Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menyediakan panduan arsitektur untuk lakehouse, mencakup sumber data, penyerapan, transformasi, kueri dan pemrosesan, penyajian, analisis, dan penyimpanan.
Setiap arsitektur referensi memiliki PDF yang dapat diunduh dalam format 11 x 17 (A3).
Sementara lakehouse di Databricks adalah platform terbuka yang terintegrasi dengan ekosistem alat mitra besar, arsitektur referensi hanya berfokus pada layanan Azure dan lakehouse Databricks. Layanan penyedia cloud yang ditampilkan dipilih untuk mengilustrasikan konsep dan tidak lengkap.
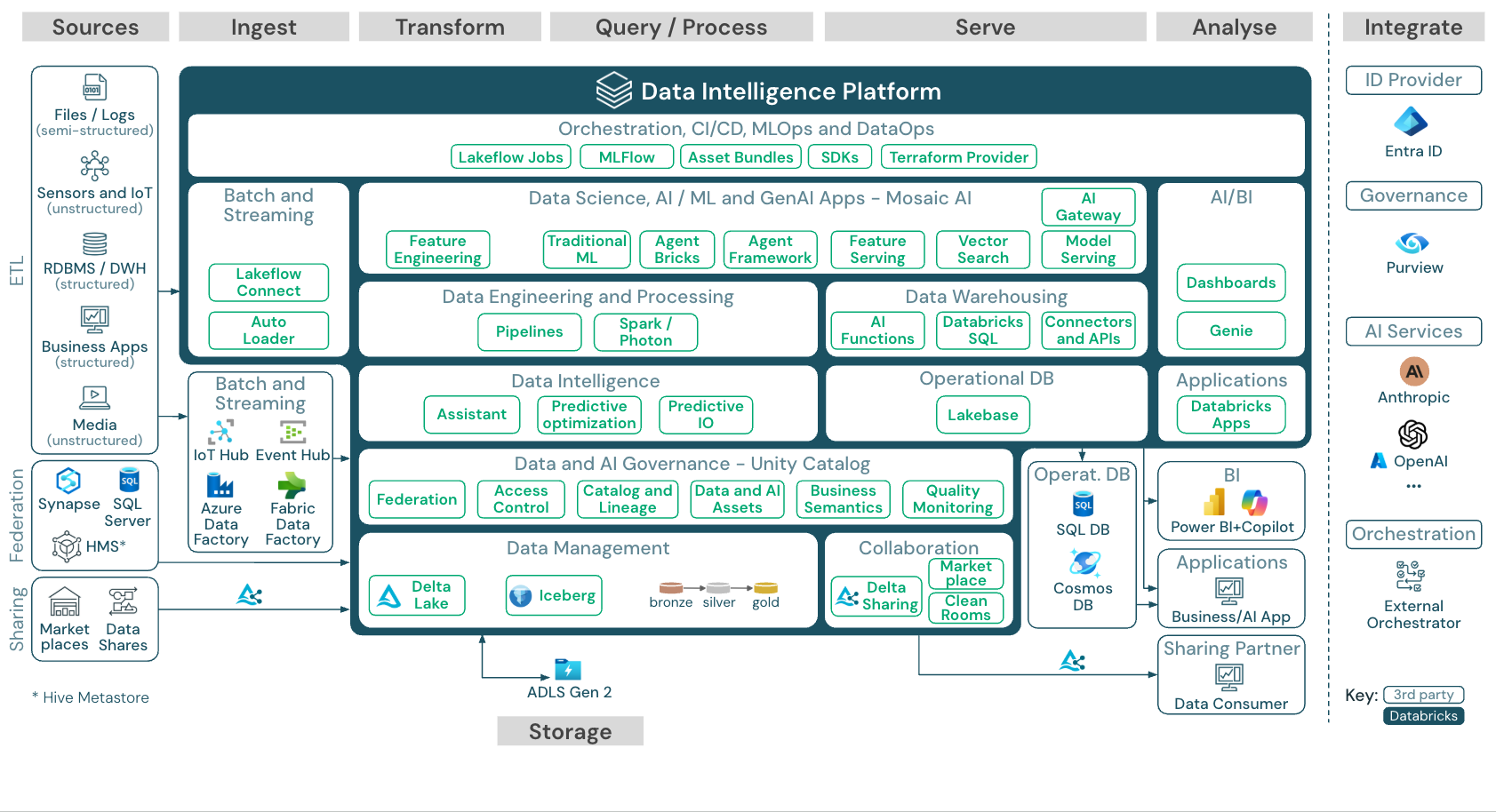
Unduh: Arsitektur Referensi untuk Azure Databricks Lakehouse
Arsitektur referensi Azure memperlihatkan layanan khusus Azure berikut ini untuk menyerap, menyimpan, melayani, dan menganalisis:
- Azure Synapse dan SQL Server sebagai sistem sumber untuk Federasi Lakehouse
- Azure IoT Hub dan Azure Event Hubs untuk pengambilan data streaming
- Azure Data Factory untuk pemrosesan batch
- Azure Data Lake Storage Gen 2 (ADLS) sebagai penyimpanan objek untuk data dan aset AI
- Azure SQL DB dan Azure Cosmos DB sebagai database operasional
- Azure Purview sebagai katalog perusahaan tempat UC mengekspor skema dan informasi silsilah data
- Power BI sebagai alat BI
- Azure OpenAI dapat digunakan oleh Model Serving sebagai sebuah LLM eksternal
Organisasi Arsitektur Referensi
Arsitektur referensi disusun di sepanjang alur Source, Ingest, Transformasi, Query/Process, Melayani, Analisis, dan Penyimpanan:
Source
Ada tiga cara untuk mengintegrasikan data eksternal ke dalam Platform Inteligensi Data:
- ETL: Platform ini memungkinkan integrasi dengan sistem yang menyediakan data semi terstruktur dan tidak terstruktur (seperti sensor, perangkat IoT, media, file, dan log), serta data terstruktur dari database relasional atau aplikasi bisnis.
- Federasi Lakehouse: Sumber SQL, seperti database relasional, dapat diintegrasikan ke dalam lakehouse dan Unity Catalog tanpa ETL. Dalam hal ini, data sistem sumber diatur oleh Katalog Unity, dan kueri diarahkan ke sistem sumber.
- Federasi Katalog: Katalog Apache Hive Metastore juga dapat diintegrasikan ke dalam Katalog Unity melalui federasi katalog, memungkinkan Katalog Unity untuk mengontrol tabel yang disimpan di Apache Hive Metastore.
Ingest
Serap data ke lakehouse melalui batch atau streaming:
- Databricks Lakeflow Connect menawarkan konektor bawaan untuk penyerapan dari aplikasi dan database perusahaan. Alur penyerapan yang dihasilkan diatur oleh Katalog Unity dan didukung oleh komputasi dan Alur tanpa server.
- File yang dikirimkan ke penyimpanan cloud dapat dimuat langsung menggunakan Databricks Auto Loader.
- Untuk penyerapan data batch dari aplikasi perusahaan ke Delta Lake, Databricks Lakehouse bergantung pada alat ingest mitra dengan adaptor tertentu untuk sistem pencatatan ini.
- Peristiwa streaming dapat diserap langsung dari sistem streaming peristiwa seperti Kafka menggunakan Databricks Structured Streaming. Sumber streaming dapat berupa sensor, IoT, atau mengubah proses pengambilan data.
Storage
- Data biasanya disimpan dalam sistem penyimpanan cloud di mana alur ETL menggunakan arsitektur medali untuk menyimpan data dengan cara yang dikumpulkan sebagai file/tabel Delta atau tabel Apache Iceberg.
Transformasi dan Kueri/proses
Lakehouse Databricks menggunakan mesin Apache Spark dan Photon untuk semua transformasi dan kueri.
Alur adalah kerangka kerja deklaratif untuk menyederhanakan dan mengoptimalkan alur pemrosesan data yang andal, dapat dipertahankan, dan dapat diuji.
