Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure Blob Storage adalah solusi penyimpanan objek untuk cloud dari Microsoft. Ini dirancang untuk menyimpan sejumlah besar data yang tidak terstruktur seperti teks, data biner, dokumen, file media, dan cadangan aplikasi. Sebagai layanan penyimpanan Azure dasar, Blob Storage menyediakan beberapa fitur keandalan untuk memastikan bahwa data Anda tetap tersedia dan tahan lama selama peristiwa yang direncanakan dan tidak direncanakan.
Saat Anda menggunakan Azure, keandalan adalah tanggung jawab bersama. Microsoft menyediakan berbagai kemampuan untuk mendukung ketahanan dan pemulihan. Anda bertanggung jawab untuk memahami cara kerja kemampuan tersebut dalam semua layanan yang Anda gunakan, dan memilih kemampuan yang Anda butuhkan untuk memenuhi tujuan bisnis dan tujuan waktu aktif Anda.
Artikel ini menjelaskan cara membuat Blob Storage tahan terhadap berbagai potensi pemadaman dan masalah, termasuk kesalahan sementara, pemadaman zona ketersediaan, dan pemadaman wilayah. Ini juga menjelaskan bagaimana Anda dapat menggunakan cadangan untuk memulihkan dari jenis masalah lain, dan menyoroti beberapa informasi utama tentang perjanjian tingkat layanan Blob Storage (SLA).
Nota
Blob Storage adalah bagian dari platform Azure Storage. Beberapa kemampuan Blob Storage umum di banyak layanan Azure Storage. Dalam artikel ini, kami menggunakan Azure Storage untuk merujuk ke fitur-fitur ini.
Rekomendasi penyebaran produksi
Untuk mempelajari tentang cara menyebarkan Blob Storage untuk mendukung persyaratan keandalan solusi Anda, dan bagaimana keandalan memengaruhi aspek lain dari arsitektur Anda, lihat Praktik terbaik arsitektur untuk Blob Storage di Azure Well-Architected Framework.
Gambaran umum arsitektur keandalan
Azure Storage menyediakan beberapa opsi redundansi untuk membantu Anda melindungi data dari berbagai jenis kegagalan. Setiap opsi menyediakan tingkat redundansi data tertentu, sehingga Anda dapat memilih tingkat yang paling sesuai dengan kebutuhan aplikasi Anda.
Penyimpanan redundan lokal (LRS) mereplikasi data dalam akun penyimpanan Anda ke satu atau beberapa zona ketersediaan Azure yang terletak di wilayah utama pilihan Anda. Meskipun tidak ada opsi untuk memilih zona ketersediaan pilihan Anda, Azure dapat memindahkan atau memperluas akun LRS di seluruh zona untuk meningkatkan penyeimbangan beban. Tidak ada jaminan bahwa data Anda akan tersebar di seluruh zona. Untuk informasi selengkapnya tentang zona ketersediaan, lihat Apa itu Zona Ketersediaan?.

Penyimpanan zona redundan (ZRS), penyimpanan geo-redundan (GRS), dan penyimpanan geo-zona-redundan (GZRS) memberikan perlindungan ekstra. Artikel ini menjelaskan opsi ini secara rinci.
Ketahanan terhadap kesalahan sementara
Kesalahan sementara adalah kegagalan yang bersifat sementara dan intermiten dalam komponen. Mereka sering terjadi di lingkungan terdistribusi seperti cloud, dan mereka adalah bagian normal dari operasi. Kesalahan sementara memperbaiki diri setelah waktu yang singkat. Penting bahwa aplikasi Anda dapat menangani kesalahan sementara, biasanya dengan mencoba kembali permintaan yang terpengaruh.
Semua aplikasi yang dihosting cloud harus mengikuti panduan penanganan kesalahan sementara Azure saat berkomunikasi dengan API, database, dan komponen lain yang dihosting cloud. Untuk informasi selengkapnya, lihat Rekomendasi untuk menangani kesalahan sementara.
Untuk mengelola kesalahan sementara secara efektif saat Anda menggunakan Blob Storage, terapkan rekomendasi berikut:
Gunakan pustaka klien Azure Storage, yang mencakup kebijakan coba lagi bawaan dengan backoff eksponensial dan jitter. SDK .NET, Java, Python, dan JavaScript secara otomatis menangani percobaan ulang untuk kegagalan sementara. Untuk informasi selengkapnya tentang opsi konfigurasi coba lagi, lihat Menerapkan kebijakan coba lagi dengan .NET.
Konfigurasikan nilai batas waktu yang sesuai untuk operasi blob Anda berdasarkan ukuran blob dan kondisi jaringan. Blob yang lebih besar memerlukan batas waktu yang lebih lama, tetapi operasi yang lebih kecil dapat menggunakan nilai yang lebih pendek untuk mendeteksi kegagalan dengan cepat.
Ketahanan terhadap kegagalan zona ketersediaan
Zona ketersediaan adalah grup pusat data yang terpisah secara fisik dalam wilayah Azure. Ketika satu zona gagal, layanan dapat melakukan failover ke salah satu zona yang tersisa.
