Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan dukungan keandalan di Azure HDInsight, dan mencakup zona ketersediaan dan pemulihan lintas wilayah dan kelangsungan bisnis. Untuk gambaran umum keandalan yang lebih rinci di Azure, lihat Keandalan Azure.
Dukungan zona ketersediaan
Zona ketersediaan adalah grup pusat data yang terpisah secara fisik dalam wilayah Azure. Ketika satu zona gagal, layanan dapat melakukan failover ke salah satu zona yang tersisa.
Azure HDInsight mendukung konfigurasi penyebaran zona. Simpul kluster Azure HDInsight ditempatkan dalam satu zona yang Anda pilih di wilayah pilihan Anda. Kluster HDInsight zonal diisolasi dari pemadaman apa pun yang terjadi di zona lain. Namun, jika pemadaman berdampak pada zona tertentu yang dipilih untuk kluster HDInsight, kluster tidak akan tersedia. Model penyebaran ini menyediakan konektivitas jaringan latensi rendah yang murah dalam kluster. Mereplikasi model penyebaran ini ke beberapa zona ketersediaan dapat memberikan tingkat ketersediaan yang lebih tinggi untuk melindungi dari kegagalan perangkat keras.
Penting
Untuk penyebaran di mana pengguna tidak menentukan zona tertentu, jenis node tidak memiliki ketahanan zona dan dapat mengalami downtime selama pemadaman di zona mana pun di wilayah tersebut.
Prasyarat
Zona ketersediaan hanya didukung untuk kluster yang dibuat setelah 15 Juni 2023. Pengaturan zona ketersediaan tidak bisa diperbarui setelah kluster dibuat. Anda juga tidak dapat memperbarui kluster bukan zona ketersediaan saat ini untuk menggunakan zona ketersediaan.
Kluster harus dibuat di bawah VNet kustom.
Anda perlu membawa SQL DB Anda sendiri untuk Ambari DB dan metastore eksternal, seperti metastore Apache Hive, sehingga Anda dapat mengonfigurasi DB ini di zona ketersediaan yang sama.
Kluster HDInsight Anda harus dibuat dengan opsi zona ketersediaan di salah satu wilayah berikut:
- Australia Timur
- Brasil Selatan
- Kanada Tengah
- US Tengah
- US Timur
- US Timur 2
- Prancis Tengah
- Jerman Barat Tengah
- Jepang Timur
- Korea Tengah
- Eropa Utara
- Qatar Tengah
- Asia Tenggara
- US Tengah Selatan
- UK Selatan
- US Gov Virginia
- Eropa Barat
- Barat AS 2
Membuat kluster HDInsight menggunakan zona ketersediaan
Anda dapat menggunakan templat Azure Resource Manager (ARM) untuk meluncurkan kluster HDInsight ke zona ketersediaan tertentu.
Di bagian sumber daya, Anda perlu menambahkan bagian 'zona' dan menyediakan zona ketersediaan mana yang Anda inginkan untuk disebarkan kluster ini.
"resources": [
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('cluster name')]",
"location": "East US 2",
"zones": [
"1"
],
}
]
Memverifikasi simpul dalam satu Zona ketersediaan di seluruh zona
Ketika kluster HDInsight sudah siap, Anda dapat memeriksa lokasi untuk melihat zona ketersediaan tempat mereka ditempatkan.

Dapatkan respons API:
[
{
"location": "East US 2",
"zones": [
"1"
],
}
]
Meningkatkan kluster
Anda dapat meningkatkan kluster HDInsight dengan lebih banyak node pekerja. Simpul pekerja yang baru ditambahkan akan ditempatkan di zona ketersediaan yang sama dengan klaster ini.
Migrasi zona ketersediaan
Kluster Azure HDInsight saat ini tidak mendukung migrasi langsung instans kluster yang sudah ada ke dukungan untuk zona ketersediaan. Namun, Anda dapat memilih untuk membuat ulang kluster Anda, dan memilih zona ketersediaan atau wilayah yang berbeda selama pembuatan kluster. Kluster siaga sekunder di wilayah yang berbeda dan zona ketersediaan yang berbeda dapat digunakan dalam skenario pemulihan bencana.
Pengalaman saat zona tidak aktif
Ketika zona ketersediaan turun:
- Anda tidak dapat melakukan ssh ke kluster ini.
- Anda tidak dapat menghapus atau meningkatkan atau menurunkan skala kluster ini.
- Anda tidak dapat mengirimkan pekerjaan atau melihat riwayat pekerjaan.
- Anda masih dapat mengirimkan permintaan pembuatan kluster baru di wilayah yang berbeda.
