Tutorial: Bagian 1 - Membangun salinan berbasis RAG dengan SDK alur prompt
Dalam tutorial Azure AI Studio ini, Anda menggunakan SDK alur permintaan (dan pustaka lainnya) untuk membangun, mengonfigurasi, mengevaluasi, dan menyebarkan salinan untuk perusahaan ritel Anda yang disebut Contoso Trek. Perusahaan ritel Anda memiliki spesialisasi perlengkapan berkemah luar ruangan dan pakaian. Salinan harus menjawab pertanyaan tentang produk dan layanan Anda. Misalnya, salinan dapat menjawab pertanyaan seperti "tenda mana yang paling tahan air?" atau "apa kantong tidur terbaik untuk cuaca dingin?".
Tutorial ini adalah bagian salah satu dari tutorial dua bagian.
Tip
Pastikan untuk menyisihkan cukup waktu untuk menyelesaikan prasyarat sebelum memulai tutorial ini. Jika Anda baru menggunakan Azure AI Studio, Anda mungkin perlu menghabiskan waktu tambahan untuk membiasakan diri dengan platform.
Bagian satu ini menunjukkan kepada Anda cara meningkatkan aplikasi obrolan dasar dengan menambahkan pengambilan augmented generation (RAG) untuk membumikan respons dalam data kustom Anda.
Di bagian satu ini, Anda mempelajari cara:
Prasyarat
Penting
Anda harus memiliki izin yang diperlukan untuk menambahkan penetapan peran di langganan Azure Anda. Memberikan izin berdasarkan penetapan peran hanya diizinkan oleh Pemilik sumber daya Azure tertentu. Anda mungkin perlu meminta pemilik langganan Azure Anda (yang mungkin admin TI Anda) untuk bantuan dalam menyelesaikan bagian tetapkan akses .
Anda perlu menyelesaikan mulai cepat Membangun aplikasi obrolan kustom di Python menggunakan mulai cepat SDK alur perintah untuk menyiapkan lingkungan Anda.
Penting
Tutorial ini dibangun pada kode dan lingkungan yang Anda siapkan di mulai cepat.
Anda memerlukan salinan lokal data produk. Repositori Azure-Samples/rag-data-openai-python-promptflow di GitHub berisi contoh informasi produk ritel yang relevan untuk skenario tutorial ini. Unduh contoh data produk ritel Contoso Trek dalam file ZIP ke komputer lokal Anda.
Struktur kode aplikasi
Buat folder yang disebut rag-tutorial di komputer lokal Anda. Seri tutorial ini menjelaskan pembuatan konten setiap file. Jika Anda menyelesaikan seri tutorial, struktur folder Anda terlihat seperti ini:
rag-tutorial/
│ .env
│ build_index.py
│ deploy.py
│ evaluate.py
│ eval_dataset.jsonl
| invoke-local.py
│
├───copilot_flow
│ └─── chat.prompty
| └─── copilot.py
| └─── Dockerfile
│ └─── flow.flex.yaml
│ └─── input_with_chat_history.json
│ └─── queryIntent.prompty
│ └─── requirements.txt
│
├───data
| └─── product-info/
| └─── [Your own data or sample data as described in the prerequisites.]
Implementasi dalam tutorial ini menggunakan alur fleksibel alur prompt, yang merupakan pendekatan code-first untuk mengimplementasikan alur. Anda menentukan fungsi entri (yang akan ditentukan dalam copilot.py), lalu menggunakan kemampuan pengujian, evaluasi, dan pelacakan alur prompt untuk alur Anda. Alur ini dalam kode dan tidak memiliki DAG (Directed Acyclic Graph) atau komponen visual lainnya. Pelajari selengkapnya tentang cara mengembangkan alur fleksibel dalam dokumentasi alur perintah di GitHub.
Mengatur variabel lingkungan awal
Ada kumpulan variabel lingkungan yang digunakan di berbagai cuplikan kode. Ayo kita atur sekarang.
Anda membuat file .env dengan variabel lingkungan berikut melalui mulai cepat Membangun aplikasi obrolan kustom di Python menggunakan mulai cepat SDK alur perintah. Jika Anda belum melakukannya, buat file .env di folder rag-tutorial Anda dengan variabel lingkungan berikut:
AZURE_OPENAI_ENDPOINT=endpoint_value AZURE_OPENAI_DEPLOYMENT_NAME=chat_model_deployment_name AZURE_OPENAI_API_VERSION=api_versionSalin file .env ke folder rag-tutorial Anda.