Blob Storage menyediakan dukungan zona ketersediaan yang kuat melalui konfigurasi ZRS yang secara otomatis mendistribusikan data Anda di beberapa zona ketersediaan dalam suatu wilayah. Tidak seperti penyimpanan redundan lokal (LRS), ZRS menjamin bahwa Azure secara sinkron mereplikasi data blob Anda di beberapa zona ketersediaan. ZRS memastikan bahwa data Anda tetap dapat diakses meskipun satu zona mengalami pemadaman.
Redundansi zona diaktifkan di tingkat akun penyimpanan dan berlaku untuk semua kontainer blob dalam akun tersebut. Anda tidak dapat mengatur tingkat redundansi yang berbeda untuk masing-masing kontainer. Konfigurasi redundansi diterapkan ke seluruh akun penyimpanan. Saat zona ketersediaan mengalami pemadaman, Azure Storage secara otomatis merutekan permintaan ke zona sehat tanpa memerlukan intervensi dari Anda atau aplikasi Anda.

Persyaratan
- Dukungan wilayah: Anda dapat menyebarkan akun Azure Storage zona-redundan di wilayah mana pun yang mendukung zona ketersediaan.
- Jenis akun penyimpanan: Redundansi zona tersedia untuk jenis akun penyimpanan Blob Blok v2 tujuan umum Standar dan Premium. Blob blok, blob penambahan, dan blob halaman semua mendukung konfigurasi redundan zona, tetapi jenis akun penyimpanan yang Anda gunakan menentukan kemampuan mana yang tersedia. Untuk informasi selengkapnya, lihat Jenis akun penyimpanan yang didukung.
Biaya
Saat Anda mengaktifkan penyimpanan redundan zona (ZRS), Anda dikenakan biaya dengan tarif yang berbeda dari penyimpanan redundan lokal (LRS) karena replikasi tambahan dan overhead penyimpanan.
Untuk informasi selengkapnya, lihat Harga Blob Storage.
Mengonfigurasi dukungan zona ketersediaan
- Buat akun penyimpanan blob dengan redundansi zona. Untuk membuat akun penyimpanan baru dengan ZRS, lihat Membuat akun penyimpanan dan memilih ZRS, penyimpanan geo-zona-redundan (GZRS), atau penyimpanan geo-redundan akses baca (RA-GZRS) sebagai opsi redundansi selama pembuatan akun.
Ubah jenis replikasi. Untuk mempelajari cara mengubah akun penyimpanan yang ada menjadi penyimpanan redundan zona (ZRS) dan tentang opsi dan persyaratan konfigurasi, lihat Mengubah cara akun penyimpanan direplikasi.
Nonaktifkan redundansi zona. Konversikan akun ZRS kembali ke konfigurasi nonzonal, seperti penyimpanan redundan lokal (LRS), dengan menggunakan proses perubahan konfigurasi redundansi yang sama.
Perilaku ketika semua zona sehat
Bagian ini menjelaskan apa yang diharapkan ketika akun penyimpanan blob dikonfigurasi untuk redundansi zona dan semua zona ketersediaan beroperasi.
Perutean lalu lintas antar zona: Azure Storage dengan penyimpanan zona redundan (ZRS) secara otomatis mendistribusikan permintaan di seluruh kluster penyimpanan di beberapa zona ketersediaan. Distribusi lalu lintas transparan untuk aplikasi dan tidak memerlukan konfigurasi sisi klien.
Replikasi data antar zona: Semua operasi tulis ke ZRS direplikasi secara sinkron di semua zona ketersediaan dalam wilayah tersebut. Saat Anda mengunggah atau mengubah data, operasi tidak dianggap selesai hingga data berhasil direplikasi di semua zona ketersediaan. Replikasi sinkron ini memastikan konsistensi yang kuat dan kehilangan data nol selama kegagalan zona.
Perilaku selama kegagalan zona
Bagian ini menjelaskan apa yang diharapkan ketika akun penyimpanan blob dikonfigurasi untuk ZRS dan ada pemadaman zona ketersediaan.
- Deteksi dan respons: Microsoft secara otomatis mendeteksi kegagalan zona dan memulai proses pemulihan. Tidak ada tindakan pelanggan yang diperlukan untuk akun penyimpanan zona redundan (ZRS). Jika suatu zona menjadi tidak tersedia, Azure akan melakukan pembaruan jaringan, seperti repointing Sistem Penamaan Domain (DNS).
- Pemberitahuan: Microsoft tidak secara otomatis memberi tahu Anda saat zona tidak berfungsi. Namun, Anda dapat menggunakan Azure Resource Health untuk memantau kesehatan sumber daya individual, dan Anda dapat menyiapkan pemberitahuan Resource Health untuk memberi tahu Anda tentang masalah. Anda juga dapat menggunakan Azure Service Health untuk memahami kesehatan layanan secara keseluruhan, termasuk kegagalan zona apa pun, dan Anda dapat menyiapkan pemberitahuan Service Health untuk memberi tahu Anda tentang masalah.
Permintaan aktif: Permintaan dalam penerbangan mungkin dihilangkan selama proses pemulihan dan harus dicoba kembali. Aplikasi harus menerapkan logika coba lagi untuk menangani gangguan sementara ini.
Kehilangan data yang diharapkan: Tidak ada kehilangan data yang terjadi selama kegagalan zona karena data direplikasi secara sinkron di beberapa zona sebelum operasi tulis selesai.
