Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pola pemulihan bencana yang jelas sangat penting untuk platform analitik data cloud asli seperti Azure Databricks. Sangat penting bahwa tim data Anda dapat menggunakan platform Azure Databricks bahkan dalam kasus langka pemadaman penyedia layanan cloud di seluruh layanan regional, baik yang disebabkan oleh bencana regional seperti badai atau gempa bumi, atau sumber lain.
Azure Databricks sering menjadi bagian inti dari ekosistem data keseluruhan yang mencakup banyak layanan, termasuk layanan penyerapan data hulu (batch/streaming), penyimpanan asli cloud seperti ADLS (untuk ruang kerja yang dibuat sebelum 6 Maret 2023, Azure Blob Storage), alat dan layanan hilir seperti aplikasi inteligensi bisnis, dan alat orkestrasi. Beberapa kasus penggunaan Anda mungkin sangat sensitif terhadap gangguan layanan regional secara keseluruhan.
Artikel ini menjelaskan konsep dan praktik terbaik untuk solusi pemulihan bencana antarregional yang sukses untuk platform Databricks.
Jaminan ketersediaan tinggi di dalam wilayah
Meskipun topik lainnya berfokus pada implementasi pemulihan bencana lintas wilayah, penting untuk memahami jaminan ketersediaan tinggi yang disediakan Azure Databricks di dalam satu wilayah. Jaminan ketersediaan tinggi di dalam wilayah mencakup komponen berikut:
Ketersediaan pesawat kendali Databricks
Sarana kontrol Databricks tahan terhadap kegagalan zona dan harus secara otomatis pulih dalam ~15 menit setelah kegagalan zona. Pengujian kegagalan zona rutin memvalidasi ini.
Semua layanan lapisan kontrol stateless dapat mengatasi hilangnya VM individu serta semua VM di seluruh zona secara otomatis. Data ruang kerja disimpan dalam database yang direplikasi di seluruh zona di wilayah tersebut. Akun penyimpanan yang digunakan untuk menyediakan gambar Databricks Runtime juga memiliki redundansi di dalam wilayah tersebut, dan semua wilayah memiliki akun penyimpanan sekunder yang digunakan saat akun primer tidak berfungsi. Beberapa wilayah memanfaatkan control plane yang diimplementasikan dalam wilayah berpasangan. Lihat Wilayah Azure Databricks untuk informasi selengkapnya.
Ketahanan kegagalan zona hanya mendukung paling banyak satu zona yang tidak berfungsi, dan hanya tersedia di wilayah Azure yang mendukung beberapa zona.
Penting
Databricks HA menyediakan waktu aktif intra-wilayah dengan redundansi zona ketersediaan (AZ). Jika satu zona mengalami pemadaman, layanan terus berjalan di wilayah tersebut.
DR menggunakan replikasi antar-wilayah dan memungkinkan Anda melakukan failover ke wilayah lain. Anda mengonfigurasi ruang kerja Databricks sekunder di wilayah lain dan mereplikasi data dan konfigurasi untuk mengaktifkan pemulihan.
Jika Anda tidak memerlukan DR multi-wilayah, Databricks HA mungkin cukup dan menghindari kompleksitas lintas wilayah. Namun, itu tidak melindungi dari pemadaman wilayah penuh karena data tetap berada di wilayah asli.
Jika Anda mengandalkan Databricks HA untuk DR, verifikasi pemisahan dan redundansi wilayah cloud Anda.
Untuk mengonfirmasi dukungan multi-AZ, lihat daftar wilayah Azure. Untuk ketahanan multi-AZ lapisan komputasi, gunakan Penyimpanan Redundan Zona.
Ketersediaan lapisan komputasi
Ketersediaan ruang kerja tergantung pada ketersediaan sarana kontrol (seperti yang dijelaskan di atas). Data di DBFS Root tidak terpengaruh jika akun penyimpanan untuk DBFS Root dikonfigurasi dengan penyimpanan Zona redundan (ZRS) atau penyimpanan geo-zona-redundan (GZRS) (defaultnya adalah penyimpanan Geo-redundan (GRS)).
Node untuk kluster ditarik dari zona ketersediaan yang berbeda dengan meminta sumber daya dari penyedia komputasi Azure (dengan asumsi bahwa zona yang tersisa memiliki kapasitas cukup untuk memenuhi permintaan). Jika node hilang, manajer kluster meminta node penggantian dari penyedia komputasi Azure, yang menariknya dari AZ yang tersedia. Satu-satunya pengecualian adalah ketika simpul driver hilang. Dalam hal ini, manajer kluster memulai ulang pekerjaan dan kluster.
Gambaran umum pemulihan bencana
Pemulihan bencana melibatkan serangkaian kebijakan, alat, dan prosedur yang memungkinkan pemulihan atau kelanjutan infrastruktur dan sistem teknologi vital setelah bencana alam atau yang disebabkan oleh manusia. Layanan cloud besar seperti Azure melayani banyak pelanggan dan memiliki pelindung bawaan terhadap satu kegagalan. Misalnya, suatu wilayah adalah sekelompok bangunan yang tersambung ke sumber daya yang berbeda untuk menjamin bahwa kehilangan daya tunggal tidak akan menonaktifkan suatu wilayah. Namun, kegagalan wilayah cloud dapat terjadi, dan tingkat gangguan serta dampaknya terhadap organisasi Anda dapat beragam.
Sebelum menerapkan rencana pemulihan bencana, penting untuk memahami perbedaan antara pemulihan bencana (DR) dan ketersediaan tinggi (HA).
High availability adalah karakteristik keandalan dari suatu sistem. Ketersediaan Tinggi memastikan performa operasional minimum yang biasanya didefinisikan dalam hal waktu aktif yang konsisten atau persentasenya. Ketersediaan tinggi diterapkan pada tempatnya (di wilayah yang sama dengan sistem primer Anda) dengan merancangnya sebagai fitur dari sistem primer. Misalnya, layanan cloud seperti Azure memiliki layanan ketersediaan tinggi seperti ADLS (untuk ruang kerja yang dibuat sebelum 6 Maret 2023, Azure Blob Storage). Tingkat ketersediaan tinggi tidak memerlukan persiapan khusus yang signifikan dari pelanggan Azure Databricks.