Pemulihan bencana lintas wilayah dan kelangsungan bisnis
Pemulihan bencana (DR) mengacu pada praktik yang digunakan organisasi untuk pulih dari peristiwa berdampak tinggi, seperti bencana alam atau penyebaran gagal yang mengakibatkan waktu henti dan kehilangan data. Terlepas dari penyebabnya, obat terbaik untuk bencana adalah rencana DR yang terdefinisi dan teruji dengan baik dan desain aplikasi yang secara aktif mendukung DR. Sebelum Anda mulai membuat rencana pemulihan bencana, lihat rekomendasi untuk merancang strategi pemulihan bencana.
Untuk DR, Microsoft menggunakan model tanggung jawab bersama . Dalam model ini, Microsoft memastikan bahwa infrastruktur dasar dan layanan platform tersedia. Namun, banyak layanan Azure tidak secara otomatis mereplikasi data atau beralih dari wilayah yang gagal untuk mereplikasi ke wilayah lain yang tersedia. Untuk layanan tersebut, Anda bertanggung jawab untuk menyiapkan rencana pemulihan bencana yang berfungsi untuk beban kerja Anda. Sebagian besar layanan yang berjalan di penawaran platform as a service (PaaS) Azure menyediakan fitur dan panduan untuk mendukung DR. Anda dapat menggunakan fitur khusus layanan untuk mendukung pemulihan cepat dan membantu mengembangkan rencana DR Anda.
Kluster Azure HDInsight bergantung pada banyak layanan Azure seperti penyimpanan, database, Direktori Aktif, Active Directory Domain Services, jaringan, dan Key Vault. Aplikasi analitik yang dirancang dengan baik, sangat tersedia, dan toleran terhadap kesalahan harus dirancang dengan redundansi yang cukup untuk menahan gangguan regional atau lokal dalam satu atau beberapa layanan ini. Bagian ini memberikan gambaran umum tentang praktik terbaik, ketersediaan tunggal dan multi wilayah, dan opsi pengoptimalan untuk perencanaan kelangsungan bisnis.
Pemulihan bencana dalam geografi multi-wilayah
Meningkatkan kelangsungan bisnis menggunakan pemulihan bencana ketersediaan tinggi lintas wilayah membutuhkan desain arsitektur dengan kompleksitas yang lebih tinggi dan biaya yang lebih tinggi. Tabel berikut merinci beberapa area teknis yang dapat meningkatkan total biaya kepemilikan.
Pengoptimalan Biaya
| Area | Penyebab eskalasi biaya | Strategi pengoptimalan |
|---|---|---|
| Penyimpanan Data | Menduplikasi data/tabel utama di wilayah sekunder | Replikasi hanya data yang dikurasi |
| Pengeluaran Data | Transfer data lintas wilayah yang keluar memiliki biaya. Meninjau panduan harga Bandwidth | Replikasi hanya data yang diseleksi untuk mengurangi biaya egress wilayah |
| Komputasi Kluster | Kluster HDInsight tambahan di wilayah sekunder | Gunakan skrip otomatis untuk menyebarkan komputasi sekunder setelah kegagalan utama. Gunakan Autoscaling untuk menjaga ukuran kluster sekunder tetap minimum. Gunakan SKU VM yang lebih murah. Buat sekunder di wilayah tempat SKU VM dapat didiskon. |
| Authentication | Skenario multipengguna di wilayah sekunder menimbulkan penyiapan Microsoft Entra Domain Services tambahan | Hindari pengaturan multi-pengguna di wilayah sekunder. |
Pengoptimalan kompleksitas
| Area | Penyebab eskalasi kompleksitas | Strategi pengoptimalan |
|---|---|---|
| Pola Menulis dan Membaca | Mengharuskan agar primer dan sekunder diaktifkan untuk Baca dan Tulis | Mendesain elemen sekunder agar hanya dapat dibaca |
| Nol RPO & RTO | Membutuhkan kehilangan data nol (RPO=0) dan waktu henti nol (RTO=0) | Rancang RPO dan RTO dengan cara untuk mengurangi jumlah komponen yang perlu di-failover. Untuk informasi selengkapnya tentang RTO dan RPO, lihat Apa itu kelangsungan bisnis, ketersediaan tinggi, dan pemulihan bencana?. |
| Fungsionalitas bisnis | Memerlukan fungsionalitas bisnis utama dalam sistem sekunder. | Evaluasi apakah Anda dapat menjalankan dengan subset minimum kritis minimum dari fungsionalitas bisnis di sekunder. |
| Connectivity | Mengharuskan semua sistem hulu dan hilir dari sistem primer agar terhubung ke sistem sekunder juga. | Batasi konektivitas sekunder ke subset kritis minimal. |
Saat Anda membuat rencana pemulihan bencana multi-wilayah, pertimbangkan rekomendasi berikut:
Tentukan fungsionalitas bisnis minimal yang Anda butuhkan jika ada bencana dan mengapa. Misalnya, evaluasi apakah Anda memerlukan kemampuan failover untuk lapisan transformasi data (ditampilkan dalam warna kuning) dan lapisan penyajian data (ditampilkan dalam warna biru), atau jika Anda hanya memerlukan failover untuk lapisan layanan data.