Waktu henti yang diharapkan: Sejumlah kecil waktu henti, biasanya, beberapa detik, mungkin terjadi selama pemulihan otomatis karena lalu lintas dialihkan ke zona sehat. Saat Anda merancang aplikasi untuk ZRS, ikuti praktik untuk penanganan kesalahan sementara, termasuk menerapkan kebijakan coba lagi dengan back-off eksponensial.
- Pengalihan lalu lintas: Jika zona ketersediaan offline, Azure memulai perubahan jaringan seperti titik ulang Sistem Nama Domain (DNS). Pembaruan ini memastikan bahwa lalu lintas dialihkan ke zona ketersediaan sehat yang tersisa. Layanan ini mempertahankan fungsionalitas penuh dengan menggunakan zona yang bertahan dan tidak memerlukan intervensi pelanggan.
Pemulihan zona
Saat zona ketersediaan yang gagal pulih, Azure Storage secara otomatis memulihkan operasi normal di semua zona ketersediaan. Layanan ini secara otomatis memastikan konsistensi data dengan menyinkronkan operasi apa pun yang terjadi selama periode pemadaman.
Uji kegagalan zona
Saat Anda menggunakan penyimpanan redundan zona (ZRS), Azure Storage mengelola replikasi, perutean lalu lintas, dan respons zona tidak berfungsi secara otomatis. Karena fitur ini dikelola sepenuhnya, Anda tidak perlu memulai atau memvalidasi proses kegagalan zona ketersediaan.
Ketahanan terhadap kegagalan di seluruh wilayah
Azure Storage, termasuk Azure Blob Storage, Azure Files, Azure Table Storage, dan Azure Queue Storage, menyediakan berbagai kemampuan geo-redundansi dan failover agar sesuai dengan persyaratan yang berbeda.
Penting
Penyimpanan geo-redundan (GRS) hanya berfungsi dalam wilayah berpasangan Azure. Jika wilayah akun penyimpanan Anda tidak dipasangkan, pertimbangkan menggunakan solusi multi-wilayah kustom untuk ketahanan.
Penyimpanan geo-reduntansi untuk wilayah yang dipadukan
Azure Storage menyediakan beberapa jenis GRS di wilayah berpasangan. Jenis GRS mana pun yang Anda gunakan, data di wilayah sekunder selalu direplikasi dengan menggunakan penyimpanan redundan lokal (LRS). Pendekatan ini memberikan perlindungan terhadap kegagalan perangkat keras di wilayah sekunder.
GRS menyediakan dukungan untuk failover yang direncanakan dan tidak direncanakan ke wilayah berpasangan Azure ketika ada pemadaman di wilayah utama. GRS secara asinkron mereplikasi data dari wilayah utama ke wilayah yang dipasangkan.
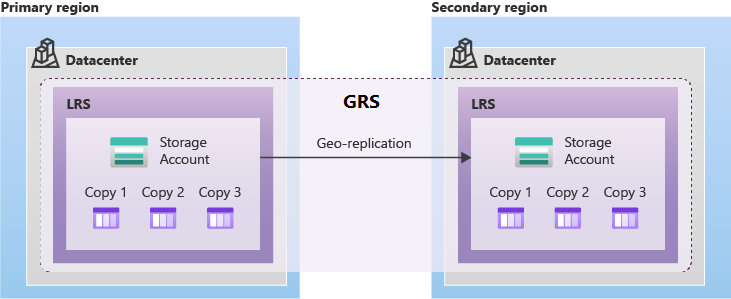
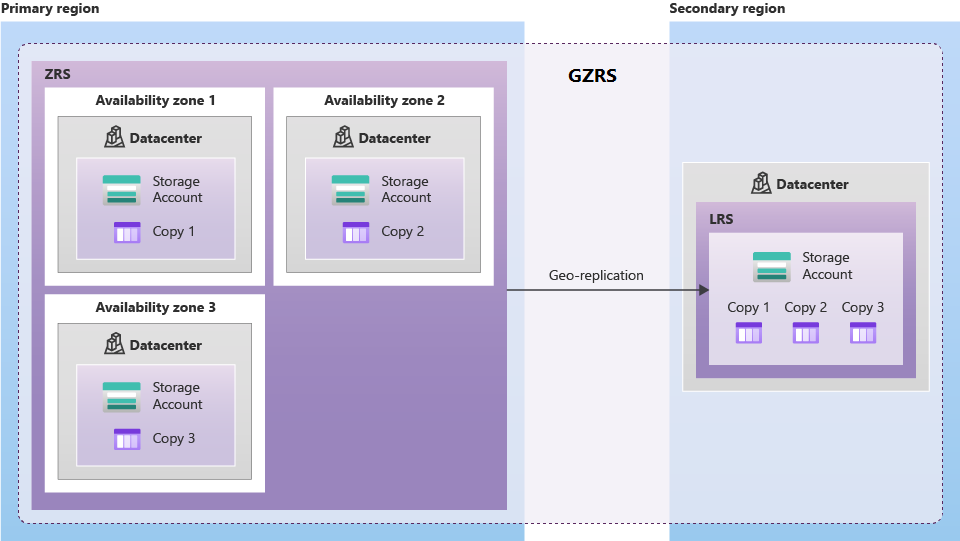
Penyimpanan geo-zona-redundan (GZRS) mereplikasi data di beberapa zona ketersediaan di wilayah utama dan ke wilayah yang dipasangkan.