Sebaliknya, rencana pemulihan bencana membutuhkan keputusan dan solusi yang bekerja untuk organisasi tertentu untuk menangani penghentian regional yang lebih besar untuk sistem penting. Artikel ini membahas terminologi pemulihan bencana umum, solusi umum, dan beberapa praktik terbaik untuk rencana pemulihan bencana dengan Azure Databricks.
Terminologi
Terminologi wilayah
Artikel ini menggunakan definisi berikut untuk wilayah:
Wilayah primer: Wilayah geografis tempat pengguna menjalankan beban kerja analitik data interaktif dan otomatis harian tipikal.
Wilayah sekunder: Wilayah geografis tempat tim TI memindahkan beban kerja analitik data sementara selama penghentian di wilayah primer.
Penyimpanan geo-redundan: Azure memiliki penyimpanan geo-redundan di seluruh wilayah untuk penyimpanan yang dipertahankan menggunakan proses replikasi penyimpanan asinkron.
Penting
Untuk proses pemulihan bencana, Databricks menyarankan agar Anda melakukan tidak mengandalkan penyimpanan geo-redundan untuk duplikasi data lintas wilayah seperti ADLS Anda (untuk ruang kerja yang dibuat sebelum 6 Maret 2023, Azure Blob Storage) yang dibuat Azure Databricks untuk setiap ruang kerja di langganan Azure Anda. Secara umum, gunakan Deep Clone untuk Tabel Delta dan konversikan data ke format Delta untuk menggunakan Deep Clone jika memungkinkan untuk format data lainnya.
Terminologi status penyebaran
Artikel ini menggunakan definisi status penyebaran berikut:
Penyebaran aktif: Pengguna dapat terhubung ke penyebaran aktif ruang kerja Azure Databricks dan menjalankan beban kerja. Pekerjaan dijadwalkan secara berkala menggunakan penjadwal Azure Databricks atau mekanisme lainnya. Aliran data juga dapat dijalankan pada penyebaran ini. Beberapa dokumen mungkin menyebut penyebaran aktif sebagai penyebaran panas.
Penyebaran pasif: Proses tidak berjalan pada penyebaran pasif. Tim TI dapat menyiapkan prosedur otomatis untuk menyebarkan kode, konfigurasi, dan objek Azure Databricks lainnya ke penyebaran pasif. Penyebaran akan menjadi aktif hanya jika penyebaran aktif saat ini sedang tidak berjalan. Beberapa dokumen mungkin menyebut penyebaran pasif sebagai penyebaran dingin.
Penting
Suatu proyek secara opsional dapat menyertakan beberapa penyebaran pasif di berbagai wilayah guna memberikan opsi tambahan untuk menyelesaikan penghentian regional.
Biasanya, tim hanya memiliki satu penyebaran aktif pada satu waktu, dalam strategi yang disebut pemulihan bencana aktif-pasif. Ada strategi solusi pemulihan bencana yang kurang umum yang disebut aktif-aktif, yaitu ada dua penyebaran aktif simultan.
Terminologi industri pemulihan bencana
Ada dua istilah industri penting yang harus Anda pahami dan definisikan untuk tim Anda:
Tujuan titik pemulihan: Tujuan titik pemulihan (RPO) adalah periode target maksimum untuk data (transaksi) dapat hilang dari layanan TI karena insiden parah. Penyebaran Azure Databricks Anda tidak menyimpan data pelanggan utama. Itu disimpan dalam sistem terpisah seperti ADLS (untuk ruang kerja yang dibuat sebelum 6 Maret 2023, Azure Blob Storage) atau sumber data lainnya di bawah kontrol Anda. Sarana kontrol Azure Databricks menyimpan beberapa objek sebagian atau seluruhnya, seperti pekerjaan dan buku catatan. Untuk Azure Databricks, RPO didefinisikan sebagai periode maksimum yang ditargetkan di mana objek, seperti pekerjaan dan perubahan buku catatan, dapat hilang. Selain itu, Anda bertanggung jawab untuk mendefinisikan RPO untuk data pelanggan Anda sendiri di ADLS (untuk ruang kerja yang dibuat sebelum 6 Maret 2023, Azure Blob Storage) atau sumber data lainnya di bawah kendali Anda.
Tujuan waktu pemulihan: Tujuan waktu pemulihan (RTO) adalah durasi waktu yang ditargetkan dan tingkat layanan untuk proses bisnis harus dipulihkan setelah bencana.
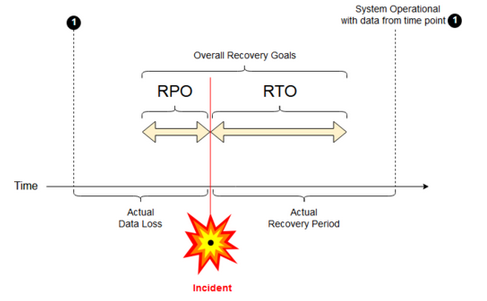
Pemulihan bencana dan kerusakan data
Solusi pemulihan bencana tidak mengurangi kerusakan data. Data yang rusak di wilayah primer direplikasi ke wilayah sekunder dan menjadi rusak di kedua wilayah. Ada cara lain untuk mengurangi kegagalan semacam ini, misalnya Perjalanan Waktu Delta.
Alur kerja pemulihan tipikal
Skenario pemulihan bencana Azure Databricks biasanya dimainkan dengan cara berikut:
Kegagalan terjadi dalam layanan penting yang Anda gunakan di wilayah primer. Kegagalan ini dapat berupa layanan sumber data atau jaringan yang memengaruhi penyebaran Azure Databricks.
Anda menyelidiki situasi dengan penyedia cloud.
Jika Anda menyimpulkan bahwa perusahaan Anda tidak dapat menunggu masalah untuk diperbaiki di wilayah utama, Anda mungkin memutuskan untuk melakukan failover ke wilayah sekunder.
Pastikan bahwa masalah yang sama tidak memengaruhi wilayah sekunder juga.
Melakukan failover ke wilayah sekunder.
- Hentikan semua aktivitas di ruang kerja. Pengguna menghentikan beban kerja. Pengguna atau administrator diinstruksikan untuk membuat file cadangan perubahan terbaru jika memungkinkan. Pekerjaan dihentikan jika belum mengalami kegagalan akibat pemadaman.
