Kesalahan Inserting value to batch for column type DATETIME2 failed menunjukkan bahwa pool tanpa server tidak dapat membaca nilai tanggal dari file dasar. Nilai datetime yang disimpan dalam file Parquet atau Delta Lake tidak dapat direpresentasikan sebagai kolom DATETIME2.
Periksa nilai minimum dalam file dengan menggunakan Spark, dan periksa bahwa beberapa tanggal tidak lebih dari 0001-01-03. Jika Anda menyimpan file dengan menggunakan versi Spark yang lebih tinggi yang masih menggunakan format penyimpanan tanggalwaktu warisan, nilai tanggalwaktu sebelum ditulis dengan menggunakan kalender Julian yang tidak selaras dengan kalender Gregorian proleptik yang digunakan dalam kumpulan SQL tanpa server.
Mungkin ada perbedaan dua hari antara kalender Julian yang digunakan untuk menulis nilai di Parquet (dalam beberapa versi Spark) dan kalender Gregorian proleptik yang digunakan dalam kumpulan SQL tanpa server. Perbedaan ini dapat menyebabkan konversi ke nilai tanggal negatif, yang tidak valid.
Coba gunakan Spark untuk memperbarui nilai-nilai ini karena nilai tersebut diperlakukan sebagai nilai tanggal yang tidak valid dalam SQL. Contoh berikut menunjukkan cara memperbarui nilai yang berada di luar rentang tanggal SQL ke NULL di Delta Lake:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Perubahan ini menghapus nilai yang tidak dapat direpresentasikan. Nilai tanggal lainnya mungkin dimuat dengan benar tetapi salah direpresentasikan karena masih ada perbedaan antara kalender Julian dan kalender Gregorian proleptik. Anda mungkin melihat pergeseran tanggal yang tidak terduga bahkan untuk tanggal sebelum 1900-01-01 jika Anda menggunakan Spark 3.0 atau versi yang lebih lama.
Pertimbangkan untuk bermigrasi ke Spark 3.1 atau yang lebih tinggi dan beralih ke kalender Gregorian proleptik. Versi Spark terbaru menggunakan secara default kalender Gregorian proleptik yang selaras dengan kalender di kumpulan SQL tanpa server. Muat ulang data lama Anda dengan versi Spark yang lebih baru, dan gunakan pengaturan berikut untuk memperbaiki tanggal:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Kueri gagal karena perubahan topologi atau kegagalan kontainer komputasi
Kesalahan ini mungkin menunjukkan bahwa beberapa masalah proses internal terjadi di kumpulan SQL tanpa server. Kirimkan tiket dukungan dengan semua detail yang diperlukan yang dapat membantu tim dukungan Azure menyelidiki masalah tersebut.
Jelaskan apa pun yang mungkin tidak biasa dibandingkan dengan beban kerja biasa. Misalnya, mungkin ada banyak permintaan bersamaan atau beban kerja khusus atau kueri yang mulai dijalankan sebelum kesalahan ini terjadi.
Waktu ekspansi wildcard habis
Sebagaimana dijelaskan pada bagian Folder kueri dan beberapa file, Serverless SQL pool mendukung pembacaan beberapa file/folder dengan menggunakan wildcard. Ada batas maksimum 10 kartubebas per kueri. Anda harus menyadari bahwa fungsionalitas ini dikenakan biaya. Dibutuhkan waktu bagi kumpulan tanpa server untuk mencantumkan semua file yang dapat cocok dengan kartubebas. Ini memperkenalkan latensi dan latensi ini dapat meningkat jika jumlah file yang Anda coba kueri tinggi. Dalam hal ini Anda dapat mengalami kesalahan berikut:
"Wildcard expansion timed out after X seconds."
Ada beberapa langkah mitigasi yang dapat Anda lakukan untuk menghindari hal ini:
- Terapkan praktik terbaik yang dijelaskan dalam Praktik Terbaik Kumpulan SQL Tanpa Server.
- Cobalah untuk mengurangi jumlah file yang coba Anda kueri, dengan memampatkan file menjadi file yang lebih besar. Cobalah untuk menjaga ukuran file Anda di atas 100 MB.
- Pastikan filter di atas kolom partisi digunakan sedapat mungkin.
- Jika Anda menggunakan format file delta, gunakan fitur optimalkan tulis di Spark. Hal ini dapat meningkatkan performa kueri dengan mengurangi jumlah data yang perlu dibaca dan diproses. Cara menggunakan penulisan teroptimasi dijelaskan dalam Menggunakan penulisan teroptimasi di Apache Spark.
- Untuk menghindari beberapa wildcard tingkat atas dengan secara efektif mengodekan filter implisit melalui kolom partisi menggunakan SQL dinamis.
Kolom hilang saat menggunakan inferensi skema otomatis
Anda dapat dengan mudah mengkueri file tanpa mengetahui atau menentukan skema, dengan menghilangkan klausa WITH. Dalam hal ini nama kolom dan jenis data akan disimpulkan dari file. Perlu diingat bahwa jika Anda membaca sejumlah file sekaligus, skema akan disimpulkan berdasarkan file pertama yang diambil layanan dari penyimpanan. Ini dapat berarti bahwa beberapa kolom yang diharapkan dihilangkan, semua karena file yang digunakan oleh layanan untuk menentukan skema tidak berisi kolom ini. Untuk menentukan skema secara eksplisit, gunakan klausa OPENROWSET WITH. Jika Anda menentukan skema (dengan menggunakan tabel eksternal atau klausul OPENROWSET WITH) mode jalur laks default akan digunakan. Itu berarti bahwa kolom yang tidak ada di beberapa file akan dikembalikan sebagai NULL (untuk baris dari file tersebut). Untuk memahami bagaimana mode jalur digunakan, periksa dokumentasi dan sampel berikut.