- Penyimpanan geo-redundan akses baca (RA-GRS) dan penyimpanan geo-zona-redundan akses baca (RA-GZRS) memperluas penyimpanan geo-redundan (GRS) dan penyimpanan geo-zona-redundan (GZRS), dengan manfaat tambahan akses baca ke titik akhir sekunder. Opsi-opsi ini ideal untuk aplikasi yang dirancang untuk aplikasi bisnis kritis dengan ketersediaan tinggi. Dalam kemungkinan yang kecil bahwa titik akhir utama mengalami pemadaman, aplikasi yang dikonfigurasi untuk akses baca ke wilayah sekunder dapat terus beroperasi.
Jenis failover
Azure Storage mendukung tiga jenis failover untuk skenario yang berbeda.
Failover yang tidak direncanakan yang dikelola pelanggan: Anda bertanggung jawab untuk memulai pemulihan jika ada kegagalan penyimpanan di seluruh wilayah di wilayah utama Anda.
Failover terencana yang dikelola pelanggan: Anda bertanggung jawab untuk memulai pemulihan jika bagian lain dari solusi Anda mengalami kegagalan di wilayah utama Anda, dan Anda perlu mengalihkan seluruh solusi Anda ke wilayah sekunder. Gunakan failover yang direncanakan ketika penyimpanan tetap beroperasi di wilayah utama, tetapi Anda perlu mengalihkan seluruh solusi Anda ke wilayah sekunder, seperti untuk latihan pemulihan bencana yang dirancang untuk memastikan persyaratan kepatuhan dan audit.
Failover yang dikelola Microsoft: Dalam keadaan luar biasa, Microsoft mungkin memulai failover untuk semua akun penyimpanan geo-redundan (GRS) di suatu wilayah. Namun, failover yang dikelola Microsoft adalah upaya terakhir dan diharapkan hanya dilakukan setelah periode pemadaman yang diperpanjang. Anda tidak boleh mengandalkan failover yang dikelola Microsoft.
Akun GRS dapat menggunakan salah satu jenis failover ini. Anda tidak perlu mengonfigurasi akun penyimpanan terlebih dahulu untuk menggunakan salah satu jenis failover sebelumnya.
Persyaratan
Dukungan wilayah: Konfigurasi geo-redundan Azure Storage menggunakan wilayah berpasangan Azure untuk replikasi wilayah sekunder. Wilayah sekunder secara otomatis ditentukan berdasarkan pilihan wilayah utama Anda dan tidak dapat disesuaikan. Untuk daftar lengkap wilayah berpasangan Azure, lihat Daftar wilayah Azure.
Jika wilayah akun penyimpanan Anda tidak dipasangkan, pertimbangkan menggunakan solusi multi-wilayah kustom untuk ketahanan.
- Jenis akun penyimpanan: Penyimpanan yang geo-redundan (GRS) dan failover serta failback yang diprakarsai pelanggan tersedia di semua wilayah berpasangan Azure yang mendukung akun Azure Storage v2 yang bersifat tujuan umum.
Pertimbangan
Saat Anda menerapkan Blob Storage multi-wilayah, pertimbangkan faktor-faktor utama berikut:
Latensi replikasi asinkron: Replikasi data ke wilayah sekunder tidak sinkron, yang berarti bahwa ada jeda antara ketika data ditulis ke wilayah utama dan ketika tersedia di wilayah sekunder. Jeda ini dapat mengakibatkan potensi kehilangan data jika kegagalan wilayah utama terjadi sebelum data terbaru direplikasi. Kehilangan data diukur oleh tujuan titik pemulihan (RPO). Anda dapat mengharapkan jeda replikasi kurang dari 15 menit, tetapi kali ini adalah perkiraan dan tidak dijamin.
Anda dapat memeriksa properti Waktu Sinkronisasi Terakhir untuk memahami berapa banyak data yang mungkin hilang jika akun penyimpanan Anda memiliki failover yang tidak direncanakan.
Akses wilayah sekunder: Dengan konfigurasi penyimpanan geo-redundan (GRS) dan penyimpanan geo-zona-redundan (GZRS), wilayah sekunder tidak dapat diakses untuk pembacaan hingga failover terjadi.
Penyimpanan geo-redundan akses baca (RA-GRS) dan konfigurasi penyimpanan geo-zona-redundan akses baca (RA-GZRS) menyediakan akses baca ke wilayah sekunder selama operasi normal, tetapi karena latensi replikasi asinkron, mereka mungkin mengembalikan data yang sedikit kedaluarsa.
- Batasan fitur: Beberapa fitur Azure Storage tidak didukung atau memiliki batasan saat Anda menggunakan penyimpanan geo-redundan (GRS) atau failover yang dikelola pelanggan. Tinjau kompatibilitas fitur sebelum Anda menerapkan geo-redundansi.