Didukung oleh Apache Spark dan Photon, Platform Databricks Data Intelligence mendukung kedua jenis beban kerja: kueri SQL melalui gudang SQL, dan beban kerja SQL, Python, dan Scala melalui kluster ruang kerja.
Untuk ilmu data (ML Modeling dan Gen AI), platform Databricks AI dan Pembelajaran Mesin menyediakan runtime ML khusus untuk AutoML dan untuk pekerjaan ML pemrograman. Semua alur kerja ilmu data dan MLOps paling baik didukung oleh MLflow.
Serving
Untuk kasus penggunaan data warehousing (DWH) dan BI, databricks lakehouse menyediakan Databricks SQL, gudang data yang didukung oleh gudang SQL, dan gudang SQL tanpa server.
Untuk pembelajaran mesin, Mosaic AI Model Serving adalah kemampuan penyajian model tingkat perusahaan yang dapat diskalakan, real time, dan dihosting di sarana kontrol Databricks. Mosaic AI Gateway adalah solusi Databricks untuk mengatur dan memantau akses ke model AI generatif yang didukung dan model terkait yang melayani titik akhir.
Database operasional:
- Lakebase adalah database pemrosesan transaksi online (OLTP) berdasarkan Postgres dan sepenuhnya terintegrasi dengan Databricks Data Intelligence Platform. Ini memungkinkan Anda membuat database OLTP di Databricks dan mengintegrasikan beban kerja OLTP dengan Lakehouse Anda.
- Sistem eksternal, seperti database operasional, dapat digunakan untuk menyimpan dan mengirimkan produk data akhir ke aplikasi pengguna.
Collaboration:
Mitra bisnis mendapatkan akses aman ke data yang mereka butuhkan melalui Berbagi Delta.
Berdasarkan Delta Sharing, Databricks Marketplace adalah platform terbuka untuk bertukar produk data.
Clean Rooms adalah lingkungan yang aman dan melindungi privasi di mana beberapa pengguna dapat bekerja sama pada data perusahaan sensitif tanpa akses langsung ke data satu sama lain.
Analysis
Aplikasi bisnis terakhir berada di "swim lane" ini. Contohnya termasuk klien kustom seperti aplikasi AI yang terhubung ke Mosaic AI Model Serving untuk inferensi waktu nyata atau aplikasi yang mengakses data yang didorong dari lakehouse ke database operasional.
Untuk kasus penggunaan BI, analis biasanya menggunakan alat BI untuk mengakses gudang data. Pengembang SQL juga dapat menggunakan Editor SQL Databricks (tidak ditampilkan dalam diagram) untuk kueri dan dasbor.
Platform Kecerdasan Data juga menawarkan dasbor untuk membangun visualisasi data dan berbagi wawasan.
Integrate
- Platform Databricks terintegrasi dengan penyedia identitas standar untuk
manajemen pengguna dan login tunggal (SSO).
Layanan AI eksternal seperti OpenAI, LangChain atau HuggingFace dapat digunakan langsung dari dalam Platform Inteligensi Databricks.
Orkestrator eksternal dapat menggunakan REST API
komprehensif atau konektor khusus ke alat orkestrasi eksternal seperti Apache Airflow .Unity Catalog digunakan untuk semua data dan tata kelola AI di Platform Intelegensi Databricks dan dapat mengintegrasikan database lain dalam tata kelolanya melalui Federasi Lakehouse.
Selain itu, Unity Catalog dapat diintegrasikan ke dalam katalog perusahaan lain, misalnya Purview. Hubungi vendor katalog perusahaan untuk detailnya.
- Platform Databricks terintegrasi dengan penyedia identitas standar untuk
Kemampuan umum untuk semua beban kerja
Selain itu, Databricks lakehouse dilengkapi dengan kemampuan manajemen yang mendukung semua beban kerja:
Tata kelola data dan AI
Data pusat dan sistem tata kelola AI di Platform Kecerdasan Databricks adalah Unity Catalog. Unity Catalog menyediakan satu tempat untuk mengelola kebijakan akses data yang berlaku di semua ruang kerja dan mendukung semua aset yang dibuat atau digunakan di lakehouse, seperti tabel, volume, fitur (feature store), dan model (model registry). Katalog Unity juga dapat digunakan untuk menelusuri asal-usul data pada runtime di seluruh kueri yang berjalan di Databricks.
Pemantauan Kualitas Databricks memungkinkan Anda memantau kualitas data semua tabel di akun Anda. Ini mendeteksi anomali di semua tabel Anda dan menyediakan profil data lengkap untuk setiap tabel.
Untuk pengamatan, tabel sistem adalah penyimpanan analitik yang dihosting Databricks dari data operasional akun Anda. Tabel sistem dapat digunakan untuk pengamatan historis di seluruh akun Anda.
Mesin kecerdasan data
Platform Kecerdasan Data Databricks memungkinkan seluruh organisasi Anda untuk menggunakan data dan AI, menggabungkan AI generatif dengan manfaat penyatuan lakehouse, sehingga dapat memahami semantik unik dari data Anda. Lihat Fitur bantuan Databricks AI.
Kode Genie tersedia di notebook Databricks, editor SQL, editor file, dan di tempat lain sebagai asisten AI sadar konteks untuk pengguna.
Otomatisasi & Orkestrasi
Pekerjaan Lakeflow mengatur pemrosesan data, pembelajaran mesin, dan alur analitik pada Platform Kecerdasan Databricks. Alur Deklaratif Lakeflow Spark memungkinkan Anda membangun alur ETL yang andal dan dapat dipertahankan dengan sintaks deklaratif. Platform ini juga mendukung CI/CD dan MLOps
Kasus penggunaan tingkat tinggi untuk Platform Inteligensi Data di Azure
Penyerapan bawaan dari aplikasi dan database SaaS dengan Lakeflow Connect
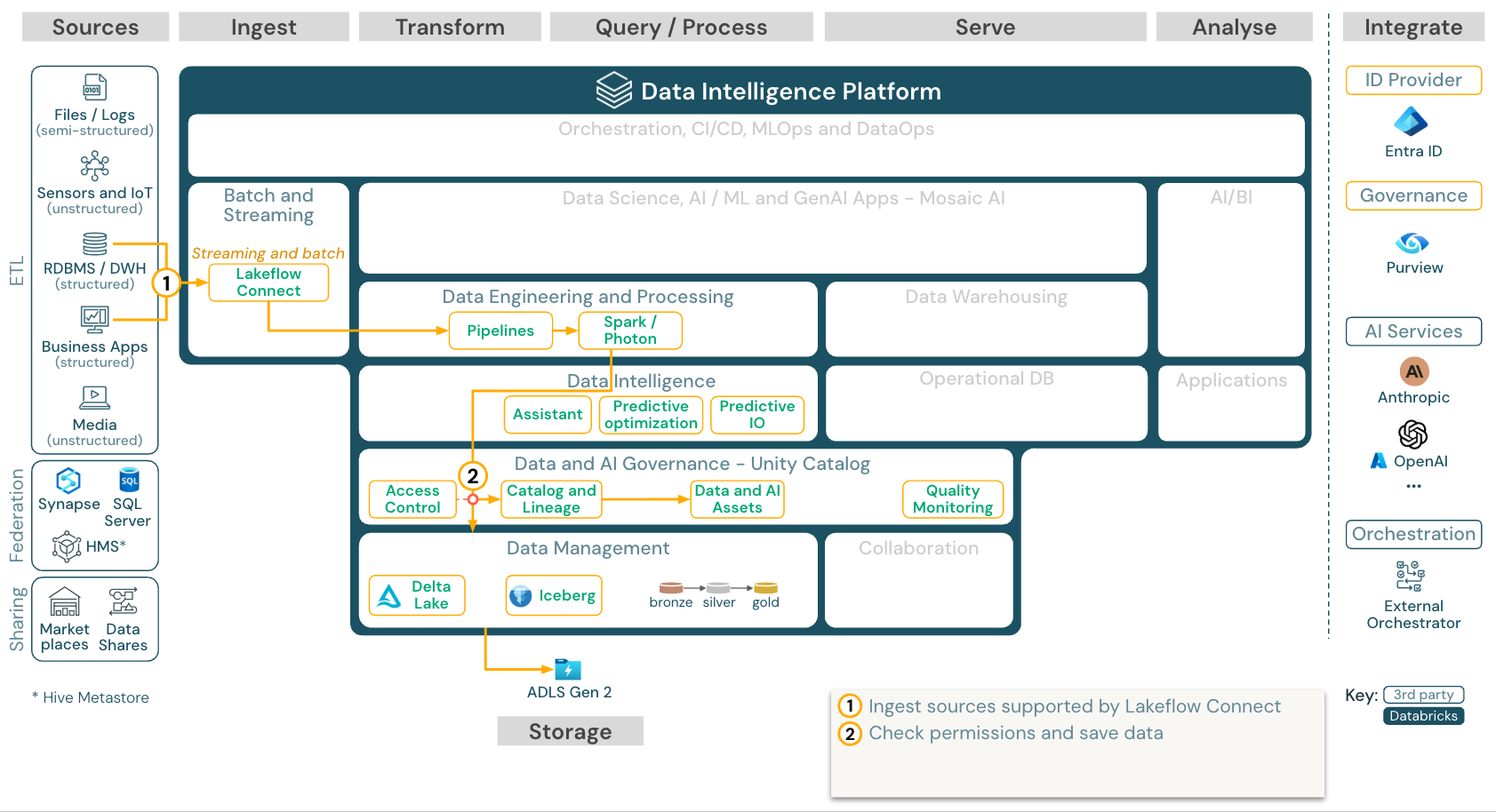
Unduh: Arsitektur referensi Lakeflow Connect untuk Azure Databricks.
