Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Suara kustom adalah fitur teks ke ucapan yang memungkinkan Anda membuat suara sintetis yang unik, disesuaikan untuk aplikasi Anda. Dengan suara kustom, Anda dapat membangun suara yang sangat terdengar alami untuk merek atau karakter Anda dengan menyediakan sampel ucapan manusia sebagai data penyempurnaan.
Penting
Akses suara kustom dibatasi berdasarkan kriteria kelayakan dan penggunaan. Minta akses pada formulir intake.
Di luar kotak, teks ke ucapan dapat digunakan dengan suara standar untuk setiap bahasa yang didukung. Suara standar berfungsi dengan baik di sebagian besar skenario teks ke ucapan jika suara unik tidak diperlukan.
Suara Kustom didasarkan pada teknologi teks-ke-ucapan berbasis jaringan saraf dan model universal, multibahasa, multi-pembicara. Anda dapat membuat suara sintetis yang kaya akan gaya berbicara, atau bahasa lintas bahasa yang dapat disesuaikan. Suara suara kustom yang realistis dan terdengar alami dapat mewakili merek, memperorangkan mesin, dan memungkinkan pengguna untuk berinteraksi dengan aplikasi secara percakapan. Lihat bahasa yang didukung untuk suara kustom.
Bagaimana cara kerjanya?
Untuk membuat suara kustom, gunakan Speech Studio untuk mengunggah audio yang direkam dan skrip terkait, melatih model, dan menyebarkan suara ke titik akhir kustom.
Membuat suara kustom yang hebat membutuhkan kontrol kualitas yang cermat di setiap langkah, mulai dari desain suara dan persiapan data, hingga penyebaran model suara ke sistem Anda.
Sebelum Anda memulai di Speech Studio, berikut adalah beberapa pertimbangan:
- Rancang persona suara yang mewakili merek Anda dengan menggunakan dokumen singkat persona. Dokumen ini menentukan elemen seperti fitur suara, dan karakter di balik suara. Ini membantu memandu proses pembuatan model suara kustom, termasuk menentukan skrip, memilih bakat suara, pelatihan, dan penyetelan suara Anda.
- Pilih skrip rekaman untuk mewakili skenario pengguna untuk suara Anda. Misalnya, Anda dapat menggunakan frasa dari percakapan bot sebagai skrip rekaman jika membuat bot layanan pelanggan. Sertakan berbagai jenis kalimat dalam skrip Anda, termasuk pernyataan, pertanyaan, dan seruan.
Berikut adalah gambaran umum langkah-langkah untuk membuat suara kustom di Speech Studio:
- Buat proyek untuk berisi data, model suara, pengujian, dan titik akhir Anda. Setiap proyek khusus untuk negara/wilayah dan bahasa. Jika Anda akan membuat beberapa suara, disarankan agar Anda membuat proyek untuk setiap suara.
- Menyiapkan bakat suara. Sebelum dapat menyempurnakan suara profesional, Anda harus mengirimkan rekaman pernyataan persetujuan bakat suara. Pernyataan bakat suara adalah rekaman bakat suara membaca pernyataan bahwa mereka menyetujui penggunaan data ucapan mereka untuk penyempurnaan suara profesional.
- Siapkan data penyempurnaan dalam format yang tepat. Sebaiknya ambil rekaman audio di studio rekaman berkualitas profesional untuk mencapai rasio sinyal-ke-kebisingan yang tinggi. Kualitas model suara sangat bergantung pada data penyempurnaan Anda. Volume yang konsisten, kecepatan berbicara, nada suara, dan konsistensi dalam tingkah laku ekspresif diperlukan.
- Latih model suara Anda. Pilih setidaknya 300 ucapan untuk membuat suara kustom. Serangkaian pemeriksaan kualitas data dilakukan secara otomatis saat Anda mengunggahnya. Untuk membangun model suara berkualitas tinggi, Anda harus memperbaiki kesalahan yang ada dan mengirimkannya lagi.
- Uji suara Anda. Siapkan skrip pengujian untuk model suara Anda yang mencakup berbagai kasus penggunaan untuk aplikasi. Sebaiknya gunakan skrip di dalam dan di luar himpunan data pelatihan, sehingga Anda dapat menguji kualitas secara lebih luas untuk konten yang berbeda.
- Sebarkan dan gunakan model suara Anda di aplikasi Anda.