Biaya
Konfigurasi akun Azure Storage multi-wilayah dikenakan biaya tambahan untuk replikasi dan penyimpanan lintas wilayah di wilayah sekunder. Transfer data antar wilayah Azure dikenakan biaya berdasarkan tarif bandwidth antarwilayah standar.
Untuk informasi selengkapnya, lihat Harga Blob Storage.
Mengonfigurasi dukungan multiregional
- Buat akun penyimpanan geo-redundan baru (GRS). Untuk membuat akun GRS, lihat Membuat akun penyimpanan dan memilih GRS, penyimpanan geo-redundan akses baca (RA-GRS), penyimpanan geo-zona-redundan (GZRS), atau penyimpanan geo-zona redundan akses baca (RA-GZRS) selama pembuatan akun.
Aktifkan geo-redundansi pada akun penyimpanan yang ada. Untuk mengonversi akun penyimpanan yang ada ke penyimpanan geo-redundan (GRS), lihat Mengubah cara akun penyimpanan direplikasi.
Peringatan
Setelah akun Anda dikonfigurasi ulang untuk geo-redundansi, mungkin perlu waktu yang signifikan sebelum data yang ada di wilayah utama baru sepenuhnya disalin ke wilayah sekunder baru.
Untuk menghindari kehilangan data utama, periksa nilai properti Waktu Sinkronisasi Terakhir sebelum Anda memulai failover yang tidak direncanakan. Untuk mengevaluasi potensi kehilangan data, bandingkan waktu sinkronisasi terakhir dengan terakhir kali data ditulis ke wilayah utama baru.
Nonaktifkan geo-redundansi. Konversi akun GRS kembali ke konfigurasi wilayah tunggal seperti penyimpanan redundan lokal (LRS) atau penyimpanan zona-redundan (ZRS) dengan menggunakan proses perubahan konfigurasi redundansi yang sama.
Perilaku ketika semua wilayah sehat
Bagian ini menjelaskan apa yang diharapkan ketika akun penyimpanan dikonfigurasi untuk geo-redundansi dan semua wilayah beroperasi.
Perutean lalu lintas antar wilayah: Azure Storage menggunakan pendekatan pasif aktif di mana semua operasi tulis dan sebagian besar operasi baca diarahkan ke wilayah utama.
Untuk penyimpanan geo-redundan akses baca (RA-GRS) dan konfigurasi penyimpanan geo-zona-redundan akses baca (RA-GZRS), aplikasi dapat secara opsional membaca dari wilayah sekunder dengan mengakses titik akhir sekunder. Pendekatan ini memerlukan konfigurasi aplikasi eksplisit dan tidak otomatis. Selain itu, karena jeda replikasi asinkron, data di wilayah sekunder mungkin sedikit ketinggalan jaman.
Replikasi data antar wilayah: Operasi tulis pertama kali diterapkan ke wilayah utama dengan menggunakan jenis redundansi yang dikonfigurasi berikut:
- Penyimpanan redundan lokal (LRS) untuk penyimpanan geo-redundan (GRS) dan RA-GRS
- Penyimpanan zona redundan (ZRS) untuk penyimpanan geo-zona-redundan (GZRS) dan RA-GZRS
Setelah berhasil diselesaikan di wilayah utama, data direplikasi secara asinkron ke wilayah sekunder tempat data disimpan dengan menggunakan LRS.
Sifat asinkron dari replikasi lintas wilayah berarti bahwa biasanya ada waktu jeda antara saat data ditulis ke wilayah utama dan kapan tersedia di wilayah sekunder. Anda dapat memantau waktu replikasi dengan menggunakan properti Waktu Sinkronisasi Terakhir.
Perilaku selama kegagalan wilayah
Bagian ini menjelaskan apa yang diharapkan ketika akun penyimpanan dikonfigurasi untuk geo-redundansi dan ada pemadaman di wilayah utama.
Failover yang dikelola pelanggan (tidak direncanakan): Gunakan failover yang tidak direncanakan saat penyimpanan di wilayah utama tidak tersedia.
Deteksi dan respons: Dalam kejadian yang tidak terduga di mana akun penyimpanan Anda tidak tersedia di wilayah utama Anda, Anda dapat mempertimbangkan untuk memulai failover yang dikelola pelanggan tanpa perencanaan. Untuk membuat keputusan ini, pertimbangkan faktor-faktor berikut:
Apakah Azure Resource Health menunjukkan masalah saat mengakses akun penyimpanan di wilayah utama Anda
Apakah Microsoft menyarankan Anda untuk melakukan failover ke wilayah lain
Peringatan
Failover yang tidak direncanakan dapat mengakibatkan hilangnya data. Sebelum Anda memulai failover yang dikelola pelanggan, putuskan apakah pemulihan layanan membenarkan risiko kehilangan data.
Pemberitahuan: Microsoft tidak secara otomatis memberi tahu Anda saat suatu wilayah tidak berfungsi. Namun:
Anda dapat menggunakan Azure Resource Health untuk memantau kesehatan sumber daya individual, dan Anda dapat menyiapkan pemberitahuan Resource Health untuk memberi tahu Anda tentang masalah.
Anda dapat menggunakan Azure Service Health untuk memahami kesehatan keseluruhan layanan, termasuk kegagalan wilayah apa pun, dan Anda dapat menyiapkan pemberitahuan Service Health untuk memberi tahu Anda tentang masalah.