Databricks Lakeflow Connect menawarkan konektor bawaan untuk penyerapan dari aplikasi dan database perusahaan. Alur penyerapan yang dihasilkan diatur oleh Unity Catalog dan didukung oleh komputasi tanpa server dan Alur Deklaratif Lakeflow Spark.
Lakeflow Connect memanfaatkan pembacaan dan penulisan inkremental yang efisien untuk membuat penyerapan data lebih cepat, dapat diskalakan, dan lebih hemat biaya, sementara data Anda tetap segar untuk konsumsi hilir.
Pengumpulan batch dan ETL
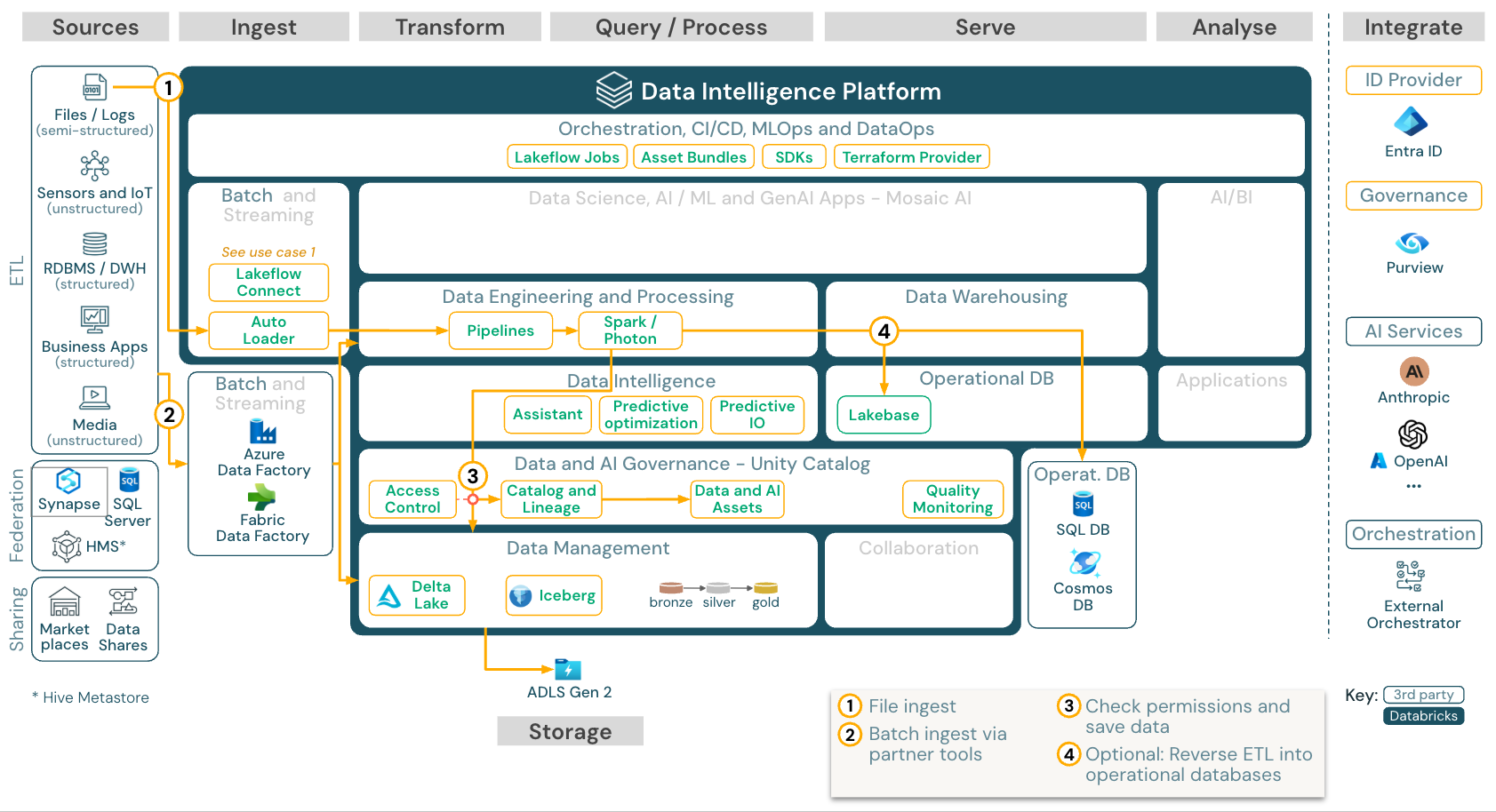
Unduh: Arsitektur referensi ETL Batch untuk Azure Databricks
Alat penyerapan menggunakan adaptor khusus sumber untuk membaca data dari sumber dan kemudian menyimpannya di penyimpanan cloud dari mana Auto Loader dapat membacanya, atau memanggil Databricks secara langsung (misalnya, dengan alat penyerapan mitra yang terintegrasi ke dalam lakehouse Databricks). Untuk memuat data, ETL dan mesin pengolahan Databricks menjalankan kueri melalui Pipelines. Mengatur pekerjaan tunggal atau multitugas menggunakan Pekerjaan Lakeflow dan mengaturnya menggunakan Katalog Unity (kontrol akses, audit, silsilah data, dan sebagainya). Untuk menyediakan akses ke tabel emas tertentu untuk sistem operasional latensi rendah, ekspor tabel ke database operasional seperti RDBMS atau penyimpanan nilai kunci di akhir alur ETL.