- Mulai prosedur pemulihan di wilayah sekunder. Prosedur pemulihan memperbarui perutean dan mengganti nama koneksi serta trafik jaringan ke wilayah sekunder.
- Setelah pengujian, nyatakan bahwa wilayah sekunder sudah operasional. Beban kerja produksi sekarang dapat dilanjutkan. Pengguna dapat masuk ke dalam penyebaran yang saat ini aktif. Anda dapat memulai ulang pekerjaan yang dijadwalkan atau tertunda.
Untuk langkah-langkah terperinci dalam konteks Azure Databricks, lihat Uji failover.
Pada titik tertentu, masalah di wilayah utama dimitigasi, dan Anda mengonfirmasi fakta ini.
Pulihkan (failback) ke wilayah primer Anda.
- Hentikan semua pekerjaan di wilayah sekunder.
- Mulai prosedur pemulihan di wilayah primer. Prosedur pemulihan menangani perutean dan penggantian nama koneksi serta lalu lintas jaringan kembali ke wilayah primer.
- Replikasi data kembali ke wilayah primer sesuai kebutuhan. Untuk mengurangi kompleksitas, mungkin juga meminimalkan jumlah data yang perlu direplikasi. Misalnya, jika beberapa pekerjaan bersifat baca-saja saat dijalankan dalam penyebaran sekunder, Anda mungkin tidak perlu mereplikasi data tersebut kembali ke penyebaran primer di wilayah primer. Namun, Anda dapat memiliki satu pekerjaan produksi yang perlu dijalankan dan mungkin memerlukan replikasi data kembali ke wilayah utama.
- Uji penyebaran di wilayah utama.
- Nyatakan bahwa wilayah primer Anda operasional dan merupakan tempat penyebaran aktif Anda. Lanjutkan beban kerja produksi.
Untuk informasi selengkapnya tentang pemulihan ke wilayah primer, lihat Pemulihan pengujian (failback).
Penting
Selama langkah-langkah ini, beberapa kehilangan data dapat terjadi. Organisasi Anda harus menentukan berapa banyak kehilangan data yang dapat diterima dan apa yang dapat Anda lakukan untuk mengurangi kehilangan ini.
Langkah 1: Memahami kebutuhan bisnis Anda
Langkah pertama adalah menentukan dan memahami kebutuhan bisnis Anda. Tentukan layanan data mana yang penting dan apa RPO dan RTO yang diharapkan.
Teliti toleransi dunia nyata dari setiap sistem. Ingatlah bahwa pemulihan bencana, failover, dan failback dapat mahal dan membawa risiko lain. Risiko lain mungkin termasuk kerusakan data, duplikasi data (jika Anda menulis ke lokasi penyimpanan yang salah), dan pengguna yang masuk dan membuat perubahan di tempat yang salah.
Memetakan semua titik integrasi Azure Databricks yang memengaruhi bisnis:
- Apakah solusi pemulihan bencana perlu mengakomodasi proses interaktif, proses otomatis, atau keduanya?
- Layanan data apa yang Anda gunakan? Beberapa mungkin di lokasi.
- Bagaimana data input sampai ke cloud?
- Siapa yang menggunakan data ini? Proses apa yang menggunakannya di hilir?
- Apakah ada integrasi pihak ketiga yang harus diberitahu tentang perubahan pada pemulihan bencana?
Menentukan alat atau strategi komunikasi yang dapat mendukung rencana pemulihan bencana:
- Alat apa yang akan Anda gunakan untuk mengubah konfigurasi jaringan dengan cepat?
- Dapatkah Anda menjelaskan konfigurasi Anda dan membuatnya modular untuk mengakomodasi solusi pemulihan bencana dengan cara yang alami dan dapat dipertahankan?
- Alat dan saluran komunikasi mana yang akan memberi tahu tim internal dan pihak ketiga (integrasi, konsumen hilir) tentang kegagalan pemulihan bencana dan perubahan failback? Bagaimana Anda akan mengonfirmasi pengakuan mereka?
- Alat atau dukungan khusus apa yang akan diperlukan?
- Layanan apa, jika ada, akan dimatikan hingga pemulihan sepenuhnya terwujud?
Langkah 2: Memilih proses yang memenuhi kebutuhan bisnis
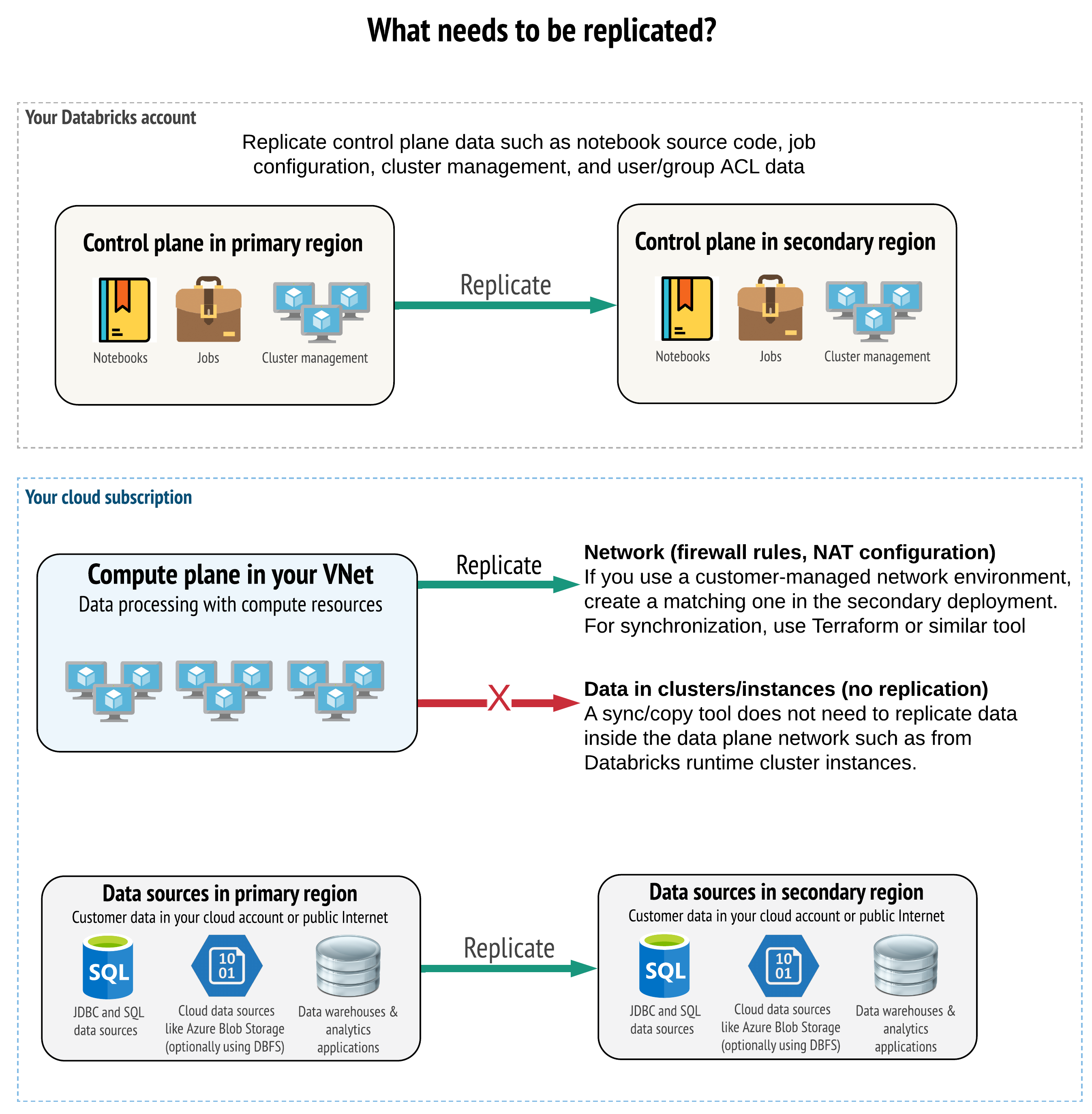
