Tutorial: Bagian 3 - Mengevaluasi aplikasi obrolan kustom dengan Azure AI Foundry SDK
Dalam tutorial ini, Anda menggunakan Azure AI SDK (dan pustaka lainnya) untuk mengevaluasi aplikasi obrolan yang Anda buat di Bagian 2 dari seri tutorial. Di bagian tiga ini, Anda mempelajari cara:
- Membuat himpunan data evaluasi
- Mengevaluasi aplikasi obrolan dengan evaluator Azure AI
- Iterasi dan tingkatkan aplikasi Anda
Tutorial ini adalah bagian ketiga dari tutorial tiga bagian.
Prasyarat
- Lengkapi bagian 2 dari seri tutorial untuk membangun aplikasi obrolan.
- Pastikan Anda telah menyelesaikan langkah-langkah untuk menambahkan pengelogan telemetri dari bagian 2.
Mengevaluasi kualitas respons aplikasi obrolan
Sekarang setelah Anda mengetahui aplikasi obrolan merespons dengan baik kueri Anda, termasuk dengan riwayat obrolan, saatnya untuk mengevaluasi bagaimana hal itu di beberapa metrik yang berbeda dan lebih banyak data.
Anda menggunakan evaluator dengan himpunan data evaluasi dan get_chat_response() fungsi target, lalu menilai hasil evaluasi.
Setelah menjalankan evaluasi, Anda kemudian dapat melakukan penyempurnaan pada logika Anda, seperti meningkatkan permintaan sistem Anda, dan mengamati bagaimana respons aplikasi obrolan berubah dan meningkat.
Membuat himpunan data evaluasi
Gunakan himpunan data evaluasi berikut, yang berisi contoh pertanyaan dan jawaban yang diharapkan (kebenaran).
Buat file bernama chat_eval_data.jsonl di folder aset Anda.
Tempelkan himpunan data ini ke dalam file:
{"query": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"query": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"query": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"query": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"query": "What brand is TrailMaster tent? ", "truth": "OutdoorLiving"} {"query": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"query": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"query": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"query": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"query": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"query": "How long are the TrailBlaze pants under warranty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"query": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"query": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
Mengevaluasi dengan evaluator Azure AI
Sekarang tentukan skrip evaluasi yang akan:
- Hasilkan pembungkus fungsi target di sekitar logika aplikasi obrolan kami.
- Muat himpunan data sampel
.jsonl. - Jalankan evaluasi, yang mengambil fungsi target, dan menggabungkan himpunan data evaluasi dengan respons dari aplikasi obrolan.
- Hasilkan satu set metrik yang dibantu GPT (relevansi, groundedness, dan koherensi) untuk mengevaluasi kualitas respons aplikasi obrolan.
- Keluarkan hasilnya secara lokal, dan catat hasilnya ke proyek cloud.
Skrip memungkinkan Anda meninjau hasilnya secara lokal, dengan menghasilkan hasil di baris perintah, dan ke file json.
Skrip ini juga mencatat hasil evaluasi ke proyek cloud sehingga Anda dapat membandingkan eksekusi evaluasi di UI.
Buat file yang disebut evaluate.py di folder utama Anda.
Tambahkan kode berikut untuk mengimpor pustaka yang diperlukan, membuat klien proyek, dan mengonfigurasi beberapa pengaturan:
import os import pandas as pd from azure.ai.projects import AIProjectClient from azure.ai.projects.models import ConnectionType from azure.ai.evaluation import evaluate, GroundednessEvaluator from azure.identity import DefaultAzureCredential from chat_with_products import chat_with_products # load environment variables from the .env file at the root of this repo from dotenv import load_dotenv load_dotenv() # create a project client using environment variables loaded from the .env file project = AIProjectClient.from_connection_string( conn_str=os.environ["AIPROJECT_CONNECTION_STRING"], credential=DefaultAzureCredential() ) connection = project.connections.get_default(connection_type=ConnectionType.AZURE_OPEN_AI, include_credentials=True) evaluator_model = { "azure_endpoint": connection.endpoint_url, "azure_deployment": os.environ["EVALUATION_MODEL"], "api_version": "2024-06-01", "api_key": connection.key, } groundedness = GroundednessEvaluator(evaluator_model)Tambahkan kode untuk membuat fungsi pembungkus yang mengimplementasikan antarmuka evaluasi untuk evaluasi kueri dan respons:
def evaluate_chat_with_products(query): response = chat_with_products(messages=[{"role": "user", "content": query}]) return {"response": response["message"].content, "context": response["context"]["grounding_data"]}Terakhir, tambahkan kode untuk menjalankan evaluasi, melihat hasilnya secara lokal, dan memberi Anda tautan ke hasil evaluasi di portal Azure AI Foundry:
# Evaluate must be called inside of __main__, not on import if __name__ == "__main__": from config import ASSET_PATH # workaround for multiprocessing issue on linux from pprint import pprint from pathlib import Path import multiprocessing import contextlib with contextlib.suppress(RuntimeError): multiprocessing.set_start_method("spawn", force=True) # run evaluation with a dataset and target function, log to the project result = evaluate( data=Path(ASSET_PATH) / "chat_eval_data.jsonl", target=evaluate_chat_with_products, evaluation_name="evaluate_chat_with_products", evaluators={ "groundedness": groundedness, }, evaluator_config={ "default": { "query": {"${data.query}"}, "response": {"${target.response}"}, "context": {"${target.context}"}, } }, azure_ai_project=project.scope, output_path="./myevalresults.json", ) tabular_result = pd.DataFrame(result.get("rows")) pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
Mengonfigurasi model evaluasi
Karena skrip evaluasi memanggil model berkali-kali, Anda mungkin ingin meningkatkan jumlah token per menit untuk model evaluasi.