Streaming dan penangkapan data perubahan (CDC)
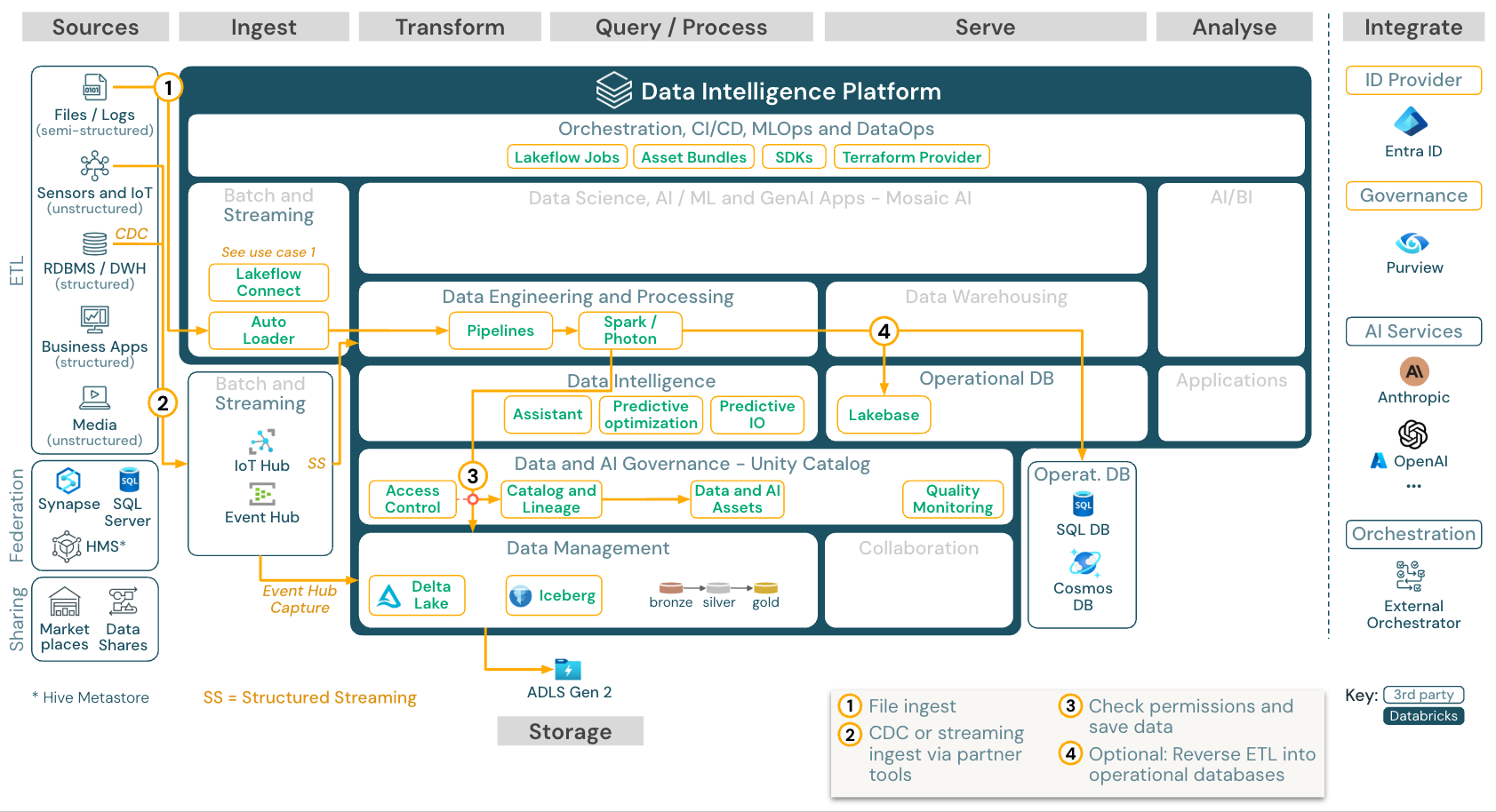
Unduh: Arsitektur streaming terstruktur Spark untuk Azure Databricks
Mesin Databricks ETL menggunakan Spark Structured Streaming untuk membaca dari antrean peristiwa seperti Apache Kafka atau Azure Event Hub. Langkah-langkah hilir mengikuti pendekatan kasus penggunaan Batch di atas.
Pengambilan data perubahan real time (CDC) biasanya menyimpan peristiwa yang diekstrak dalam antrean peristiwa. Dari sana, kasus penggunaan mengikuti pola penggunaan streaming.
Jika CDC dilakukan dalam batch, dengan rekaman yang diekstrak disimpan terlebih dahulu di penyimpanan cloud, Databricks Auto Loader dapat membacanya, dan skenario penggunaannya mengikuti model Batch ETL.
Pembelajaran mesin dan AI (tradisional)
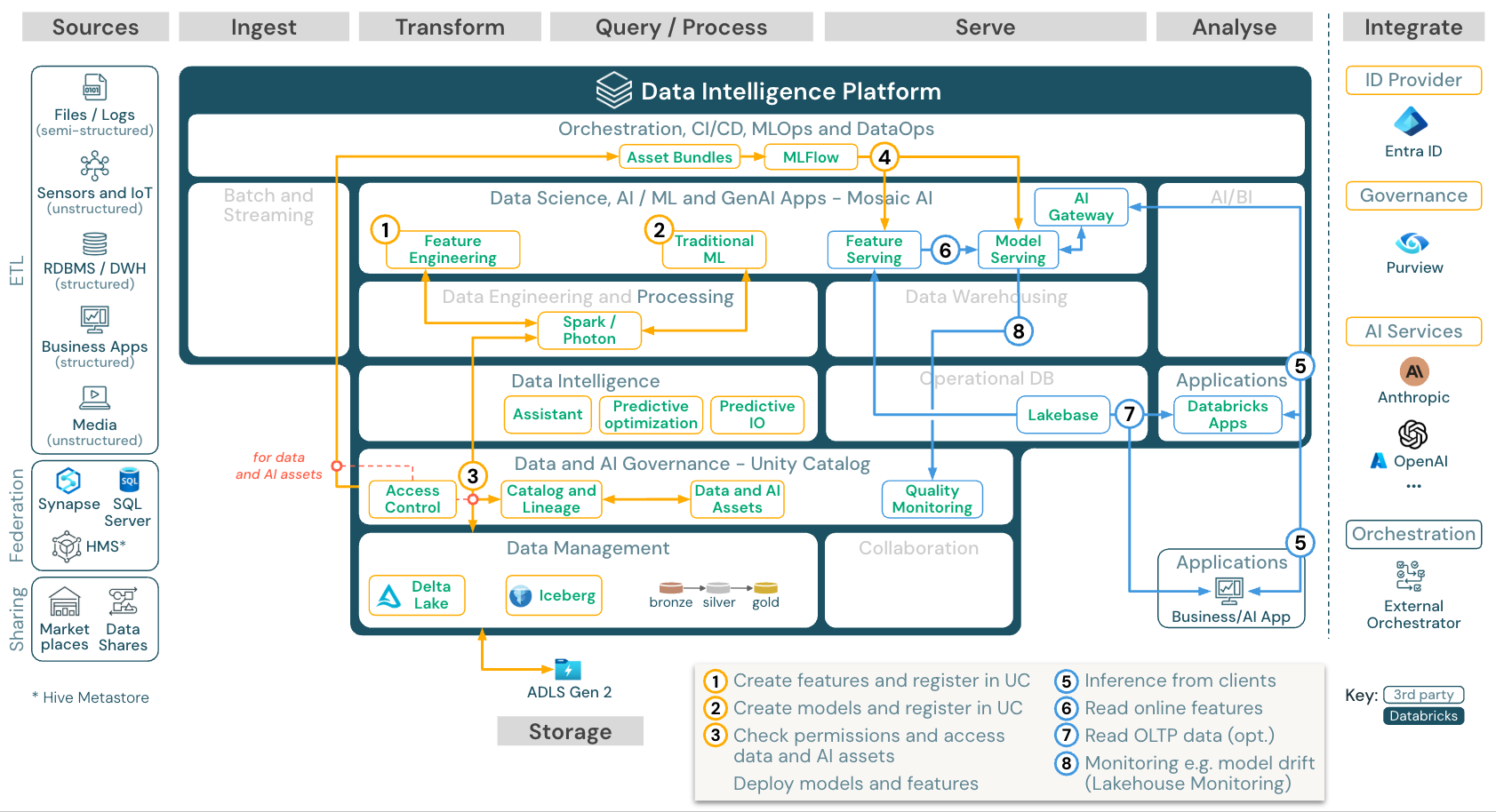
Unduh: Arsitektur referensi pembelajaran mesin dan AI untuk Azure Databricks
Untuk pembelajaran mesin, Databricks Data Intelligence Platform menyediakan Mosaic AI, yang dilengkapi dengan mesin canggih dan pustaka pembelajaran mendalam. Ini menyediakan kemampuan seperti Penyimpanan Fitur dan Registri Model (keduanya terintegrasi ke dalam Unity Catalog), fitur kode rendah dengan AutoML, dan integrasi MLflow ke dalam siklus hidup ilmu data.