Dalam file .env masukkan lebih banyak variabel lingkungan untuk aplikasi salinan:
- AZURE_SUBSCRIPTION_ID: ID langganan Azure Anda
- AZURE_RESOURCE_GROUP: Grup sumber daya Azure Anda
- AZUREAI_PROJECT_NAME: Nama proyek Azure AI Studio Anda
- AZURE_OPENAI_CONNECTION_NAME: Gunakan AIServices atau koneksi Azure OpenAI yang sama dengan yang Anda gunakan untuk menyebarkan model obrolan.
Anda dapat menemukan ID langganan, nama grup sumber daya, dan nama proyek dari tampilan proyek Anda di AI Studio.
- Di AI Studio, buka proyek Anda dan pilih Pengaturan dari panel kiri.
- Di bagian Detail proyek, Anda bisa menemukan ID Langganan dan Grup sumber daya.
- Di bagian Pengaturan proyek, Anda dapat menemukan Nama proyek.
Sekarang, Anda harus memiliki variabel lingkungan berikut dalam file .env Anda:
AZURE_OPENAI_ENDPOINT=endpoint_value
AZURE_OPENAI_DEPLOYMENT_NAME=chat_model_deployment_name
AZURE_OPENAI_API_VERSION=api_version
AZURE_SUBSCRIPTION_ID=<your subscription id>
AZURE_RESOURCE_GROUP=<your resource group>
AZUREAI_PROJECT_NAME=<your project name>
AZURE_OPENAI_CONNECTION_NAME=<your AIServices or Azure OpenAI connection name>
Menyebarkan model penyematan
Untuk kemampuan pembuatan tertambah pengambilan (RAG), kita harus dapat menyematkan kueri pencarian untuk mencari indeks Pencarian Azure AI yang kita buat.
Menyebarkan model penyematan Azure OpenAI. Ikuti panduan sebarkan model Azure OpenAI dan sebarkan model text-embedding-ada-002. Gunakan koneksi AIServices atau Azure OpenAI yang sama dengan yang Anda gunakan untuk menyebarkan model obrolan.
Tambahkan variabel lingkungan model penyematan dalam file .env Anda. Untuk nilai AZURE_OPENAI_EMBEDDING_DEPLOYMENT, masukkan nama model penyematan yang Anda sebarkan.
AZURE_OPENAI_EMBEDDING_DEPLOYMENT=embedding_model_deployment_name
Untuk informasi selengkapnya tentang model penyematan, lihat dokumentasi penyematan Azure OpenAI Service.
Membuat indeks Pencarian Azure AI
Tujuan dengan aplikasi berbasis RAG ini adalah untuk membumikan respons model dalam data kustom Anda. Anda menggunakan indeks Azure AI Search yang menyimpan data vektor dari model penyematan. Indeks pencarian digunakan untuk mengambil dokumen yang relevan berdasarkan pertanyaan pengguna.
Anda memerlukan layanan Pencarian dan koneksi Azure AI untuk membuat indeks pencarian.
Catatan
Membuat layanan Pencarian Azure AI dan indeks pencarian berikutnya memiliki biaya terkait. Anda dapat melihat detail tentang tingkat harga dan harga untuk azure AI layanan Pencarian di halaman pembuatan, untuk mengonfirmasi biaya sebelum membuat sumber daya.
Membuat layanan Pencarian Azure AI
Jika Anda sudah memiliki azure AI layanan Pencarian di lokasi yang sama dengan proyek, Anda dapat melompat ke bagian berikutnya.
Jika tidak, Anda dapat membuat azure AI layanan Pencarian menggunakan portal Azure atau Azure CLI (yang Anda instal sebelumnya untuk mulai cepat).
Penting
Gunakan lokasi yang sama dengan proyek Anda untuk layanan Pencarian Azure AI. Temukan lokasi proyek Anda di pemilih proyek kanan atas Azure AI Studio dalam tampilan proyek.
- Buka portal Microsoft Azure.
- Buat layanan Pencarian Azure AI di portal Azure.
- Pilih grup sumber daya dan detail instans Anda. Anda dapat melihat detail tentang tingkat harga dan harga di halaman ini.
- Lanjutkan melalui wizard dan pilih Tinjau + tetapkan untuk membuat sumber daya.
- Konfirmasikan detail layanan Pencarian Azure AI Anda, termasuk perkiraan biaya.
Membuat koneksi Azure AI Search
Jika Anda sudah memiliki koneksi Azure AI Search di proyek, Anda dapat melompat untuk mengonfigurasi akses untuk azure AI layanan Pencarian. Hanya gunakan koneksi yang ada jika berada di lokasi yang sama dengan proyek Anda.