Konfigurasi
Kumpulan SQL tanpa server memungkinkan Anda menggunakan T-SQL untuk mengonfigurasi objek database. Ada beberapa kendala:
- Anda tidak dapat membuat objek di
masterdanlakehouseatau database Spark. - Anda harus memiliki kunci master untuk membuat kredensial.
- Anda harus memiliki izin untuk mereferensikan data yang digunakan dalam objek.
Tidak dapat membuat database
Jika Anda mendapatkan kesalahan CREATE DATABASE failed. User database limit has been already reached., Anda telah membuat jumlah maksimum database yang didukung di satu ruang kerja. Untuk informasi selengkapnya, lihat Batasan.
- Jika Anda perlu memisahkan objek, gunakan skema dalam database.
- Jika Anda perlu mereferensikan penyimpanan Azure Data Lake, buat database lakehouse atau database Spark yang akan disinkronkan di kumpulan SQL tanpa server.
Membuat atau mengubah tabel gagal karena ukuran baris minimum melebihi ukuran baris tabel maksimum yang diizinkan sebesar 8060 byte
Setiap tabel dapat memiliki ukuran hingga 8 KB per baris (tidak termasuk data VARCHAR(MAX)/VARBINARY(MAX) off-row. Jika Anda membuat tabel di mana ukuran total sel dalam baris melebihi 8060 byte, Anda akan mendapatkan kesalahan berikut:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Kesalahan ini juga mungkin terjadi di database Lake jika Anda membuat tabel Spark dengan ukuran kolom yang melebihi 8060 byte, dan kumpulan SQL tanpa server tidak dapat membuat tabel yang mereferensikan data tabel Spark.
Sebagai mitigasi, hindari menggunakan jenis ukuran tetap seperti CHAR(N) dan ganti dengan jenis ukuran VARCHAR(N) variabel, atau kurangi ukuran dalam CHAR(N). Lihat Batasan grup baris 8 KB di SQL Server.
Buat kunci master di database atau buka kunci master di sesi sebelum melakukan operasi ini
Jika kueri Anda gagal dengan pesan Please create a master key in the database or open the master key in the session before performing this operation.kesalahan , artinya database pengguna Anda tidak memiliki akses ke kunci master saat ini.
Kemungkinan besar, Anda membuat database pengguna baru dan belum membuat kunci master.
Untuk mengatasi masalah ini, buat kunci master dengan kueri berikut:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Catatan
Ganti 'strongpasswordhere' dengan rahasia lain di sini.
Pernyataan CREATE tidak didukung di database master
Jika kueri Anda gagal dengan pesan Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database.kesalahan , itu berarti bahwa master database di kumpulan SQL tanpa server tidak mendukung pembuatan:
- Tabel eksternal.
- Sumber data eksternal.
- Kredensial cakupan database.
- Format file eksternal.
Berikut solusinya:
Buat database pengguna:
CREATE DATABASE <DATABASE_NAME>Jalankan pernyataan CREATE dalam konteks <DATABASE_NAME>, yang sebelumnya gagal untuk database
master.Berikut contoh pembuatan format file eksternal:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Tidak dapat membuat login atau pengguna Microsoft Entra
Jika Anda mendapatkan kesalahan saat mencoba membuat login atau pengguna Microsoft Entra baru dalam database, periksa login yang Anda gunakan untuk menyambungkan ke database Anda. Login yang mencoba membuat pengguna Microsoft Entra baru harus memiliki izin untuk mengakses domain Microsoft Entra dan memeriksa apakah pengguna ada. Perlu diketahui bahwa:
- Login SQL tidak memiliki izin ini, jadi Anda akan selalu mendapatkan kesalahan ini jika Anda menggunakan autentikasi SQL.
- Jika Anda menggunakan login Microsoft Entra untuk membuat login baru, periksa untuk melihat apakah Anda memiliki izin untuk mengakses domain Microsoft Entra.
Azure Cosmos DB
Kumpulan SQL tanpa server memungkinkan Anda mengkueri penyimpanan analitik Azure Cosmos DB dengan menggunakan fungsi OPENROWSET. Pastikan kontainer Azure Cosmos DB Anda memiliki penyimpanan analitik. Pastikan Anda menentukan akun, database, dan nama kontainer dengan benar. Pastikan juga bahwa kunci akun Azure Cosmos DB Anda valid. Untuk informasi selengkapnya, lihat Prasyarat.