Unity Catalog mengatur semua aset terkait ilmu data (tabel, fitur, dan model), dan ilmuwan data dapat menggunakan Pekerjaan Lakeflow untuk mengatur pekerjaan mereka.
Untuk menyebarkan model dengan cara yang dapat diskalakan dan memenuhi standar perusahaan, gunakan kemampuan MLOps untuk menerbitkan model dalam pelayanan model.
Aplikasi Agen AI (Gen AI)
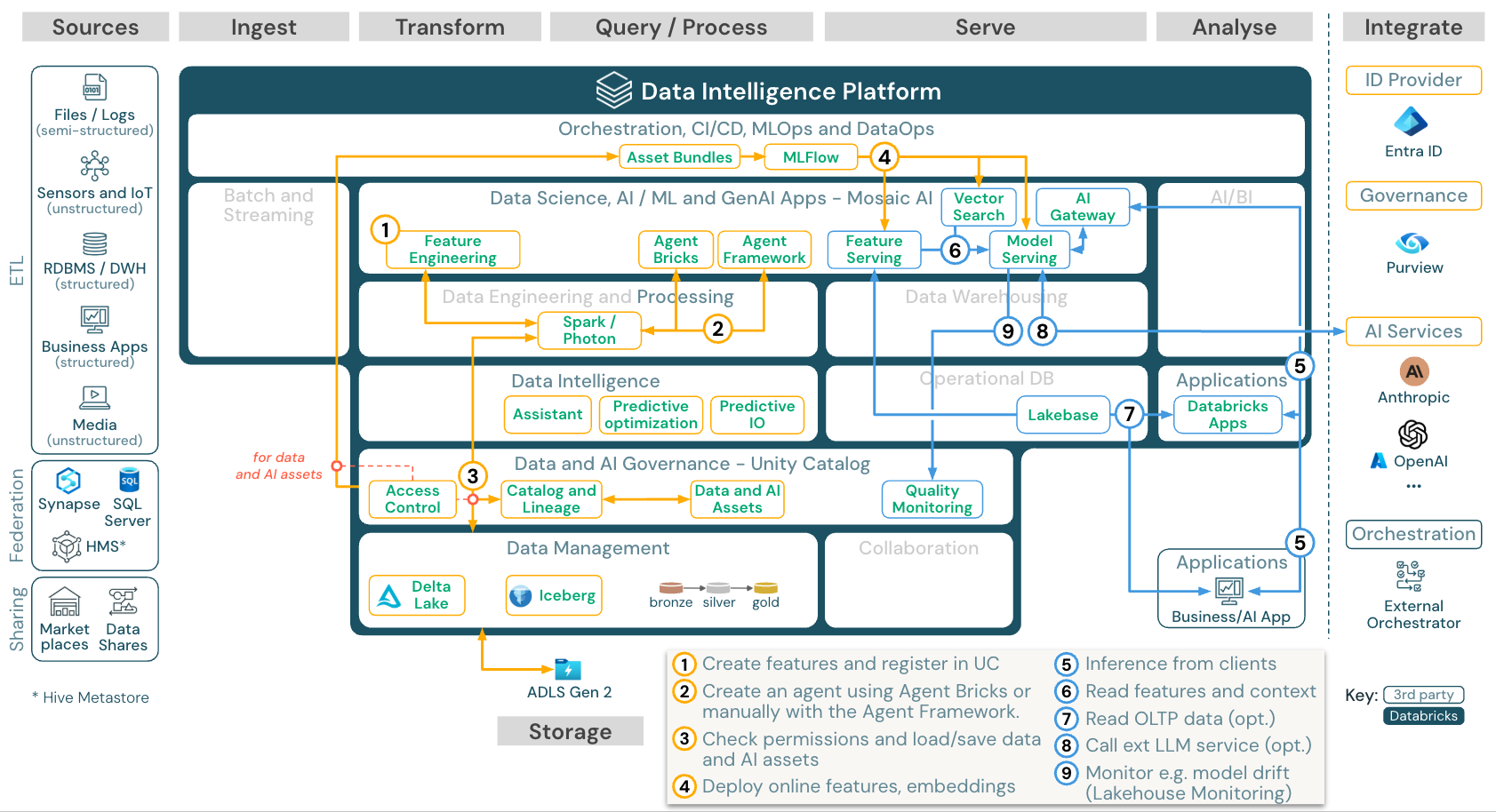
Unduh: Arsitektur referensi aplikasi Gen AI untuk Azure Databricks
Untuk menyebarkan model secara skalabel dan berkelas perusahaan, gunakan kemampuan MLOps untuk memublikasikan model dalam layanan model.
Analitik BI dan SQL
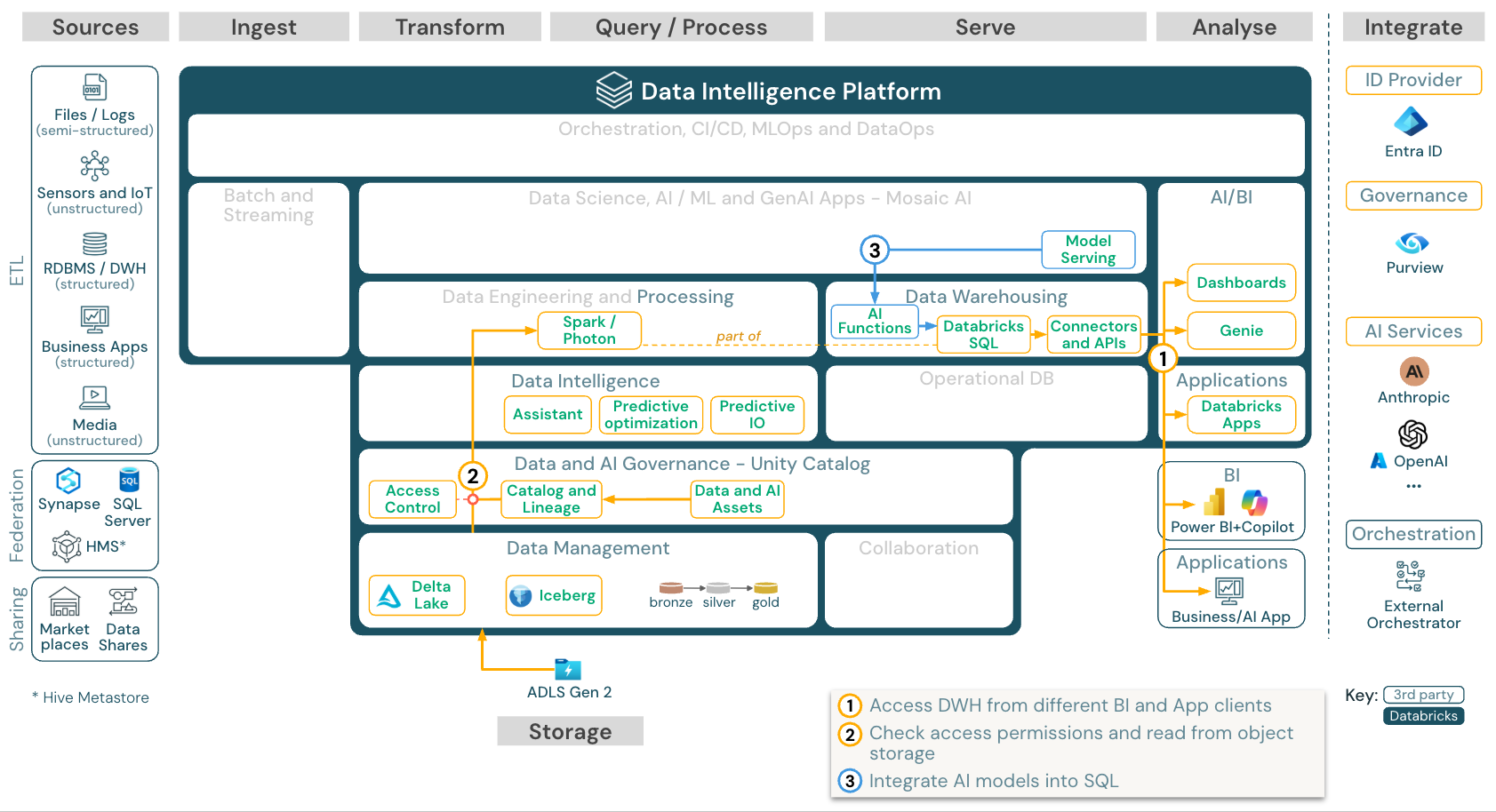
Unduh: Arsitektur referensi analitik BI dan SQL untuk Azure Databricks
Untuk kasus penggunaan BI, analis bisnis dapat menggunakan dasbor, editor Databricks SQL atau alat BI seperti Tableau atau Power BI. Dalam semua kasus, mesinnya adalah Databricks SQL (tanpa server atau tanpa server), dan Unity Catalog menyediakan penemuan, eksplorasi, dan kontrol akses data.