Di Azure AI Studio, periksa sumber daya yang tersambung dengan Azure AI Search.
- Di AI Studio, buka proyek Anda dan pilih Pengaturan dari panel kiri.
- Di bagian Sumber daya tersambung, lihat untuk melihat apakah Anda memiliki koneksi jenis Azure AI Search.
- Jika Anda memiliki koneksi Azure AI Search, verifikasi bahwa koneksi tersebut berada di lokasi yang sama dengan proyek Anda. Jika demikian, Anda dapat melompat ke depan untuk mengonfigurasi akses untuk layanan Pencarian Azure AI.
- Jika tidak, pilih Koneksi baru lalu Pencarian Azure AI.
- Temukan layanan Pencarian Azure AI Anda di opsi dan pilih Tambahkan koneksi.
- Lanjutkan melalui wizard untuk membuat koneksi. Untuk informasi selengkapnya tentang menambahkan koneksi, lihat panduan cara penggunaan ini.
Mengonfigurasi akses untuk layanan Pencarian Azure AI
Sebaiknya gunakan ID Microsoft Entra alih-alih menggunakan kunci API. Untuk menggunakan autentikasi ini, Anda perlu mengatur kontrol akses yang tepat dan menetapkan peran yang tepat untuk layanan Pencarian Azure AI Anda.
Peringatan
Anda dapat menggunakan kontrol akses berbasis peran secara lokal karena Anda menjalankannya az login nanti dalam tutorial ini. Tetapi saat Anda menyebarkan aplikasi di bagian 2 tutorial, penyebaran diautentikasi menggunakan kunci API dari layanan Pencarian Azure AI Anda. Dukungan untuk autentikasi MICROSOFT Entra ID penyebaran akan segera hadir.
Untuk mengaktifkan kontrol akses berbasis peran untuk layanan Pencarian Azure AI Anda, ikuti langkah-langkah berikut:
Di layanan Pencarian Azure AI Anda di portal Azure, pilih Tombol Pengaturan > dari panel kiri.
Pilih Keduanya untuk memastikan bahwa kunci API dan kontrol akses berbasis peran diaktifkan untuk layanan Pencarian Azure AI Anda.
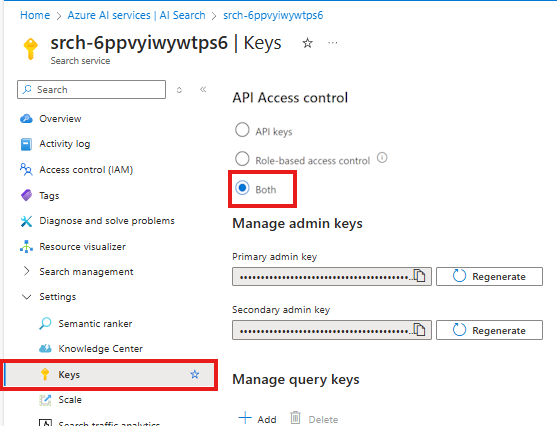
Anda atau administrator Anda perlu memberikan identitas pengguna Anda peran Kontributor Data Indeks Pencarian dan Kontributor Layanan Pencarian di layanan Pencarian Azure AI Anda. Peran ini memungkinkan Anda memanggil azure AI layanan Pencarian menggunakan identitas pengguna Anda.
Catatan
Langkah-langkah ini mirip dengan cara Anda menetapkan peran untuk identitas pengguna Anda untuk menggunakan Layanan Azure OpenAI di mulai cepat.
Di portal Azure, ikuti langkah-langkah ini untuk menetapkan peran Kontributor Data Indeks Pencarian ke layanan Pencarian Azure AI Anda:
- Pilih layanan Pencarian Azure AI Anda di portal Azure.
- Dari halaman kiri di portal Azure, pilih Kontrol akses (IAM)>+ Tambahkan>penetapan peran.
- Cari peran Kontributor Data Indeks Pencarian lalu pilih. Kemudian pilih Berikutnya.
- Pilih Pengguna, grup, atau perwakilan layanan. Lalu pilih Pilih anggota.
- Di panel Pilih anggota yang terbuka, cari nama pengguna yang ingin Anda tambahkan penetapan perannya. Pilih pengguna lalu pilih Pilih.
- Lanjutkan melalui wizard dan pilih Tinjau + tetapkan untuk menambahkan penetapan peran.
Ulangi langkah-langkah sebelumnya untuk menambahkan peran Kontributor Layanan Pencarian.