Tidak dapat mengkueri Azure Cosmos DB dengan menggunakan fungsi OPENROWSET
Jika Anda tidak dapat terhubung ke akun Azure Cosmos DB, lihat prasyarat. Kemungkinan kesalahan dan tindakan pemecahan masalah tercantum dalam tabel berikut.
| Kesalahan | Akar masalah |
|---|---|
| Kesalahan sintaksis: - Sintaks salah di dekat OPENROWSET.- ... bukan opsi penyedia BULK OPENROWSET yang dikenali.- Sintaks salah di dekat .... |
Kemungkinan akar penyebabnya: - Tidak menggunakan Azure Cosmos DB sebagai parameter pertama. - Menggunakan string literal dan bukan pengidentifikasi di parameter ketiga. - Tidak menentukan parameter ketiga (nama kontainer). |
| Ada kesalahan dalam string koneksi Azure Cosmos DB. | - Akun, database, atau kunci tidak ditentukan. - Opsi dalam string koneksi tidak dikenali. - Titik koma ( ;) ditempatkan di akhir string koneksi. |
| Gagal menyelesaikan jalur Azure Cosmos DB dengan kesalahan "Nama akun salah" atau "Nama database salah." | Nama akun, nama database, atau kontainer yang ditentukan tidak dapat ditemukan, atau penyimpanan analitik belum diaktifkan ke koleksi yang ditentukan. |
| Gagal mengurai jalur Azure Cosmos DB dengan kesalahan "Nilai rahasia salah" atau "Rahasia tidak ada atau kosong." | Kunci akun tidak valid atau hilang. |
Peringatan kolasi UTF-8 dikembalikan saat membaca jenis string di Azure Cosmos DB
Kumpulan SQL tanpa server mengembalikan peringatan waktu kompilasi jika kolase kolom OPENROWSET tidak memiliki pengodean UTF-8. Anda dapat dengan mudah mengubah kolase default untuk semua OPENROWSET fungsi yang berjalan dalam database saat ini dengan menggunakan pernyataan T-SQL:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Kolase Latin1_General_100_BIN2_UTF8 memberikan performa terbaik saat Anda memfilter data menggunakan predikat string.
Baris yang hilang di penyimpanan analitik Azure Cosmos DB
Beberapa item dari Azure Cosmos DB mungkin tidak dikembalikan oleh fungsi OPENROWSET. Perlu diketahui bahwa:
- Ada penundaan sinkronisasi antara penyimpanan transaksional dan analitik. Dokumen yang Anda masukkan di penyimpanan transaksional Azure Cosmos DB mungkin muncul di penyimpanan analitik setelah dua hingga tiga menit.
- Dokumen mungkin melanggar beberapa batasan skema.
Kueri menampilkan nilai NULL di beberapa item Azure Cosmos DB
Azure Synapse SQL menampilkan NULL, bukan nilai yang Anda lihat di penyimpanan transaksi dalam kasus berikut ini:
- Ada penundaan sinkronisasi antara penyimpanan transaksional dan analitik. Nilai yang Anda masukkan di penyimpanan transaksional Azure Cosmos DB mungkin muncul di penyimpanan analitik setelah dua hingga tiga menit.
- Mungkin ada nama kolom atau ekspresi jalur yang salah dalam klausa WITH. Nama kolom (atau ekspresi jalur setelah jenis kolom) di klausa WITH harus cocok dengan nama properti dalam koleksi Azure Cosmos DB. Perbandingan peka huruf besar/kecil. Misalnya,
productCodedanProductCodemerupakan properti yang berbeda. Pastikan nama kolom Anda sama persis dengan nama properti Azure Cosmos DB. - Properti mungkin tidak dipindahkan ke penyimpanan analitik karena melanggar beberapa batasan skema, seperti lebih dari 1.000 properti atau lebih dari 127 tingkat bersarang.
- Jika Anda menggunakan representasi skema yang terdefinisi dengan baik, nilai di penyimpanan transaksional mungkin memiliki jenis yang salah. Skema yang ditentukan dengan baik mengunci jenis untuk setiap properti dengan mengambil sampel dokumen. Nilai apa pun yang ditambahkan dalam penyimpanan transaksional yang tidak cocok dengan jenis diperlakukan sebagai nilai yang salah dan tidak dimigrasikan ke penyimpanan analitis.
- Jika Anda menggunakan representasi skema dengan tingkat kesetiaan penuh, pastikan Anda menambahkan akhiran jenis setelah nama properti seperti
$.price.int64. Jika Anda tidak melihat nilai untuk jalur yang direferensikan, mungkin nilai tersebut disimpan di bagian jalur jenis yang berbeda, misalnya,$.price.float64. Untuk informasi selengkapnya, lihat Mengkueri koleksi Azure Cosmos DB dalam skema fidelitas penuh.
Kolom tidak kompatibel dengan jenis data eksternal
Kesalahan Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. dikembalikan jika jenis kolom yang ditentukan dalam klausa WITH tidak cocok dengan jenis dalam kontainer Azure Cosmos DB. Coba ubah tipe kolom sebagaimana dijelaskan di bagian Pemetaan tipe Azure Cosmos DB ke SQL atau gunakan tipe VARCHAR.
Mengatasi: Jalur Azure Cosmos DB gagal dengan kesalahan
Jika Anda mendapatkan kesalahan Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'., periksa untuk melihat apakah Anda menggunakan titik akhir privat di Azure Cosmos DB. Untuk mengizinkan kumpulan SQL tanpa server mengakses penyimpanan analitik dengan titik akhir privat, Anda harus mengonfigurasi titik akhir privat untuk penyimpanan analitik Azure Cosmos DB.
Masalah performa Azure Cosmos DB
Jika Anda mengalami beberapa masalah performa yang tidak terduga, pastikan Anda menerapkan praktik terbaik, seperti:
- Pastikan Anda menempatkan aplikasi klien, kumpulan tanpa server, dan penyimpanan analitik Azure Cosmos DB di wilayah yang sama.