Aplikasi Bisnis
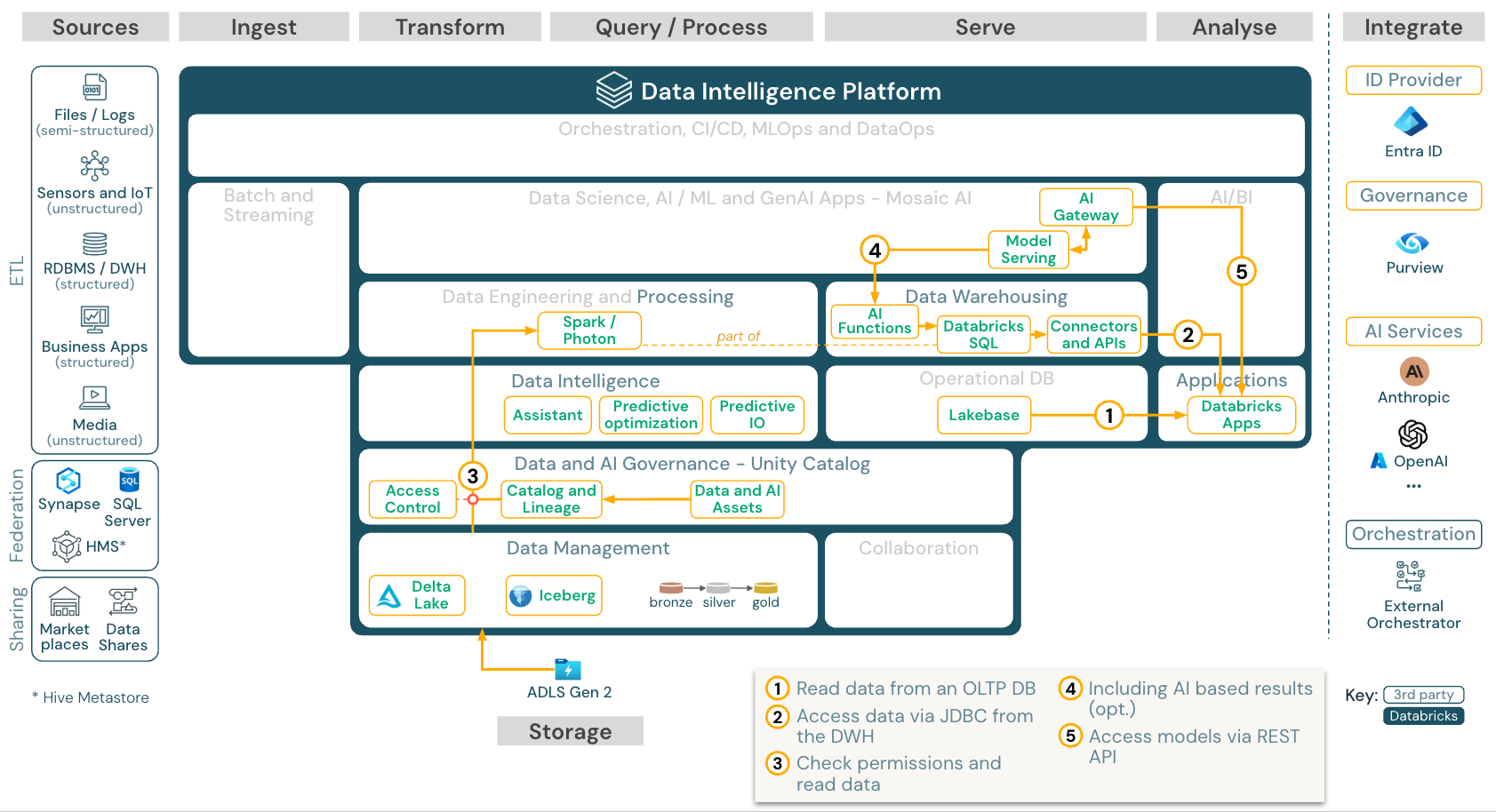
Unduh: Aplikasi Bisnis untuk Databricks untuk Azure Databricks
Databricks Apps memungkinkan pengembang untuk membangun dan menyebarkan data yang aman dan aplikasi AI langsung di platform Databricks, yang menghilangkan kebutuhan akan infrastruktur terpisah. Aplikasi dihosting di platform tanpa server Databricks dan diintegrasikan dengan layanan platform utama. Gunakan Lakebase jika aplikasi membutuhkan data OLTP yang disinkronkan dari Lakehouse.