Penting
Setelah Anda menetapkan peran ini, jalankan az login di konsol Anda untuk memastikan perubahan disebarluaskan di lingkungan pengembangan Anda. Ini juga memastikan bahwa Anda dapat menggunakan identitas pengguna secara lokal untuk mengautentikasi dengan azure AI layanan Pencarian.
Mengatur variabel lingkungan pencarian
Anda perlu mengatur variabel lingkungan untuk azure AI layanan Pencarian dan koneksi dalam file .env Anda.
Di AI Studio, buka proyek Anda dan pilih Pengaturan dari panel kiri.
Di bagian Sumber daya tersambung, pilih tautan untuk azure AI layanan Pencarian yang Anda buat sebelumnya.
Salin URL Target untuk
<your Azure Search endpoint>.Salin nama di bagian atas untuk
<your Azure Search connection name>.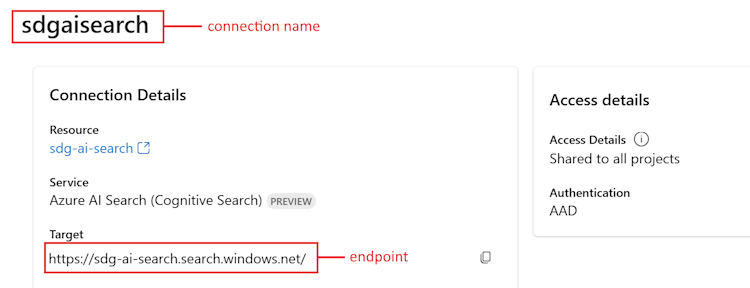
Tambahkan variabel lingkungan ini ke file .env Anda:
AZURE_SEARCH_ENDPOINT=<your Azure Search endpoint> AZURE_SEARCH_CONNECTION_NAME=<your Azure Search connection name>
Membuat indeks pencarian
Jika Anda belum membuat indeks Azure AI Search, kami akan membahas cara membuatnya. Jika Anda sudah memiliki indeks untuk digunakan, Anda dapat melompat ke bagian atur variabel lingkungan pencarian. Indeks pencarian dibuat pada layanan Pencarian Azure AI yang dibuat atau direferensikan di langkah sebelumnya.
Gunakan data Anda sendiri atau unduh contoh data produk ritel Contoso Trek dalam file ZIP ke komputer lokal Anda. Unzip file ke folder rag-tutorial Anda. Data ini adalah kumpulan file markdown yang mewakili informasi produk. Data disusun dengan cara yang mudah diserap ke dalam indeks pencarian. Anda membangun indeks pencarian dari data ini.
Paket RAG alur perintah memungkinkan Anda untuk menyerap file markdown, membuat indeks pencarian secara lokal, dan mendaftarkannya di proyek cloud. Instal paket RAG alur prompt:
pip install promptflow-ragTingkatkan paket azure-ai-ml ke versi terbaru. Jalankan perintah berikut di terminal Anda:
pip install azure-ai-ml -UBuat file build_index.py di folder rag-tutorial Anda.
Salin dan tempel kode berikut ke dalam file build_index.py Anda.
import os from dotenv import load_dotenv load_dotenv() from azure.ai.ml import MLClient from azure.identity import DefaultAzureCredential from azure.ai.ml.entities import Index from promptflow.rag.config import ( LocalSource, AzureAISearchConfig, EmbeddingsModelConfig, ConnectionConfig, ) from promptflow.rag import build_index client = MLClient( DefaultAzureCredential(), os.getenv("AZURE_SUBSCRIPTION_ID"), os.getenv("AZURE_RESOURCE_GROUP"), os.getenv("AZUREAI_PROJECT_NAME"), ) import os # append directory of the current script to data directory script_dir = os.path.dirname(os.path.abspath(__file__)) data_directory = os.path.join(script_dir, "data/product-info/") # Check if the directory exists if os.path.exists(data_directory): files = os.listdir(data_directory) # List all files in the directory if files: print( f"Data directory '{data_directory}' exists and contains {len(files)} files." ) else: print(f"Data directory '{data_directory}' exists but is empty.") exit() else: print(f"Data directory '{data_directory}' does not exist.") exit() index_name = "tutorial-index" # your desired index name index_path = build_index( name=index_name, # name of your index vector_store="azure_ai_search", # the type of vector store - in this case it is Azure AI Search. Users can also use "azure_cognitive search" embeddings_model_config=EmbeddingsModelConfig( model_name=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT"), deployment_name=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT"), connection_config=ConnectionConfig( subscription_id=client.subscription_id, resource_group_name=client.resource_group_name, workspace_name=client.workspace_name, connection_name=os.getenv("AZURE_OPENAI_CONNECTION_NAME"), ), ), input_source=LocalSource(input_data=data_directory), # the location of your files index_config=AzureAISearchConfig( ai_search_index_name=index_name, # the name of the index store inside the azure ai search service ai_search_connection_config=ConnectionConfig( subscription_id=client.subscription_id, resource_group_name=client.resource_group_name, workspace_name=client.workspace_name, connection_name=os.getenv("AZURE_SEARCH_CONNECTION_NAME"), ), ), tokens_per_chunk=800, # Optional field - Maximum number of tokens per chunk token_overlap_across_chunks=0, # Optional field - Number of tokens to overlap between chunks ) # register the index so that it shows up in the cloud project client.indexes.create_or_update(Index(name=index_name, path=index_path))- Atur
index_namevariabel ke nama indeks yang Anda inginkan. - Sesuai kebutuhan, Anda dapat memperbarui
path_to_datavariabel ke jalur tempat file data Anda disimpan.