- Pastikan Anda menggunakan klausa WITH dengan jenis data yang optimal.
- Pastikan Anda menggunakan kolase Latin1_General_100_BIN2_UTF8 saat memfilter data dengan menggunakan predikat string.
- Jika Anda memiliki kueri berulang yang mungkin di-cache, coba gunakan CETAS untuk menyimpan hasil kueri di Azure Data Lake Storage.
Danau Delta
Ada beberapa batasan yang mungkin Anda lihat di dukungan Delta Lake di kumpulan SQL tanpa server:
- Pastikan Anda merujuk folder akar Delta Lake di fungsi OPENROWSET atau lokasi tabel eksternal.
- Folder akar harus memiliki subfolder bernama
_delta_log. Kueri gagal jika tidak ada folder_delta_log. Jika Anda tidak melihat folder tersebut, Anda merujuk file Parquet biasa yang harus dikonversi ke Delta Lake dengan menggunakan kumpulan Apache Spark. - Jangan tentukan wildcard untuk menjelaskan skema partisi. Kueri Delta Lake secara otomatis mengidentifikasi partisi Delta Lake.
- Folder akar harus memiliki subfolder bernama
- Tabel Delta Lake yang dibuat di kumpulan Apache Spark secara otomatis tersedia di kumpulan SQL tanpa server, tetapi skema tidak diperbarui (batasan pratinjau publik). Jika Anda menambahkan kolom dalam tabel Delta menggunakan kumpulan Spark, perubahan tidak akan ditampilkan dalam database kumpulan SQL tanpa server.
- Tabel eksternal tidak mendukung partisi. Gunakan tampilan yang dipartisi di folder Delta Lake untuk menggunakan penghapusan partisi. Lihat masalah umum dan solusinya nanti dalam artikel ini.
- Kumpulan SQL tanpa server tidak mendukung kueri perjalanan waktu. Gunakan kumpulan Apache Spark di Synapse Analytics untuk membaca data historis.
- Kumpulan SQL tanpa server tidak mendukung pembaruan file Delta Lake. Anda dapat menggunakan kumpulan SQL tanpa server untuk meminta versi terbaru Delta Lake. Gunakan kumpulan Apache Spark di Synapse Analytics untuk memperbarui Delta Lake.
- Anda tidak dapat menyimpan hasil kueri ke penyimpanan dalam format Delta Lake dengan menggunakan perintah CETAS. Perintah CETAS hanya mendukung Parquet dan CSV sebagai format output.
- Kumpulan SQL tanpa server di Synapse Analytics kompatibel dengan pembaca Delta versi 1.
- Kumpulan SQL tanpa server di Synapse Analytics tidak mendukung himpunan data dengan filter BLOOM. Kumpulan SQL tanpa server mengabaikan filter BLOOM.
- Dukungan Delta Lake tidak tersedia di kumpulan SQL khusus. Pastikan Anda menggunakan kumpulan SQL tanpa server untuk membuat kueri file Delta Lake.
- Untuk informasi selengkapnya tentang masalah yang sudah diketahui dengan SQL pool tanpa server, lihat Masalah yang sudah diketahui Azure Synapse Analytics.
Dukungan tanpa server versi Delta 1.0
Kumpulan SQL tanpa server hanya membaca versi Delta Lake 1.0. Kumpulan SQL tanpa server adalah pembaca Delta dengan tingkat 1, dan tidak mendukung fitur berikut:
- Pemetaan kolom diabaikan - kumpulan SQL tanpa server akan mengembalikan nama kolom asli.
- Vektor penghapusan diabaikan dan versi lama baris yang dihapus/diperbarui akan dikembalikan (mungkin hasil yang salah).
- Fitur Delta Lake berikut tidak didukung: pemeriksaan V2, tanda waktu tanpa zona waktu, pemeriksaan protokol VACUUM
Vektor penghapusan diabaikan
Jika tabel Delta lake Anda dikonfigurasi untuk menggunakan penulis Delta versi 7, tabel tersebut akan menyimpan baris yang dihapus dan versi lama baris yang diperbarui di Delete Vectors (DV). Karena kumpulan SQL tanpa server memiliki pembaca Delta tingkat 1, mereka akan mengabaikan vektor penghapusan dan mungkin menghasilkan hasil yang salah saat membaca versi Delta Lake yang tidak didukung.
Penggantian nama kolom dalam tabel Delta tidak didukung
Kumpulan SQL tanpa server tidak mendukung kueri tabel Delta Lake dengan kolom yang diganti namanya. Kumpulan SQL tanpa server tidak dapat membaca data dari kolom yang diganti namanya.
Nilai kolom dalam tabel Delta adalah NULL
Jika Anda menggunakan himpunan data Delta yang memerlukan pembaca Delta versi 2 atau yang lebih tinggi, dan menggunakan fitur yang tidak didukung di versi 1 (misalnya - mengganti nama kolom, menghilangkan kolom, atau pemetaan kolom), nilai dalam kolom yang direferensikan mungkin tidak ditampilkan.
Teks JSON tidak diformat dengan benar
Kesalahan ini menunjukkan bahwa kumpulan SQL tanpa server tidak dapat membaca log transaksi Delta Lake. Anda mungkin akan melihat kesalahan berikut:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Pastikan himpunan data Delta Lake Anda tidak rusak. Verifikasi bahwa Anda dapat membaca konten folder Delta Lake dengan menggunakan kumpulan Apache Spark di Azure Synapse. Dengan cara ini Anda akan memastikan bahwa file _delta_log tidak rusak.