Anda dapat menyetel, menyesuaikan, dan menggunakan suara kustom Anda, sama seperti Anda akan menggunakan suara standar. Konversi teks menjadi ucapan secara real time, atau hasilkan konten audio offline dengan input teks. Anda menggunakan REST API, Speech SDK, atau Speech Studio.
Petunjuk / Saran
Lihat sampel kode di repositori Speech SDK di GitHub untuk melihat cara menggunakan suara kustom di aplikasi Anda.
Gaya dan karakteristik model suara yang dilatih tergantung pada gaya dan kualitas rekaman dari pengisi suara yang digunakan untuk pelatihan. Namun, Anda dapat melakukan beberapa penyesuaian dengan menggunakan SSML (Speech Synthesis Markup Language) saat Anda membuat panggilan API ke model suara untuk menghasilkan ucapan sintetis. SSML adalah bahasa markup yang digunakan untuk berkomunikasi dengan layanan teks ke ucapan untuk mengonversi teks menjadi audio. Penyesuaian tersebut meliputi perubahan nada, laju, intonasi, dan koreksi pengucapan. Jika model suara dibuat dengan beberapa gaya, Anda juga dapat menggunakan SSML untuk mengganti gaya.
Urutan komponen
Suara kustom terdiri dari tiga komponen utama: penganalisis teks, model akustik neural, dan vocoder neural. Untuk menghasilkan ucapan sintetis alami dari teks, teks terlebih dahulu dimasukkan ke dalam penganalisis teks, yang memberikan output berupa urutan fonem. Fonem adalah satuan dasar bunyi yang membedakan satu kata dengan kata lain dalam bahasa tertentu. Urutan fonem mendefinisikan pengucapan kata-kata yang disediakan dalam teks.
Selanjutnya, urutan fonem masuk ke model akustik neural untuk memprediksi fitur akustik yang menentukan sinyal ucapan. Fitur akustik meliputi timbre, gaya berbicara, kecepatan, intonasi, dan pola penekanan. Terakhir, vocoder neural mengubah fitur akustik menjadi gelombang yang dapat didengar, sehingga menghasilkan suara sintetis.
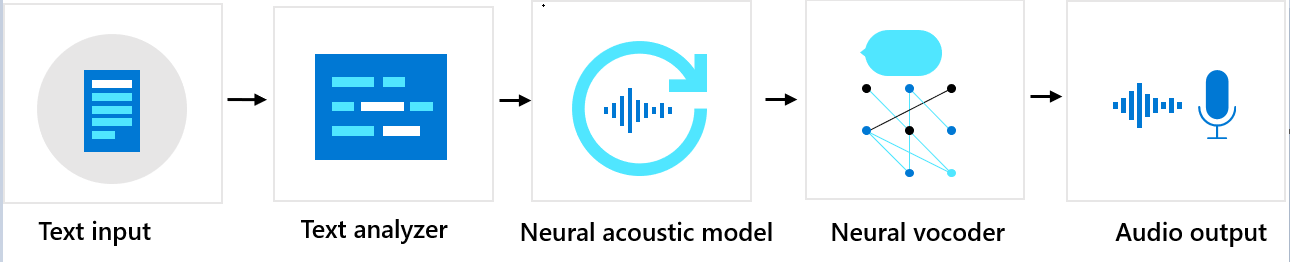
Model suara teks ke ucapan neural dilatih dengan menggunakan jaringan neural mendalam berdasarkan sampel rekaman suara manusia. Untuk informasi selengkapnya, lihat posting blog Microsoft ini. Untuk mempelajari selengkapnya tentang cara melatih vocoder neural, lihat posting blog Microsoft ini.
AI yang Bertanggung Jawab
Sistem AI tidak hanya mencakup teknologi, tetapi juga orang-orang yang menggunakannya, orang-orang yang terpengaruh olehnya, dan lingkungan tempatnya disebarkan. Baca catatan transparansi untuk mempelajari tentang penggunaan dan penyebaran AI yang bertanggung jawab di sistem Anda.
- Catatan transparansi dan kasus penggunaan untuk suara kustom
- Karakteristik dan batasan untuk menggunakan suara kustom
- Akses terbatas ke suara kustom
- Panduan untuk penyebaran teknologi suara sintetis yang bertanggung jawab
- Pengungkapan untuk bakat suara
- Panduan desain pengungkapan
- Pola desain pengungkapan
- Kode Etik untuk integrasi Teks ke ucapan
- Data, privasi, dan keamanan untuk suara kustom