Penting
Secara default, sampel kode mengharapkan struktur kode aplikasi seperti yang dijelaskan sebelumnya dalam tutorial ini. Folder
dataharus berada pada tingkat yang sama dengan build_index.py Anda dan folder yang diunduhproduct-infodengan file md di dalamnya.- Atur
Dari konsol Anda, jalankan kode untuk membangun indeks Anda secara lokal dan mendaftarkannya ke proyek cloud:
python build_index.pySetelah skrip dijalankan, Anda dapat melihat indeks yang baru dibuat di halaman Indeks proyek Azure AI Studio Anda. Untuk informasi selengkapnya, lihat Cara membuat dan menggunakan indeks vektor di Azure AI Studio.
Jika Anda menjalankan skrip lagi dengan nama indeks yang sama, skrip akan membuat versi baru dari indeks yang sama.
Mengatur variabel lingkungan indeks pencarian
Setelah Anda memiliki nama indeks yang ingin Anda gunakan (baik dengan membuat yang baru, atau merujuk yang sudah ada), tambahkan ke file .env Anda, seperti ini:
AZUREAI_SEARCH_INDEX_NAME=<index-name>
Mengembangkan kode RAG kustom
Selanjutnya Anda membuat kode kustom untuk menambahkan kemampuan retrieval augmented generation (RAG) ke aplikasi obrolan dasar. Dalam mulai cepat, Anda membuat file chat.py dan chat.prompty . Di sini Anda memperluas kode tersebut untuk menyertakan kemampuan RAG.
Salinan dengan RAG mengimplementasikan logika umum berikut:
- Membuat kueri pencarian berdasarkan niat kueri pengguna dan riwayat obrolan apa pun
- Menggunakan model penyematan untuk menyematkan kueri
- Mengambil dokumen yang relevan dari indeks pencarian, mengingat kueri
- Meneruskan konteks yang relevan ke model penyelesaian obrolan Azure OpenAI
- Mengembalikan respons dari model Azure OpenAI
Logika implementasi salinan
Logika implementasi salinan berada dalam file copilot.py . File ini berisi logika inti untuk salinan berbasis RAG.
Buat folder bernama copilot_flow di folder rag-tutorial .
Kemudian buat file yang disebut copilot.py di folder copilot_flow .
Tambahkan kode berikut ke file copilot.py :
import os from dotenv import load_dotenv load_dotenv() from promptflow.core import Prompty, AzureOpenAIModelConfiguration from promptflow.tracing import trace from openai import AzureOpenAI # <get_documents> @trace def get_documents(search_query: str, num_docs=3): from azure.identity import DefaultAzureCredential, get_bearer_token_provider from azure.search.documents import SearchClient from azure.search.documents.models import VectorizedQuery token_provider = get_bearer_token_provider( DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default" ) index_name = os.getenv("AZUREAI_SEARCH_INDEX_NAME") # retrieve documents relevant to the user's question from Cognitive Search search_client = SearchClient( endpoint=os.getenv("AZURE_SEARCH_ENDPOINT"), credential=DefaultAzureCredential(), index_name=index_name, ) aoai_client = AzureOpenAI( azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), azure_ad_token_provider=token_provider, api_version=os.getenv("AZURE_OPENAI_API_VERSION"), ) # generate a vector embedding of the user's question embedding = aoai_client.embeddings.create( input=search_query, model=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT") ) embedding_to_query = embedding.data[0].embedding context = "" # use the vector embedding to do a vector search on the index vector_query = VectorizedQuery( vector=embedding_to_query, k_nearest_neighbors=num_docs, fields="contentVector" ) results = trace(search_client.search)( search_text="", vector_queries=[vector_query], select=["id", "content"] ) for result in results: context += f"\n>>> From: {result['id']}\n{result['content']}" return context # <get_documents> from promptflow.core import Prompty, AzureOpenAIModelConfiguration from pathlib import Path from typing import TypedDict class ChatResponse(TypedDict): context: dict reply: str def get_chat_response(chat_input: str, chat_history: list = []) -> ChatResponse: model_config = AzureOpenAIModelConfiguration( azure_deployment=os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT"), api_version=os.getenv("AZURE_OPENAI_API_VERSION"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), ) searchQuery = chat_input # Only extract intent if there is chat_history if len(chat_history) > 0: # extract current query intent given chat_history path_to_prompty = f"{Path(__file__).parent.absolute().as_posix()}/queryIntent.prompty" # pass