Solusi Sementara
Coba buat pos pemeriksaan pada himpunan data Delta Lake dengan menggunakan kumpulan Apache Spark dan jalankan kembali kueri. Pos pemeriksaan mengumpulkan file log JSON transaksional dan mungkin menyelesaikan masalah.
Jika himpunan data valid, buat tiket dukungan dan berikan informasi selengkapnya:
- Jangan membuat perubahan apa pun seperti menambahkan atau menghapus kolom atau mengoptimalkan tabel karena operasi ini dapat mengubah status file log transaksi Delta Lake.
- Salin konten folder
_delta_logke folder kosong baru. Jangan menyalin file.parquet data. - Coba baca konten yang disalin di folder baru dan verifikasi bahwa Anda mendapatkan kesalahan yang sama.
- Kirim konten file
_delta_logyang disalin ke dukungan Azure.
Sekarang Anda dapat melanjutkan menggunakan folder Delta Lake dengan Spark pool. Anda akan memberikan salinan data ke dukungan Microsoft jika Anda diizinkan untuk membagikan informasi ini. Tim Azure akan menyelidiki konten file delta_log dan memberikan informasi selengkapnya tentang kemungkinan kesalahan dan solusinya.
Mengatasi log Delta gagal
Kesalahan berikut menunjukkan bahwa kumpulan SQL tanpa server tidak dapat mengatasi log Delta: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. Penyebab paling umum adalah bahwa last_checkpoint_file dalam _delta_log folder lebih besar dari 200 byte karena checkpointSchema bidang yang ditambahkan di Spark 3.3.
Ada dua opsi yang tersedia untuk menghindari kesalahan ini:
- Ubah konfigurasi yang sesuai di dalam notebook Spark dan buat titik pemeriksaan yang baru, sehingga
last_checkpoint_fileakan dibuat ulang. Jika Anda menggunakan Azure Databricks, modifikasi konfigurasi adalah sebagai berikut:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Turunkan ke Spark 3.2.1.
Tim teknisi kami saat ini sedang mengerjakan dukungan yang penuh untuk Spark 3.3.
Tabel Delta yang dibuat di Spark tidak ditampilkan di kumpulan tanpa server
Catatan
Replikasi tabel Delta yang dibuat di Spark masih dalam pratinjau publik.
Jika Anda membuat tabel Delta di Spark, dan tidak diperlihatkan di kumpulan SQL tanpa server, periksa hal berikut:
- Tunggu beberapa waktu (biasanya 30 detik) karena tabel Spark disinkronkan dengan sedikit penundaan.
- Jika tabel tidak muncul di kumpulan SQL tanpa server setelah beberapa waktu, periksa skema tabel Spark Delta. Tabel Spark dengan tipe kompleks atau tipe yang tidak didukung di serverless tidak dapat digunakan. Cobalah untuk membuat tabel Spark Parquet dengan skema yang sama dalam database lake dan periksa apakah tabel tersebut akan muncul di kumpulan SQL tanpa server.
- Periksa folder Delta Lake akses Identitas Terkelola ruang kerja yang dirujuk oleh tabel. Kumpulan SQL tanpa server menggunakan Identitas Terkelola ruang kerja untuk mendapatkan informasi kolom tabel dari penyimpanan untuk membuat tabel.
Database lake
Tabel database Lake yang dibuat menggunakan desainer Spark atau Synapse secara otomatis tersedia di serverless SQL pool untuk melakukan kueri. Anda dapat menggunakan kumpulan SQL tanpa server untuk mengkueri tabel Parquet, CSV, dan Delta Lake yang dibuat menggunakan kumpulan Spark, dan menambahkan skema, tampilan, prosedur, fungsi nilai tabel, dan pengguna Microsoft Entra lainnya yang db_datareader berperan ke database Lake Anda. Kemungkinan masalah tercantum di bagian berikut.
Tabel yang dibuat di Spark tidak tersedia di kumpulan tanpa server
Tabel yang dibuat mungkin tidak segera tersedia di kumpulan SQL tanpa server.
- Tabel akan tersedia di kumpulan tanpa server dengan beberapa penundaan. Anda mungkin perlu menunggu 5-10 menit setelah pembuatan tabel di Spark untuk melihatnya di kumpulan SQL tanpa server.
- Hanya tabel yang mereferensikan format Parquet, CSV, dan Delta yang tersedia di kumpulan SQL tanpa server. Jenis tabel lainnya tidak tersedia.
- Tabel yang berisi beberapa jenis kolom yang tidak didukung tidak akan tersedia di kumpulan SQL tanpa server.
- Mengakses tabel Delta Lake di database Lake berada dalam pratinjau publik. Periksa masalah lain yang tercantum di bagian ini atau di bagian Delta Lake.
Tabel eksternal yang dibuat di Spark memperlihatkan hasil yang tidak terduga dalam kumpulan tanpa server
Dapat terjadi bahwa ada ketidakcocokan antara tabel eksternal Spark sumber dan tabel eksternal yang direplikasi pada kumpulan tanpa server. Ini dapat terjadi jika file yang digunakan dalam membuat tabel eksternal Spark tanpa ekstensi. Untuk mendapatkan hasil yang tepat, pastikan semua file memiliki ekstensi seperti .parquet.