Permintaan aktif: Selama proses failover, titik akhir akun penyimpanan primer dan sekunder menjadi tidak tersedia untuk baca dan tulis untuk sementara waktu. Setiap permintaan aktif mungkin dihilangkan, dan aplikasi klien perlu mencoba kembali setelah failover selesai.
Kehilangan data yang diharapkan: Kehilangan data umum terjadi selama failover yang tidak direncanakan karena lag replikasi asinkron, yang berarti bahwa penulisan terbaru mungkin tidak direplikasi. Anda dapat memeriksa properti Waktu Sinkronisasi Terakhir untuk memahami berapa banyak data yang mungkin hilang selama failover yang tidak direncanakan. Kehilangan data yang diharapkan sering disebut sebagai tujuan titik pemulihan (RPO). Anda umumnya dapat mengharapkan RPO kurang dari 15 menit, meskipun waktu tersebut tidak dapat dijamin.
Waktu henti yang diharapkan: Jumlah waktu henti yang diharapkan sering disebut sebagai tujuan waktu pemulihan (RTO). Failover yang dikelola pelanggan biasanya selesai dalam waktu 60 menit, tergantung pada ukuran dan kompleksitas akun.
Pengalihan lalu lintas: Saat failover selesai, Azure secara otomatis memperbarui titik akhir akun penyimpanan sehingga aplikasi tidak perlu dikonfigurasi ulang. Jika aplikasi Anda menyimpan entri Sistem Nama Domain (DNS) yang di-cache, mungkin perlu untuk menghapus cache untuk memastikan bahwa aplikasi mengirim lalu lintas ke wilayah utama baru.
Konfigurasi pasca-failover: Setelah failover yang tidak direncanakan selesai, akun penyimpanan Anda di wilayah tujuan menggunakan tingkat penyimpanan redundan lokal (LRS). Jika Anda perlu mereplikasinya secara geografis lagi, Anda perlu mengaktifkan kembali penyimpanan geo-redundan (GRS) dan menunggu data direplikasi ke wilayah sekunder baru.
Untuk informasi selengkapnya tentang cara memulai failover yang dikelola pelanggan, lihat Cara kerja failover yang dikelola pelanggan (tidak direncanakan) dan Memulai failover akun penyimpanan.
Failover yang dikelola pelanggan (direncanakan): Gunakan failover yang direncanakan ketika penyimpanan tetap beroperasi di wilayah utama, tetapi Anda perlu mengalihkan seluruh solusi Anda ke wilayah sekunder karena alasan lain. Misalnya, layanan Azure lain mungkin mengalami masalah dan Anda perlu beralih menggunakan wilayah sekunder untuk seluruh solusi Anda. Atau Anda dapat menggunakan failover yang direncanakan untuk melakukan latihan pemulihan bencana (DR) untuk tujuan kepatuhan dan audit.
Deteksi dan respons: Anda bertanggung jawab untuk memutuskan melakukan fail-over. Anda biasanya membuat keputusan ini jika Anda perlu melakukan failover antar wilayah, meskipun akun penyimpanan Anda sehat. Misalnya, Anda mungkin memicu failover ketika ada pemadaman besar komponen aplikasi lain yang tidak dapat Anda pulihkan di wilayah utama.
Pemberitahuan: Microsoft tidak secara otomatis memberi tahu Anda saat suatu wilayah tidak berfungsi. Namun:
Anda dapat menggunakan Azure Resource Health untuk memantau kesehatan sumber daya individual, dan Anda dapat menyiapkan pemberitahuan Resource Health untuk memberi tahu Anda tentang masalah.
Anda dapat menggunakan Azure Service Health untuk memahami kesehatan keseluruhan layanan, termasuk kegagalan wilayah apa pun, dan Anda dapat menyiapkan pemberitahuan Service Health untuk memberi tahu Anda tentang masalah.
Permintaan aktif: Selama proses failover, titik akhir akun penyimpanan primer dan sekunder menjadi tidak tersedia untuk baca dan tulis untuk sementara waktu. Setiap permintaan aktif mungkin dihilangkan, dan aplikasi klien perlu mencoba kembali setelah failover selesai.
Kehilangan data yang diharapkan: Tidak ada kehilangan data yang diharapkan karena proses failover selesai hanya setelah semua data disinkronkan, yang menghasilkan RPO nol.
Waktu henti yang diharapkan: Failover biasanya selesai dalam waktu 60 menit, yang berarti bahwa RTO yang diharapkan adalah 60 menit, tergantung pada ukuran dan kompleksitas akun. Selama proses failover, titik akhir akun penyimpanan primer dan sekunder menjadi tidak tersedia untuk baca dan tulis untuk sementara waktu.
Pengalihan lalu lintas: Saat failover selesai, Azure secara otomatis memperbarui titik akhir akun penyimpanan sehingga aplikasi tidak perlu dikonfigurasi ulang. Jika aplikasi Anda menyimpan entri DNS yang di-cache, mungkin perlu untuk menghapus cache untuk memastikan bahwa aplikasi mengirim lalu lintas ke wilayah utama baru.