Di Bagian 1 dari seri tutorial ini, Anda membuat file .env yang menentukan nama model evaluasi, gpt-4o-mini. Cobalah untuk meningkatkan batas token per menit untuk model ini, jika Anda memiliki kuota yang tersedia. Jika Anda tidak memiliki cukup kuota untuk meningkatkan nilai, jangan khawatir. Skrip dirancang untuk menangani kesalahan batas.
- Di proyek Anda di portal Azure AI Foundry, pilih Model + titik akhir.
- Pilih gpt-4o-mini.
- Pilih Edit.
- Jika Anda memiliki kuota untuk meningkatkan Token per Batas Tarif Menit, coba tingkatkan menjadi 30.
- Pilih Simpan dan Tutup.
Jalankan skrip evaluasi
Dari konsol Anda, masuk ke akun Azure Anda dengan Azure CLI:
az loginInstal paket yang diperlukan:
pip install azure-ai-evaluation[remote]Sekarang jalankan skrip evaluasi:
python evaluate.py
Menginterpretasikan output evaluasi
Dalam output konsol, Anda akan melihat jawaban untuk setiap pertanyaan, diikuti dengan tabel dengan metrik yang dirangkum. (Anda mungkin melihat kolom yang berbeda dalam output Anda.)
Jika Anda tidak dapat meningkatkan batas token per menit untuk model Anda, Anda mungkin melihat beberapa kesalahan waktu habis, yang diharapkan. Skrip evaluasi dirancang untuk menangani kesalahan ini dan terus berjalan.
Catatan
Anda mungkin juga melihat banyak WARNING:opentelemetry.attributes: - ini dapat diabaikan dengan aman dan tidak memengaruhi hasil evaluasi.
====================================================
'-----Summarized Metrics-----'
{'groundedness.gpt_groundedness': 1.6666666666666667,
'groundedness.groundedness': 1.6666666666666667}
'-----Tabular Result-----'
outputs.response ... line_number
0 Could you specify which tent you are referring... ... 0
1 Could you please specify which camping table y... ... 1
2 Sorry, I only can answer queries related to ou... ... 2
3 Could you please clarify which aspects of care... ... 3
4 Sorry, I only can answer queries related to ou... ... 4
5 The TrailMaster X4 Tent comes with an included... ... 5
6 (Failed) ... 6
7 The TrailBlaze Hiking Pants are crafted from h... ... 7
8 Sorry, I only can answer queries related to ou... ... 8
9 Sorry, I only can answer queries related to ou... ... 9
10 Sorry, I only can answer queries related to ou... ... 10
11 The PowerBurner Camping Stove is designed with... ... 11
12 Sorry, I only can answer queries related to ou... ... 12
[13 rows x 8 columns]
('View evaluation results in Azure AI Foundry portal: '
'https://xxxxxxxxxxxxxxxxxxxxxxx')
Menampilkan hasil evaluasi di portal Azure AI Foundry
Setelah proses evaluasi selesai, ikuti tautan untuk melihat hasil evaluasi pada halaman Evaluasi di portal Azure AI Foundry.

Anda juga dapat melihat baris individual dan melihat skor metrik per baris, dan melihat konteks/dokumen lengkap yang diambil. Metrik ini dapat membantu dalam menafsirkan dan men-debug hasil evaluasi.