Operasi tidak diizinkan untuk database yang direplikasi
Kesalahan ini dikembalikan jika Anda mencoba mengubah database Lake, membuat tabel eksternal, sumber data eksternal, kredensial cakupan database, atau objek lain di database Lake Anda. Objek ini hanya dapat dibuat pada database SQL.
Database Lake direplikasi dari kumpulan Apache Spark dan dikelola oleh Apache Spark. Oleh karena itu, Anda tidak dapat membuat objek seperti di SQL Database dengan menggunakan bahasa T-SQL.
Hanya operasi berikut yang diizinkan dalam database Lake:
- Membuat, menghilangkan, atau mengubah tampilan, prosedur, dan fungsi nilai tabel sebaris (iTVF) dalam skema selain
dbo. - Membuat dan menghilangkan pengguna database dari ID Microsoft Entra.
- Menambahkan atau menghapus pengguna database dari skema
db_datareader.
Operasi lain tidak diizinkan dalam database Lake.
Catatan
Jika Anda membuat tampilan, prosedur, atau fungsi di skema dbo (atau menghilangkan skema dan menggunakan skema default yang biasanya dbo), Anda akan mendapatkan pesan kesalahan.
Tabel Delta di database Lake tidak tersedia di kumpulan SQL tanpa server
Pastikan bahwa Identitas Terkelola ruang kerja Anda memiliki akses baca pada penyimpanan ADLS yang berisi folder Delta. Kumpulan SQL tanpa server membaca skema tabel Delta Lake dari log Delta yang ditempatkan di ADLS dan menggunakan Identitas Terkelola ruang kerja untuk mengakses log transaksi Delta.
Cobalah untuk menyiapkan sumber data dalam suatu Database SQL yang mereferensikan Azure Data Lake Storage Anda menggunakan kredensial Managed Identity, dan coba buat tabel eksternal pada sumber data dengan Managed Identity untuk mengonfirmasi bahwa tabel dengan Managed Identity dapat mengakses penyimpanan.
Tabel Delta dalam database Lake tidak memiliki skema yang identik di Spark dan kumpulan tanpa server
Kumpulan SQL tanpa server memungkinkan Anda mengakses tabel Parquet, CSV, dan Delta yang dibuat di database Lake menggunakan perancang Spark atau Synapse. Mengakses tabel Delta masih dalam pratinjau publik, dan saat ini tanpa server akan menyinkronkan tabel Delta dengan Spark pada saat pembuatan tetapi tidak akan memperbarui skema jika kolom ditambahkan nanti menggunakan ALTER TABLE pernyataan di Spark.
Ini adalah batasan pratinjau publik. Letakkan dan buat ulang tabel Delta di Spark (jika memungkinkan) alih-alih mengubah tabel untuk mengatasi masalah ini.
Batas waktu kueri atau penurunan performa pada tabel
Ketika tabel asli di Spark atau Dataverse dimodifikasi, tabel yang sesuai di kumpulan tanpa server secara otomatis dibuat ulang. Proses ini mengakibatkan hilangnya statistik yang ada pada tabel. Tanpa statistik ini, kueri pada tabel mungkin mengalami penundaan atau bahkan waktu habis.
Jika Anda mengalami masalah ini, pertimbangkan untuk menyiapkan pekerjaan untuk membuat ulang statistik pada tabel setelah perubahan di Spark/Dataverse atau pada jadwal reguler.
Performance
Kumpulan SQL tanpa server menetapkan sumber daya ke kueri berdasarkan ukuran himpunan data dan kompleksitas kueri. Anda tidak dapat mengubah atau membatasi sumber daya yang disediakan untuk kueri. Ada beberapa kasus di mana Anda mungkin mengalami penurunan kinerja kueri yang tidak terduga dan Anda mungkin harus mengidentifikasi akar penyebabnya.
Durasi kueri sangat panjang
Jika Anda memiliki kueri dengan durasi kueri lebih dari 30 menit, kueri perlahan mengembalikan hasil ke klien lambat. Kumpulan SQL tanpa server memiliki batas eksekusi 30 menit. Waktu lainnya dihabiskan untuk streaming hasil. Coba solusi berikut:
- Jika Anda menggunakan Synapse Studio, coba reproduksi masalah dengan beberapa aplikasi lain seperti SQL Server Management Studio atau Visual Studio Code.
- Jika kueri Anda lambat saat dijalankan dengan menggunakan SQL Server Management Studio, Visual Studio Code, Power BI, atau beberapa aplikasi lainnya, periksa masalah jaringan dan praktik terbaik.
- Masukkan kueri dalam perintah CETAS dan hitung durasi kueri. Perintah CETAS menyimpan hasil ke Azure Data Lake Storage dan tidak bergantung pada koneksi klien. Jika perintah CETAS selesai lebih cepat dari kueri asli, periksa bandwidth jaringan antara klien dan kumpulan SQL tanpa server.
Kueri lambat saat dijalankan dengan menggunakan Synapse Studio
Jika Anda menggunakan Synapse Studio, coba gunakan klien desktop seperti SQL Server Management Studio atau Visual Studio Code. Synapse Studio adalah klien web yang terhubung ke kumpulan SQL tanpa server dengan menggunakan protokol HTTP, yang umumnya lebih lambat daripada koneksi SQL asli yang digunakan di SQL Server Management Studio atau Visual Studio Code.