Federasi Lakehouse
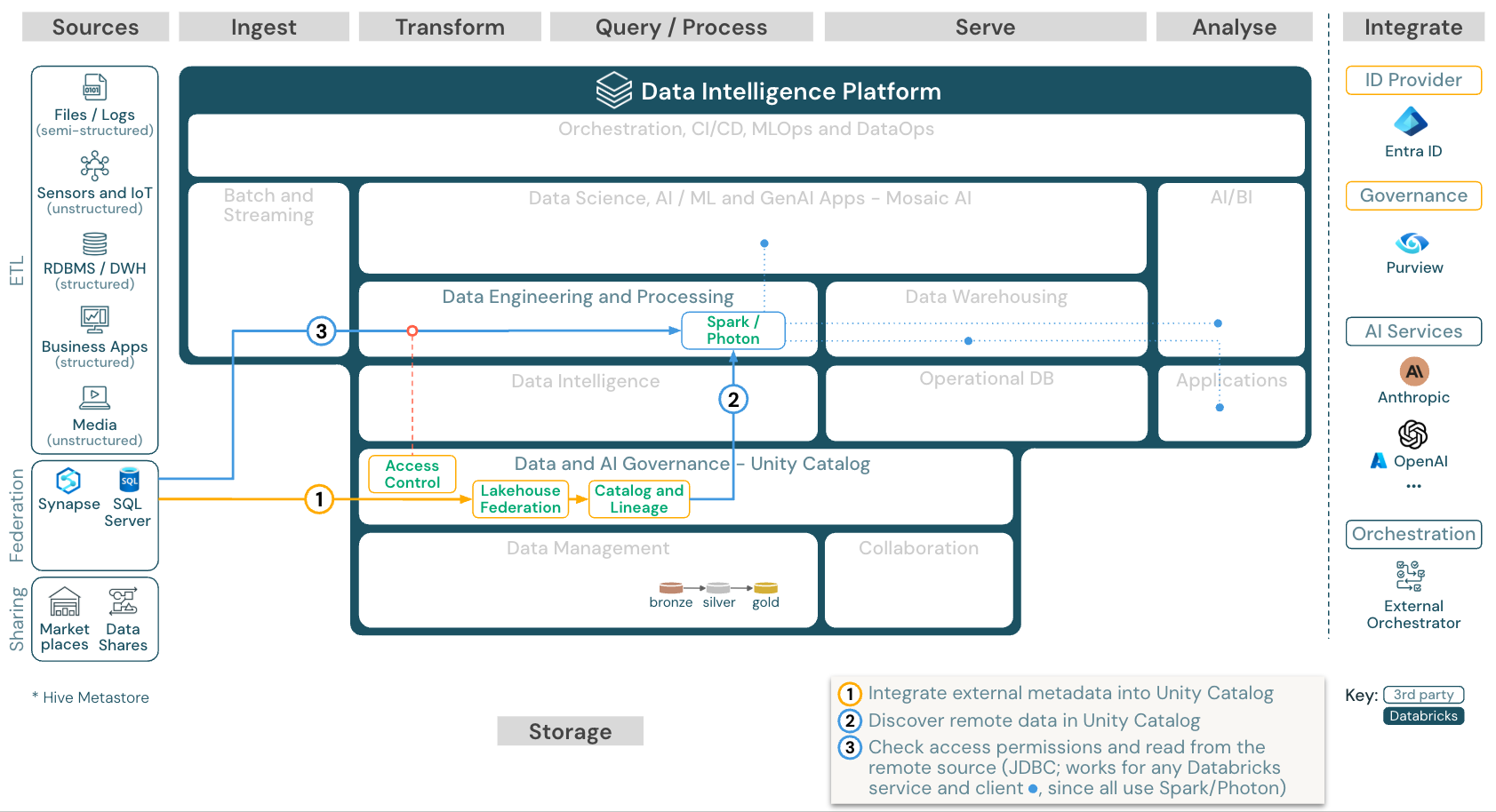
Unduh: Arsitektur referensi federasi Lakehouse untuk Azure Databricks
Federasi Lakehouse memungkinkan database SQL data eksternal (seperti MySQL, Postgres, SQL Server, atau Azure Synapse) untuk diintegrasikan dengan Databricks.
Semua beban kerja (AI, DWH, dan BI) dapat memperoleh manfaat dari ini tanpa perlu ETL data ke penyimpanan objek terlebih dahulu. Katalog sumber eksternal dipetakan ke dalam katalog Unity dan kontrol akses halus dapat diterapkan untuk mengakses melalui platform Databricks.
Federasi katalog
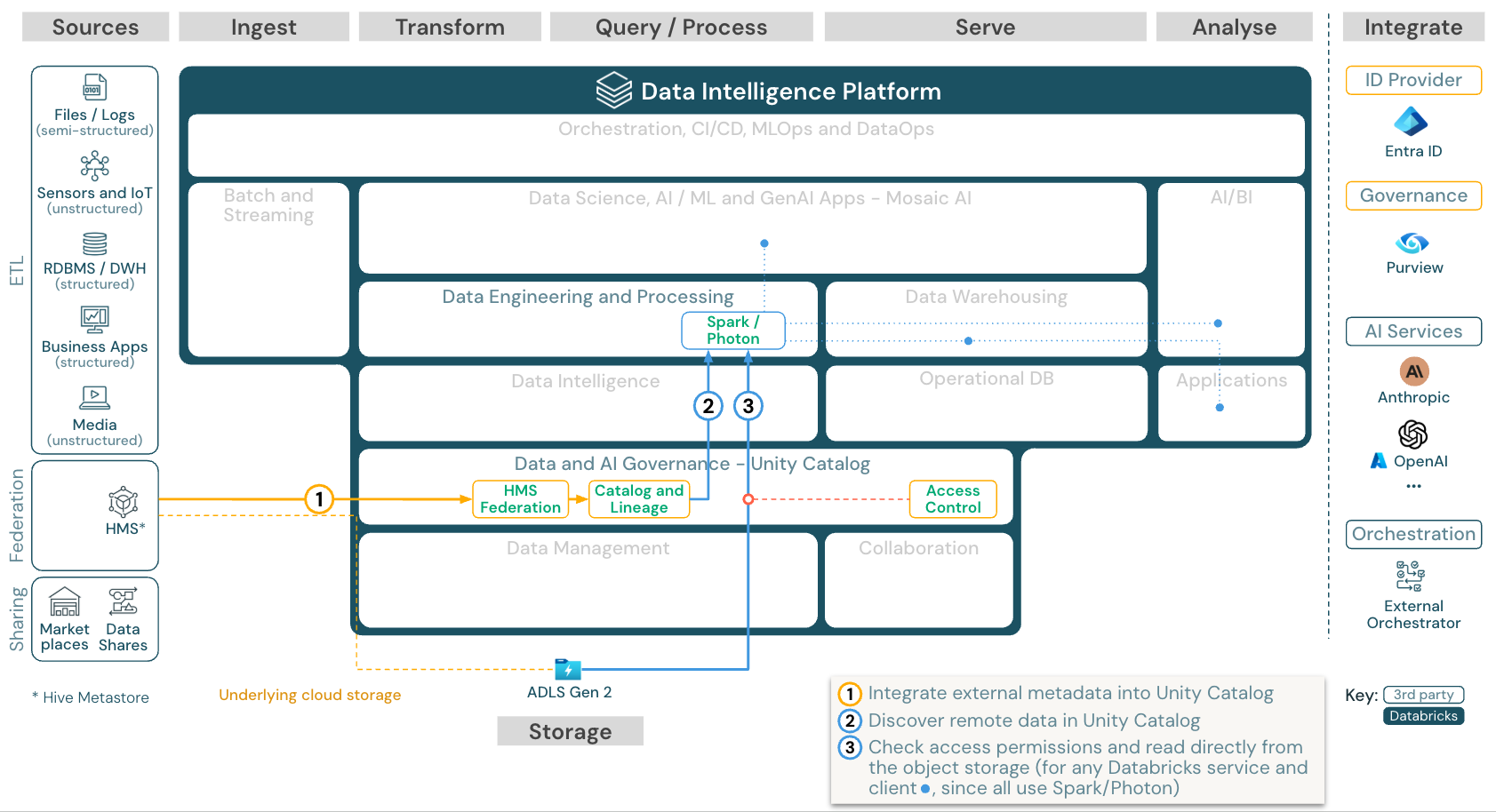
Unduh: Arsitektur referensi federasi katalog untuk Azure Databricks
Federasi katalog memungkinkan Metastores Apache Hive eksternal (seperti MySQL, Postgres, SQL Server, atau Azure Synapse) untuk diintegrasikan dengan Databricks.
Semua beban kerja (AI, DWH, dan BI) dapat memperoleh manfaat dari ini tanpa perlu ETL data ke penyimpanan objek terlebih dahulu. Katalog sumber eksternal ditambahkan ke Unity Catalog di mana kontrol akses terperindas diterapkan melalui platform Databricks.