Solusi Anda harus mereplikasi data yang benar di sarana kontrol, sarana komputasi, dan sumber data. Ruang kerja redundan untuk pemulihan bencana harus dipetakan ke bidang kontrol yang berbeda di berbagai wilayah. Anda harus memastikan data tersebut tetap sinkron secara berkala menggunakan solusi berbasis skrip, baik alat sinkronisasi atau alur kerja CI/CD. Tidak perlu menyinkronkan data dari dalam jaringan rangkaian komputasi itu sendiri, seperti dari pekerja di Databricks Runtime.
Jika menggunakan fitur injeksi VNet (tidak tersedia pada semua jenis langganan dan penyebaran), Anda dapat menyebarkan jaringan tersebut secara konsisten di kedua wilayah menggunakan alat berbasis templat seperti Terraform.
Selain itu, Anda perlu memastikan bahwa sumber data direplikasi sesuai kebutuhan di seluruh wilayah.
Praktik terbaik umum
Praktik terbaik umum untuk keberhasilan rencana pemulihan bencana meliputi:
Pahami proses mana yang penting bagi bisnis dan harus berjalan dalam pemulihan bencana.
Identifikasi dengan jelas layanan mana yang terlibat, data mana yang sedang diproses, apa aliran datanya, dan di mana data disimpan.
Isolasi layanan dan data sebanyak mungkin. Misalnya, buat kontainer penyimpanan cloud khusus untuk data pemulihan bencana atau pindahkan objek Azure Databricks yang diperlukan selama bencana ke ruang kerja terpisah.
Anda bertanggung jawab untuk menjaga integritas antara penyebaran primer dan sekunder terhadap objek lain yang tidak disimpan di Sarana Kontrol Databricks.
Peringatan
Praktik terbaiknya adalah Anda tidak menyimpan data di ADLS akar (untuk ruang kerja yang dibuat sebelum 6 Maret 2023, Azure Blob Storage) yang digunakan untuk akses root DBFS untuk ruang kerja. Penyimpanan root DBFS tidak didukung untuk data pelanggan produksi. Databricks juga menyarankan agar Anda tidak menyimpan pustaka, file konfigurasi, atau skrip init di lokasi ini.
Untuk sumber data, jika memungkinkan, sebaiknya Anda menggunakan alat Azure asli terhadap replikasi dan redundansi untuk mereplikasi data ke wilayah pemulihan bencana.
Pilih strategi solusi pemulihan
Solusi pemulihan bencana biasanya melibatkan dua (atau mungkin lebih) ruang kerja. Anda dapat memilih dari beberapa strategi. Pertimbangkan potensi lamanya gangguan (beberapa jam atau bahkan mungkin sehari), upaya untuk memastikan bahwa ruang kerja beroperasi penuh, dan upaya untuk mengembalikan (failback) ke wilayah primer.
Strategi solusi aktif-pasif
Solusi aktif-pasif adalah solusi yang paling umum dan termudah, dan jenis solusi ini adalah fokus artikel ini. Solusi aktif-pasif menyinkronkan perubahan data dan objek dari penyebaran aktif ke penyebaran pasif. Jika mau, Anda dapat menjalankan beberapa penyebaran pasif di berbagai wilayah, tetapi artikel ini berfokus pada pendekatan penyebaran pasif tunggal. Selama peristiwa pemulihan bencana, penyebaran pasif di wilayah sekunder menjadi penyebaran aktif Anda.
Ada dua varian utama untuk strategi ini:
- Solusi terpadu (dari segi perusahaan): Serangkaian penyebaran aktif dan pasif yang mendukung seluruh organisasi.
- Solusi berdasarkan departemen atau proyek: Setiap departemen atau domain proyek mempertahankan solusi pemulihan bencana terpisah. Beberapa organisasi ingin memisahkan detail pemulihan bencana di antara departemen serta menggunakan wilayah primer dan sekunder yang berbeda untuk setiap tim berdasarkan kebutuhan unik masing-masing tim.
Ada varian lain, seperti menggunakan pengimplementasian pasif untuk kasus penggunaan yang hanya membaca. Jika Anda memiliki beban kerja yang bersifat baca-saja, misalnya, kueri pengguna, mereka dapat berjalan pada solusi pasif kapan saja jika mereka tidak memodifikasi data atau objek Azure Databricks seperti buku catatan atau pekerjaan.