Kuery lambat saat dijalankan dengan menggunakan aplikasi
Periksa masalah berikut jika Anda mengalami eksekusi kueri yang lambat:
- Pastikan bahwa aplikasi klien Anda ditempatkan bersama dengan titik akhir kumpulan SQL nirserver. Menjalankan kueri di seluruh wilayah dapat menyebabkan latensi ekstra dan streaming lambat dari tataan hasil.
- Pastikan Anda tidak memiliki masalah jaringan yang dapat menyebabkan streaming lambat dari kumpulan hasil
- Pastikan bahwa aplikasi klien memiliki sumber daya yang cukup (misalnya, tidak menggunakan CPU 100%).
- Pastikan akun penyimpanan atau penyimpanan analitik Azure Cosmos DB ditempatkan di wilayah yang sama dengan titik akhir SQL tanpa server Anda.
Lihat praktik terbaik untuk menyusun sumber daya.
Variasi tinggi dalam durasi kueri
Jika Anda menjalankan kueri yang sama dan mengamati variasi dalam durasi kueri, beberapa alasan dapat menyebabkan perilaku ini:
- Periksa apakah ini adalah eksekusi kueri pertama. Eksekusi pertama kueri mengumpulkan statistik yang diperlukan untuk membuat rencana. Statistik dikumpulkan dengan memindai file yang mendasarinya dan dapat meningkatkan durasi kueri. Di Synapse Studio, Anda akan melihat kueri "pembuatan statistik global" dalam daftar permintaan SQL yang dijalankan sebelum kueri Anda.
- Statistik mungkin akan kedaluwarsa setelah beberapa waktu. Secara berkala, Anda mungkin mengamati dampak pada performa karena kumpulan tanpa server harus memindai dan membuat ulang statistik. Anda mungkin melihat kueri "pembuatan statistik global" lain dalam daftar permintaan SQL yang dijalankan sebelum kueri Anda.
- Periksa apakah ada beban kerja yang berjalan pada titik akhir yang sama saat Anda menjalankan kueri dengan durasi yang lebih lama. Titik akhir SQL tanpa server mengalokasikan sumber daya secara merata ke semua kueri yang dijalankan secara paralel, dan kueri mungkin tertunda.
Connections
Kumpulan SQL tanpa server memungkinkan Anda terhubung dengan menggunakan protokol TDS dan dengan menggunakan bahasa T-SQL untuk kueri data. Sebagian besar alat yang dapat terhubung ke SQL Server atau Azure SQL Database juga dapat terhubung ke kumpulan SQL tanpa server.
Kumpulan SQL sedang dipanaskan
Setelah periode tidak aktif yang lebih lama, kumpulan SQL tanpa server akan dinonaktifkan. Aktivasi terjadi secara otomatis pada aktivitas pertama berikutnya, seperti upaya koneksi pertama. Proses aktivasi mungkin memakan waktu sedikit lebih lama daripada interval upaya koneksi tunggal, sehingga pesan kesalahan ditampilkan. Mencoba kembali upaya koneksi sudah cukup.
Sebagai praktik terbaik, untuk klien yang mendukungnya, gunakan kata kunci string koneksi ConnectionRetryCount dan ConnectRetryInterval untuk mengontrol perilaku koneksi ulang. Sebagian besar driver klien SQL memiliki batas waktu koneksi default yang diatur ke 15 detik. Pastikan batas waktu koneksi dikonfigurasi untuk mengizinkan semua upaya coba lagi. Misalnya, nilai yang dipilih harus memenuhi kondisi berikut: Connection Timeout > ConnectRetryCount * ConnectionRetryInterval.
Jika pesan kesalahan berlanjut, ajukan tiket dukungan melalui portal Azure.
Tidak dapat terhubung dari Synapse Studio
Lihat bagian Synapse Studio.
Tidak dapat terhubung ke kumpulan Azure Synapse dari alat
Beberapa alat mungkin tidak memiliki opsi eksplisit yang dapat Anda gunakan untuk menghubungkan ke kumpulan SQL tanpa server Azure Synapse. Gunakan opsi yang akan Anda gunakan untuk menghubungkan ke SQL Server atau SQL Database. Dialog koneksi tidak perlu dicap sebagai "Synapse" karena kumpulan SQL tanpa server menggunakan protokol yang sama dengan SQL Server atau SQL Database.
Meskipun alat memungkinkan Anda memasukkan hanya nama server logis dan menetapkan domain database.windows.net sebelumnya, masukkan nama ruang kerja Azure Synapse diikuti dengan akhiran -ondemand dan domain database.windows.net.
Keamanan
Pastikan pengguna memiliki izin untuk mengakses database, izin untuk menjalankan perintah, dan izin untuk mengakses Azure Data Lake atau penyimpanan Azure Cosmos DB.
Tidak dapat mengakses akun Azure Cosmos DB
Anda harus menggunakan kunci Azure Cosmos DB baca-saja untuk mengakses penyimpanan analitik, jadi pastikan bahwa kunci tersebut tidak kedaluwarsa atau tidak dibuat ulang.
Jika Anda mendapatkan kesalahan "Gagal menyelesaikan jalur Azure Cosmos DB dengan kesalahan", pastikan Anda mengonfigurasi firewall.