absolute file path to prompty intentPrompty = Prompty.load( path_to_prompty, model={ "configuration": model_config, "parameters": { "max_tokens": 256, }, }, ) searchQuery = intentPrompty(query=chat_input, chat_history=chat_history) # retrieve relevant documents and context given chat_history and current user query (chat_input) documents = get_documents(searchQuery, 3) # send query + document context to chat completion for a response path_to_prompty = f"{Path(__file__).parent.absolute().as_posix()}/chat.prompty" chatPrompty = Prompty.load( path_to_prompty, model={ "configuration": model_config, "parameters": {"max_tokens": 256, "temperature": 0.2}, }, ) result = chatPrompty( chat_history=chat_history, chat_input=chat_input, documents=documents ) return dict(reply=result, context=documents)
File copilot.py berisi dua fungsi utama: get_documents() dan get_chat_response().
Perhatikan kedua fungsi ini memiliki @trace dekorator, yang memungkinkan Anda melihat log pelacakan alur prompt dari setiap input dan output panggilan fungsi. @trace adalah pendekatan alternatif dan diperluas untuk cara mulai cepat menunjukkan kemampuan pelacakan.
Fungsi ini get_documents() adalah inti dari logika RAG.
- Mengambil kueri pencarian dan jumlah dokumen yang akan diambil.
- Menyematkan kueri pencarian menggunakan model penyematan.
- Mengkueri indeks Azure Search untuk mengambil dokumen yang relevan dengan kueri.
- Mengembalikan konteks dokumen.
Fungsi ini get_chat_response() dibangun dari logika sebelumnya dalam file chat.py Anda:
- Mengambil di
chat_inputdan apa punchat_history. - Membuat kueri pencarian berdasarkan
chat_inputniat danchat_history. get_documents()Panggilan untuk mengambil dokumen yang relevan.- Memanggil model penyelesaian obrolan dengan konteks untuk mendapatkan respons dasar terhadap kueri.
- Mengembalikan balasan dan konteks. Kami menetapkan kamus yang ditik sebagai objek pengembalian untuk fungsi kami
get_chat_response(). Anda dapat memilih bagaimana kode Anda mengembalikan respons agar paling sesuai dengan kasus penggunaan Anda.
Fungsi ini get_chat_response() menggunakan dua Prompty file untuk melakukan panggilan Model Bahasa Besar (LLM) yang diperlukan, yang kami bahas berikutnya.
Templat perintah untuk obrolan
File chat.prompty sederhana, dan mirip dengan chat.prompty di mulai cepat. Permintaan sistem diperbarui untuk mencerminkan produk kami dan templat prompt menyertakan konteks dokumen.
Tambahkan file chat.prompty di direktori copilot_flow . File mewakili panggilan ke model penyelesaian obrolan, dengan perintah sistem, riwayat obrolan, dan konteks dokumen yang disediakan.
Tambahkan kode ini ke file chat.prompty :
--- name: Chat Prompt description: A prompty that uses the chat API to respond to queries grounded in relevant documents model: api: chat configuration: type: azure_openai inputs: chat_input: type: string chat_history: type: list is_chat_history: true default: [] documents: type: object --- system: You are an AI assistant helping users with queries related to outdoor outdooor/camping gear and clothing. If the question is not related to outdoor/camping gear and clothing, just say 'Sorry, I only can answer queries related to outdoor/camping gear and clothing. So, how can I help?' Don't try to make up any answers. If the question is related to outdoor/camping gear and clothing but vague, ask for clarifying questions instead of referencing documents. If the question is general, for example it uses "it" or "they", ask the user to specify what product they are asking about. Use the following pieces of context to answer the questions about outdoor/camping gear and clothing as completely, correctly, and concisely as possible. Do not add documentation reference in the response. # Documents {{documents}} {% for item in chat_history %} {{item.role}} {{item.content}} {% endfor %} user: {{chat_input}}
Templat perintah untuk riwayat obrolan
Karena kami menerapkan aplikasi berbasis RAG, ada beberapa logika tambahan yang diperlukan untuk mengambil dokumen yang relevan tidak hanya untuk kueri pengguna saat ini, tetapi juga dengan mempertimbangkan riwayat obrolan. Tanpa logika tambahan ini, panggilan LLM Anda akan memperhitungkan riwayat obrolan. Tetapi Anda tidak akan mengambil dokumen yang tepat untuk konteks tersebut, sehingga Anda tidak akan mendapatkan respons yang diharapkan.