Strategi solusi aktif-aktif
Dalam solusi aktif-aktif, Anda menjalankan semua proses data di kedua wilayah setiap saat secara paralel. Tim operasi Anda harus memastikan bahwa proses data atau tugas ditandai sebagai selesai hanya jika sukses diselesaikan di kedua wilayah. Objek tidak dapat diubah selama produksi dan harus mengikuti promosi CI/CD yang ketat sejak pengembangan/penahapan hingga produksi.
Solusi aktif-aktif adalah strategi yang paling kompleks, dan karena pekerjaan dilakukan di kedua wilayah, ada biaya keuangan tambahan.
Sama seperti strategi aktif-pasif, Anda dapat menerapkan solusi ini sebagai solusi organisasi terpadu atau berdasarkan departemen.
Anda mungkin tidak memerlukan ruang kerja yang setara di sistem sekunder untuk semua ruang kerja, tergantung pada alur kerja Anda. Misalnya, ruang kerja pengembangan atau penahapan mungkin tidak memerlukan duplikasi. Dengan alur pengembangan yang dirancang dengan baik, Anda mungkin dapat merekonstruksi ruang kerja tersebut dengan mudah jika diperlukan.
Memilih alat
Ada dua pendekatan utama terhadap alat untuk menjaga data semirip mungkin antara ruang kerja di wilayah primer dan sekunder:
- Klien sinkronisasi yang menyalin dari primer ke sekunder: Klien sinkronisasi mengirim data produksi dan aset dari wilayah primer ke wilayah sekunder. Biasanya, ini berjalan secara terjadwal.
- Alat CI/CD untuk penyebaran paralel: Untuk kode produksi dan aset, gunakan alat CI/CD yang mendorong perubahan pada sistem produksi secara simultan ke kedua wilayah. Misalnya, saat mengirim kode dan aset dari staging/pengembangan ke produksi, sistem CI/CD menyediakannya di kedua wilayah secara bersamaan. Ide intinya adalah memperlakukan semua artefak di ruang kerja Azure Databricks sebagai infrastruktur sebagai kode. Sebagian besar artefak dapat disebarkan bersama ke ruang kerja primer dan sekunder, sementara beberapa artefak mungkin perlu disebarkan hanya setelah peristiwa pemulihan bencana. Untuk alat, lihat Skrip, sampel, dan prototipe automasi.
Diagram berikut membedakan kedua pendekatan tersebut.
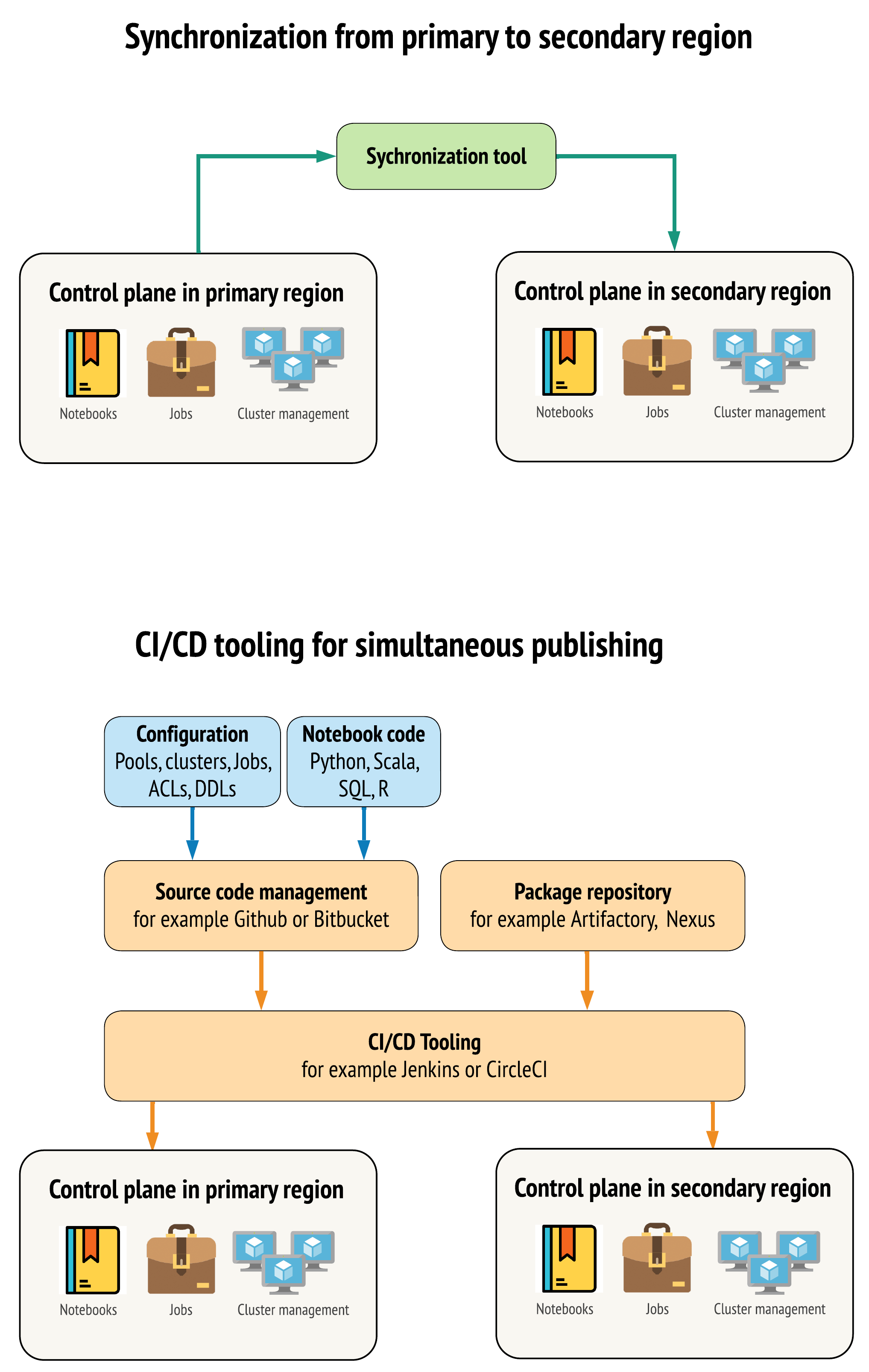
Tergantung pada kebutuhan, Anda dapat menggabungkan kedua pendekatan tersebut. Misalnya, gunakan CI/CD untuk kode sumber notebook, tetapi gunakan sinkronisasi untuk konfigurasi seperti kumpulan dan kontrol akses.