Bagikan Data dengan alat pihak ke-3
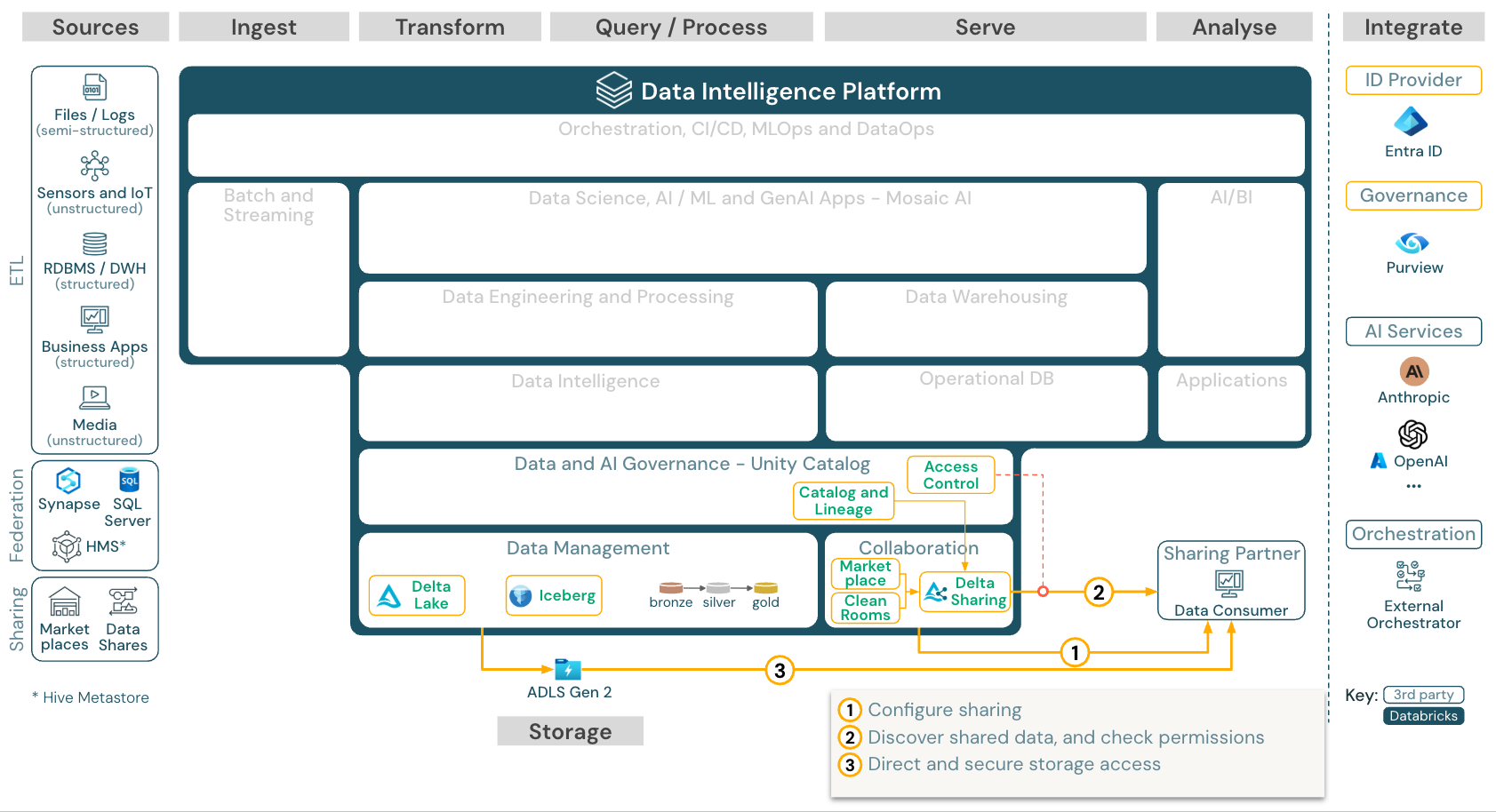
Berbagi data kelas perusahaan dengan pihak ketiga disediakan oleh Berbagi Delta. Ini memungkinkan akses langsung ke data di penyimpanan objek yang diamankan oleh Katalog Unity. Kemampuan ini juga digunakan di Databricks Marketplace, forum terbuka untuk bertukar produk data.
Menggunakan data yang dibagikan dari Databricks
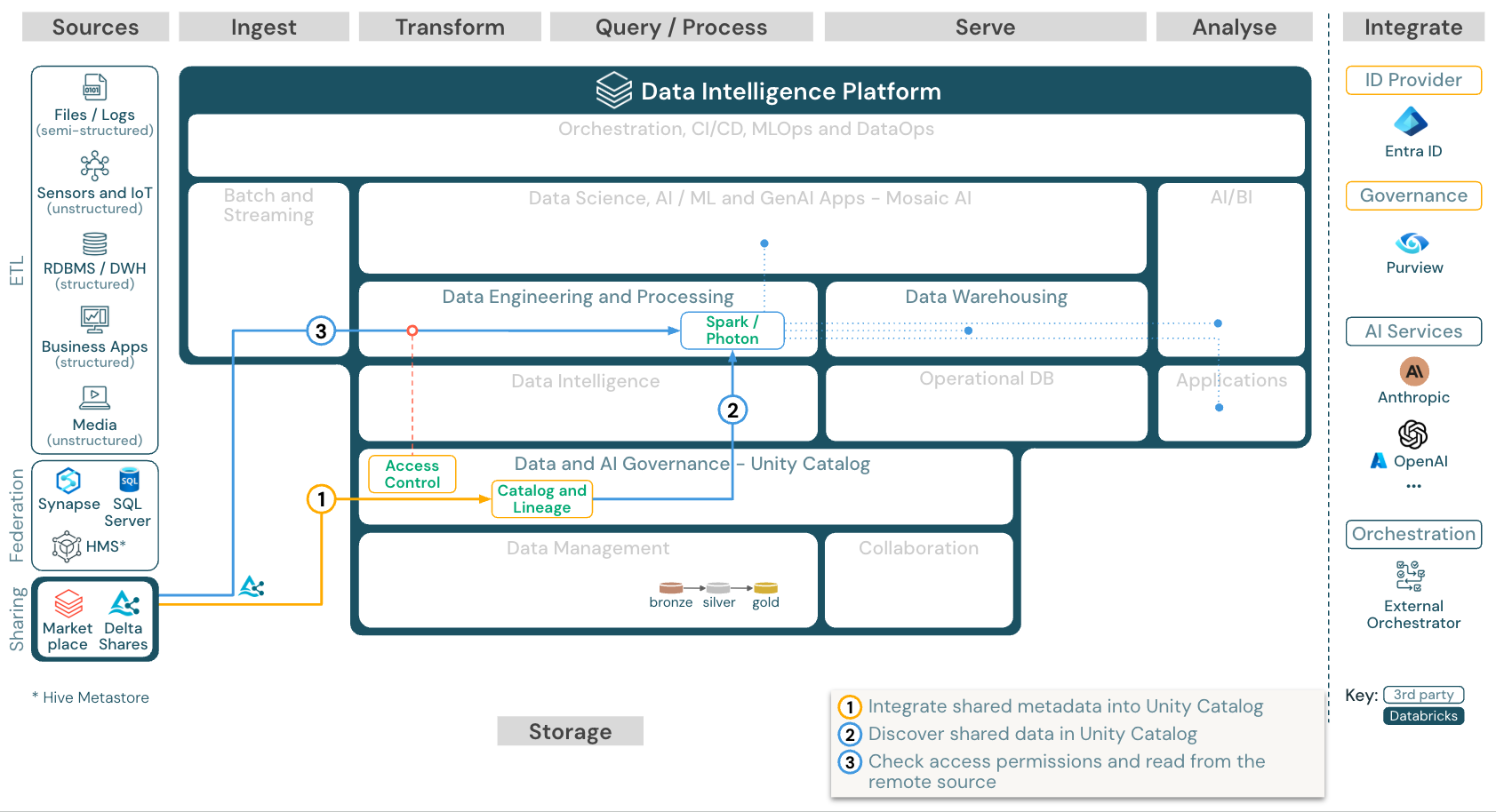
Unduh: Memanfaatkan data yang dibagikan dari arsitektur referensi Databricks untuk Azure Databricks
Protokol Delta Sharing Databricks-to-Databricks memungkinkan pengguna untuk berbagi data dengan aman dengan pengguna Databricks apa pun, terlepas dari akun atau host cloud, selama pengguna tersebut memiliki akses ke ruang kerja yang diaktifkan untuk Unity Catalog.