Konfigurasi pasca-failover: Setelah failover yang direncanakan selesai, akun penyimpanan Anda di wilayah tujuan terus direplikasi secara geografis dan tetap berada di tingkat GRS.
Untuk informasi selengkapnya tentang cara memulai failover yang dikelola pelanggan, lihat Cara kerja failover yang dikelola pelanggan (terencana) dan Memulai failover akun penyimpanan.
Failover yang dikelola Microsoft: Jika terjadi bencana besar yang jarang terjadi di mana Microsoft menentukan bahwa wilayah utama tidak dapat dipulihkan secara permanen, failover otomatis ke wilayah sekunder mungkin dimulai. Microsoft menangani seluruh proses dan tidak ada tindakan pelanggan yang diperlukan. Jumlah waktu yang berlalu sebelum failover terjadi tergantung pada tingkat keparahan bencana dan waktu yang diperlukan untuk menilai situasi.
Pemberitahuan: Microsoft tidak secara otomatis memberi tahu Anda saat suatu wilayah tidak berfungsi. Namun:
Anda dapat menggunakan Azure Resource Health untuk memantau kesehatan sumber daya individual, dan Anda dapat menyiapkan pemberitahuan Resource Health untuk memberi tahu Anda tentang masalah.
Anda dapat menggunakan Azure Service Health untuk memahami kesehatan keseluruhan layanan, termasuk kegagalan wilayah apa pun, dan Anda dapat menyiapkan pemberitahuan Service Health untuk memberi tahu Anda tentang masalah.
Penting
Gunakan opsi failover yang dikelola pelanggan untuk mengembangkan, menguji, dan mengimplementasikan rencana DR Anda. Jangan mengandalkan failover yang dikelola Microsoft, yang mungkin hanya digunakan dalam keadaan ekstrem. Failover yang dikelola Microsoft kemungkinan dimulai untuk seluruh wilayah. Ini tidak dapat dimulai untuk akun penyimpanan individu, langganan, atau pelanggan. Failover mungkin terjadi pada waktu yang berbeda untuk layanan Azure yang berbeda. Kami menyarankan agar Anda menggunakan failover yang dikelola pelanggan.
Pemulihan wilayah
Proses failback berbeda secara signifikan antara skenario failover yang dikelola Microsoft dan dikelola pelanggan.
Failover yang dikelola pelanggan (tidak direncanakan): Setelah failover yang tidak direncanakan, akun penyimpanan dikonfigurasi dengan penyimpanan redundan lokal (LRS). Untuk melakukan failback, Anda perlu membuat ulang hubungan penyimpanan geo-redundan (GRS) dan menunggu data direplikasi.
Failover yang dikelola pelanggan (direncanakan): Setelah failover yang direncanakan, akun penyimpanan tetap direplikasi secara geografis. Anda dapat memulai failover lain yang dikelola pelanggan untuk melakukan failback ke wilayah utama asli. Pertimbangan failover yang sama berlaku.
Failover yang dikelola Microsoft: Jika Microsoft memulai failover, kemungkinan bencana signifikan terjadi di wilayah utama, dan wilayah utama mungkin tidak dapat dipulihkan. Setiap garis waktu atau rencana pemulihan tergantung pada sejauh mana upaya bencana dan pemulihan regional. Anda harus memantau komunikasi Azure Service Health untuk detailnya.
Pengujian untuk mendeteksi kegagalan wilayah
Anda dapat mensimulasikan kegagalan regional untuk menguji prosedur pemulihan bencana Anda.
Pengujian failover yang direncanakan: Untuk akun penyimpanan geo-redundan (GRS), Anda dapat melakukan operasi failover yang direncanakan selama jendela pemeliharaan untuk menguji proses failover dan failback lengkap. Failover yang direncanakan tidak memerlukan kehilangan data, tetapi melibatkan waktu henti selama failover dan failback.
Pengujian titik akhir sekunder: Untuk penyimpanan geo-redundan akses baca (RA-GRS) dan konfigurasi penyimpanan geo-zona-redundan akses baca (RA-GZRS), uji operasi baca secara teratur terhadap titik akhir sekunder untuk memastikan bahwa aplikasi Anda dapat berhasil membaca data dari wilayah sekunder.
Solusi multi-wilayah kustom untuk ketahanan
Kemampuan failover lintas wilayah Azure Storage mungkin tidak cocok karena alasan berikut:
Akun penyimpanan Anda berada di wilayah yang tidak berpasangan.
Tujuan waktu aktif bisnis Anda tidak terpenuhi oleh waktu pemulihan atau kehilangan data yang disediakan opsi failover bawaan.
Anda perlu melakukan failover ke wilayah yang bukan pasangan wilayah utama Anda.
Anda memerlukan konfigurasi aktif/aktif di seluruh wilayah.
Bagian ini memberikan gambaran umum tingkat tinggi tentang beberapa pendekatan yang perlu dipertimbangkan. Gambaran umum komprehensif topologi penyebaran multi-wilayah untuk Azure Storage berada di luar cakupan artikel ini.