Tabel berikut menjelaskan cara menangani berbagai jenis data dengan setiap opsi alat.
| Deskripsi | Cara menangani alat CI/CD | Cara menangani dengan alat sinkronisasi |
|---|---|---|
| Kode sumber: ekspor sumber notebook dan kode sumber untuk pustaka yang dikemas | Terapkan keduanya ke primer dan sekunder secara bersamaan. | Sinkronkan kode sumber dari primer ke sekunder. |
| Pengguna dan grup | Kelola metadata sebagai konfigurasi di Git. Sebagai alternatif, gunakan penyedia identitas yang sama untuk kedua ruang kerja. Sebarkan data grup dan pengguna secara bersamaan pada penyebaran primer dan sekunder. | Gunakan SCIM atau automasi lainnya untuk kedua wilayah. Pembuatan manual tidak disarankan, tetapi jika digunakan, harus dilakukan terhadap keduanya secara bersamaan. Jika Anda menggunakan penyiapan manual, buat proses otomatis terjadwal untuk membandingkan daftar pengguna dan grup antara dua penyebaran. |
| Konfigurasi kumpulan | Dapat berupa templat di Git. Sebarkan secara bersamaan ke primer dan sekunder. Namun, min_idle_instances pada bagian sekunder harus nol sampai terjadinya peristiwa pemulihan bencana. |
Kumpulan yang dibuat dengan min_idle_instances ketika mereka disinkronkan ke ruang kerja sekunder menggunakan API atau CLI. |
| Konfigurasi pekerjaan | Dapat berupa templat di Git. Untuk penyebaran primer, sebarkan definisi kerja sebagaimana adanya. Untuk penyebaran sekunder, sebarkan tugas dan tetapkan konkurensi ke nol. Tindakan ini akan menonaktifkan tugas di penyebaran ini dan membatasi eksekusi tambahan. Ubah nilai konkurensi setelah penyebaran sekunder menjadi aktif. | Jika pekerjaan berjalan pada kluster <interactive> yang ada karena suatu alasan, maka klien sinkronisasi perlu memetakan ke cluster_id yang sesuai di ruang kerja sekunder. |
| Daftar kontrol akses (ACL) | Dapat berupa templat di Git. Lakukan penerapan bersama ke penyebaran primer dan sekunder untuk notebook, folder, dan kluster. Namun, simpan data pekerjaan hingga peristiwa pemulihan bencana. | API Permissions dapat mengatur kontrol akses untuk kluster, tugas, kumpulan, notebook, dan folder. Klien sinkronisasi perlu memetakan setiap objek di ruang kerja sekunder ke ID objek yang sesuai. Databricks merekomendasikan untuk membuat peta ID objek dari ruang kerja primer ke sekunder seraya menyinkronkan objek tersebut sebelum mereplikasi kontrol akses. |
| Pustaka | Sertakan dalam kode sumber dan templat kluster/pekerjaan. | Sinkronkan pustaka kustom dari repositori terpusat, DBFS, atau penyimpanan cloud (dapat dipasang). |
| Skrip inisialisasi cluster | Sertakan dalam kode sumber jika Anda mau. | Untuk sinkronisasi yang lebih sederhana, simpan skrip init di ruang kerja primer dalam folder umum atau dalam serangkaian kecil folder jika memungkinkan. |
| Titik pemasangan | Sertakan dalam kode sumber jika dibuat hanya melalui pekerjaan berbasis buku catatan atau API Perintah. | Gunakan pekerjaan yang dapat dijalankan sebagai aktivitas di Azure Data Factory (ADF). Perhatikan bahwa titik akhir penyimpanan mungkin berubah, mengingat ruang kerja akan berada di wilayah yang berbeda. Ini sangat bergantung pada strategi pemulihan bencana data Anda juga. |
| Metadata tabel | Sertakan dengan kode sumber jika dibuat hanya melalui pekerjaan berbasis buku catatan atau API Perintah. Ini berlaku untuk metastore Azure Databricks internal atau metastore eksternal yang dikonfigurasi. | Bandingkan definisi metadata di antara metastore menggunakan Spark Catalog API atau Tampilkan Buat Tabel melalui buku catatan atau skrip. Perhatikan bahwa tabel untuk penyimpanan yang mendasarinya dapat berbasis wilayah dan akan berbeda di antara instans metastore. |
| Rahasia | Sertakan dalam kode sumber jika dibuat hanya melalui API Perintah. Perhatikan bahwa beberapa konten rahasia mungkin perlu diubah di antara primer dan sekunder. | Rahasia dibuat di kedua ruang kerja melalui API. Perhatikan bahwa beberapa konten rahasia mungkin perlu diubah di antara primer dan sekunder. |
| Konfigurasi klaster | Dapat berupa templat di Git. Sebarkan secara bersamaan ke penyebaran primer dan sekunder, meskipun penyebaran sekunder harus dihentikan hingga peristiwa pemulihan bencana. | Kluster dibuat setelah disinkronkan ke ruang kerja sekunder menggunakan API atau CLI. Itu dapat dihentikan secara eksplisit jika Anda mau, tergantung pada pengaturan pemutusan otomatis. |
| Izin buku catatan, pekerjaan, dan folder | Dapat berupa templat di Git. Sebarkan secara bersamaan ke penyebaran primer dan sekunder. | Replikasi menggunakan Permissions API. |
Pilih wilayah dan beberapa ruang kerja sekunder
Anda memerlukan kontrol penuh atas pemicu pemulihan bencana. Anda dapat memutuskan untuk memicunya kapan saja atau dengan alasan apa pun. Anda harus bertanggung jawab atas stabilisasi pemulihan bencana sebelum dapat memulai ulang operasi Anda dalam mode failback (produksi normal). Biasanya, ini berarti Anda harus membuat beberapa ruang kerja Azure Databricks untuk melayani kebutuhan produksi dan pemulihan bencana Anda, dan memilih wilayah failover sekunder Anda.