Misalnya, jika pengguna mengajukan pertanyaan "apakah tahan air?", kita memerlukan sistem untuk melihat riwayat obrolan untuk menentukan apa yang dirujuk oleh kata "itu", dan menyertakan konteks tersebut ke dalam kueri pencarian untuk disematkan. Dengan cara ini, kami mengambil dokumen yang tepat untuk "itu" (mungkin Tenda Alpine Explorer) dan "biayanya."
Alih-alih meneruskan hanya kueri pengguna yang akan disematkan, kita perlu membuat kueri pencarian baru yang memperhitungkan riwayat obrolan apa pun. Kami menggunakan yang lain Prompty (yang merupakan panggilan LLM lain) dengan permintaan khusus untuk menginterpretasikan niat kueri pengguna yang diberikan riwayat obrolan, dan membuat kueri pencarian yang memiliki konteks yang diperlukan.
Buat file queryIntent.prompty di folder copilot_flow .
Masukkan kode ini untuk detail spesifik tentang format perintah dan contoh beberapa bidikan.
--- name: Chat Prompt description: A prompty that extract users query intent based on the current_query and chat_history of the conversation model: api: chat configuration: type: azure_openai inputs: query: type: string chat_history: type: list is_chat_history: true default: [] --- system: - You are an AI assistant reading a current user query and chat_history. - Given the chat_history, and current user's query, infer the user's intent expressed in the current user query. - Once you infer the intent, respond with a search query that can be used to retrieve relevant documents for the current user's query based on the intent - Be specific in what the user is asking about, but disregard parts of the chat history that are not relevant to the user's intent. Example 1: With a chat_history like below: \``` chat_history: [ { "role": "user", "content": "are the trailwalker shoes waterproof?" }, { "role": "assistant", "content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions." } ] \``` User query: "how much do they cost?" Intent: "The user wants to know how much the Trailwalker Hiking Shoes cost." Search query: "price of Trailwalker Hiking Shoes" Example 2: With a chat_history like below: \``` chat_history: [ { "role": "user", "content": "are the trailwalker shoes waterproof?" }, { "role": "assistant", "content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions." }, { "role": "user", "content": "how much do they cost?" }, { "role": "assistant", "content": "The TrailWalker Hiking Shoes are priced at $110." }, { "role": "user", "content": "do you have waterproof tents?" }, { "role": "assistant", "content": "Yes, we have waterproof tents available. Can you please provide more information about the type or size of tent you are looking for?" }, { "role": "user", "content": "which is your most waterproof tent?" }, { "role": "assistant", "content": "Our most waterproof tent is the Alpine Explorer Tent. It is designed with a waterproof material and has a rainfly with a waterproof rating of 3000mm. This tent provides reliable protection against rain and moisture." } ] \``` User query: "how much does it cost?" Intent: "the user would like to know how much the Alpine Explorer Tent costs" Search query: "price of Alpine Explorer Tent" {% for item in chat_history %} {{item.role}} {{item.content}} {% endfor %} Current user query: {{query}} Search query:
Pesan sistem sederhana dalam file queryIntent.prompty kami mencapai minimum yang diperlukan agar solusi RAG berfungsi dengan riwayat obrolan.
Mengonfigurasi paket yang diperlukan
Buat requirements.txt file di folder copilot_flow. Tambahkan konten ini:
openai
azure-identity
azure-search-documents==11.4.0
promptflow[azure]==1.11.0
promptflow-tracing==1.11.0
promptflow-tools==1.4.0
promptflow-evals==0.3.0
jinja2
aiohttp
python-dotenv
Ini adalah paket yang diperlukan agar alur berjalan secara lokal dan di lingkungan yang disebarkan.
Gunakan aliran fleksibel
Seperti yang disebutkan sebelumnya, implementasi ini menggunakan alur fleksibel alur prompt, yang merupakan pendekatan code-first untuk mengimplementasikan alur. Anda menentukan fungsi entri (yang ditentukan dalam copilot.py). Pelajari lebih lanjut di Mengembangkan alur fleksibel.