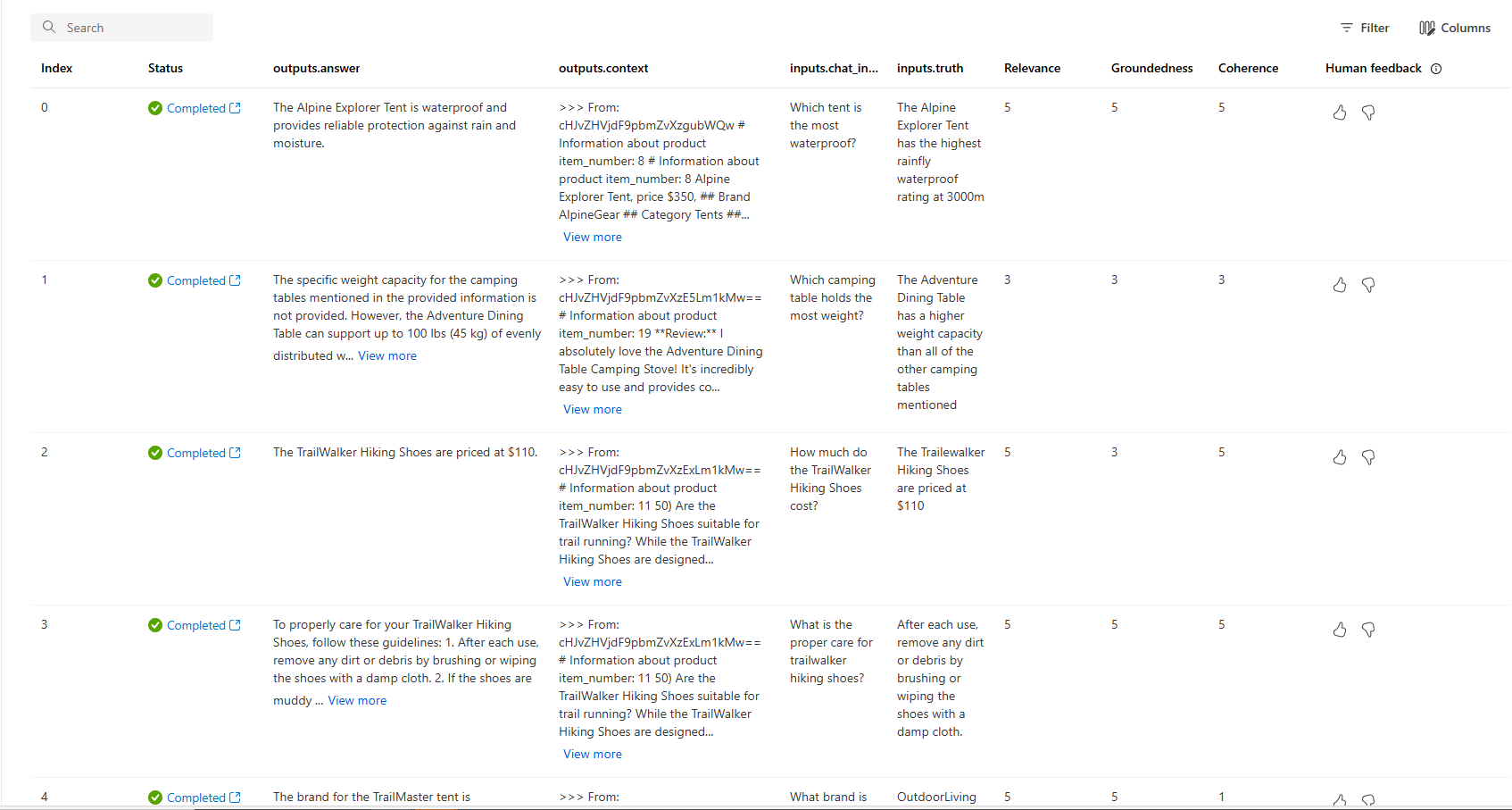
Untuk informasi selengkapnya tentang hasil evaluasi di portal Azure AI Foundry, lihat Cara melihat hasil evaluasi di portal Azure AI Foundry.
Iterasi dan tingkatkan
Perhatikan bahwa respons tidak di-grounded dengan baik. Dalam banyak kasus, model membalas dengan pertanyaan daripada jawaban. Ini adalah hasil dari instruksi templat perintah.
- Dalam file aset/grounded_chat.prompty Anda, temukan kalimat "Jika pertanyaan terkait dengan perlengkapan dan pakaian luar ruangan/berkemah tetapi tidak jelas, mintalah klarifikasi pertanyaan alih-alih merujuk dokumen."
- Ubah kalimat menjadi "Jika pertanyaan terkait dengan roda gigi dan pakaian luar ruangan/berkemah tetapi samar- samar, coba jawab berdasarkan dokumen referensi, lalu mintalah klarifikasi pertanyaan."
- Simpan file dan jalankan kembali skrip evaluasi.
Coba modifikasi lain pada templat perintah, atau coba model yang berbeda, untuk melihat bagaimana perubahan memengaruhi hasil evaluasi.
Membersihkan sumber daya
Untuk menghindari timbulnya biaya Azure yang tidak perlu, Anda harus menghapus sumber daya yang Anda buat dalam tutorial ini jika tidak lagi diperlukan. Untuk mengelola sumber daya, Anda dapat menggunakan portal Azure.