Di Azure, periksa replikasi data Anda serta ketersediaan jenis produk dan VM.
Langkah 3: Menyiapkan ruang kerja dan melakukan penyalinan satu kali
Jika ruang kerja sudah dalam produksi, operasi satu kali penyalinan biasanya dijalankan untuk menyinkronkan penyebaran pasif dengan penyebaran aktif. Penyalinan satu kali ini melibatkan hal-hal berikut:
- Replikasi data: Mereplikasi menggunakan solusi replikasi cloud atau operasi Delta Deep Clone.
- Pembuatan token: Gunakan pembuatan token untuk mengotomatiskan replikasi dan beban kerja di masa mendatang.
- Replikasi ruang kerja: Gunakan replikasi ruang kerja menggunakan metode yang dijelaskan di Langkah 4: Menyiapkan sumber data. Untuk panduan komprehensif tentang mengekspor konfigurasi ruang kerja, data, dan aset AI/ML, lihat Mengekspor data ruang kerja.
- Validasi ruang kerja: - Lakukan pengujian untuk memastikan bahwa ruang kerja dan proses dapat dijalankan dengan efektif dan memberikan hasil yang diharapkan.
Tindakan penyalinan dan sinkronisasi berikutnya menjadi lebih cepat setelah operasi penyalinan pertama kali. Setiap pencatatan dari alat Anda juga merekam perubahan yang terjadi dan kapan.
Step 4: Menyiapkan sumber data
Azure Databricks dapat memproses berbagai macam sumber data menggunakan pemrosesan batch atau aliran.
Pemrosesan batch dari sumber data
Ketika data diproses dalam batch, data biasanya berada di sumber data yang dapat dengan mudah direplikasi atau dikirimkan ke wilayah lain.
Misalnya, data mungkin diunggah secara teratur ke lokasi penyimpanan cloud. Dalam mode pemulihan bencana untuk wilayah sekunder Anda, pastikan file akan diunggah ke penyimpanan wilayah sekunder Anda. Beban kerja harus dibaca dari penyimpanan wilayah sekunder dan menulis ke penyimpanan wilayah sekunder.
Aliran
Memproses aliran data adalah tantangan yang lebih besar. Data streaming dapat diserap dari berbagai sumber, diproses, dan dikirim ke solusi streaming:
- Antrean pesan seperti Kafka
- Aliran pengambilan data perubahan database
- Pemrosesan berkelanjutan berbasis file
- Pemrosesan terjadwal berbasis file, juga dikenal sebagai pemicu satu kali
Dalam semua kasus tersebut, Anda harus mengonfigurasi sumber data untuk menangani mode pemulihan bencana dan menggunakan penyebaran sekunder di wilayah sekunder.
Penulis aliran data menyimpan titik pemeriksaan dengan informasi tentang data yang telah diproses. Titik pemeriksaan ini dapat berisi lokasi data (biasanya penyimpanan cloud) yang harus diubah ke lokasi baru untuk memastikan keberhasilan memulai ulang aliran. Misalnya, subfolder source dalam titik pemeriksaan mungkin menyimpan folder cloud berbasis file.
Titik pemeriksaan ini harus direplikasi pada waktu yang tepat. Pertimbangkan sinkronisasi interval titik pemeriksaan dengan solusi replikasi cloud baru.
Pembaruan titik pemeriksaan adalah fungsi penulis dan oleh karena itu berlaku untuk penerimaan data aliran atau pemrosesan dan penyimpanan pada sumber aliran lainnya.
Untuk beban kerja streaming, pastikan bahwa titik pemeriksaan dikonfigurasi dalam penyimpanan terkelola pelanggan sehingga dapat direplikasi ke wilayah sekunder untuk dimulainya kembali beban kerja dari titik kegagalan terakhir. Anda juga dapat memilih untuk menjalankan proses streaming sekunder secara paralel dengan proses primer.
Langkah 5: Menerapkan dan menguji solusi
Uji penyiapan pemulihan bencana secara berkala untuk memastikannya berfungsi dengan benar. Tidak ada nilai dalam mempertahankan solusi pemulihan bencana jika Anda tidak dapat menggunakannya saat Anda membutuhkannya. Beberapa perusahaan beralih antarwilayah setiap beberapa bulan. Beralih wilayah pada jadwal teratur menguji asumsi dan proses Anda, dan memastikan bahwa wilayah tersebut memenuhi kebutuhan pemulihan Anda. Ini juga memastikan bahwa organisasi Anda terbiasa dengan kebijakan dan prosedur untuk keadaan darurat.
Penting
Uji solusi pemulihan bencana Anda secara teratur dalam kondisi dunia nyata.
Jika Anda menemukan bahwa Anda kehilangan objek atau templat dan masih harus mengandalkan informasi yang disimpan di ruang kerja utama Anda, ubah rencana Anda untuk menghapus rintangan ini, mereplikasi informasi ini dalam sistem sekunder, atau membuatnya tersedia dengan cara lain.
Uji perubahan organisasi yang diperlukan pada proses Anda dan ke konfigurasi secara umum. Rencana pemulihan bencana memengaruhi alur penyebaran Anda, dan penting bagi tim Anda untuk mengetahui apa yang perlu tetap sinkron. Setelah menyiapkan ruang kerja pemulihan bencana, pastikan infrastruktur (manual atau kode), pekerjaan, buku catatan, pustaka, dan objek ruang kerja lainnya tersedia di wilayah sekunder Anda.
Diskusikan dengan tim Anda mengenai cara memperluas proses kerja standar dan alur konfigurasi untuk menyebarkan perubahan ke semua ruang kerja. Kelola identitas pengguna di semua ruang kerja. Ingatlah untuk mengonfigurasi alat seperti automasi pekerjaan dan pemantauan ruang kerja baru.
Rencanakan dan uji perubahan pada alat konfigurasi:
- Penyerapan: Pahami tempat sumber data Anda berada dan tempat sumber tersebut mendapatkan datanya. Jika memungkinkan, buat parameter sumber dan pastikan Anda memiliki templat konfigurasi terpisah untuk bekerja dengan penyebaran sekunder dan wilayah sekunder. Siapkan rencana untuk failover dan uji semua asumsi.