Tidak dapat mengakses database lakehouse atau Spark
Jika pengguna tidak dapat mengakses lakehouse atau database Spark, pengguna mungkin tidak memiliki izin untuk mengakses dan membaca database. Pengguna dengan izin CONTROL SERVER harus memiliki akses penuh ke semua database. Sebagai izin terbatas, Anda mungkin mencoba menggunakan CONNECT ANY DATABASE dan SELECT ALL USER SECURABLES.
Pengguna SQL tidak dapat mengakses tabel Dataverse
Tabel Dataverse mengakses penyimpanan dengan memanfaatkan identitas Microsoft Entra dari pemanggil. Pengguna SQL dengan izin tinggi mungkin mencoba memilih data dari tabel, tetapi tabel tidak akan dapat mengakses data Dataverse. Skenario ini tidak didukung.
Kegagalan masuk perwakilan layanan Microsoft Entra saat SPI membuat penetapan peran
Jika Anda ingin membuat penetapan peran untuk pengidentifikasi perwakilan layanan (SPI) atau aplikasi Microsoft Entra dengan menggunakan SPI lain, atau jika Anda sudah membuatnya namun gagal masuk, Anda mungkin akan menerima kesalahan berikut: Login error: Login failed for user '<token-identified principal>'.
Untuk prinsipal layanan, login harus dibuat dengan menggunakan ID aplikasi sebagai ID keamanan (SID) bukan dengan ID objek. Ada batasan yang diketahui untuk perwakilan layanan, yang mencegah Azure Synapse mengambil ID aplikasi dari Microsoft Graph saat membuat penetapan peran untuk SPI atau aplikasi lain.
Solusi 1
Buka portal Microsoft Azure>Synapse Studio>Kelola>Kontrol akses dan tambahkan secara manual Administrator Synapse atau Administrator Synapse SQL untuk perwakilan layanan yang diinginkan.
Solusi 2
Anda harus membuat login yang tepat secara manual dengan kode SQL:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Solusi 3
Anda juga dapat menyiapkan admin Azure Synapse perwakilan layanan dengan menggunakan PowerShell. Anda harus menginstal modul Az.Synapse.
Solusinya adalah menggunakan cmdlet New-AzSynapseRoleAssignment dengan -ObjectId "parameter". Di bidang parameter tersebut, berikan ID aplikasi, bukan ID objek dengan menggunakan kredensial perwakilan layanan Azure admin ruang kerja.
Skrip PowerShell:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Catatan
Dalam hal ini, UI studio data synapse tidak akan menampilkan penetapan peran yang ditambahkan oleh metode di atas, sehingga disarankan untuk menambahkan penetapan peran ke ID objek dan ID aplikasi secara bersamaan sehingga dapat ditampilkan di UI juga.
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Administrator Synapse" -ObjectId "<object_id_to_add_as_admin>" [-Debug]
Validasi
Sambungkan ke titik akhir SQL tanpa server dan verifikasi bahwa login eksternal dengan SID (app_id_to_add_as_admin dalam sampel sebelumnya) dibuat:
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Atau, coba masuk ke endpoint SQL tanpa server dengan menggunakan aplikasi pengaturan admin.
Constraints
Beberapa batasan sistem umum mungkin memengaruhi beban kerja Anda:
| Property | Pembatasan |
|---|---|
| Jumlah maksimum ruang kerja Azure Synapse per langganan | Lihat batasan. |
| Jumlah maksimum database per kumpulan tanpa server | 100 (tidak termasuk database yang disinkronkan dari kumpulan Apache Spark). |
| Jumlah maksimum database yang disinkronkan dari kumpulan Apache Spark | Tidak terbatas. |
| Jumlah maksimum objek dalam setiap database | Total jumlah semua objek dalam database tidak boleh melebihi 2.147.483.647. Lihat Batasan di mesin database SQL Server. |
| Panjang pengidentifikasi maksimum dalam karakter | 128. Lihat Batasan di mesin database SQL Server. |
| Durasi kueri maksimum | 30 menit. |
| Ukuran maksimum dari himpunan hasil | Hingga 400 GB dibagikan antara kueri bersamaan. |
| Konkurensi maksimum | Tidak terbatas dan tergantung pada kompleksitas kueri dan jumlah data yang dipindai. Satu kumpulan SQL tanpa server dapat secara bersamaan menangani 1.000 sesi aktif yang mengeksekusi kueri ringan. Jumlahnya akan berkurang jika kueri lebih kompleks atau memindai data dalam jumlah yang lebih besar, jadi pertimbangkan untuk mengurangi konkurensi dan jalankan kueri dalam jangka waktu yang lebih lama jika memungkinkan. |
| Ukuran maksimum nama Tabel Eksternal | 100 karakter. |
Tidak dapat membuat database di kumpulan SQL tanpa server
Kumpulan SQL tanpa server memiliki batasan, dan Anda tidak dapat membuat lebih dari 100 database per ruang kerja. Jika Anda perlu memisahkan objek dan mengisolasinya, gunakan skema.
Jika Anda mendapatkan kesalahan CREATE DATABASE failed. User database limit has been already reached , Anda telah membuat jumlah maksimum database yang didukung dalam satu ruang kerja.
Anda tidak perlu menggunakan database terpisah untuk mengisolasi data untuk penyewa yang berbeda. Semua data disimpan secara eksternal di data lake dan Azure Cosmos DB. Metadata seperti tabel, tampilan, dan definisi fungsi dapat berhasil diisolasi dengan menggunakan skema. Isolasi berbasis skema juga digunakan di Spark di mana database dan skema adalah konsep yang sama.