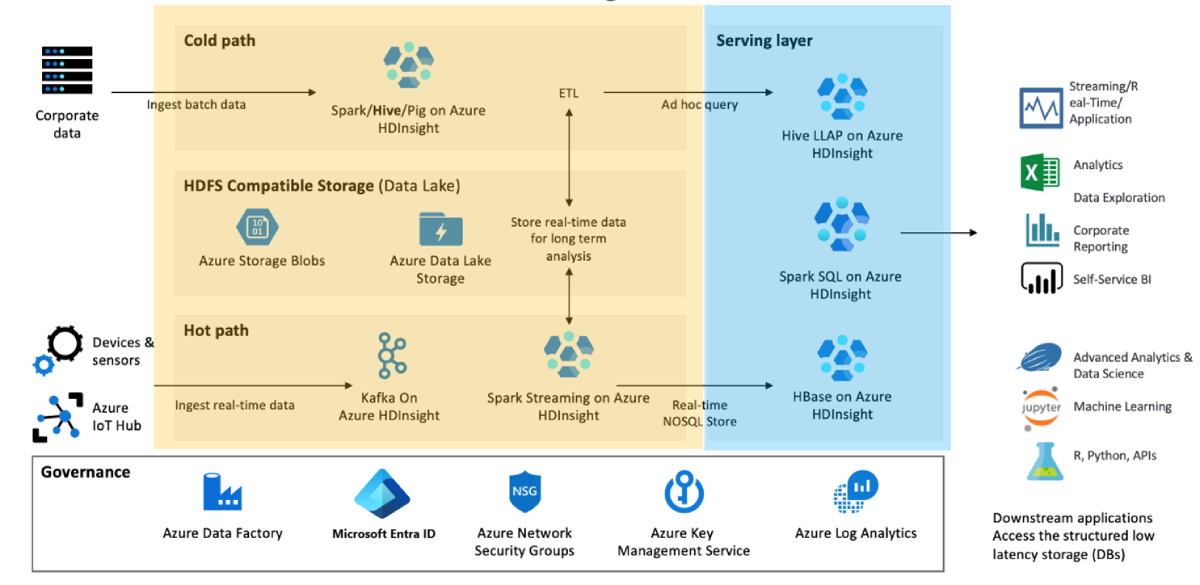
Segmentasikan kluster Anda berdasarkan beban kerja, siklus hidup pengembangan, dan departemen. Memiliki lebih banyak kluster mengurangi kemungkinan kegagalan besar tunggal yang memengaruhi beberapa proses bisnis yang berbeda.
Jadikan wilayah sekunder Anda hanya-baca. Wilayah failover yang memiliki kemampuan baca dan tulis dapat menyebabkan arsitektur menjadi kompleks.
Kluster sementara lebih mudah dikelola ketika ada bencana. Rancang beban kerja Anda dengan cara agar kluster dapat di-siklus dan tidak ada status yang dipertahankan dalam kluster.
Seringkali beban kerja dibiarkan belum selesai jika ada bencana dan perlu dimulai ulang di wilayah baru. Rancang beban kerja Anda agar bersifat idempoten.
Gunakan otomatisasi selama penyebaran kluster dan pastikan pengaturan konfigurasi kluster diskrip sejauh mungkin untuk memastikan penyebaran yang cepat dan sepenuhnya otomatis jika ada bencana.
Deteksi, pemberitahuan, dan manajemen gangguan
Gunakan alat pemantauan Azure di HDInsight untuk mendeteksi perilaku abnormal di kluster dan mengatur pemberitahuan pemberitahuan yang sesuai. Anda dapat menyebarkan solusi manajemen khusus kluster HDInsight yang telah dikonfigurasi sebelumnya yang mengumpulkan metrik performa penting dari jenis kluster tertentu. Untuk informasi selengkapnya, lihat Pemantauan Azure untuk HDInsight.
Berlangganan pemberitahuan kesehatan Azure untuk diberi tahu tentang masalah layanan, pemeliharaan terencana, saran kesehatan dan keamanan untuk langganan, layanan, atau wilayah. Pemberitahuan kesehatan yang mencakup masalah penyebab dan ETA resolut membantu Anda menjalankan failover dan failback dengan lebih baik. Untuk informasi selengkapnya, lihat Dokumentasi Azure Service Health.