Yaml ini menentukan fungsi entri, yang merupakan get_chat_response fungsi yang ditentukan dalam copilot.py. Ini juga menentukan persyaratan yang perlu dijalankan alur.
Buat file flow.flex.yaml di folder copilot_flow . Tambahkan konten ini:
entry: copilot:get_chat_response
environment:
python_requirements_txt: requirements.txt
Gunakan alur prompt untuk menguji salinan Anda
Gunakan kemampuan pengujian alur prompt untuk melihat performa salinan Anda seperti yang diharapkan pada input sampel. Dengan menggunakan file flow.flex.yaml , Anda dapat menggunakan alur perintah untuk menguji dengan input yang ditentukan.
Jalankan alur menggunakan perintah alur perintah ini:
pf flow test --flow ./copilot_flow --inputs chat_input="how much do the Trailwalker shoes cost?"
Atau, Anda dapat menjalankan alur secara interaktif dengan --ui bendera.
pf flow test --flow ./copilot_flow --ui
Saat Anda menggunakan --ui, pengalaman obrolan sampel interaktif membuka jendela di browser lokal Anda.
- Saat pertama kali menjalankan dengan
--uibendera, Anda perlu memilih input dan output obrolan secara manual dari opsi. Pertama kali Anda membuat sesi ini, pilih pengaturan konfigurasi bidang input/output obrolan, lalu mulai mengobrol. - Saat berikutnya Anda menjalankan dengan
--uibendera, sesi akan mengingat pengaturan Anda.

Setelah selesai dengan sesi interaktif, masukkan Ctrl + C di jendela terminal untuk menghentikan server.
Menguji dengan riwayat obrolan
Secara umum, alur permintaan dan Prompty riwayat obrolan dukungan. Jika Anda menguji dengan --ui bendera di front end yang dilayani secara lokal, alur prompt mengelola riwayat obrolan Anda. Jika Anda menguji tanpa --ui, Anda dapat menentukan file input yang menyertakan riwayat obrolan.
Karena aplikasi kami mengimplementasikan RAG, kami harus menambahkan logika tambahan untuk menangani riwayat obrolan dalam file queryIntent.prompty .
Untuk menguji dengan riwayat obrolan, buat file yang disebut input_with_chat_history.json di folder copilot_flow , dan tempelkan konten ini:
{
"chat_input": "how much does it cost?",
"chat_history": [
{
"role": "user",
"content": "are the trailwalker shoes waterproof?"
},
{
"role": "assistant",
"content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions."
},
{
"role": "user",
"content": "how much do they cost?"
},
{
"role": "assistant",
"content": "The TrailWalker Hiking Shoes are priced at $110."
},
{
"role": "user",
"content": "do you have waterproof tents?"
},
{
"role": "assistant",
"content": "Yes, we have waterproof tents available. Can you please provide more information about the type or size of tent you are looking for?"
},
{
"role": "user",
"content": "which is your most waterproof tent?"
},
{
"role": "assistant",
"content": "Our most waterproof tent is the Alpine Explorer Tent. It is designed with a waterproof material and has a rainfly with a waterproof rating of 3000mm. This tent provides reliable protection against rain and moisture."
}
]
}
Untuk menguji dengan file ini, jalankan:
pf flow test --flow ./copilot_flow --inputs ./copilot_flow/input_with_chat_history.json
Output yang diharapkan seperti: "Tenda Alpine Explorer dihargai $ 350."
Sistem ini dapat menafsirkan niat kueri "berapa biayanya?" untuk mengetahui bahwa "itu" mengacu pada Tenda Alpine Explorer, yang merupakan konteks terbaru dalam riwayat obrolan. Kemudian sistem membuat kueri pencarian untuk harga Tenda Alpine Explorer untuk mengambil dokumen yang relevan untuk biaya Tenda Alpine Explorer, dan kami mendapatkan responsnya.
Jika Anda menavigasi ke pelacakan dari alur ini berjalan, Anda akan melihat tindakan ini. Tautan jejak lokal ditampilkan di output konsol sebelum hasil eksekusi pengujian alur.

Membersihkan sumber daya
Untuk menghindari timbulnya biaya Azure yang tidak perlu, Anda harus menghapus sumber daya yang Anda buat dalam tutorial ini jika tidak lagi diperlukan. Untuk mengelola sumber daya, Anda dapat menggunakan portal Azure.
Tetapi jangan menghapusnya, jika Anda ingin menyebarkan salinan Anda ke Azure di bagian berikutnya dari seri tutorial ini.