Anda dapat menyebarkan Azure Storage di beberapa wilayah dengan menggunakan akun penyimpanan terpisah di setiap wilayah. Pendekatan ini memberikan fleksibilitas dalam pemilihan wilayah, kemampuan untuk menggunakan wilayah yang tidak berpasangan, dan kontrol yang lebih terperinci atas waktu replikasi dan konsistensi data. Saat menerapkan beberapa akun penyimpanan di seluruh wilayah, Anda perlu mengonfigurasi replikasi data lintas wilayah, menerapkan kebijakan penyeimbangan beban dan failover, dan memastikan konsistensi data di seluruh wilayah.
Replikasi objek menyediakan opsi tambahan untuk replikasi data lintas wilayah yang menyediakan penyalinan asinkron blob blok antar akun penyimpanan. Tidak seperti opsi penyimpanan geo-redundan bawaan yang menggunakan wilayah berpasangan tetap, replikasi objek memungkinkan Anda mereplikasi data antara akun penyimpanan di wilayah Azure mana pun, termasuk wilayah yang tidak berpasangan. Pendekatan ini memberi Anda kontrol penuh atas wilayah sumber dan tujuan, kebijakan replikasi, dan awalan kontainer dan blob tertentu untuk direplikasi.
Anda dapat mengonfigurasi replikasi objek untuk mereplikasi semua blob dalam kontainer atau subset tertentu berdasarkan awalan dan tag blob. Replikasi asinkron dan terjadi di latar belakang. Anda dapat mengonfigurasi beberapa kebijakan replikasi dan bahkan replikasi rantai di beberapa akun penyimpanan untuk membuat topologi multi-wilayah yang canggih.
Replikasi objek tidak kompatibel dengan semua akun penyimpanan. Misalnya, ini tidak berfungsi dengan akun penyimpanan yang menggunakan namespace hierarkis (juga dikenal sebagai akun Azure Data Lake Storage Gen2).
Untuk informasi selengkapnya, lihat Replikasi objek untuk blob blok dan Mengonfigurasi replikasi objek.
Pencadangan dan pemulihan
Blob Storage menyediakan beberapa mekanisme perlindungan data yang melengkapi redundansi untuk strategi pencadangan yang komprehensif. Redundansi bawaan layanan melindungi dari kegagalan infrastruktur, dan kemampuan pencadangan tambahan melindungi dari penghapusan, kerusakan, dan aktivitas berbahaya yang tidak disengaja.
Pemulihan titik waktu (PITR) memungkinkan Anda memulihkan data blob blok ke status sebelumnya dalam periode retensi yang dikonfigurasi hingga 365 hari. Microsoft sepenuhnya mengelola fitur ini. Ini juga menyediakan kemampuan pemulihan terperinci di tingkat kontainer atau blob. Data PITR disimpan di wilayah yang sama dengan akun sumber dan dapat diakses bahkan selama pemadaman regional jika Anda menggunakan konfigurasi geo-redundan.
Penerapan versi blob secara otomatis mempertahankan versi blob sebelumnya saat dimodifikasi atau dihapus. Setiap versi disimpan sebagai objek terpisah dan dapat diakses secara independen. Versi disimpan di wilayah yang sama dengan blob saat ini dan mengikuti konfigurasi redundansi yang sama dengan akun penyimpanan.
Penghapusan sementara menyediakan jaring pengaman untuk blob dan kontainer yang dihapus secara tidak sengaja dengan menyimpan data yang dihapus untuk periode yang dapat dikonfigurasi. Data yang dihapus sementara tetap berada di akun dan wilayah penyimpanan yang sama, yang membuatnya segera tersedia untuk pemulihan. Untuk akun geo-redundan, data yang dihapus sementara juga direplikasi ke wilayah sekunder.
Rekam jepret blob membuat salinan blob baca-saja dan point-in-time yang dapat Anda gunakan untuk skenario pencadangan dan pemulihan. Rekam jepret disimpan di akun penyimpanan yang sama dan mengikuti pengaturan redundansi dan replikasi geografis yang sama dengan blob dasar.
Untuk persyaratan pencadangan lintas wilayah, pertimbangkan untuk menggunakan Azure Backup untuk blob, yang menyediakan manajemen cadangan terpusat dan dapat menyimpan data cadangan di wilayah yang berbeda dari data sumber. Layanan ini menyediakan opsi pencadangan operasional dan vault yang memiliki kebijakan retensi dan kemampuan pemulihan yang dapat dikonfigurasi. Untuk informasi selengkapnya, lihat Gambaran umum Pencadangan untuk blob.
Untuk sebagian besar solusi, Anda tidak boleh mengandalkan cadangan secara eksklusif. Sebagai gantinya, gunakan kemampuan lain yang dijelaskan dalam panduan ini untuk mendukung persyaratan ketahanan Anda. Namun, pencadangan melindungi dari beberapa risiko yang tidak dapat dicegah oleh pendekatan lain. Untuk informasi selengkapnya, lihat Apa itu redundansi, replikasi, dan cadangan?.
Perjanjian tingkat layanan
Perjanjian tingkat layanan (SLA) untuk Azure Storage menjelaskan ketersediaan layanan yang diharapkan dan kondisi yang harus dipenuhi untuk mencapai harapan ketersediaan tersebut. SLA ketersediaan yang memenuhi syarat untuk Anda bergantung pada tingkat penyimpanan dan jenis replikasi yang Anda gunakan. Untuk informasi selengkapnya, lihat SLA untuk Layanan Online.