Pemulihan bencana dalam geografi wilayah tunggal
Setiap komponen dalam sistem HDInsight dasar memiliki mekanisme toleransi kesalahan wilayah tunggalnya sendiri. Ingatlah bahwa tidak selalu diperlukan peristiwa bencana untuk memengaruhi fungsionalitas bisnis. Insiden layanan di satu atau beberapa layanan berikut dalam satu wilayah juga dapat menyebabkan hilangnya fungsionalitas bisnis yang diharapkan.
Komputasi (komputer virtual): Kluster Azure HDInsight. HDInsight menawarkan ketersediaan Perjanjian Tingkat Layanan (SLA) 99,9%. Untuk memberikan ketersediaan tinggi dalam satu penyebaran, HDInsight disertai dengan banyak layanan yang berada dalam mode ketersediaan tinggi secara default. Mekanisme toleransi kesalahan dalam HDInsight disediakan oleh layanan ketersediaan tinggi ekosistem Microsoft dan Apache OSS.
Komponen infrastruktur berikut dirancang agar sangat tersedia:
- Headnode Aktif dan Siaga
- Beberapa Node Gateway
- Tiga node Kuorum Zookeeper
- Node Pekerja dikelompokkan berdasarkan domain kesalahan dan pembaruan
Layanan berikut ini juga dirancang agar sangat tersedia:
- Apache Ambari Server
- Sever garis waktu aplikasi untuk YARN
- Server Riwayat Pekerjaan untuk Hadoop MapReduce
- Apache Livy
- HDFS (Sistem Berkas Terdistribusi Hadoop)
- YARN Resource Manager (Pengelola Sumber Daya YARN)
- HBase Master
Untuk mempelajari selengkapnya, lihat layanan ketersediaan tinggi yang didukung oleh Azure HDInsight.
Metastore: Azure SQL Database. HDInsight menggunakan Azure SQL Database sebagai metastore, yang menyediakan SLA 99,99%. Tiga replika data bertahan dalam pusat data dengan replikasi sinkron. Jika ada kehilangan replika, replika alternatif disajikan dengan mulus. Replikasi geografis aktif didukung di luar kotak dengan maksimal empat pusat data. Ketika terjadi failover, baik secara manual maupun yang melibatkan pusat data, replika pertama dalam hierarki secara otomatis menjadi dapat berfungsi sebagai baca-tulis. Untuk informasi selengkapnya, lihat Kelangsungan bisnis Azure SQL Database.
Penyimpanan: Penyimpanan Azure Data Lake Gen2 atau Blob. HDInsight merekomendasikan Azure Data Lake Storage Gen2 sebagai lapisan penyimpanan yang mendasar. Azure Storage, termasuk Azure Data Lake Storage Gen2, menyediakan SLA 99,9%. HDInsight menggunakan layanan LRS di mana tiga replika data bertahan dalam pusat data, dan replikasi sinkron. Ketika ada kehilangan replika, replika disajikan dengan mulus.
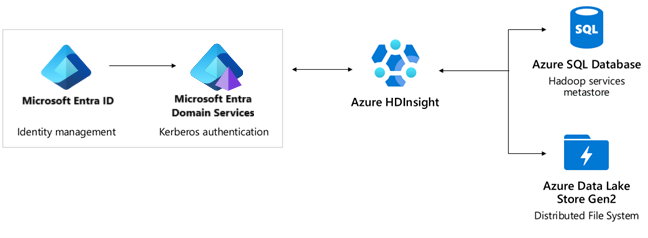
Autentikasi: ID Microsoft Entra, Microsoft Entra Domain Services, Paket Keamanan Perusahaan.
- MICROSOFT Entra ID menyediakan SLA 99,9%. Direktori Aktif adalah layanan global dengan beberapa tingkat redundansi internal dan pemulihan otomatis. Untuk informasi selengkapnya, lihat bagaimana Microsoft terus meningkatkan keandalan ID Microsoft Entra.
- Microsoft Entra Domain Services menyediakan SLA 99,9%. Microsoft Entra Domain Services adalah layanan yang sangat tersedia yang dihosting di pusat data yang didistribusikan secara global. Set replika adalah fitur pratinjau di Microsoft Entra Domain Services yang memungkinkan pemulihan bencana geografis jika suatu wilayah Azure mengalami gangguan. Untuk informasi selengkapnya, lihat konsep dan fitur set replika untuk Microsoft Entra Domain Services untuk mempelajari selengkapnya.
- Azure DNS menyediakan SLA sebesar 100%. HDInsight menggunakan Azure DNS di berbagai tempat untuk resolusi nama domain.
Layanan opsional, seperti Azure Key Vault dan Azure Data Factory.