- Perubahan eksekusi: Jika memiliki penjadwal untuk memicu pekerjaan atau tindakan lain, Anda mungkin perlu mengonfigurasi penjadwal terpisah yang berfungsi dengan penyebaran sekunder atau sumber datanya. Siapkan rencana untuk failover dan uji semua asumsi.
- Konektivitas interaktif: Pertimbangkan bagaimana konfigurasi, autentikasi, dan koneksi jaringan mungkin dipengaruhi oleh gangguan regional untuk penggunaan REST API, alat CLI, atau layanan lain seperti JDBC/ODBC. Siapkan rencana untuk failover dan uji semua asumsi.
- Perubahan automasi: Untuk semua alat automasi, siapkan rencana failover dan uji semua asumsi.
- Output: Untuk alat apa pun yang menghasilkan data atau log output, siapkan rencana failover dan uji semua asumsi.
Pengujian failover
Pemulihan bencana dapat dipicu oleh berbagai skenario. Bisa dipicu oleh jeda tak terduga. Beberapa fungsi inti mungkin tidak berfungsi, termasuk jaringan cloud, penyimpanan cloud, atau layanan inti lainnya. Anda tidak memiliki akses untuk mematikan sistem secara teratur dan harus mencoba memulihkannya. Namun, prosesnya dapat dipicu oleh penonaktifan atau penghentian yang direncanakan, atau bahkan dengan beralihnya penyebaran aktif Anda secara berkala di antara dua wilayah.
Saat Anda menguji failover, sambungkan ke sistem dan jalankan proses mematikan. Pastikan semua pekerjaan telah selesai dan kluster dihentikan.
Klien sinkronisasi (atau alat CI/CD) dapat mereplikasi objek dan sumber daya Azure Databricks yang relevan ke ruang kerja sekunder. Untuk mengaktifkan ruang kerja sekunder, proses Anda mungkin meliputi beberapa atau semua hal berikut:
- Jalankan pengujian untuk mengonfirmasi bahwa platform tersebut terbaru.
- Nonaktifkan kumpulan dan kluster di wilayah primer sehingga jika layanan yang gagal kembali online, wilayah primer tidak mulai memproses data baru.
- Proses pemulihan:
- Periksa tanggal data yang disinkronkan terbaru. Lihat Terminologi industri pemulihan bencana. Detail langkah ini bervariasi tergantung pada cara Anda menyinkronkan data dan kebutuhan bisnis unik Anda.
- Stabilkan sumber data Anda dan pastikan semuanya tersedia. Sertakan semua sumber data eksternal, seperti Azure Cloud SQL, dan Delta Lake, Parquet, atau file Lainnya.
- Temukan titik pemulihan streaming Anda. Siapkan proses untuk memulai ulang dari sana dan memiliki proses yang siap untuk mengidentifikasi dan menghilangkan potensi duplikat (Delta Lake membuatnya lebih mudah).
- Selesaikan proses aliran data dan beri tahu pengguna.
- Mulai kumpulan yang relevan (atau tingkatkan
min_idle_instanceske angka yang relevan). - Mulai kluster yang relevan (jika belum dihentikan).
- Ubah jalannya tugas secara bersamaan dan jalankan tugas yang relevan. Ini bisa jadi eksekusi satu kali atau eksekusi berkala.
- Untuk alat luar apa pun yang menggunakan URL atau nama domain untuk ruang kerja Azure Databricks Anda, perbarui konfigurasi untuk memperhitungkan sarana kontrol baru. Misalnya, perbarui URL untuk REST API dan koneksi JDBC/ODBC. URL yang menghadap pelanggan aplikasi web Azure Databricks berubah saat sarana kontrol berubah, jadi beri tahu pengguna organisasi Anda tentang URL baru.
Pengujian pemulihan (failback)
Failback lebih mudah dikontrol dan dapat dilakukan di jendela pemeliharaan. Rencana ini dapat mencakup beberapa atau semua hal berikut:
- Pastikan bahwa wilayah utama telah dipulihkan.
- Nonaktifkan kumpulan dan kluster di wilayah sekunder sehingga tidak akan memulai pemrosesan data baru.
- Sinkronkan aset baru atau yang diubah di ruang kerja sekunder kembali ke lingkungan utama. Bergantung pada desain skrip failover Anda, Anda mungkin dapat menjalankan skrip yang sama untuk menyinkronkan objek dari wilayah sekunder (pemulihan bencana) ke wilayah (produksi) primer.
- Sinkronkan kembali pembaruan data baru ke penyebaran primer. Anda dapat menggunakan jejak audit log dan tabel Delta untuk memastikan tidak ada data yang hilang.
- Matikan semua beban kerja di wilayah pemulihan bencana.
- Ubah URL pekerjaan dan URL pengguna ke wilayah utama.
- Jalankan pengujian untuk mengonfirmasi bahwa platform tersebut terbaru.
- Mulai kumpulan yang relevan (atau tingkatkan
min_idle_instanceske angka yang relevan). - Mulai kluster yang relevan (jika belum dihentikan).
- Ubah pengaturan pelaksanaan untuk tugas secara bersamaan, dan jalankan tugas yang relevan. Ini bisa jadi eksekusi satu kali atau eksekusi berkala.
- Sesuai kebutuhan, siapkan wilayah sekunder lagi untuk pemulihan bencana di masa mendatang.
Skrip, sampel, dan prototipe automasi
Skrip automasi yang perlu dipertimbangkan untuk proyek pemulihan bencana:
- Databricks merekomendasikan agar Anda menggunakan Penyedia Databricks Terraform untuk membantu mengembangkan proses sinkronisasi Anda sendiri.
- Lihat juga Alat Migrasi Ruang Kerja Databricks untuk skrip sampel dan prototipe. Selain objek Azure Databricks, replikasi alur Azure Data Factory yang relevan sehingga akan merujuk ke layanan tertaut yang dipetakan ke ruang kerja sekunder.
- Proyek Databricks Sync (DBSync) adalah alat sinkronisasi objek yang mencadangkan, memulihkan, dan menyinkronkan ruang kerja Databricks.